
Nota do editor: Atualmente, o sistema Retrieval Enhanced Generation (RAG) tornou-se uma das principais tecnologias para capacitar conhecimento massivo em grandes modelos. No entanto, como processar eficientemente dados semiestruturados e não estruturados, especialmente dados tabulares em documentos, ainda é um grande problema enfrentado pelos sistemas RAG.
O autor deste artigo propõe uma nova solução para processamento de dados tabulares para resolver esse problema. O autor primeiro classifica sistematicamente as principais tecnologias de processamento de tabelas no sistema RAG, incluindo análise de tabelas, design de estrutura de índice, etc., e analisa algumas soluções de código aberto existentes. Com base nisso, o autor propôs sua própria inovação - usar a ferramenta Nougat para analisar com precisão e eficiência o conteúdo da tabela no documento, usar o modelo de linguagem para resumir a tabela e seu título e, finalmente, construir uma nova estrutura de índice de resumo do documento, e fornece detalhes completos de implementação do código.
A vantagem deste método é que ele pode analisar a tabela com eficácia e considerar totalmente o relacionamento entre o resumo da tabela e a tabela. Ele não requer o uso de LLM multimodal e pode economizar custos de análise. Vamos esperar e ver a aplicação e o desenvolvimento deste esquema na prática.
Autor | Florian Junho
Compilado |
A implementação de um sistema RAG é uma tarefa desafiadora, especialmente quando tabelas em documentos não estruturados precisam ser analisadas e compreendidas. Para documentos que foram digitalizados por operações de digitalização (documentos digitalizados) ou documentos em formato de imagem (documentos em formato de imagem), é ainda mais difícil implementar estas operações. Existem pelo menos três desafios:
- Documentos digitalizados por operações de digitalização (documentos digitalizados) ou documentos em formato de imagem (documentos em formato de imagem) são relativamente complexos , como a diversidade de estruturas de documentos, o documento pode conter alguns elementos não textuais e o documento pode simultaneamente A presença de o conteúdo manuscrito e impresso trará desafios à extração precisa e automatizada de informações de formulários. A análise imprecisa do documento destruirá a estrutura da tabela. A conversão de informações incompletas da tabela em representação vetorial (incorporação) não apenas não pode capturar efetivamente as informações semânticas da tabela, mas também pode facilmente causar problemas na saída final do RAG.
- Como extrair os títulos de cada tabela e associá-los à tabela específica a que correspondem.
- Como organizar e armazenar com eficiência informações semânticas importantes em tabelas por meio de um design razoável de estrutura de índice.
Este artigo apresenta primeiro como gerenciar e processar dados tabulares no modelo Retrieval Augmented Generation (RAG). Em seguida, algumas soluções de código aberto existentes são revisadas e, finalmente, um novo método de gerenciamento de dados tabulares é projetado e implementado com base na tecnologia atual.
01 Introdução às principais tecnologias relacionadas aos dados da tabela RAG
1.1 Análise de Tabela Análise de dados de tabela
A principal função deste módulo é extrair com precisão estruturas de tabelas de documentos ou imagens não estruturadas.
Requisitos adicionais: É melhor extrair o título da tabela correspondente para facilitar aos desenvolvedores associar o título da tabela à tabela.
De acordo com meu entendimento atual, existem vários métodos, conforme mostrado na Figura 1:
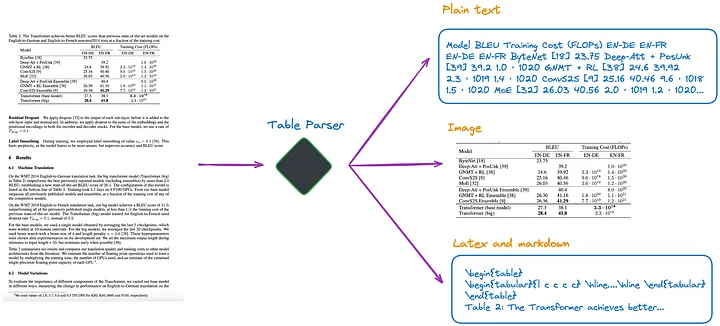
Figura 1: Analisador de tabela. Foto fornecida pelo autor original.
(a).Use LLM multimodal (como GPT-4V[1]) para reconhecer tabelas e extrair informações de cada página PDF.
- Entrada: página PDF em formato de imagem
- Saída: dados tabulares em JSON ou outros formatos. Se o LLM multimodal não conseguir extrair dados tabulares, ele deverá resumir a imagem PDF e retornar um resumo do conteúdo.
(b). Use modelos profissionais de detecção de tabela (como Table Transformer[2]) para identificar estruturas de tabela.
