В этом разделе описывается рабочий механизм Hadoop MapReduce введен, в основном описывается от MapReduce процессов выполнения задания и технологических аспектов случайного порядка. К лучшему пониманию механизма работы MapReduce, разработчики могут сделать программу более рациональным использование MapReduce для решения практических задач.
Процесс выполнения задания Hadoop MapReduce
Hadoop MapReduce процесс выполнения всего задания показано на фиг.1, разделен на 10 шагов.
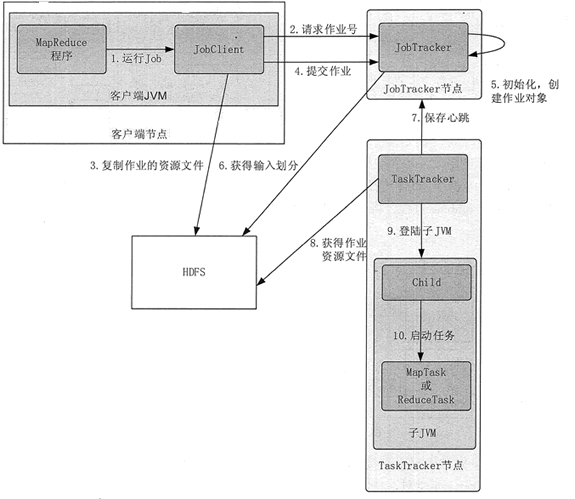
1 Hadoop MapReduce процесс выполнения задания на фиг.
1. Представьте работу
Клиент представить работу JobTracker. Во-первых, вам нужно настроить все параметры, которые будут настроены в соответствии с потребностями. После того, как работа будет отправлена, она будет ввести автоматизированное выполнение. В этом процессе, пользователь может контролировать только осуществление программы работы и вынужден прервать, но не выполнение работы любого вмешательства. Основной процесс выглядит следующим образом представить работу.
1) клиент через метод Runjob () , чтобы начать процесс подачи задания.
2) Клиент запрашивает новый идентификатор задания по JobTracker getNewJobId ().
3) осмотр Выход Описание Клиента операция ввод срез равных вычислительные операции, если есть проблемы, метательные исключение, если нормальные, будет работать ресурс (например, файл Jar задания, файл конфигурация , необходимый для работы, вычисленные нарезка на входе и т.д.) , которые будут скопированы в каталог с именем идентификатор задания.
4) () метод говорит работу готов выполнить с помощью вызова submitjob JobTracker.
2. Инициализировать работу
JobTracker в конце JobTracker запуска инициализации работы, в том числе создания ряда структур данных в памяти, чтобы записать работу этого задания.
1) После приема вызовов на метод JobTracker submitJob (), вызов будет поставлен во внутреннюю очередь, расписания планировщика заданий назыв. Инициализация главной целью является создание средства выполнения задания, для того , чтобы отслеживать состояние и ход выполнения задачи.
2) Для того , чтобы создать список запуска задачи, то планировщик заданий первого приобретает JobClient вычисленного из HDFS хорошей нарезания ввода информации, а затем создает MapTask для каждого среза, и создает ReduceTask.
3. Задачи Присвоить
JobTracker запросит файл HDFS внутри NameNode которого имеются соответствующие данные в этих файлах разбросаны в какие узлы внутри. JobTracker необходимо назначать задачи в соответствии с принципом «ближайшей перспективе.»
TaskTracker регулярно общается с JobTracker через «сердцебиение», в основном, чтобы сообщить себя ли JobTracker еще жив, и будет ли новая задача готова к запуску и так далее.
После JobTracker получить сердцебиения сообщения, если задача будет обойтись, она будет поставлена задача TaskTracker, и возвращается к значению связи TaskTracker информации о выделении пакета возврата сердцебиения.
Для задания карты, JobTracker обычно выбирает кусочек от своего недавнего ввода TaskTracker для Сократить задачи, JobTracker нельзя считать локализованную данные.
4. Выполните задание
1) После того, как TaskTracker назначается задаче, копировать файлы с помощью HDFS заданий Jar TaskTracker в файловой системе , где, в то же время, TaskTracker все документы , необходимые для применения копируются из распределенного кэша на локальном диске. TaskTracker задача создать новый локальный рабочий каталог, а содержимое файла Jar извлечены в эту папку.
2) TaskTracker начать новую JVM для выполнения каждой задачи (включая задачи картографирования и Reduce задачи), так, JobClient из MapReduce не влияет на TaskTracker демона. Задачи Дочерний процесс каждые несколько секунд сообщит родительский процесс его прогресса , пока задача не будет завершена.
5. Процесс обновления и статус
И работа, которая имеет статус каждой задачи, в том числе и рабочее состояние выполнения задания или задачи, Карта и уменьшить задачи задачи, значения счетчика, статусное сообщение или описание. Задача во время выполнения, следить за их прогрессом.
