Введение в лоток
концепция лотка
Flume - это высокодоступная, высоконадежная, распределенная система сбора, агрегирования и передачи массивных журналов, предоставляемая Cloudera.
преимущества лотка
(1) Его можно интегрировать с любым централизованным хранилищем.
(2) Если скорость ввода больше, чем скорость записи в место хранения, поток буферизует ее.
(3) Flume обеспечивает контекстную маршрутизацию (маршрут потока данных).
(4) Транзакция Flume основана на канале. У Flume есть две модели транзакций (отправитель + получатель), чтобы гарантировать надежную отправку сообщений.
(5) Flume является надежным, отказоустойчивым, обновляемым, простым в управлении и настраиваемым.
Особенности лотка
(1) Flume может эффективно хранить информацию журнала, собранную с нескольких веб-серверов, в HDFS / HBase
(2) Используя Flume, мы можем быстро передавать данные, полученные с нескольких серверов, в Hadoop.
(3) Помимо информации журнала, Flume также может использоваться для доступ и сбор данных о событиях крупномасштабных узлов социальных сетей, таких как facebook, twitter, сайтов электронной коммерции, таких как Amazon, flipkart и т. д.
(4) Поддержка различных типов данных ресурсов доступа, а исходящий тип данных
(5) поддерживает несколько -путевый трафик, многотрубный трафик доступа, многоканальный исходящий трафик, контекстная маршрутизация и т. д.
(6) могут быть расширены по горизонтали
Flume поддерживает настройку различных отправителей данных в системе журналов для сбора данных
Flume Обеспечивает возможность обработки данных и записи различным получателям данных (настраивается).
лотковый процесс
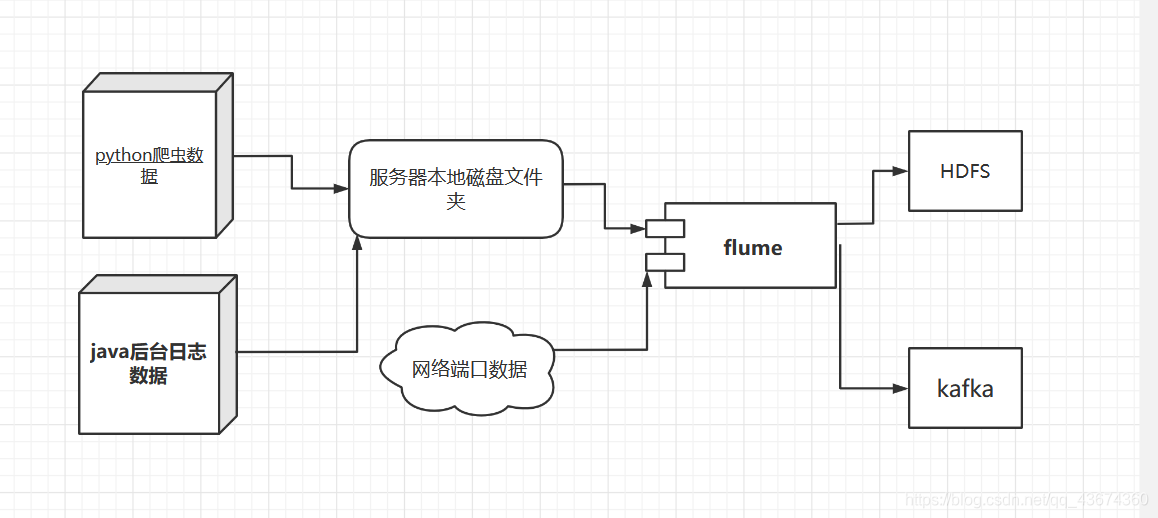
фон лотка
Основная функция Flume - считывать данные с локального диска сервера в реальном времени и записывать данные в HDFS.
Flume - это распределенная система сбора журналов, созданная программной компанией cloudera, которая позже была передана в дар Apache Software Foundation в 2009 году как один из связанных компонентов hadoop. Особенно в последние годы, с постоянным улучшением лотка и введением обновленных версий, особенно лотка-нг; в то же время различные компоненты внутри лотка постоянно обогащаются, и удобство пользователей в процессе разработки значительно улучшилось. Теперь он стал одним из лучших проектов Apache.