- Entrada: imagem da página PDF
- Saída: imagem da tabela
(c). Use estruturas de código aberto, como não estruturadas[3] ou outras estruturas que também usam modelos de detecção de objetos (este artigo[4] detalha o processo de detecção de tabelas não estruturadas). Essas estruturas podem analisar totalmente o documento inteiro e extrair conteúdo relacionado à tabela dos resultados analisados.
- Entrada: Documento em formato PDF ou imagem
- Saída: Tabela em texto simples ou formato HTML (obtida a partir da análise de todo o documento)
(d). Use modelos ponta a ponta, como Nougat[5] e Donut[6] para analisar todo o documento e extrair o conteúdo relacionado à tabela. Esta abordagem não requer um modelo de OCR.
- Entrada: Documento em formato PDF ou imagem
- Saída: Tabela em formato LaTeX ou JSON (obtida a partir da análise de todo o documento)
Deve-se observar que independentemente do método utilizado para extrair as informações da tabela, o título da tabela também deve ser extraído. Porque na maioria dos casos, o título da tabela é uma breve descrição da tabela pelo autor do documento ou autor do artigo, que pode resumir em grande parte o conteúdo de toda a tabela.
Entre os quatro métodos acima, o método (d) pode recuperar títulos de tabelas de forma mais conveniente. Este é um grande benefício para os desenvolvedores, pois eles podem associar títulos de tabelas a tabelas. Os experimentos a seguir ilustrarão isso melhor.
1.2 Como a Estrutura do Índice indexa dados tabulares
Existem aproximadamente os seguintes tipos de métodos de indexação:
(e). Indexar apenas tabelas em formato de imagem.
(f). Indexar apenas tabelas em texto simples ou formato JSON.
(g). Somente indexar tabelas em formato LaTeX.
(h). Apenas o resumo da tabela é indexado.
(i). De pequeno a grande porte (Nota do tradutor: inclui indexação refinada, como indexação de cada linha ou resumo de tabela, e indexação granular, como indexação de toda a tabela de imagens, texto simples ou LaTeX digite dados, forme uma estrutura de índice hierárquica de pequeno a grande porte.) Ou use o resumo da tabela para construir uma estrutura de índice, conforme mostrado na Figura 2.
O conteúdo do pequeno pedaço (Nota do tradutor: bloco de dados correspondente ao nível de índice refinado), como tratar cada linha da tabela ou informações resumidas como um pequeno bloco de dados independente.
O conteúdo do grande pedaço (Nota do tradutor: O bloco de dados correspondente ao nível de índice de granulação grossa) pode ser uma tabela inteira em formato de imagem, formato de texto simples ou formato LaTeX.
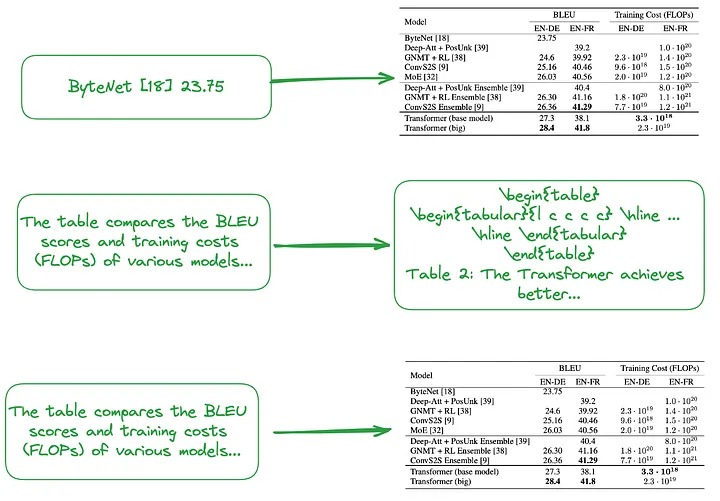
Figura 2: Indexação de pequeno a grande porte (parte superior) e uso de resumos de tabelas (meio, parte inferior). Foto fornecida pelo autor original.
Conforme mencionado acima, os resumos tabulares são normalmente gerados usando o processamento LLM:
- Entrada: formato de imagem, formato de texto ou tabela em formato LaTeX
- Saída: resumo da tabela
1.3 Uma abordagem que não requer análise de tabelas, construção de índices ou uso de tecnologia RAG
Alguns algoritmos não requerem análise de dados tabulares.
(j). Envie a imagem relevante (página do documento PDF) e a consulta do usuário para o modelo VQA (como DAN [7], etc.) (Nota do tradutor: Abreviação de modelo de resposta visual a perguntas. É uma combinação de modelos de computador. de visão e técnicas de processamento de linguagem natural que podem ser usadas para responder a perguntas de linguagem natural sobre o conteúdo da imagem) ou LLM multimodal e respostas de retorno.
