Основы Flume
1. Что такое Flume?
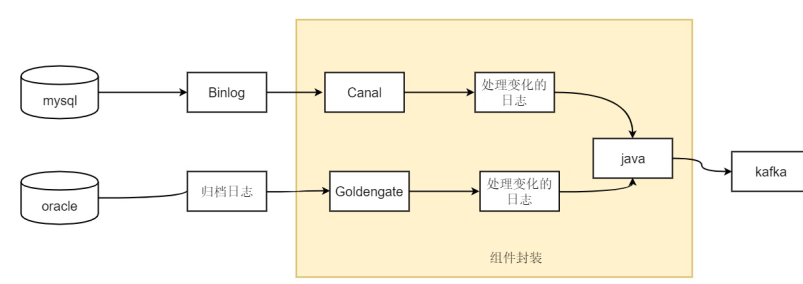
Flume - это фреймворк для сбора данных и сбора журналов, которые собираются распределенным образом (высокодоступный распределенный)
Суть: данные журналов можно эффективно собирать с различных веб-серверов и хранить в HDFS, hbase.
2. К каким источникам данных может подключаться Flume?
Консоль 、 RPC 、 Текст 、 Хвост 、 Системный журнал 、 Exec 等
3. Каково место назначения вывода источника данных, принимаемого Flume?
Диск, hdfs, hbase, kafka передаются по сети
data-> flume-> kafka-> потоковая передача искр / шторм / флинк -> hbase, mysql
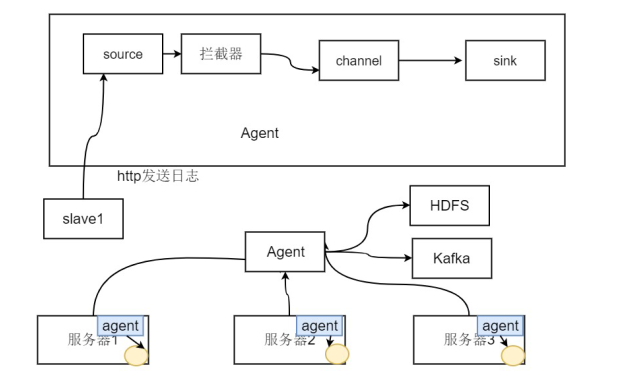
4. Процесс развертывания агента на сервере, отвечающего за сбор данных журнала сервера.
5. Flume использует событие, чтобы использовать объект события в качестве формата передачи данных, который является основной единицей внутренней передачи данных.
Две части: состоящие из байтового массива перепечатанных данных + необязательный заголовок
6. Агент: Три важных компонента:
источник: указывает источник данных лотка
канал: пул хранения
файл: убедитесь, что данные не потеряны, а скорость относительно низкая.
память: данные могут быть потеряны, быстрее
Когда передача данных завершена, событие удаляется из канала - (надежность)
сток: передать событие на внешний носитель
• Функции:
- Поддержка настройки различных отправителей данных в системе журналов для сбора данных
- Flume предоставляет возможность просто обрабатывать данные и писать различным получателям данных (настраивается)
Особенности лотка
- Flume - это распределенная, надежная и высокодоступная система массового сбора, агрегирования и передачи журналов.
- Flume может собирать различные формы исходных данных, такие как файлы, пакеты сокетов, файлы, папки, кафка и т. Д.
- Он также может выводить собранные данные во многие внешние системы хранения, такие как HDFS, hbase, hive, kafka и т. Д.
- Общие требования к сбору могут быть выполнены за счет простой конфигурации лотка.
- Flume также имеет хорошие возможности настраиваемого расширения для особых сценариев , поэтому Flume можно применять к большинству сценариев ежедневного сбора данных.
- Флюм труба на основе сделки , чтобы гарантировать , что данные в передаче и приеме по консистенции.
- Flume поддерживает многопутевый трафик , трафик многоканального доступа, трафик многоканального доступа, контекстную маршрутизацию и т. Д.
Сердечник лотка
Событие Flume
• Объект события - это основная единица передачи данных в Flume.
• Две части: событие состоит из байтового массива перепечатанных данных + необязательного заголовка.
• Событие состоит из нуля или более заголовков и тела
• Заголовок имеет форму ключа / значения , который может использоваться для принятия решений о маршрутизации или передачи другой структурированной информации (например, метки времени события или имени хоста сервера, на котором возникло событие). Вы можете думать об этом как о предоставлении той же функции, что и HTTP-заголовок, через этот метод для передачи дополнительной информации за пределы тела.
