А, MapReduce идеи
MapReduce хорошо дело с большими данными, поэтому у него есть такая сила? Это можно найти MapReduce дизайнерские идеи. MapReduce Идея заключается в том , чтобы « разделяй и властвуй » .
(1) Mapper отвечает за «минуту», а именно комплекс задач в нескольких «простой задачу», чтобы иметь дело с. «Простая задача» содержит три значения: во-первых, данные или рассчитать относительный размер исходной задачи, чтобы быть значительно сокращена, а второй является ближайшим принцип вычислений, что задача будет назначена для хранения данных, необходимых для расчета узла, в-третьих, эти небольшие параллельных вычислений задача, почти нет зависимостей между друг с другом.
(2) Редуктор ответственности за результаты этапа карт объединяются. По мере увеличения числа требуемых редуктора, пользователь в зависимости от конкретной проблемы, установив значение параметра mapred.reduce.tasks файла конфигурации mapred-site.xml, значение по умолчанию.
Во-вторых, подготовка спецификаций MapReduce
1, пользовательская программа написана на три части: Mapper, редуктор, Driver (подано клиентская программа работает MR)
2, входные данные в виде Картопостроитель пары КВ (КВ настраиваемый тип)
3, выходные данные в виде Картопостроитель пары КВ (КВ настраиваемый тип)
4, Картопостроитель логика в карте () метод
5 Метод, карта () (процесс maptask) для каждого <K, V> вызывается один раз
6, в виде входных данных редуктора Mapper, соответствующий типу типа выходных данных, но и на КВ
7, Редуктор логики в рамках метода уменьшения ()
8, Reducetask процесс вызывается один раз уменьшить () метод для каждого набора одного и того же к <K, V> группы
9, Mapper и Reducer определенного пользователя класс должен наследовать свой отец
10, весь процесс требует Drvier представить, представить описание различных объектов необходимой информации задания
В-третьих, экземпляр процесса MapReduce работает в распределенной, когда
1, MRAppMaster: отвечает за весь процесс планирования и координации государственных программ
2, Yarnchild: отвечает за все обработки данных карты потока этапа
3, Yarnchild: ответственные за весь MapTask данных и ReduceTask две стадии процесса поток более, чем снизить этапы обработки являются YarnChild, если не сказать, что MapTask и ReduceTask работать в одной и той же YarnChild
В-четвертых, процесс запущен MapReduce
1, когда программа начинает М.Р., является первым, чтобы начать MRAppMaster, MRAppMaster после начала информации описания текущего задания, количество вычисления требуемого примера maptask, и машина запускают приложение, соответствующее количеству кластеров технологического maptask
2, после того, как процесс начинается maptask, для обработки данных в соответствии с заданным срезом данных (который диапазоном, к которому файл смещение) диапазон, в качестве основного потока:
А, используя клиент указанного InputFormat RecordReader приобретает считывать данные образуют входной сигнал на КВ
В, и на входе карты KV передаются метода клиента определяется (), делать логические операции, а отображение () метод КВ вывод в кэш собраны
C, KV для разбиения кэша K в соответствии с родом продолжает переполнять в файл на диск
3, MRAppMaster после всех maptask, чтобы контролировать процесс выполнения задачи (Правда, некоторый процесс лечения maptask завершен, он будет получать maptask данных начался в reducetask был завершен), начнет соответствующее число параметров, заданных в соответствии с reducetask клиента процесс, и сообщить reducetask процесс для решения диапазона данных (раздел данных)
4, после того, как начинается Reducetask процесс, положение MRAppMaster сообщить данные, подлежащая обработке, расположено, чтобы получить от машины ряда Тайваня maptask выполняется до нескольких выходных maptask файла, и повторно сортировки слияния локально, а затем следует KV же ключу для группа, клиент определенного вызова методы уменьшения () выполнять логическую операцию, и выводит результат операции, чтобы собрать KV, а затем вызвать клиент указанного OUTPUTFORMAT выводит результирующие данные на внешнее хранилище
Пять, степень параллельности maptask
Hadoop определения механизма параллелизма в MapTask. В программе запуска MapReduce, не MapTask больше, тем лучше. Нам необходимо рассмотреть вопрос о том, как настроить машину и объем данных. Если объем данных мал, это может быть время, чтобы начать задачу намного превосходит данные времени обработки. То же самое не лучше.