- Conteúdo a ser indexado: Documentos em formato de imagem
- O que enviar para o modelo VQA ou LLM multimodal: Consulta + página de documentação correspondente como imagem
(k). Envie a página PDF em formato de texto relevante e a consulta do usuário para o LLM e, em seguida, retorne a resposta.
- Conteúdo a ser indexado: Documentos em formato texto
- Conteúdo enviado ao LLM: Consulta + página de documentação correspondente em formato de texto
(l). Envie imagens de documentos relevantes (páginas de documentos PDF), blocos de texto e a consulta do usuário para LLM multimodal (como GPT-4V, etc.) e, em seguida, retorne a resposta diretamente.
- Conteúdo a ser indexado: Documentos em formato de imagem e partes de documentos em formato de texto
- Conteúdo enviado para LLM multimodal: Consulta + documento no formato de imagem correspondente + blocos de texto correspondentes
Além disso, aqui estão alguns métodos que não requerem indexação, conforme mostrado nas Figuras 3 e 4:
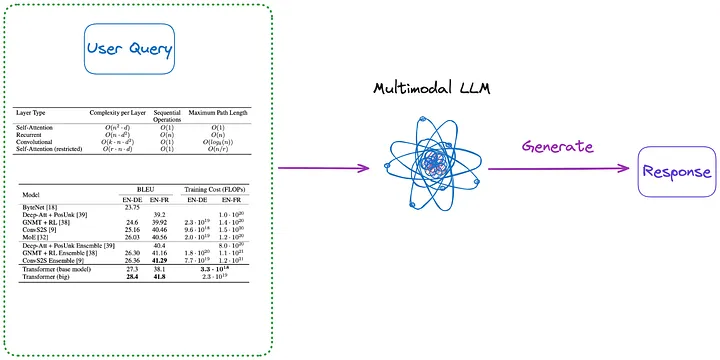
Figura 3: Categoria (m) (Nota do tradutor: Conteúdo introduzido no primeiro parágrafo abaixo). Foto fornecida pelo autor original.
(m). Primeiro, analise todas as tabelas do documento em formato de imagem usando qualquer um dos métodos de (a) a (d). Em seguida, todas as imagens da tabela e a consulta do usuário são enviadas diretamente para um LLM multimodal (como GPT-4V, etc.) e a resposta é retornada.
- Conteúdo a ser indexado: Nenhum
- Conteúdo enviado para LLM multimodal: Consulta + todas as tabelas que foram convertidas para formato de imagem
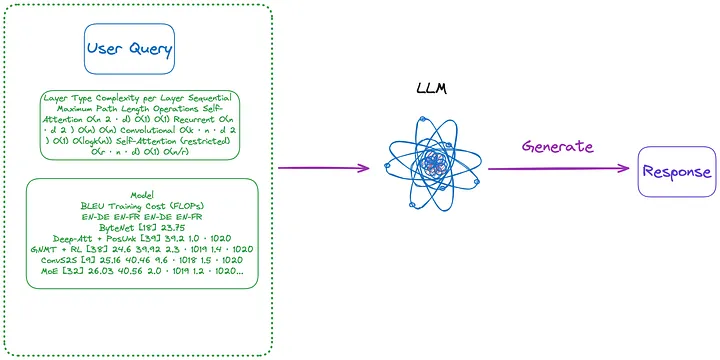
Figura 4: Ctegoria (n) (Nota do tradutor: Conteúdo introduzido no primeiro parágrafo abaixo). Foto fornecida pelo autor original.
(n). Utilize a tabela no formato de imagem extraída pelo método (m), e a seguir utilize o modelo OCR para identificar todo o texto da tabela, e a seguir envie diretamente todo o texto da tabela e a Consulta do usuário para o LLM. e retornar diretamente a resposta.
- Conteúdo a ser indexado: Nenhum
- Conteúdo enviado ao LLM: Consulta do usuário + todo o conteúdo da tabela (enviado em formato de texto)
Vale ressaltar que no processamento de tabelas em documentos, alguns métodos não utilizam a tecnologia RAG (Retrieval-Augmented Generation):
- O primeiro tipo de método não usa LLM, mas treina em um conjunto de dados específico, para que os modelos de IA (como outros modelos de linguagem baseados na arquitetura Transformer e inspirados no BERT) possam suportar melhor o processamento de tarefas de compreensão de tabelas, como TAPAS [8 ].
- O segundo tipo de método é usar LLM, usando pré-treinamento, métodos de ajuste fino ou engenharia de palavras imediatas, para que o LLM possa completar tarefas de compreensão de tabelas, como GPT4Table [9].
