PaddlePaddle学习之使用PaddleDetection在树莓派4B进行模型部署(一)— 项目环境搭建
PaddlePaddle学习之使用PaddleDetection在树莓派4B进行模型部署(二)— 深度学习模型训练
PaddlePaddle学习之使用PaddleDetection在树莓派4B进行模型部署(三)— 树莓派4B部署
此项目已公开,包括数据集在内已经打包上传,欢迎Fork!传送门:Paddle_ssd_mobilenet_v1_pascalvoc
本文将使用ssd_mobilenet_v1_voc算法,以一个例子说明,如何利用paddleDetection完成一个项目----从准备数据集到完成树莓派部署,项目用到的工具是百度的AI Studio在线AI开发平台和树莓派4B
全部资料已经都打包在这里(PaddleDetection、Paddle-Lite-Demo、Paddle-Lite、opt)↓
链接:https://pan.baidu.com/s/1IKT-ByVN9BaVxfqQC1VaMw
提取码:mdd1
数据集准备
本项目是用的数据集格式是VOC格式,标注工具为labelimg,图像数据是手动拍摄获取。

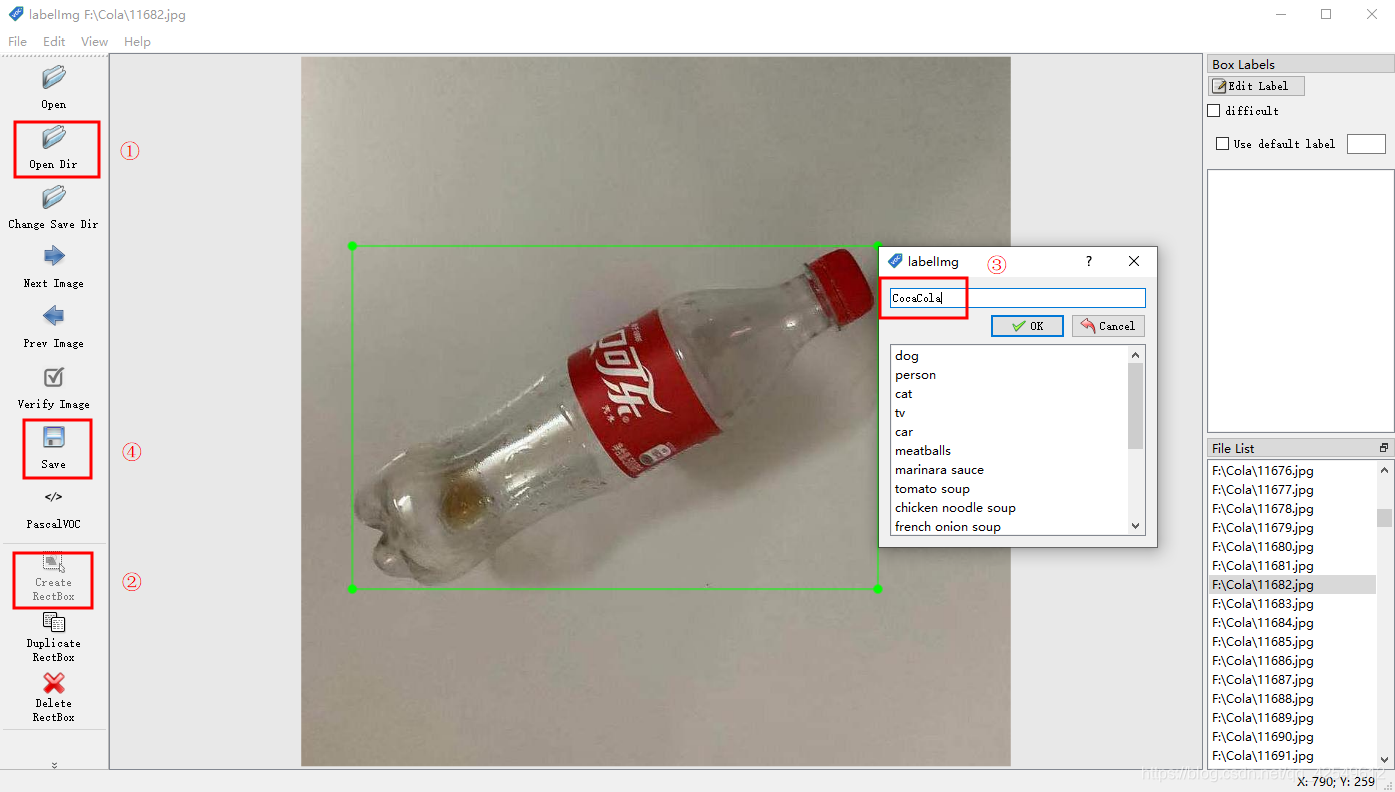
数据标注:
- 点击Open Dir,打开文件夹,载入图片
- 点击Create RectBox,即可在图像上画框标注
- 输入标签,点击OK
- 点击Save保存,保存下来的是XML文件
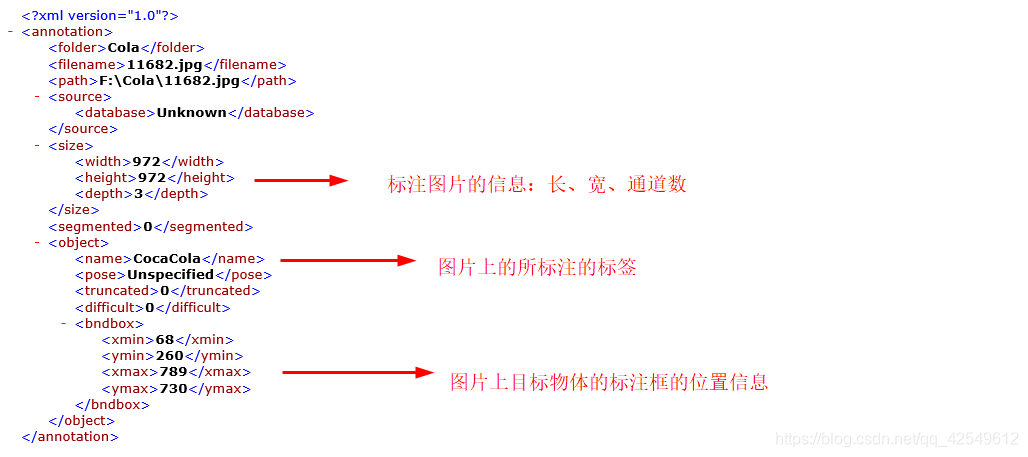
XML文件内容如下
整理成VOC格式的数据集:
创建三个文件夹:Annotations、ImageSets、JPEGImages