• Body - это массив байтов, который содержит фактическое содержимое.
заголовки (необязательно) -> ключ
тело (данные) -> значение
Агент Flume
• Внутри Flume есть один или несколько агентов.
• Каждый агент - это независимый демон (JVM).
• Где получить коллекцию от клиента или от других агентов, а затем быстро передать полученные данные следующему агенту узла назначения.
• Агент в основном состоит из трех компонентов: источника, канала и приемника.
Источник агента
• Источник Flume
• Отвечает за внешний источник (генератор данных), например за события, доставленные ему веб-сервером.
• Внешний источник отправляет свои события в Flume в формате, который Flume может распознать.
• Когда источник Flume получает событие, он сохраняет событие через один или несколько каналов.
Канал агента
• Канал: в виде пассивного хранения , то канал будет кэшировать событие , пока событие не обрабатывается компонент мойки
• Таким образом, Channel - это краткосрочный контейнер хранения . Он кэширует данные формата событий, полученные от источника, до тех пор, пока они не будут использованы приемниками. Он действует как мост между источником и приемником, а канал является полным. Транзакция, это обеспечивает согласованность данных при отправке и получении. И это может быть связано с любым количеством источников и приемников.
• Максимальное количество событий может быть установлено параметрами
• Flume обычно выбирает FileChannel вместо Memory Channel.
- Канал памяти : транзакции с памятью, пропускная способность очень высока, но есть риск потери данных
- Файловый канал : режим реализации транзакции на локальном диске, чтобы гарантировать, что данные не будут потеряны (реализация WAL), журнал упреждающей записи (журнал упреждающей записи на диск)
Агент Раковина
• Sink удалит событие из канала и поместит событие на внешний носитель данных.
- Например: через канал Flume HDFS Sink для помещения данных в HDFS или размещение рядом с исходным потоком Flume до следующей обработки Flume.
- Для событий, кэшированных в канале, Source и Sink обрабатываются асинхронно.
• После того, как Sink успешно удалит событие, удалите событие из канала.
• Раковина должна воздействовать на точный канал.
• Различные типы моек:
- Сохранить событие в конечном терминале назначения : HDFS, Hbase
- Автоматическое потребление: Null Sink
- Используется для связи между агентами: Avro
Агент Интерцепто
• Перехватчик - это набор перехватчиков для источника, который фильтрует и настраивает события в соответствии с заданным порядком и при необходимости.
Реализация логики обработки
• Между приложением (журналом приложения) и источником журнал приложения перехватывается. То есть ввести в журнал
Перед источником выполните некоторые действия, такие как упаковка, обновление и фильтрация журналов.
• Официально предоставленными существующими перехватчиками являются:
- Timestamp Interceptor: добавьте ключ в заголовок события с именем: timestamp, value - текущая временная метка.
- Host Interceptor: добавьте ключ в заголовок события с именем: host, значение - это имя хоста или IP-адрес текущего компьютера.
- Статический перехватчик: вы можете добавить пользовательский ключ и значение в заголовок события.
- Regex Extractor Interceptor: добавьте указанный ключ в заголовок с помощью регулярных выражений, и значение будет частью регулярного сопоставления
• Перехватчик Flume также выполнен в виде цепочки.Вы можете указать несколько перехватчиков для источника и обрабатывать их последовательно.
Селектор агентов
• Существует два типа переключателей каналов:
Селектор репликации каналов (по умолчанию): отправка событий из источника на все каналы
Multiplexing Channel Selector: Мультиплексирование можно выбрать на волосы , на какой канал
• Очевидно, что для выборочного выбора источников данных необходимо использовать мультиплексирование в качестве метода распределения.
• Проблема: при мультиплексировании необходимо определить значение ключа, указанного в заголовке, чтобы решить распространить его по конкретному каналу . 1. Если demo и demo2 работают на одном сервере в одно и то же время, если они работают на разных серверах, мы может добавить его в перехватчик хоста source1 A, чтобы вы могли определить, в какой канал событие должно быть передано хостом в заголовке. Это на том же сервере. Хост не может различить источник журнала. Мы должны найти способ добавить единицу к ключу заголовка, чтобы отличить источник журнала
Это можно решить, настроив разные источники в апстриме.