02 Soluções de código aberto existentes para processamento de tabelas
A seção anterior resumiu e classificou as principais tecnologias para processamento de dados tabulares em sistemas RAG. Antes de propor a solução que implementaremos neste artigo, vamos explorar algumas soluções de código aberto.
LlamaIndex propõe quatro métodos [10], dos quais os três primeiros utilizam modelos multimodais.
- Recupere a imagem da página PDF relevante e envie-a para GPT-4V em resposta à consulta do usuário.
- Converta cada página PDF em formato de imagem e deixe o GPT-4V realizar o raciocínio de imagem em cada página. Estabeleça um índice de armazenamento de vetores de texto para o processo de raciocínio de imagem (nota do tradutor: converta as informações de texto inferidas da imagem em forma vetorial e crie um índice) e, em seguida, use o armazenamento de vetores de raciocínio de imagem (nota do tradutor: deve ser o índice anterior , Consulte o índice Text Vector Store criado anteriormente) para encontrar a resposta.
- Use o Table Transformer para cortar informações da tabela das imagens recuperadas e, em seguida, enviar essas imagens da tabela cortadas para GPT-4V para obter respostas de consulta (Nota do tradutor: Envie a consulta ao modelo e obtenha as respostas retornadas pelo modelo).
- Aplique OCR na imagem da tabela recortada e envie os dados para GPT4/GPT-3.5 para responder à consulta do usuário.
Para resumir os quatro métodos acima:
- O primeiro método é semelhante ao método (j) apresentado neste artigo e não requer análise de tabela. Mas acontece que mesmo que a resposta esteja ali na imagem, ela não produz a resposta correta.
- O segundo método envolve a análise de tabelas e corresponde ao método (a). O conteúdo do índice pode ser conteúdo tabular ou resumos de conteúdo, dependendo inteiramente dos resultados retornados pelo GPT-4V, que podem corresponder ao método (f) ou (h). A desvantagem dessa abordagem é que a capacidade do GPT-4V de identificar tabelas e extrair seu conteúdo de imagens de documentos é inconsistente, especialmente quando a imagem do documento contém tabelas, texto e outras imagens (o que é comum em documentos PDF).
- O terceiro método é semelhante ao método (m) e não requer indexação.
- O quarto método é semelhante ao método (n) e também não requer indexação. Os resultados mostraram que o motivo das respostas erradas foi a incapacidade de extrair efetivamente informações tabulares das imagens.
Através de testes, constatou-se que o terceiro método tem o melhor efeito geral. No entanto, de acordo com os testes que realizei, o terceiro método teve dificuldade em detectar a tabela, muito menos em extrair e associar corretamente o título e o conteúdo da tabela.
Langchain também propôs algumas soluções para a tecnologia RAG de dados semiestruturados (RAG semiestruturado) [11]. As tecnologias principais incluem:
- Use não estruturado para análise de tabela, que é um método de classe (c).
- O método de índice é o índice de resumo do documento (Nota do tradutor: use informações de resumo do documento como conteúdo do índice), que pertence ao método da classe (i). O bloco de dados correspondente ao nível de índice refinado: conteúdo do resumo da tabela, e o bloco de dados correspondente ao nível de índice granular: conteúdo original da tabela (formato de texto).
Conforme mostrado na Figura 5:
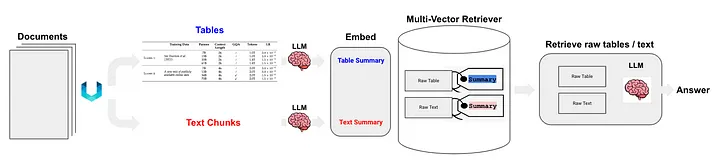
Figura 5: Solução RAG semiestruturada da Langchain. Fonte: RAG semiestruturado[11]
O RAG Semiestruturado e Multimodal [12] propôs três soluções, cuja arquitetura é mostrada na Figura 6.
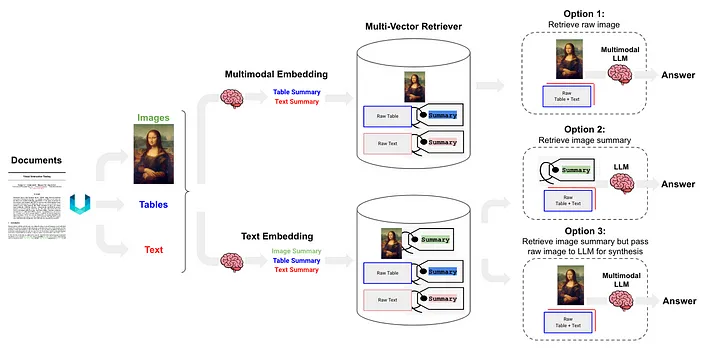
Figura 6: Esquema RAG semiestruturado e multimodal da Langchain. Fonte: RAG Semiestruturado e Multimodal[12].
