

Com a exploração aprofundada de aplicações de modelos em grande escala, a tecnologia de geração aumentada de recuperação recebeu ampla atenção e foi aplicada em vários cenários, como perguntas e respostas de base de conhecimento, consultores jurídicos, assistentes de aprendizagem, robôs de sites, etc.
No entanto, muitos amigos não têm clareza sobre o relacionamento e os princípios técnicos dos bancos de dados vetoriais e do RAG. Este artigo fornecerá uma compreensão aprofundada do novo banco de dados vetorial na era RAG.
01.
A ampla gama de aplicações do RAG e suas vantagens exclusivas
Uma estrutura RAG típica pode ser dividida em duas partes: Recuperador e Gerador. O processo de recuperação inclui segmentação de dados (como documentos), incorporação de vetores (incorporação) e construção de índices (vetores de pedaços) e, em seguida, os resultados relevantes são recuperados por meio da recuperação de vetores. , e o processo de geração usa Prompt aprimorado com base nos resultados da recuperação (Contexto) para ativar o LLM para gerar respostas (Resultado).
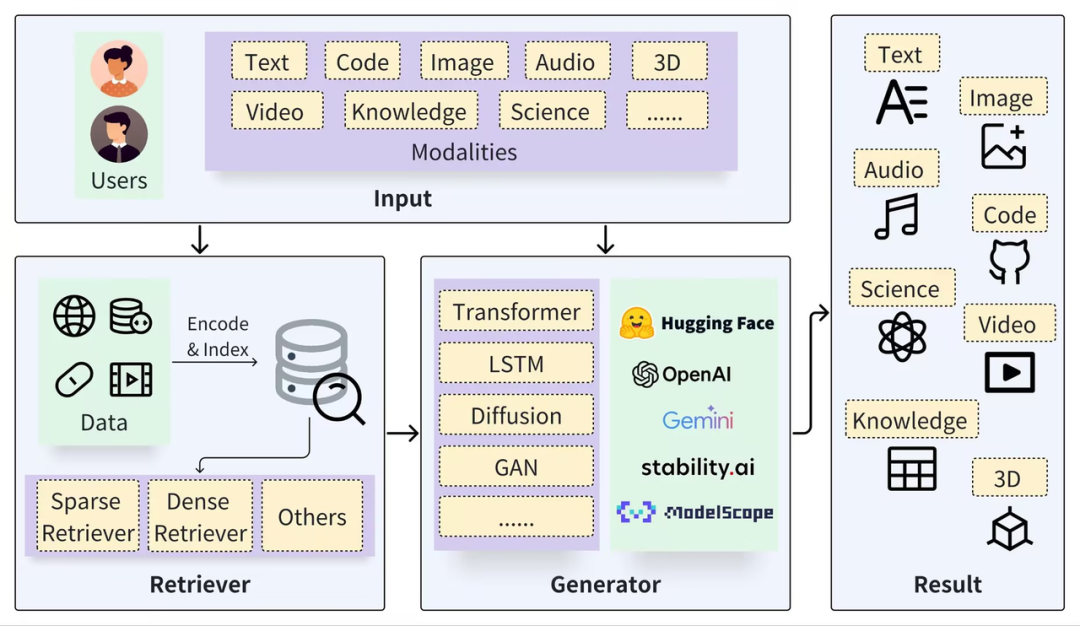
https://arxiv.org/pdf/2402.19473
A chave para a tecnologia RAG é que ela combina o melhor de ambas as abordagens: um sistema de recuperação que fornece factos e dados específicos e relevantes, e um modelo generativo que constrói respostas de forma flexível e incorpora contexto e informações mais amplos. Essa combinação torna o modelo RAG muito eficaz no processamento de consultas complexas e na geração de respostas ricas em informações, o que é muito útil em sistemas de resposta a perguntas, sistemas de diálogo e outras aplicações que requerem compreensão e geração de linguagem natural. Em comparação com modelos nativos de grande escala, o emparelhamento com RAG pode formar vantagens complementares naturais:
Evite problemas de "alucinação": o RAG auxilia grandes modelos a responder perguntas, recuperando informações externas como entrada. Este método pode reduzir significativamente perguntas sobre informações geradas imprecisas e aumentar a rastreabilidade das respostas.