надежность:
• Flume гарантирует надежность одиночного прыжка : событие будет удалено из канала после завершения передачи.
• Flume использует транзакционный метод для обеспечения надежности взаимодействия событий.
• В течение всего процесса, если шаг был принудительно завершен из-за прерывания сети или по другим причинам, данные будут повторно переданы в следующий раз.
• Надежность Flume также отражается во временном хранении данных.Когда цель недоступна, данные будут временно сохранены в канале.После того, как цель станет доступной, данные будут временно сохранены.
Выполнить повторную передачу контрольной точки Taildir
• Источник и приемник инкапсулированы в хранилище и извлечение транзакции, то есть размещение или предоставление событий обеспечивается отдельно транзакцией через канал. Эта гарантия
Для обеспечения надежной сквозной доставки наборов событий в потоке .
- Sink запускает транзакцию
- Sink получает данные из канала
- Sink отправляет данные источнику другого агента Flume
-Источник открывает транзакцию
- Источник передает данные в канал
-Источник закрывает транзакцию
- Sink закрывает сделку
Практика лотка:
Переименуйте агента: a1
источники : r1
раковины: k1
каналы: c1
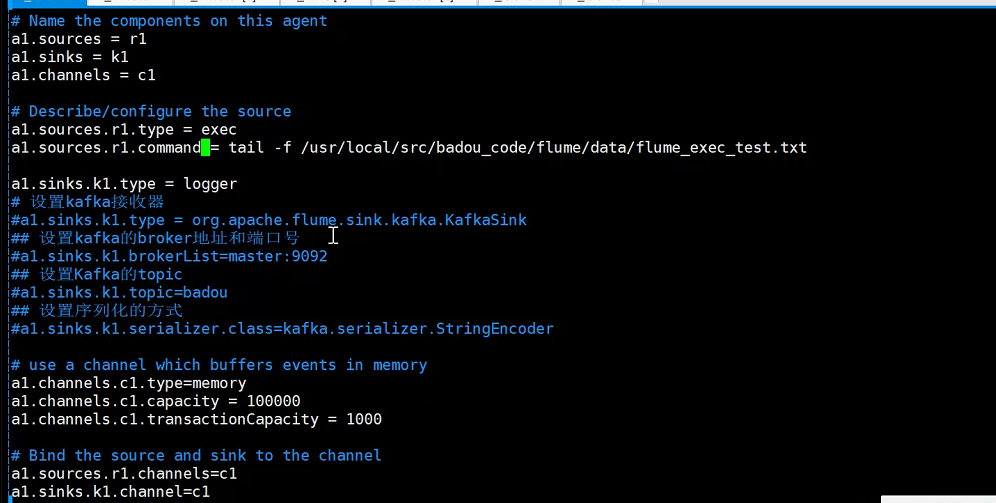
] # vim flume.conf
Запустите flume-ng
./bin/flume-ng agent --conf conf --conf-file ./conf/flume.conf -name a1 -Dflume.root.logger = DEBUG, console
Требование 1. Используйте netcat как источник и приемник как регистратор
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger = INFO, консоль
Требование 2: использование netcat в качестве источника и приемника в качестве регистратора, теперь я забочусь о буквах и отфильтровываю числа
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger = INFO, консоль
Требование 3: используйте netcat в качестве источника и приемника для записи в hdfs
./bin/flume-ng agent --conf conf --conf-file ./conf/example.conf -name a1 -Dflume.root.logger = INFO, консоль
Как настроить лоток, чтобы не было слишком много маленьких файлов?
а. Ограничьте размер файловых данных в файле.
a1.sinks.k1.hdfs.rollSize = 200 * 1024 * 1024
б. Ограничьте количество событий, которые может хранить файл.