A opção 1 é semelhante ao método (l) acima. Esta abordagem envolve o uso de embeddings multimodais (como CLIP [13]) para converter imagens e texto em vetores de incorporação e, em seguida, usar um algoritmo de busca por similaridade para recuperar ambos e converter os dados de imagem e texto não processados são passados para o LLM multimodal, permitindo-lhes para serem processados em conjunto e gerar respostas às perguntas.
A opção 2 usa LLM multimodal (como GPT-4V[14], LLaVA[15] ou FUYU-8b[16]) para processar a imagem para gerar resumos de texto. Os dados de texto são então convertidos em vetores de incorporação, e esses vetores são usados para pesquisar ou recuperar conteúdo de texto que corresponda à consulta feita pelo usuário e passados ao LLM para gerar respostas.
- Os dados da tabela são analisados usando o método não estruturado, que pertence ao método da classe (d).
- O método de indexação é o índice de resumo do documento (Nota do tradutor: as informações de resumo do documento são usadas como conteúdo do índice), que pertence ao (i) método de classe O bloco de dados correspondente ao nível de índice refinado: conteúdo do resumo da tabela e os dados. bloco correspondente ao nível de índice de granulação grossa: texto Formatar conteúdo da tabela.
A opção 3 usa LLM multimodal (como GPT-4V [14], LLaVA [15] ou FUYU-8b [16]) para gerar resumos de texto a partir de dados de imagem e, em seguida, incorporar esses resumos de texto em vetores, usando esses vetores de incorporação , Os resumos de imagem podem ser recuperados (recuperados) de forma eficiente. Em cada resumo de imagem recuperado, uma referência correspondente à imagem bruta (referência à imagem bruta) pertence ao método (i) acima. e blocos de texto são passados para o LLM multimodal para gerar respostas.
03 A solução proposta neste artigo
As principais tecnologias e soluções existentes estão resumidas, classificadas e discutidas no artigo anterior. Com base nisso, propomos a seguinte solução, conforme mostrado na Figura 7. Para simplificar, alguns módulos RAG, como reclassificação e reescrita de consultas, são omitidos da figura.
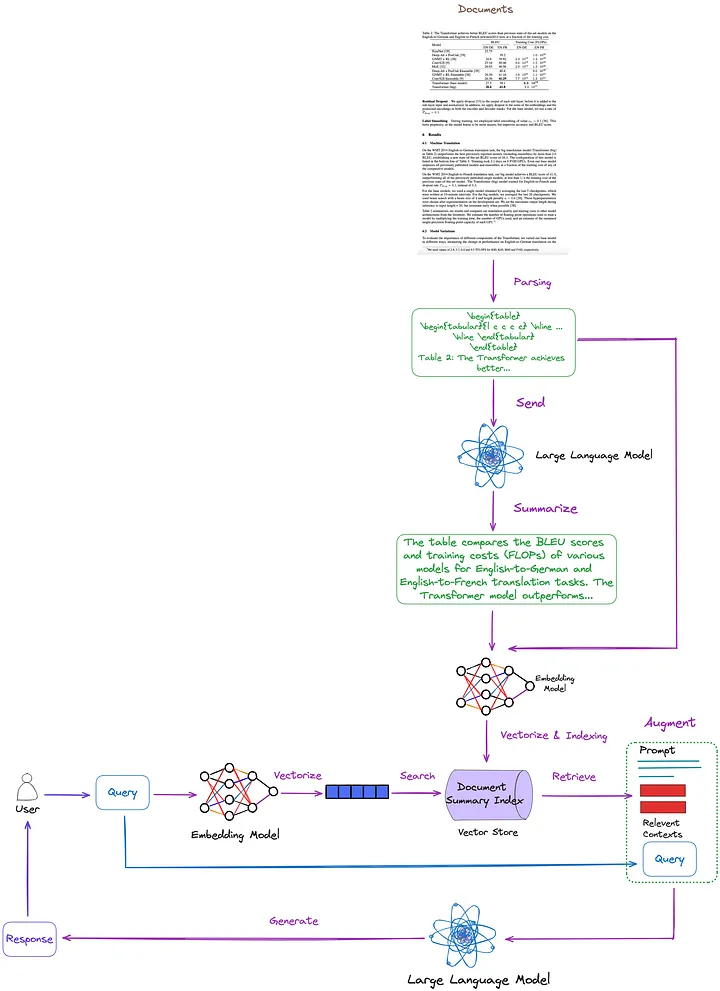
Figura 7: A solução proposta neste artigo. Foto fornecida pelo autor original.