Так как нарезка это?
Если у нас есть файл 300M, он будет разрезан на три в HDFS. 0-128M, 128-256M, 256-300M. И помещены в различных узлах идти вверх. В задаче MapReduce, этот 3 Блок будет дано три MapTask.
MapTask фактически назначается, когда диапазон ломтика задачи, но этот диапазон является логическим понятием, не имеет ничего общего с физическим разбиением блока. Но на практике, если Считанные данные не MapTask работы машины должен выполнять передачу данных через сеть, очень большое влияние на производительность. Таким образом, политика часто принимается на субе-вырезать MapTask A блока хранения данных, такие, что каждый считывать данные MapTask машины, насколько это возможно.
Если блок очень мало, вы можете положить несколько небольшой блок на MapTask.
Таким образом, сократить MapTask суб-процесс зависит от обстоятельств. Реализация по умолчанию должен быть сегментирован в соответствии с Размер блока. MapTask нарезка ответственности (мы пишем основной метод) клиента. Кусочек соответствует примеру MapTask.
Шесть, maptask определяют степень параллельности механизма
карта параллелизм работы фазы определяется клиентом при передаче задания.
И клиент основная логика планирования фазы отображения параллельности следующим образом:
Выполнение логических данных, подлежащих обработке срез (т.е. срез В соответствии с конкретным размером, данные, которые должны быть обработаны на множество разделения логически), то каждый назначен раздвоение пример параллельной обработки mapTask
Нарежьте механизмы:
FileInputFormat механизм по умолчанию нарезанного
1, в разрезе в соответствии с простой длиной содержимого файла
2, размер плитки, размер блока по умолчанию равно
3, срез не рассматривается общий набор данных, но один кусочек за кусочком для каждого файла данных, подлежащих обработке, например, в виде двух файлов:
fILE1.TXT 200M
file2.txt 100M
После того, как getSplits () способ обработки информации следующей ломтик, формируются:
FILE1.TXT-split1 0-128M
FILE1.TXT-split2 129m-200M
File2.txt-split1 0-100m
Анализируя источник, в FileInputFormat, вычисление размера логического среза: длинный splitSize = computeSplitSize (BLOCKSIZE, MinSize, MaxSize), перевод того, что является вычисление промежуточного значения этих трех величин
Операция Кусочек основном определяется этими величинами:
размер_блок: По умолчанию 128M, может быть изменено dfs.blocksize
MinSize: По умолчанию 1, может быть изменен mapreduce.input.fileinputformat.split.minsize
MAXSIZE: По умолчанию Long.MaxValue, может быть изменен mapreduce.input.fileinputformat.split.maxsize
Поэтому, если тон отношения размер_блока MAXSIZE мал, меньше размера блока , если большой кусок будет MinSize тона , чем размер блока, срез будет больше не размером блока Однако, независимо от того , как параметры тонов не позволяют несколько небольших файлы «секретный» раскол
Семь, reducetask параллелизм
Reducetask также влияет на степень параллелизма всей работы параллельной и эффективности, но число одновременных maptask определяется количеством различных секций, число решения ReduceTask непосредственно вручную установить: job.setNumReduceTasks (4);
Значение по умолчанию равно 1,
Вручную установить до 4, показывая четыре запуска ReduceTask,
Это не установлено на 0, что означает отсутствие запущенной задачи reduceTask, то есть, нет стадии редуктора, только этап сопоставителя
Если данные распределены неравномерно, то можно генерировать данные наклона уменьшить фазу
Примечание: Номер reducetask не может быть установлен, но и учитывать потребности бизнес-логики, в некоторых случаях, необходимо рассчитать общие совокупные результаты, вы можете иметь только один reducetask
Старайтесь не работать слишком много reducetask. Для большинства работы, лучшие и самый rduce количества кластеров уменьшить плоские или меньше, чем уменьшить слоты кластера. Для этого небольшого кластера, это особенно важно.