Privacidade e segurança de dados: o RAG pode usar a base de conhecimento como um anexo externo para gerenciar os dados privados de uma empresa ou instituição para evitar que os dados vazem de maneira incontrolável após o aprendizado do modelo.
Natureza da informação em tempo real: o RAG permite a recuperação em tempo real de informações de fontes de dados externas, para que o conhecimento mais recente e específico do domínio possa ser obtido e o problema da atualidade do conhecimento possa ser resolvido.
Embora a pesquisa de ponta em modelos de grande escala também seja dedicada a resolver os problemas acima, como o ajuste fino com base em dados privados e a melhoria das capacidades de processamento de texto longo do próprio modelo, esses estudos ajudam a promover o avanço de grandes modelos. tecnologia de modelo em escala. No entanto, em cenários mais gerais, o RAG ainda é uma escolha estável, fiável e económica, principalmente porque o RAG tem as seguintes vantagens:
Modelo de caixa branca : Comparado com o efeito de "caixa preta" de ajuste fino e processamento de texto longo, a relação entre os módulos RAG é mais clara e próxima, o que proporciona maior operabilidade e interpretabilidade no ajuste de efeitos, além disso, quando a qualidade e confiança; (A certeza) do conteúdo recuperado e recuperado não é alta, o sistema RAG pode até proibir a intervenção de LLMs e responder diretamente “não sei” em vez de inventar bobagens.
Custo e velocidade de resposta: o RAG tem as vantagens de um tempo de treinamento curto e baixo custo em comparação com modelos ajustados em comparação com o processamento de texto longo, possui velocidade de resposta mais rápida e custo de inferência muito menor; Na fase de investigação e experimental, o efeito e a precisão são os mais atrativos, mas em termos de indústria e implementação industrial, o custo é um fator decisivo que não pode ser ignorado;
Gestão de dados privados: Ao dissociar a base de conhecimento de grandes modelos, o RAG não só fornece uma base prática segura e implementável, mas também pode gerir melhor o conhecimento existente e novo da empresa e resolver o problema da dependência do conhecimento. Outro ângulo relacionado é o controle de acesso e gerenciamento de dados, o que é fácil de fazer para o banco de dados base do RAG, mas difícil para modelos grandes.
Portanto, na minha opinião, à medida que a investigação em modelos de grande escala continua a se aprofundar, a tecnologia RAG não será substituída, pelo contrário, manterá uma posição importante por muito tempo. Isso se deve principalmente à sua complementaridade natural com o LLM, que permite que aplicações construídas em RAG brilhem em diversos campos. A chave para a melhoria do RAG é, por um lado, a melhoria das capacidades dos LLMs e, por outro lado, depende de várias melhorias e otimizações de recuperação (Retrieval).
02.
A base para pesquisas RAG: bancos de dados vetoriais
Na prática da indústria, a recuperação RAG é geralmente integrada com bancos de dados vetoriais, o que também deu origem a uma solução RAG baseada em ChatGPT + Banco de dados vetorial + Prompt, conhecida como pilha de tecnologia CVP. Esta solução depende de bancos de dados vetoriais para recuperar com eficiência informações relevantes para aprimorar grandes modelos de linguagem (LLMs). Ao converter consultas geradas por LLMs em vetores, o sistema RAG pode localizar rapidamente entradas de conhecimento correspondentes no banco de dados vetorial. Este mecanismo de recuperação permite que os LLMs utilizem as informações mais recentes armazenadas no banco de dados de vetores ao enfrentar problemas específicos, resolvendo efetivamente os problemas de atraso na atualização do conhecimento e ilusão inerentes aos LLMs.