- Técnica de análise de tabela: usando o método de classe Nougat ((d)). De acordo com meus testes, os recursos de detecção de tabela desta ferramenta são mais eficazes do que os não estruturados (uma técnica do tipo (c)). Além disso, o Nougat também pode extrair muito bem os títulos das tabelas, tornando-o muito conveniente para associá-los às tabelas.
- Estrutura de índice para indexação e recuperação de resumos de documentos (métodos da classe (i)): o nível de índice refinado contém resumos de conteúdo tabular, e o nível de índice de granulação grossa contém tabelas correspondentes em formato LaTeX e títulos de tabelas em formato de texto. Usamos um recuperador multivetorial[17] (Nota do tradutor: um recuperador para recuperar conteúdo em um índice de resumo de documento que pode processar vários vetores ao mesmo tempo para recuperar com eficiência resumos de documentos relacionados à consulta.) para atender.
- Como obter um resumo do conteúdo da tabela: Envie a tabela e o título da tabela ao LLM para resumo do conteúdo.
A vantagem desse método é que ele pode analisar a tabela com eficácia e considerar totalmente o relacionamento entre o resumo da tabela e a tabela. Elimina a necessidade de usar LLM multimodal, resultando em economia de custos.
3.1 Como funciona o Nougat
Nougat [18] é desenvolvido com base na arquitetura Donut [19]. Esta abordagem usa algoritmos que podem reconhecer texto automaticamente de maneira implícita, sem qualquer entrada ou módulo relacionado a OCR.
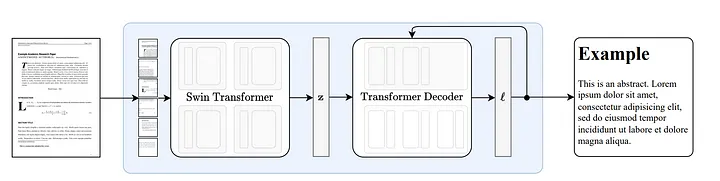
Figura 8: Arquitetura ponta a ponta seguindo Donut [19]. O codificador Swin Transformer pega uma imagem de documento e a converte em embeddings latentes (Nota do tradutor: a informação da imagem é codificada em um espaço latente) e então a converte em uma sequência de tokens de maneira autorregressiva. Fonte: Nougat: Compreensão Óptica Neural para Documentos Acadêmicos.[18]
A capacidade do Nougat de analisar fórmulas é impressionante[20], mas sua capacidade de analisar tabelas também é excepcional. Conforme mostrado na Figura 9, pode ser associado a títulos de tabelas, o que é muito conveniente:

Figura 9: Resultados da execução do Nougat O arquivo de resultados está no formato Mathpix Markdown (pode ser aberto através do plug-in vscode) e a tabela é apresentada no formato LaTeX.
Em um teste que realizei em uma dúzia de artigos, descobri que os títulos das tabelas eram sempre fixados na próxima linha da tabela. Essa consistência sugere que não foi por acaso. Portanto, estamos mais interessados em como o Nougat consegue essa funcionalidade.
Dado que este é um modelo ponta a ponta sem resultados intermediários, é provável que seu desempenho dependa fortemente de seus dados de treinamento.
Com base na análise do código, a localização e a maneira como a seção do cabeçalho da tabela é armazenada parecem ser consistentes com (e imediatamente \end{table} após caption_parts ) o formato organizacional da tabela nos dados de treinamento.
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
3.2 Vantagens e Desvantagens do Nougat
vantagem:
- O Nougat pode analisar com precisão seções que eram difíceis de analisar com ferramentas de análise anteriores, como fórmulas e tabelas, em código-fonte LaTeX.
- O resultado da análise do Nougat é um documento semiestruturado semelhante ao Markdown.
- Capacidade de obter facilmente títulos de tabelas e associá-los facilmente a tabelas.
deficiência:
- A velocidade de análise do Nougat é lenta, o que pode causar dificuldades em aplicações de grande escala.
- Como o conjunto de dados de treinamento do Nougat consiste basicamente em artigos científicos, essa técnica funciona bem em documentos com estruturas semelhantes. O desempenho diminui ao processar documentos de texto não latinos.
- O modelo Nougat treina apenas uma página de um artigo científico por vez e não tem conhecimento das outras páginas. Isso pode levar a algumas inconsistências no conteúdo analisado. Portanto, se o efeito de reconhecimento não for bom, considere dividir o PDF em páginas separadas e analisá-las página por página.
- A análise de tabelas em artigos de duas colunas não é tão boa quanto em artigos de uma coluna.