Восемь, reducetask определяют степень параллельности механизма
1, job.setNumReduceTasks (число);
2, job.setReducerClass (MyReducer.class);
3, job.setPartitioonerClass (MyPTN.class);
Обсудите следующие ситуации:
1, если число 1 и 2 было установлено к пользовательскому Reducer, количество reduceTask является 1
программа MR , независимо от написания пользователя не установлен секционирования, то район сборки не будет работать
2, если номер не установлен, и 2 было установлено , чтобы настроить редуктор, число reduceTask 1 находится
под влиянием сборки разделов по умолчанию, независимо от количества , установленного пользователем, независимо от того, несколько, любое число больше 1, может выполнять все нормально а.
Если раздел при установке пользовательских компонентов, необходимо обратить внимание на:
количество , установленное вами reduceTasks должен быть ==== номер раздела максимум + 1
лучшем случае сценария: номер раздела непрерывно.
Тогда максимальное общее количество reduceTasks = номер раздела номер раздела = 1 +
3, если число> = 2 и 2 было установлено на номер заказного числа редуктора reduceTask это
основные данные по умолчанию сборочный раздел работы
4, если вы установите количество числа, но не установлен пользовательский редуктор, то программа не означает , что нет ступени редуктора MapReduce
реального редуктора логики, то для вызова класса Reducer родительского по умолчания в логике реализации: вывод
reduceTask из число является номером
5, если программа MR, не хочет этапа редуктора. Так что просто делать то , что вы можете работать:
job.setNumberReudceTasks (0),
вся программа MR только Mapper этап. Нет Редуктор стадии.
Тогда нет никакой стадии воспроизведения в случайном порядке
Влияние 91, из разметки
Во время вычислений MapReduce, иногда нужно положить конечные выходные данные в различные файлы, например, в соответствии с делением провинций, она нуждается в данных той же провинции в файле, требуются те же данные по полу в соответствии с половой разговор в файл. Мы знаем, что конечные выходные данные из Reducer задачи. Итак, если вы хотите получить более одного файл, который означает то же количество работающего Reducer задач. Данные Mapper Reducer задача от задачи, сказала Mapper задача разделить данные, присвоенные различные задачи, работающих под управлением Reducer для различных данных. Процесс Mapper данных о разделении задач называется Partition. Подразделение отвечает за реализацию типа данных под названием Разметка.
Десять, combinar роли
объединитель факт принадлежит схеме оптимизации, из-за ограничения пропускной способности, и попытаться сопоставить число передачи данных между уменьшить. На карте заканчиваются одни и те же ключевые пары значений и комбинированные вычисления, правила расчета, соответствующие уменьшения, так комбайнер может также рассматриваться как специальный редуктор.
Сумматор выполняет операции, необходимые разработчики объединитель предоставляются в программе (программа с помощью job.setCombinerClass (myCombine.class) пользовательских операций объединителя).
Объединитель компонент используется, чтобы сделать частичное резюме, она объединяется в mapTask в; Редуктор сборка используется, чтобы сделать глобальное резюме окончательного, окончательное резюме.
Одиннадцать, MapReduce в случайном порядке Комментарии
. 1, MapReduce, этап обработки данных передается на редуктор, как этап преобразователя, структура MapReduce является наиболее важным процессом, этот процесс называется случайным порядок
2, в случайном порядке: данные перетасовки - (Основной механизм: разделение данных, сортировка, частичный буфер полимеризации, тянуть, а затем сортировка слиянием)
3, а именно: результаты обработки данных является MapTask вывод, в соответствии с правилами, установленными секционирования компонентами распределенных ReduceTask, и в процессе распределения, данные разделены и отсортированы по ключу
Перемешайте процесс MapReduce введения:
Перемешайте первоначальный смысл перетасовки, перетасовки, можно преобразовать набор данных с определенным набором данных в регулярный нерегулярный, более случайный, тем лучше. MapReduce, как Перемешать перетасовки это обратный процесс, чтобы попытаться преобразовать набор случайных данных в набор данных, имеющих определенное правило.
Почему MapReduce вычислительной модели требует процесс воспроизведения в случайном порядке? Мы все знаем, MapReduce модель вычислений, как правило, включает в себя два основных этапа: Карта представляет собой отображение, фильтрацию данных отвечает за распределение; Снизить статут рассчитываются отвечают за данные слияния. Снизить данные с карты, вывод на карте, которая вводится для снижения, уменьшить необходимость получения данных по Shuffle.