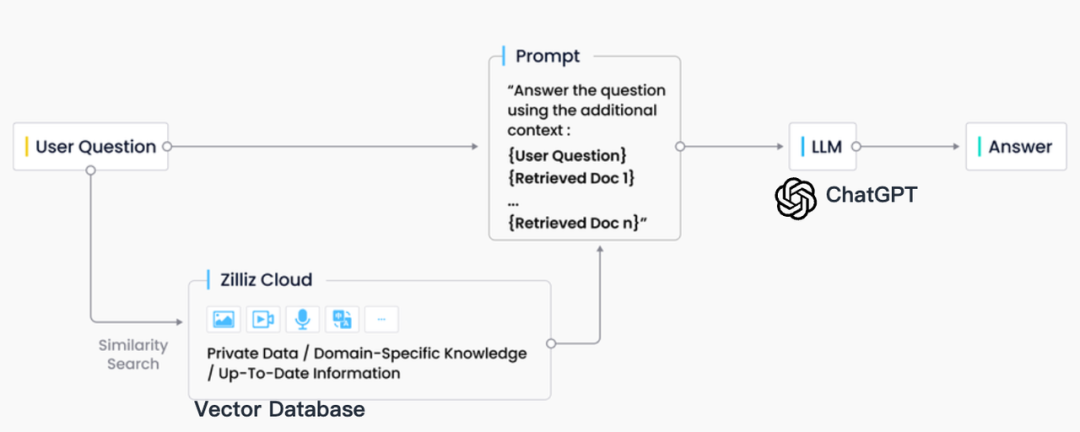
Embora existam muitas tecnologias de armazenamento e recuperação no campo da recuperação de informação, incluindo motores de busca, bases de dados relacionais, bases de dados de documentos, etc., as bases de dados vectoriais tornaram-se a primeira escolha da indústria em cenários RAG. Por trás dessa escolha está a excelente capacidade dos bancos de dados vetoriais de armazenar e recuperar com eficiência um grande número de vetores incorporados. Esses vetores de incorporação são gerados por modelos de aprendizado de máquina e não apenas são capazes de caracterizar vários tipos de dados, como texto e imagens, mas também de capturar suas informações semânticas profundas. No sistema RAG, a tarefa de recuperação é encontrar com rapidez e precisão a informação que melhor corresponde à semântica da consulta de entrada, e os bancos de dados vetoriais se destacam por suas vantagens significativas no processamento de dados vetoriais de alta dimensão e na realização de pesquisas rápidas de similaridade.
A seguir está uma comparação horizontal de bancos de dados vetoriais representados pela recuperação vetorial com outras opções técnicas, bem como uma análise dos principais fatores que os tornam uma escolha comum em cenários RAG:
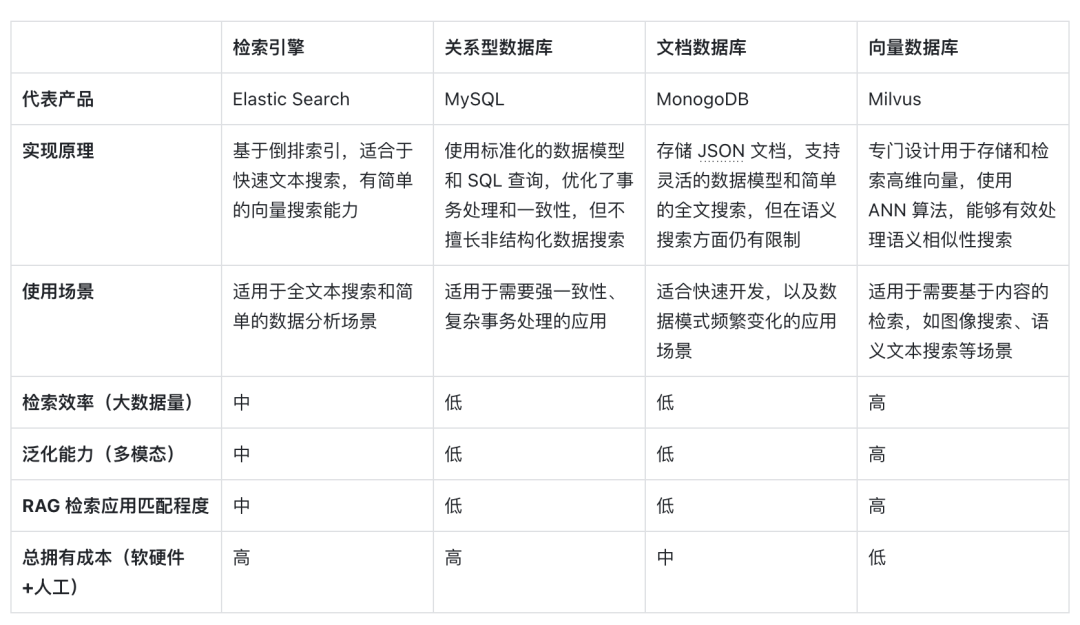
Em primeiro lugar, em termos de princípios de implementação , os vetores são a forma de codificação do significado semântico do modelo. Os bancos de dados vetoriais podem compreender melhor o conteúdo semântico das consultas porque aproveitam a capacidade dos modelos de aprendizado profundo de codificar o significado do texto, não apenas a correspondência de palavras-chave. . Beneficiando-se do desenvolvimento de modelos de IA, a precisão semântica por trás dele também está melhorando constantemente. O uso da similaridade de distância vetorial para expressar a similaridade semântica tornou-se a forma principal de PNL.