Эти сообщения к агрегации TaskTracker ChildJVM, а затем снова сходились интервалами некоторого времени JobTracker. JobTracker производит шоу, которое будет выполняться глобальным представлением всех рабочих мест и их статуса работы, пользователь может просматривать через веб-интерфейс. JobClient получить последний статус запроса JobTracker в секунду, а также вывод на консоль.
6. завершить работу
Когда последняя задача JobTracker получил это задание была завершена, он будет статус работы изменится на «успешный». Когда JobClient добраться до статуса работы, вы знаете, что работа была успешно завершена, а затем сообщить задание на печать JobClient информация пользователя успешно закончилась, последние () метод возвращает из Runjob.
HadoopMapReduce сценического случайного порядка
Перемешайте этап Hadoop MapReduce означает, начинается вывод из карты, содержащее выполнение системы сортировки и передачи результатов по сокращению Карты в качестве входов процесса.
Относится к процессу сортировки фазы закончилась выходным ключ карты рода. Различные карты может выдавать один и тот же ключ, ключ должен быть отправлен в тот же Снизить же конец лечения. этап воспроизведения в случайном порядке можно разделить на этапы Перемешать Перемешать фазы и уменьшить конец конца карты. Перемешайте стадии рабочего процесса, как показано на фиг.
1. Карта стадии Перетасовки конца
1) каждый входной срез Карта сделать задачу процесса, по умолчанию, размер блока HDFS ( по умолчанию 64) кусочка. Функция карты выдает выходной сигнал , когда начало, а не просто записывать данные на диск, из - за частые операции диска приведет к серьезному ухудшению рабочих характеристик. Он обрабатывает данные сначала записываются в буфер памяти и сделать некоторые предварительно сортируют, в целях повышения эффективности.
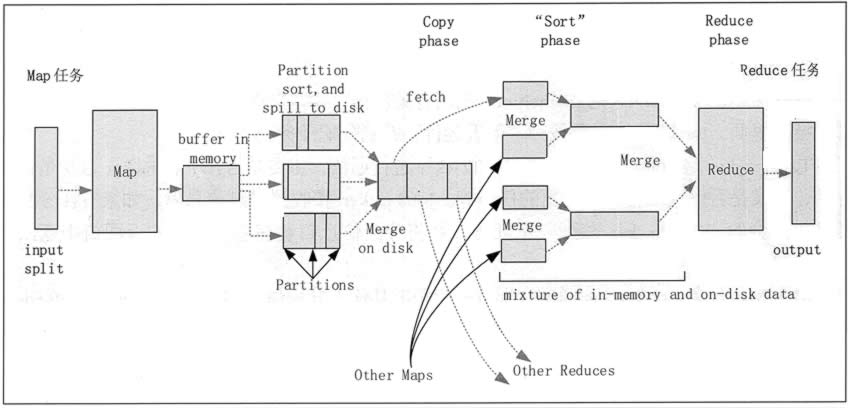
Фиг.2 Hadoop MapReduce этап Перетасовке
2) Каждая задача имеет карту для записи выходных данных кольцевого буферной пам ти (размер по умолчанию составляет 100 МБ), когда объем данных в буфере достигает определенное пороговое значение ( по умолчанию 80%), система начнет фоновый поток, содержимое буфера записывается на диск (т.е. стадии разлива). В процессе записи на диск, вывод на карте продолжает записываться в буфер, но в то же время , если буфер заполнен, задача Карта будет заблокирована , пока процесс не завершится запись на диск.
3) перед записью на диск, в соответствии с данными первого потока в конечном счете быть переданы к задаче Уменьшить данные в соответствующий раздел (раздела). В каждом районе, фоновый поток для сортировки по ключу, если есть объединитель, будет работать на выходе отсортирован.
4) После того, как порог переполнения буфера записи памяти достиг, это создаст файлы записи переполнения, поэтому после того, как карта завершает свою задачу последняя выходная запись, будет несколько файлов переполнения записи. Карта до завершения задачи, файлы Переполнение записи объединяются в один индекс и файлы данных (множественным сортировка слиянием) (Сортировать этап).
5) После того , как разливы запись файл объединение будет завершено, задача Карты будет удалять все временные перелива файлов запись и сказать задачи TaskTracker была завершены, пока задача Карты завершена, уменьшить задание начнет копировать его выход (Копировать этап).