Выход Карты от входа Уменьшить весь процесс может быть в широком смысле называют Перемешайте. Карта и уменьшить через Перемешать конец конец конец содержит по карте процесса разливы, и своего рода копия Уменьшить конец включает в себя способ, как показано на рисунке:
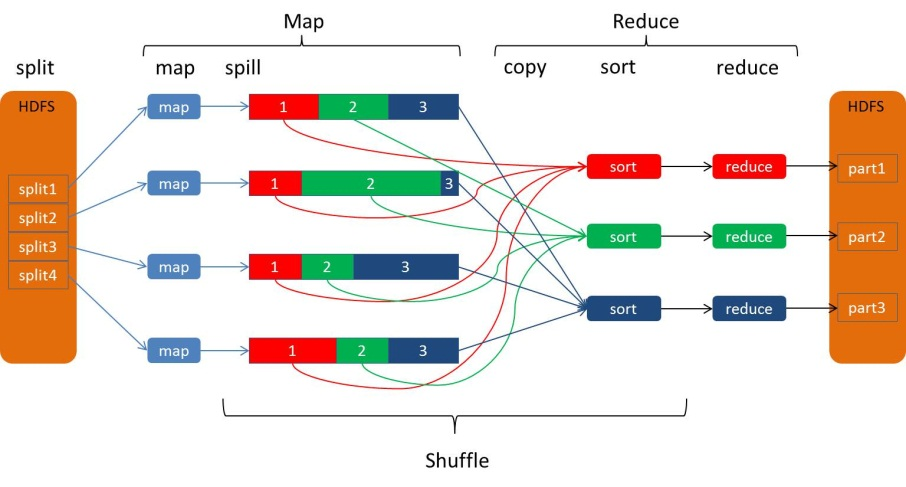
Процедура ликвидации разливов:
Процесс разлива включает в себя выход, заказ, написать переполнения, этап слияния и т.п., как показано:
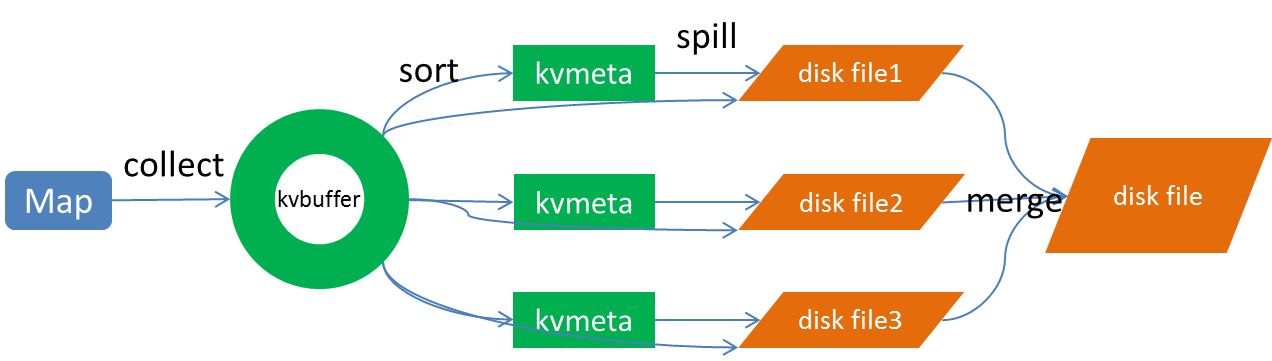
собирать
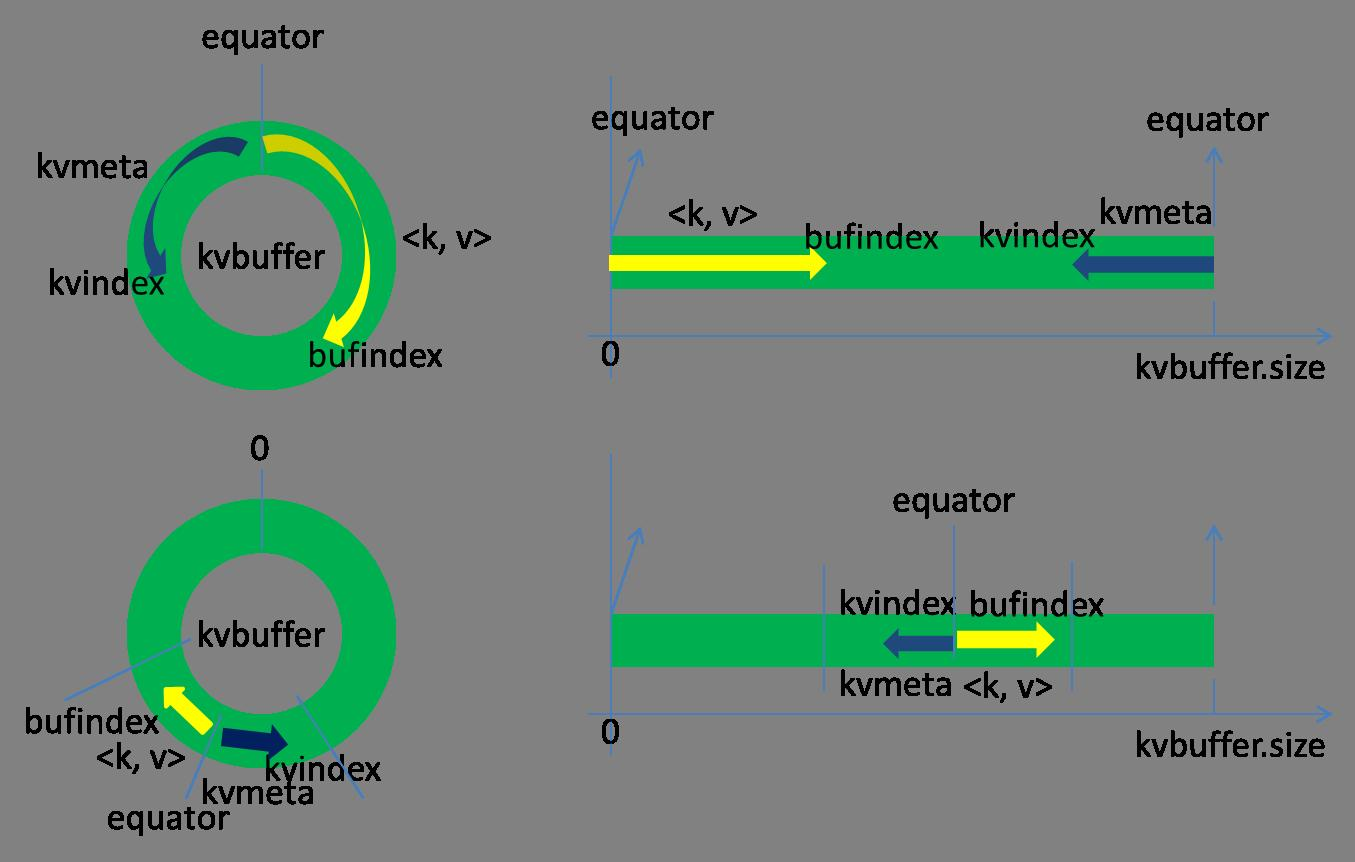
Каждая задача Карты непрерывно в виде выходных данных к кольцевой структуре данных конфигурации в памяти. Кольцевая конструкция с использованием данных с целью более эффективного использования пространства памяти, помещая столько данных в памяти.