водоводная инфраструктура
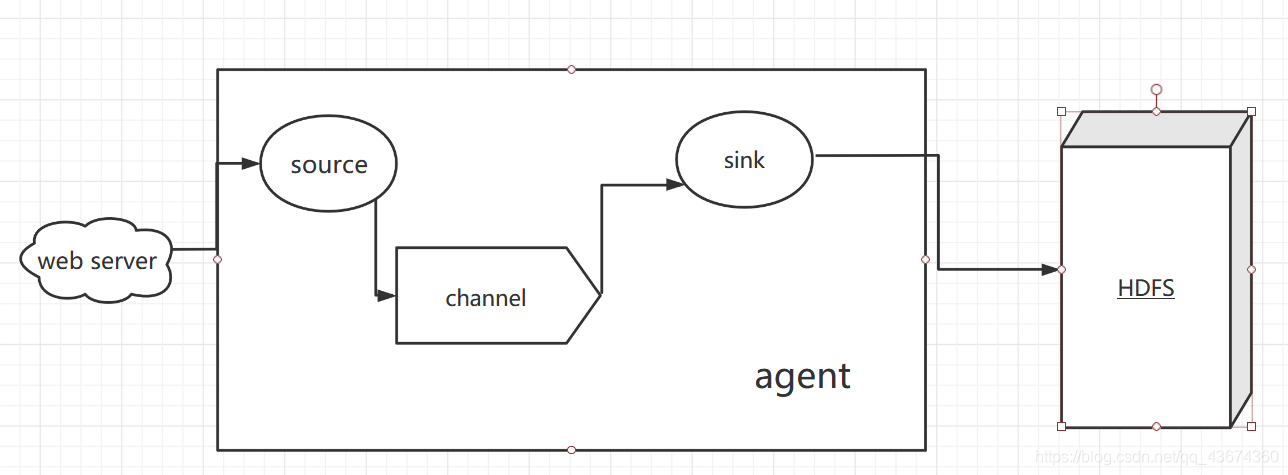 Давайте подробно представим компоненты в архитектуре Flume ниже:
Давайте подробно представим компоненты в архитектуре Flume ниже:
компоненты архитектуры лотка
Агент
Агент - это процесс JVM, который отправляет данные из источника в пункт назначения в виде событий.
Агент в основном состоит из 3 частей: источника, канала и приемника.
Источник
Источник - это компонент, отвечающий за получение данных в агент Flume. Компонент Source может обрабатывать
данные журналов различных типов и форматов, включая avro, thrift, exec, jms, каталог буферизации, netcat,
генератор последовательности , syslog, http и устаревшие.
Раковина
Sink непрерывно опрашивает события в канале и удаляет их пакетами и записывает эти события в систему хранения
или индексирования пакетами или отправляет их другому агенту Flume.
Назначения компонентов приемника включают hdfs, logger, avro, thrift, ipc, file, HBase, solr и самоопределение
.
Канал
Канал - это буфер между Источником и Приемником. Таким образом, Channel позволяет Source и Sink
работать с разными скоростями. Канал является потокобезопасным и может одновременно обрабатывать несколько операций записи источника и несколько
операций чтения приемника.
Flume имеет два канала: канал памяти, канал файла и канал Kafka.
Канал памяти - это очередь в памяти. Канал памяти подходит для сценариев, когда вам не нужно беспокоиться о потере данных
. Если вам нужно беспокоиться о потере данных, то не следует использовать канал памяти, потому что смерть программы,
простой или перезапуск машины вызовут потерю данных.
Файловый канал записывает все события на диск. Таким образом, данные не будут потеряны при закрытии программы или остановке машины
.
Мероприятие
Блок передачи, основной блок передачи данных Flume, отправляет данные из источника в пункт назначения в форме события.
Событие состоит из r Header и y Body. Заголовок используется для хранения некоторых атрибутов события. Это структура KV.
Body используется для хранения данных в виде байтового массива.

Общий процесс развития бизнеса Hadoop
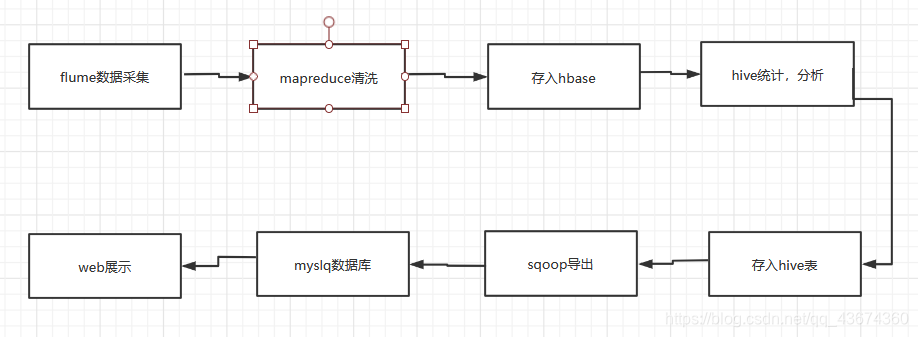
В бизнес-обработке больших данных сбор данных является очень важным и неизбежным шагом. Платформы многих компаний создают большое количество журналов каждый день. Для обработки этих журналов требуется особая система журналов. Вообще говоря, эти системы должны иметь следующие характеристики:
构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
支持近实时的在线分析系统和类似于Hadoop的离线分析系统;
具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展。
Системы журналов с открытым исходным кодом включают scribe, chukwa, kafka, flume и т. Д. Среди них: Flume - это распределенная, надежная и высокодоступная система массового агрегирования журналов, предоставляемая Cloudera. Она поддерживает настройку различных отправителей данных в системе журналов для сбора данных; в то же время Flume обеспечивает простую обработку и запись данных. различные получатели данных (например, текст, HDFS, Hbase и т. д.).
В Flume произошли серьезные структурные изменения между 0.9.x и 1.x. После версии 1.x он переименован в Flume NG, а 0.9.x называется Flume OG.