Первый модуль импорта файлов
импорт панды как э.р.
1, свойство DataFrame
DF = pd.DataFrame ( данные = { " имя " : [ " ZS " , " Ls " , " WW " , " ZL " ], " возраст " : [18, 19, 29, 11 ], " оценка " : [ 92,5, 93, 97, 65 ] }, индекс = [ " stu_1 " , " stu_2 " , " stu_3 ", "stu_4 " ] )
Создание ФР
В пеленгации и пеленгации виды печати , чтобы увидеть:

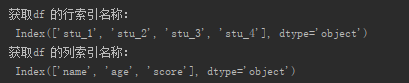
(1) Df индексированного свойства
Print ( " получить ф.р. имя индекса строки: \ n- " , df.index) Печать ( " получить ф.р. имя индекса столбца: \ n- " , df.columns)
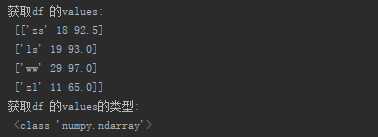
(2) значения DF собственности
Print ( " прибудет ФР значений: \ n- " , df.values) Print ( " получить Df типов значений: \ n- " , типа (df.values))
(3) атрибуты формы DF и габариты
Печать ( " Получить ф.р. форму: \ n- " , df.shape) Print ( " Get размер ДФ: \ n- " , df.ndim)

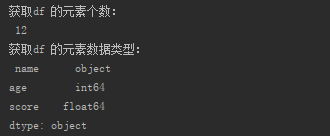
(4) DF число элементов и типов элементов данных,
Печать ( " Получить количество элементов ДФ: \ n- " , df.size) Print ( " Получение данных типа элемента ДФ: \ n- " , df.dtypes)
2, файл операции панды
(1) Использование read_table () метод, чтобы прочитать файл
= Информация pd.read_table ( filepath_or_buffer = " ./meal_order_info.csv " , на сентябрь = " " , заголовок = " Infer " , # Автоматическая идентификация # заголовок = None, не указывайте имя столбца # # заголовок = 0, # 0 обозначены имя индекса строка занимает кодирующий = " ANSI " , # index_col = 0 устанавливаются в индексе первой строки 0 # имя # Nrows = 3, # usecols = [0, 1], # имена = [ "01", "07" ], вы можете создавать свои собственные имена столбцов # # usecols = [ "info_id", "emp_id"] )
CSV - файл: запятая « » является разделителем текстового файла, filepath_or_buffer : имя путь + файл файл, на сентябрь / DELIMITER : разделители, заголовок = «Infer» : Автоматический индекс идентификации имен столбцов, имена : можно указать само имя столбца, index_col : Вы можете указать , какие столбцы, столбцы имя в качестве индекса строки, usecol : может получить свой собственный заданный столбец, кодирующие : кодирование настройки, Nrows : можно указать количество строк , читаемые
(2) с использованием read_csv () метод, чтобы прочитать файл
Информация = pd.read_csv ( " ./meal_order_info.csv " , кодирование = " ANSI " )
Параметры Ссылочных конкретных read_table () метод
(3) с использованием read_excel () метод, чтобы прочитать файл
= Пользователи pd.read_excel ( " ./users.xlsx " , SheetName = 0, parse_cols = [0 ,. 1], # в некоторых версиях работы )
Использование read_excel () метод читает первенствовать файл ( .xlsx , * .xls конец), параметр 1 : путь + имя файла, SheetName : номер таблицы, index_col : который можно указать столбец, в котором столбцы в качестве имени индекса строки, parse_cols : считывает указанный столбец
(4) использование to_csv () метод для сохранения файла
info.to_csv ( " ./info_save.csv " , индекс = False, режим = " " )
Информация: DataFrame переменные, индекс : сохранять ли индекс, из режима : режим экономии