Эта структура данных на самом деле массив байт, называемый Kvbuffer, как следует из названия справедливости, но не только поместила данных, но и поставила ряд индексных данных, индекс данные областей должны быть размещены с псевдонима в Kvmeta, в районе Kvbuffer на ношение IntBuffer (последовательность байт используется в самой платформы обратный порядок байт) жилета. область данных и область данных индекс Kvbuffer соседствует с двумя областей не перекрывает друг друга, с точкой отсечения, чтобы разделить два, точка демаркации не неизменна, но обновляется после каждого разлива. 0 начальная точка отсечки, данные, сохраненные в направлении вверх роста, направление данных индекса сохраняется растет вниз, как показано на рисунке:
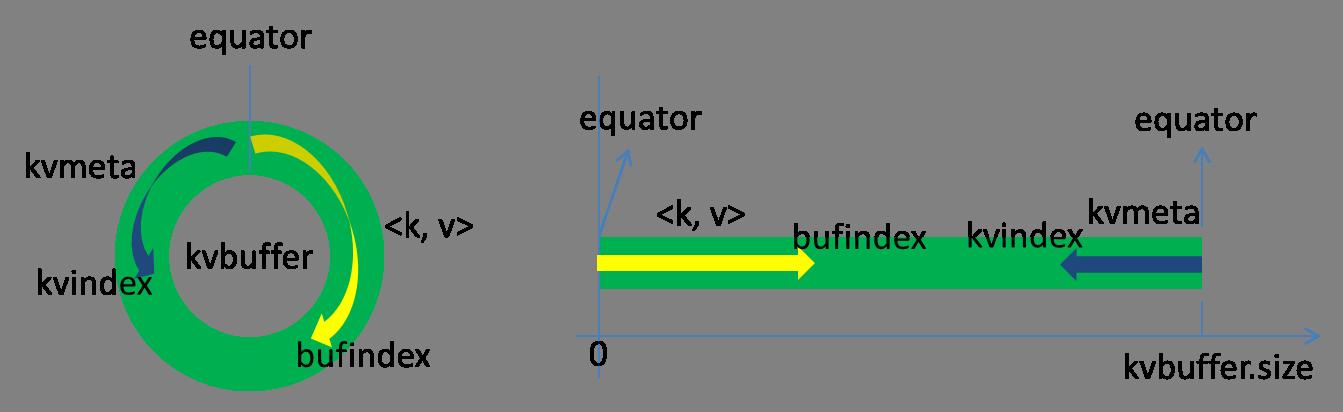
После хранения указателей Kvbuffer bufIndex имеет заложенный вверх рост головы, начальное значение 0 bufIndex Например, ключ типа Int закончен, bufIndex роста 4, внешн значение типа после отделки, 8 роста bufIndex.
索引是对在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,Kvmeta的存放指针Kvindex每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如Kvindex初始位置是-4,当第一个写完之后,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、(Kvindex+2)的位置存放partition的值、(Kvindex+3)的位置存放value的长度,然后Kvindex跳到-8位置,等第二个和索引写完之后,Kvindex跳到-32位置。
Kvbuffer的大小虽然可以通过参数设置,但是总共就那么大,和索引不断地增加,加着加着,Kvbuffer总有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把Kvbuffer中的数据刷到磁盘上的过程就叫Spill,多么明了的叫法,内存中的数据满了就自动地spill到具有更大空间的磁盘。