6)Map 任务的输出文件放置在运行 Map 任务的 TaskTracker 的本地磁盘上,它是运行 Reduce 任务的 TaskTracker 所需要的输入数据。
2. Reduce 端的 Shuffle 阶段
1)Reduce 进程启动一些数据复制线程,请求 Map 任务所在的 TaskTracker 以获取输出文件(Copy 阶段)。
2)将 Map 端复制过来的数据先放入内存缓冲区中,Merge 有 3 种形式,分别是内存到内存,内存到磁盘,磁盘到磁盘。默认情况下,第一种形式不启用,第二种形式一直在运行(Spill 阶段),直到结束,第三种形式生成最终的文件(Merge 阶段)。
3)最终文件可能存在于磁盘中,也可能存在于内存中,但是默认情况下是位于磁盘中的。当 Reduce 的输入文件已定,整个 Shuffle 阶段就结束了,然后就是 Reduce 执行,把结果放到 HDFS 中(Reduce 阶段)。
Hadoop MapReduce的主要特点
MapReduce 在设计上具有的主要技术特点如下。
1. 向“外”横向扩展,而非向“上”纵向扩展
MapReduce 集群的构建完全选用价格便宜、易于扩展的低端商用服务器,而非价格昂贵、不易扩展的高端服务器。
对于大规模数据处理,由于有大量数据存储的需要,因此,基于低端服务器的集群远比基于高端服务器的集群优越,这就是 MapReduce 并行计算集群会基于低端服务器实现的原因。
2. 失效被认为是常态
MapReduce 集群中使用大量的低端服务器,因此,结点硬件失效和软件出错是常态,因而一个设计良好、具有高容错性的并行计算系统不能因为结点失效而影响计算服务的质量。
任何结点失效都不应当导致结果的不一致或不确定性,任何一个结点失效时,其他结点要能够无缝接管失效结点的计算任务,当失效结点恢复后应能自动无缝加入集群,而不需要管理员人工进行系统配置。
MapReduce 并行计算软件框架使用了多种有效的错误检测和恢复机制,如结点自动重启技术,使集群和计算框架具有对付结点失效的健壮性,能有效处理失效结点的检测和恢复。
3. 把处理向数据迁移
传统高性能计算系统通常有很多处理器结点与一些外存储器结点相连,如用存储区域网络连接的磁盘阵列,因此,大规模数据处理时,外存文件数据 I/O 访问会成为一个制约系统性能的瓶颈。
为了减少大规模数据并行计算系统中的数据通信开销,不应把数据传送到处理结点,而应当考虑将处理向数据靠拢和迁移。MapReduce 采用了数据/代码互定位的技术方法,计算结点将首先尽量负责计算其本地存储的数据,以发挥数据本地化特点,仅当结点无法处理本地数据时,再采用就近原则寻找其他可用计算结点,并把数据传送到该可用计算结点。
4. 顺序处理数据,避免随机访问数据
大规模数据处理的特点决定了大量的数据记录难以全部存放在内存中,而通常只能放在外存中进行处理。由于磁盘的顺序访问要远比随机访问快得多,因此 MapReduce 主要设计为面向顺序式大规模数据的磁盘访问处理。
为了实现高吞吐量的并行处理,MapReduce 可以利用集群中的大量数据存储结点同时访问数据,以此利用分布集群中大量结点上的磁盘集合提供高带宽的数据访问和传输。
5. 为应用幵发者隐藏系统层细节
专业程序员之所以写程序困难,是因为程序员需要记住太多的编程细节,这对大脑记忆是一个巨大的认知负担,需要高度集中注意力,而并行程序编写有更多困难。
例如,需要考虑多线程中诸如同步等复杂繁琐的细节。由于并发执行中的不可预测性,程序的调试查错也十分困难,而且,大规模数据处理时程序员需要考虑诸如数据分布存储管理、数据分发、数据通信和同步、计算结果收集等诸多细节问题。
MapReduce обеспечивает механизм абстракции, системный программист слой может изолировать детали, вычислить, что программист должен только быть описан, и конкретно упоминается о том, как вычислить систему, чтобы выполнить процесс кадра, так что система программиста из слой детали освобождения, разработки алгоритмов и стремится к своим собственным приложением вычислительных задач.
6. Гладкая и плавная масштабируемость
Вот что масштабируемость в том числе расширения двух чувств: масштабируемость данных и размера масштабируемости системы.
Идеальные алгоритмы программного обеспечения должны иметь возможность масштабирования с расширением данных, продолжая показать эффективность, степень снижения производительности следует расширить масштабы многочисленных данных, а, по размеру кластера, требования должны быть в состоянии вычислить производительность алгоритма с числом узлов поддержание почти линейное увеличение степени роста.
Подавляющее большинство существующих алгоритмов автономных ниже, чем выше идеальные требования, данные промежуточные результаты сохраняются в памяти одного алгоритме скоро выйдет из строя при крупномасштабной обработке данных, вычисления из от одного до больших кластеров на основе параллельно принципиально требует совершенно иной дизайн алгоритма.
Тем не менее, во многих случаях MapReduce или более достигается за характеристики расширения для многого расчета, на основе вычисленной производительности MapReduce может быть увеличена с числом узлов увеличились примерно линейно нахождение.
. Hadoop MapReduce рабочий процесс
. MapReduce Пример: подсчет слов
. Механизм Hadoop MapReduce