3.3 Implementação do código
Primeiro, instale os pacotes Python relevantes:
pip install langchain
pip install chromadb
pip install nougat-ocr
Após a conclusão da instalação, você precisa verificar a versão do pacote Python:
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
Configure um ambiente de trabalho e importe pacotes:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
Baixe o artigo "Atenção é tudo que você precisa" [21] para o caminho YOUR_PDF_PATH, execute nougat para analisar o arquivo PDF e obtenha os dados da tabela em formato látex e o título da tabela em formato de texto a partir dos resultados da análise. A execução do programa pela primeira vez fará o download dos arquivos de modelo necessários para o ambiente local.
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
A função june_get_tables_from_mmd é usada para extrair todo o conteúdo de um arquivo mmd (de \begin{table} até \end{table}, mas também incluindo \end{table} a primeira linha depois), conforme mostrado na Figura 10.

Figura 10: Resultados da execução do Nougat O arquivo de resultados está no formato Mathpix Markdown (pode ser aberto por meio do plug-in vscode) e o conteúdo da tabela analisada está no formato latex. A função da função june_get_tables_from_mmd é extrair as informações da tabela na caixa vermelha. Foto fornecida pelo autor original.
Porém, não existe nenhum documento oficial determinando que o título da tabela deva ser colocado abaixo da tabela, ou que a tabela deva começar com \begin{table} e terminar com \end{table}. Portanto, june_get_tables_from_mmd é um método heurístico.
A seguir estão os resultados da análise de tabela do documento PDF:
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \ \hline Self-Attention & (O(n^{2}\cdot d)) & (O(1)) & (O(1)) \ Recurrent & (O(n\cdot d^{2})) & (O(n)) & (O(n)) \ Convolutional & (O(k\cdot n\cdot d^{2})) & (O(1)) & (O(log_{k}(n))) \ Self-Attention (restricted) & (O(r\cdot n\cdot d)) & (O(1)) & (O(n/r)) \ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. (n) is the sequence length, (d) is the representation dimension, (k) is the kernel size of convolutions and (r) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \ \hline ByteNet [18] & 23.75 & & & \ Deep-Att + PosUnk [39] & & 39.2 & & (1.0\cdot 10^{20}) \ GNMT + RL [38] & 24.6 & 39.92 & (2.3\cdot 10^{19}) & (1.4\cdot 10^{20}) \ ConvS2S [9] & 25.16 & 40.46 & (9.6\cdot 10^{18}) & (1.5\cdot 10^{20}) \ MoE [32] & 26.03 & 40.56 & (2.0\cdot 10^{19}) & (1.2\cdot 10^{20}) \ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & (8.0\cdot 10^{20}) \ GNMT + RL Ensemble [38] & 26.30 & 41.16 & (1.8\cdot 10^{20}) & (1.1\cdot 10^{21}) \ ConvS2S Ensemble [9] & 26.36 & **41.29** & (7.7\cdot 10^{19}) & (1.2\cdot 10^{21}) \ \hline Transformer (base model) & 27.3 & 38.1 & & (\mathbf{3.3\cdot 10^{18}}) \ Transformer (big) & **28.4** & **41.8** & & (2.3\cdot 10^{19}) \ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & (N) & (d_{\text{model}}) & (d_{\text{ff}}) & (h) & (d_{k}) & (d_{v}) & (P_{drop}) & (\epsilon_{ls}) & train steps & PPL & BLEU & params \ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \ & 4 & & & & & & & & 5.19 & 25.3 & 50 \ & 8 & & & & & & & & 4.88 & 25.5 & 80 \ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \ & & 1024 & & & & & & 5.12 & 25.4 & 53 \ & & 4096 & & & & & & 4.75 & 26.2 & 90 \ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \ & & & & & & 0.2 & & 4.95 & 25.5 & \ & & & & & & & 0.0 & 4.67 & 25.3 & \ & & & & & & & 0.2 & 5.47 & 25.7 & \ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \ \hline Vinyals & Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \ Huang & Harper (2009) [14] & semi-supervised & 91.3 \ McClosky et al. (2006) [26] & semi-supervised & 92.1 \ Vinyals & Kaiser el al. (2014) [37] & semi-supervised & 92.1 \ \hline Transformer (4 layers) & semi-supervised & 92.7 \ \hline Luong et al. (2015) [23] & multi-task & 93.0 \ Dyer et al. (2016) [8] & generative & 93.3 \ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
Em seguida, use o LLM para resumir os dados tabulares:
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
A seguir está um resumo do conteúdo das quatro tabelas em "Atenção é tudo que você precisa" [21], conforme mostrado na Figura 11:
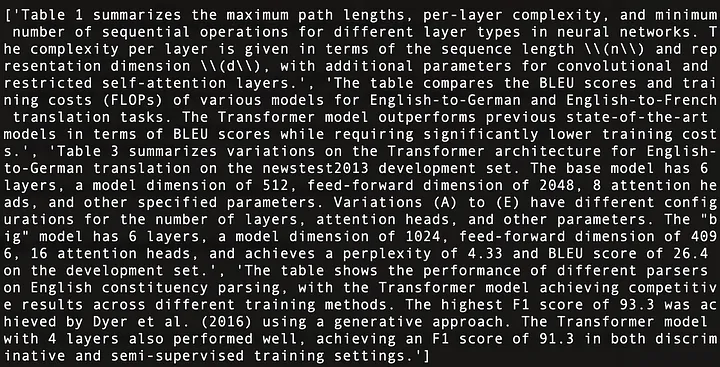
Figura 11: Resumo do conteúdo das quatro tabelas em "Attention Is All You Need" [21].