关于Spill触发的条件,也就是Kvbuffer用到什么程度开始Spill,还是要讲究一下的。如果把Kvbuffer用得死死得,一点缝都不剩的时候再开始Spill,那Map任务就需要等Spill完成腾出空间之后才能继续写数据;如果Kvbuffer只是满到一定程度,比如80%的时候就开始Spill,那在Spill的同时,Map任务还能继续写数据,如果Spill够快,Map可能都不需要为空闲空间而发愁。两利相衡取其大,一般选择后者。
Spill这个重要的过程是由Spill线程承担,Spill线程从Map任务接到“命令”之后就开始正式干活,干的活叫SortAndSpill,原来不仅仅是Spill,在Spill之前还有个颇具争议性的Sort。
Sort:
先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill:
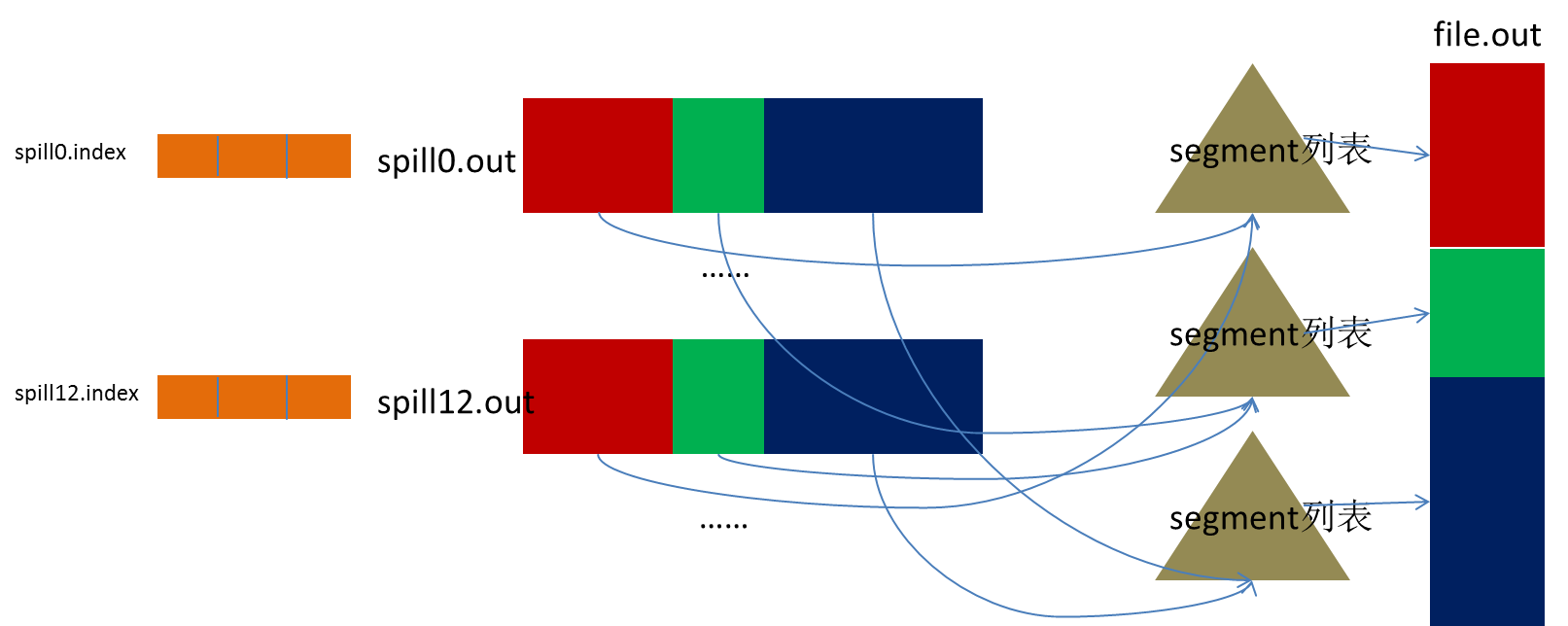
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。
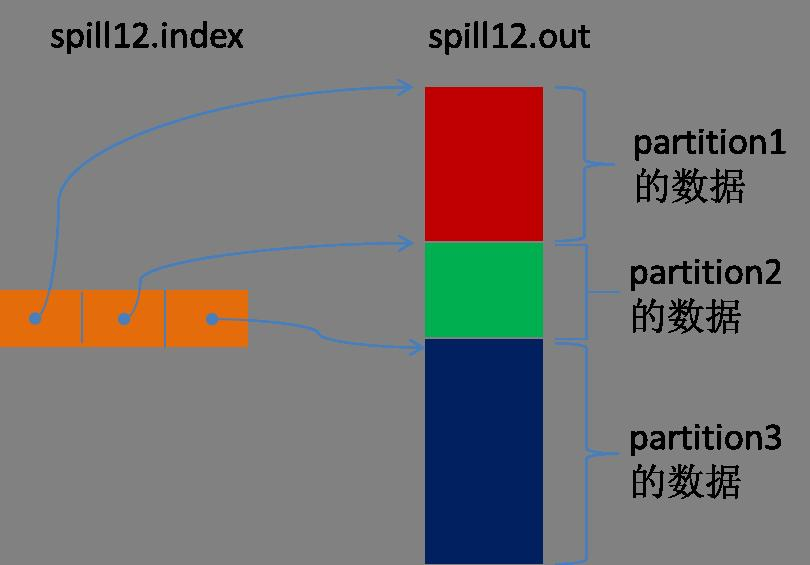
所有的partition对应的数据都放在这个文件里,虽然是顺序存放的,但是怎么直接知道某个partition在这个文件中存放的起始位置呢?强大的索引又出场了。有一个三元组记录某个partition对应的数据在这个文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。然后把这些索引信息存放在内存中,如果内存中放不下了,后续的索引信息就需要写到磁盘文件中了:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out.index”的文件,文件中不光存储了索引数据,还存储了crc32的校验数据。(spill12.out.index不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中,即使在磁盘上创建了,和spill12.out文件也不一定在同一个目录下。)
每一次Spill过程就会最少生成一个out文件,有时还会生成index文件,Spill的次数也烙印在文件名中。索引文件和数据文件的对应关系如下图所示:
在Spill线程如火如荼的进行SortAndSpill工作的同时,Map任务不会因此而停歇,而是一无既往地进行着数据输出。Map还是把数据写到kvbuffer中,那问题就来了:只顾着闷头按照bufindex指针向上增长,kvmeta只顾着按照Kvindex向下增长,是保持指针起始位置不变继续跑呢,还是另谋它路?如果保持指针起始位置不变,很快bufindex和Kvindex就碰头了,碰头之后再重新开始或者移动内存都比较麻烦,不可取。Map取kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点,bufindex指针移动到这个分界点,Kvindex移动到这个分界点的-16位置,然后两者就可以和谐地按照自己既定的轨迹放置数据了,当Spill完成,空间腾出之后,不需要做任何改动继续前进。分界点的转换如下图所示:
Map任务总要把输出的数据写到磁盘上,即使输出数据量很小在内存中全部能装得下,在最后也会把数据刷到磁盘上。
Merge
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。