a1.sinks.k1.hdfs.rollCount = 10000
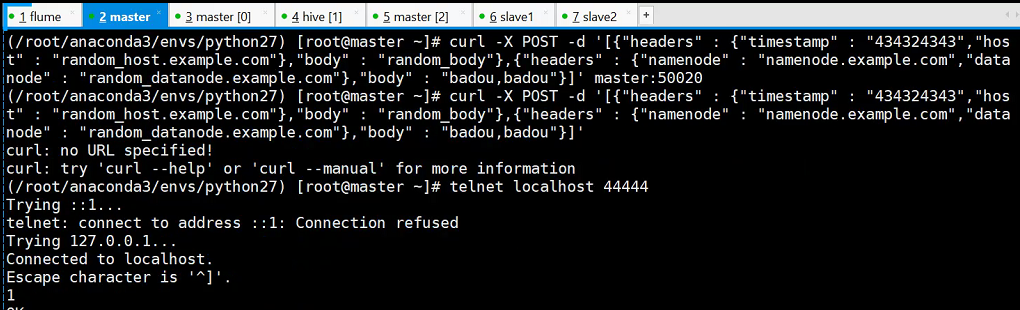
Требование 4: запись в регистратор через HTTP в качестве источника и приемника
./bin/flume-ng agent --conf conf --conf-file ./conf/header_test.conf -name a1 -Dflume.root.logger = INFO, консоль
curl -X POST -d '[{"заголовки": {"отметка времени": "434324343", "хост": "random_host.example.com"}, "body": "random_body"}, {"заголовки": { "namenode": "namenode.example.com", "datanode": "random_datanode.example.com"}, "body": "badou, badou"}] 'master: 50020
Здесь вы также можете получить к нему доступ через slave1
Требование 5: Подключите агент последовательно агент-> агент
1 、 раб2:
./bin/flume-ng агент -c conf -f conf / pull.conf -n a2 -Dflume.root.logger = INFO, консоль
2 、 мастер:
./bin/flume-ng agent -c conf -f conf / push.conf -n a1 -Dflume.root.logger = INFO, консоль
3. Выполнить на мастере
telnet localhost 44444
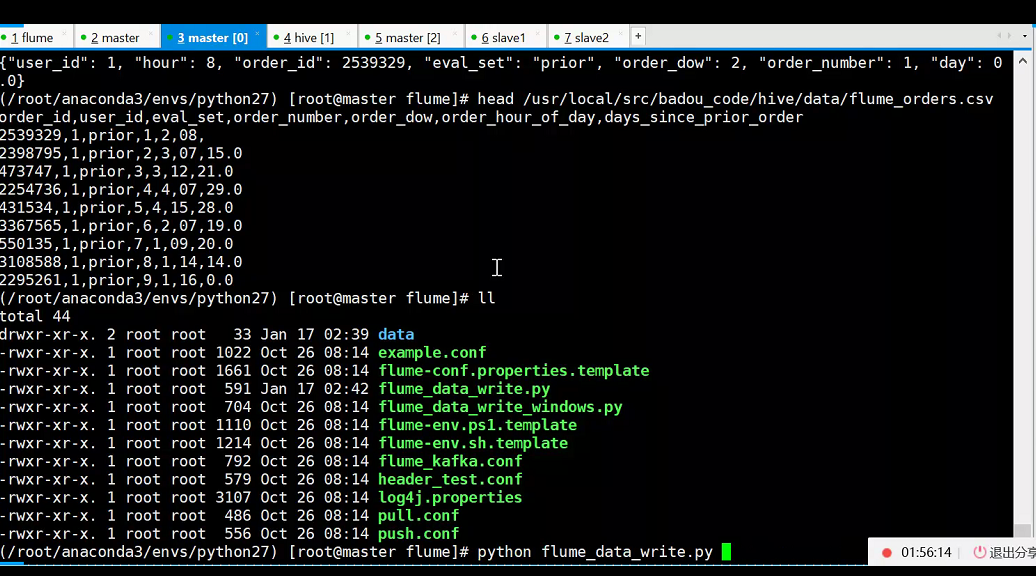
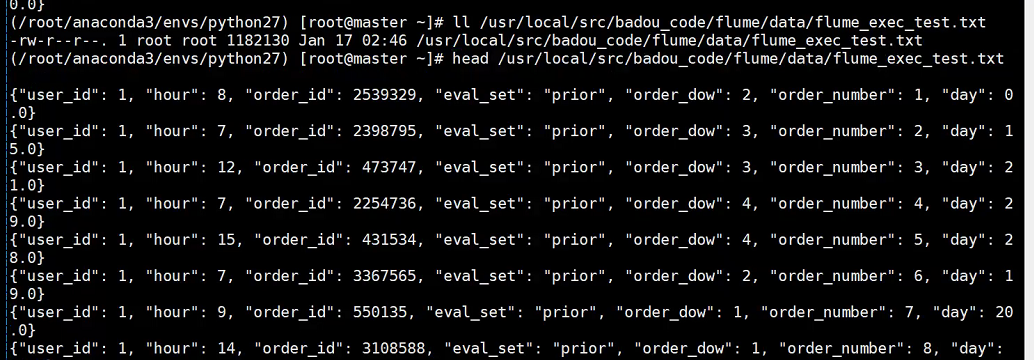
Требование 5. Отслеживайте изменения файла журнала через поток, а затем, наконец, погрузитесь в регистратор, чтобы получить файл формата json.