Use Multi-Vector Retriever (Nota do tradutor: um recuperador para recuperar conteúdo no índice de resumo do documento. O recuperador pode processar vários vetores ao mesmo tempo para recuperar efetivamente resumos de documentos relacionados à consulta.) Construir uma estrutura de índice de resumo do documento [17] (Nota do tradutor: uma estrutura de índice usada para armazenar informações resumidas de documentos, e essas informações resumidas podem ser recuperadas ou consultadas conforme necessário).
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
Quando tudo estiver pronto, configure um pipeline RAG simples e execute as consultas do usuário:
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
Os resultados da execução são os seguintes. Essas perguntas foram respondidas com precisão, conforme mostrado na Figura 12:

Figura 12: Respostas a três dúvidas de usuários. A primeira linha corresponde à tabela 1, a segunda linha à tabela 2 e a terceira linha à tabela 4 em Atenção é tudo que você precisa.
O código geral é o seguinte:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
04 Conclusão
Este artigo discute as principais tecnologias e soluções existentes para operações de processamento de tabelas em sistemas RAG e propõe uma solução e sua implementação.
Neste artigo, usamos o Nougat para analisar tabelas. No entanto, consideraremos a substituição do Nougat se uma ferramenta de análise mais rápida e eficiente estiver disponível. Nossa atitude em relação às ferramentas é primeiro ter a ideia certa e depois encontrar ferramentas para implementá-la, em vez de depender de uma determinada ferramenta.
Neste artigo, inserimos todo o conteúdo da tabela no LLM. Contudo, em cenários reais, precisamos levar em consideração a situação em que o tamanho da tabela excede o comprimento do contexto LLM. Podemos resolver esse problema usando métodos eficientes de chunking.
Obrigado por ler!
——
Floriano junho
Pesquisador de inteligência artificial, escreve principalmente artigos sobre grandes modelos de linguagem, estruturas de dados e algoritmos e PNL.
FIM
Referências
[1] https://openai.com/research/gpt-4v-system-card
[2] https://github.com/microsoft/table-transformer
[3] https://unstructured-io.github.io/unstructured/best_practices/table_extraction_pdf.html
[4] https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
[5] https://github.com/facebookresearch/nougat
[6] https://github.com/clovaai/donut/
[7] https://arxiv.org/pdf/1611.00471.pdf
[8] https://aclanthology.org/2020.acl-main.398.pdf
[9] https://arxiv.org/pdf/2305.13062.pdf
[10] https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13] https://openai.com/research/clip
[14] https://openai.com/research/gpt-4v-system-card
[16] https://www.adept.ai/blog/fuyu-8b
[17] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[18] https://arxiv.org/pdf/2308.13418.pdf
[19] https://arxiv.org/pdf/2111.15664.pdf
[21] https://arxiv.org/pdf/1706.03762.pdf
Este artigo foi compilado por Baihai IDP com a autorização do autor original. Caso necessite reimprimir a tradução, entre em contato conosco para autorização.
Links originais:
https://ai.plainenglish.io/advanced-rag-07-exploring-rag-for-tables-5c3fc0de7af6
Quanta receita um projeto de código aberto desconhecido pode trazer? A equipe chinesa de IA da Microsoft fez as malas e foi para os Estados Unidos, envolvendo centenas de pessoas. A Huawei anunciou oficialmente que as mudanças de emprego de Yu Chengdong foram fixadas no "Pilar da Vergonha FFmpeg" por 15 anos. atrás, mas hoje ele tem que nos agradecer—— Tencent QQ Video vinga sua humilhação passada? O site espelho de código aberto da Universidade de Ciência e Tecnologia de Huazhong está oficialmente aberto para acesso externo : Django ainda é a primeira escolha para 74% dos desenvolvedores. O editor Zed fez progressos no suporte ao Linux. deu a notícia: Depois de ser desafiado por um subordinado, o líder técnico ficou furioso e rude, foi demitido e engravidou. Funcionária Alibaba Cloud lança oficialmente Tongyi Qianwen 2.5 Microsoft doa US$ 1 milhão para a Rust Foundation.