Merge过程怎么知道产生的Spill文件都在哪了呢?从所有的本地目录上扫描得到产生的Spill文件,然后把路径存储在一个数组里。Merge过程又怎么知道Spill的索引信息呢?没错,也是从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里。到这里,又遇到了一个值得纳闷的地方。在之前Spill过程中的时候为什么不直接把这些信息存储在内存中呢,何必又多了这步扫描的操作?特别是Spill的索引数据,之前当内存超限之后就把数据写到磁盘,现在又要从磁盘把这些数据读出来,还是需要装到更多的内存中。之所以多此一举,是因为这时kvbuffer这个内存大户已经不再使用可以回收,有内存空间来装这些数据了。(对于内存空间较大的土豪来说,用内存来省却这两个io步骤还是值得考虑的。)
然后为merge过程创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引。
一个partition一个partition的进行合并输出。对于某个partition来说,从索引列表中查询这个partition对应的所有索引信息,每个对应一个段插入到段列表中。也就是这个partition对应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等等。
然后对这个partition对应的所有的segment进行合并,目标是合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并:先从segment列表中把第一批取出来,以key为关键字放置成最小堆,然后从最小堆中每次取出最小的输出到一个临时文件中,这样就把这一批段合并成一个临时的段,把它加回到segment列表中;再从segment列表中把第二批取出来合并输出到一个临时segment,把其加入到列表中;这样往复执行,直到剩下的段是一批,输出到最终的文件中。
最终的索引数据仍然输出到Index文件中。
Map端的Shuffle过程到此结束。
Copy:
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。每个节点都会启动一个常驻的HTTP server,其中一项服务就是响应Reduce拖取Map数据。当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出文件中对应这个Reduce部分的数据通过网络流输出给Reduce。
Reduce任务拖取某个Map对应的数据,如果在内存中能放得下这次数据的话就直接把数据写到内存中。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中。
如果在内存中不能放得下这个Map的数据的话,直接把Map数据写到磁盘上,在本地目录创建一个文件,从HTTP流中读取数据然后写到磁盘,使用的缓存区大小是64K。拖一个Map数据过来就会创建一个文件,当文件数量达到一定阈值时,开始启动磁盘文件merge,把这些文件合并输出到一个文件。
有些Map的数据较小是可以放在内存中的,有些Map的数据较大需要放在磁盘上,这样最后Reduce任务拖过来的数据有些放在内存中了有些放在磁盘上,最后会对这些来一个全局合并。
Merge Sort:
这里使用的Merge和Map端使用的Merge过程一样。Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。
Reduce端的Shuffle过程至此结束。