python flume_data_write.py
./bin/flume-ng agent --conf conf --conf-file ./conf/flume_kafka.conf -name a1 -Dflume.root.logger = INFO, console
Требование 6: лоток + кафка
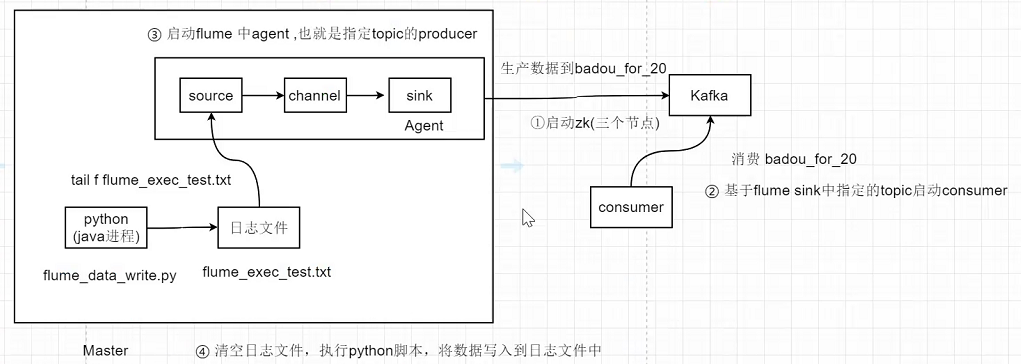
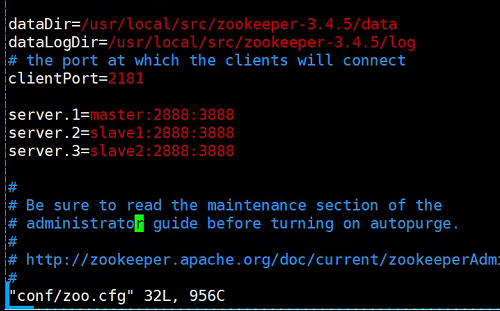
1. Сначала запустите zookeeper
./zkServer.sh start
Конфигурация Zookeeper: 1. vim zoo.cfg 2. vim data / myid - это номер записанного числа
2. Мастер запускает кафку (порт 9092)
./bin/kafka-server-start.sh config / server.properties & (Фоновый запуск)
Три способа проверить, нормально ли начался процесс :
jobs -l: просмотр фоновых процессов
ps -ef | grep 32918: просмотр фоновых процессов.
netstat -anp | grep 9092: Просмотр номера порта
- Просмотр темы кафки
bin / kafka-topics.sh --list --zookeeper localhost: 2181
- Создать тему
bin / kafka-topics.sh --create --zookeeper localhost: 2181 - коэффициент репликации 1 --partitions 1 --topic badou_for_20
- Расход по теме badou_for_20
./bin/kafka-console-consumer.sh --zookeeper master: 2181 --topic badou_for_20 --from-begin
3. Запустить лоток
./bin/flume-ng agent --conf conf --conf-file ./conf/flume_kafka.conf -name a1 -Dflume.root.logger = INFO, console
4. Очистите файл журнала.
эхо ''> flume_exec_test.txt
5. Запустите python flume_data_write.py, чтобы имитировать запись внутреннего журнала в файл журнала.
# -*- coding: utf-8 -*-
import random
import time
import pandas as pd
import json
writeFileName="/usr/local/src/badou_code/flume/data/flume_exec_test.txt"
cols = ["order_id","user_id","eval_set","order_number","order_dow","hour","day"]
df1 = pd.read_csv('/usr/local/src/badou_code/hive/data/orders.csv')
df1.columns = cols
df = df1.fillna(0)
with open(writeFileName,'a+')as wf:
for idx,row in df.iterrows():
d = {}
for col in cols:
d[col]=row[col]
js = json.dumps(d)
wf.write(js+'\n')
# rand_num = random.random()
# time.sleep(rand_num)