Em segundo lugar, em termos de eficiência de recuperação , uma vez que a informação pode ser expressa como vetores de alta dimensão, métodos especiais de otimização e quantificação de índice podem ser adicionados aos vetores, o que pode melhorar significativamente a eficiência de recuperação e comprimir os custos de armazenamento. o banco de dados vetorial pode ser expandido horizontalmente, mantendo o tempo de resposta da consulta, o que é crucial para sistemas RAG que precisam processar grandes quantidades de dados, portanto, os bancos de dados vetoriais são melhores no processamento de dados não estruturados em grande escala.
Quanto à dimensão da capacidade de generalização , a maioria dos mecanismos de busca tradicionais, bancos de dados relacionais ou de documentos só podem processar texto e têm pouca capacidade de generalização e expansão. Os bancos de dados vetoriais não estão limitados a dados de texto, mas também podem processar imagens, áudio e outros dados não estruturados. . tipo de vetor de incorporação, o que torna o sistema RAG mais flexível e versátil.
Finalmente, em termos de custo total de propriedade , em comparação com outras opções, os bancos de dados vetoriais são mais convenientes de implantar e mais fáceis de usar. Eles também fornecem APIs ricas, tornando-os fáceis de integrar com estruturas e fluxos de trabalho de aprendizado de máquina existentes, por isso são populares. entre eles. Um favorito entre muitos desenvolvedores de aplicativos RAG.
A recuperação de vetores tornou-se um recuperador RAG ideal na era dos grandes modelos em virtude de sua capacidade de compreensão semântica, alta eficiência de recuperação e suporte de generalização para multimodalidades. Com o desenvolvimento adicional de IA e modelos de incorporação, essas vantagens podem se tornar mais proeminentes. no futuro.
03.
Requisitos para bancos de dados vetoriais em cenários RAG
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
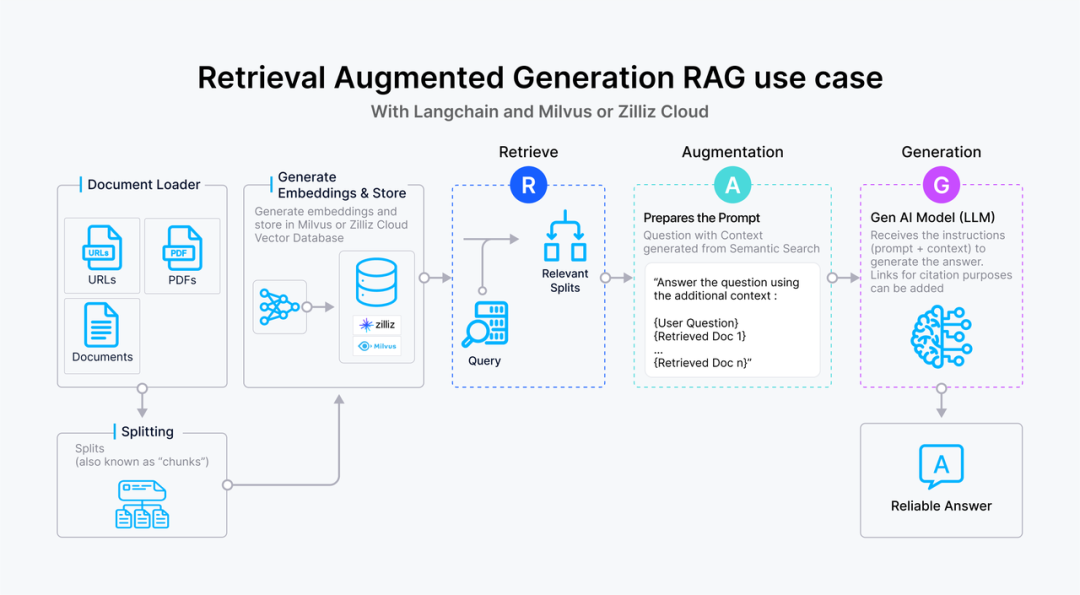
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。