1. Dados de séries temporais e suas características
Time Series Data é uma série de dados de monitoramento de indicadores gerados continuamente com base em uma frequência relativamente estável, como o índice Dow Jones dentro de um ano, a temperatura medida em diferentes momentos do dia e assim por diante. Os dados de séries temporais têm as seguintes características:
- Invariância de dados históricos
- disponibilidade de dados
- Pontualidade dos dados
- dados estruturados
- volume de dados
Em segundo lugar, a estrutura básica do banco de dados de séries temporais
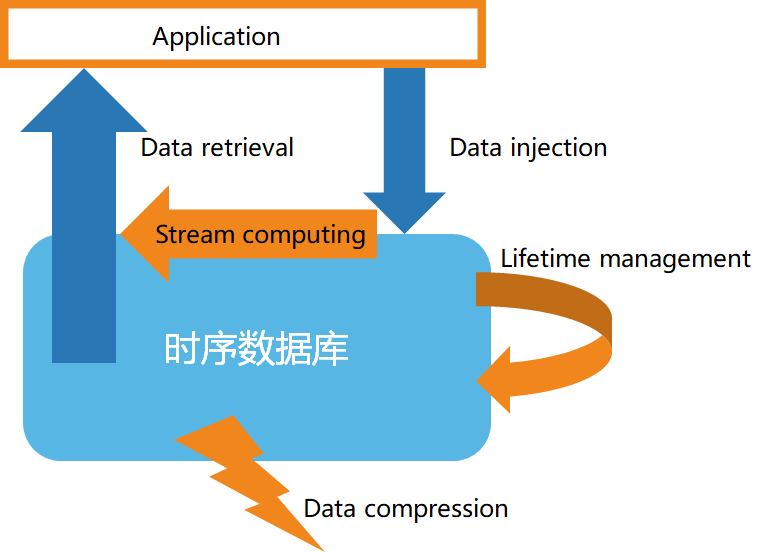
De acordo com as características dos dados de séries temporais, os bancos de dados de séries temporais geralmente têm as seguintes características:
- Armazenamento de dados de alta velocidade
- Gerenciamento do ciclo de vida dos dados
- Processamento de fluxo de dados
- Consulta de dados eficiente
- Compactação de dados personalizada
3. Introdução à Stream Computing
A computação de fluxo refere-se principalmente à aquisição em tempo real de dados massivos de diferentes fontes de dados e análise e processamento em tempo real para obter informações valiosas. Cenários de negócios comuns incluem resposta rápida a eventos em tempo real, alarmes em tempo real para mudanças de mercado, análise interativa de dados em tempo real, etc. A computação de fluxo geralmente inclui as seguintes funções:
1) Filtragem e conversão (filtro e mapa)
2) Funções de agregação e janela (reduzir, agregar/janela)
3) Fusão de vários fluxos de dados e correspondência de padrões (junção e detecção de padrões)
4) Do fluxo ao processamento em bloco
4. Suporte de banco de dados de séries temporais para computação de fluxo
-
Caso 1: Use uma API de computação de fluxo personalizada, conforme mostrado no exemplo a seguir:
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
Caso 2: Use instruções semelhantes a SQL para criar computação de fluxo e definir regras de computação de fluxo, como segue:
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);