将标注生成的XML文件存入Annotations,图片存入JPEGImages,训练集、测试集、验证集的划分情况存入ImageSets。
在ImageSets下创建一个Main文件夹,并且在Mian文件夹下建立label_list.txt,里面存入标注的标签。
此label_list.txt文件复制一份与Annotations、ImageSets、JPEGImages同级位置放置。
其内容如下:

运行该代码将会生成trainval.txt、train.txt、val.txt、test.txt,将我们标注的600张图像按照训练集、验证集、测试集的形式做一个划分。
import os
import random
trainval_percent = 0.95 #训练集验证集总占比
train_percent = 0.9 #训练集在trainval_percent里的train占比
xmlfilepath = 'F:/Cola/Annotations'
txtsavepath = 'F:/Cola/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('F:/Cola/ImageSets/Main/trainval.txt', 'w')
ftest = open('F:/Cola/ImageSets/Main/test.txt', 'w')
ftrain = open('F:/Cola/ImageSets/Main/train.txt', 'w')
fval = open('F:/Cola/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
以下代码可根据在Main文件夹中划分好的数据集进行位置索引,生成含有图像及对应的XML文件的地址信息的文件。
import os
import re
import random
devkit_dir = './'
output_dir = './'
def get_dir(devkit_dir, type):
return os.path.join(devkit_dir, type)
def walk_dir(devkit_dir):
filelist_dir = get_dir(devkit_dir, 'ImageSets/Main')
annotation_dir = get_dir(devkit_dir, 'Annotations')
img_dir = get_dir(devkit_dir, 'JPEGImages')
trainval_list = []
train_list = []
val_list = []
test_list = []
added = set()
for _, _, files in os.walk(filelist_dir):
for fname in files:
print(fname)
img_ann_list = []
if re.match('trainval.txt', fname):
img_ann_list = trainval_list
elif re.match('train.txt', fname):
img_ann_list = train_list
elif re.match('val.txt', fname):
img_ann_list = val_list
elif re.match('test.txt', fname):
img_ann_list = test_list
else:
continue
fpath = os.path.join(filelist_dir, fname)
for line in open(fpath):
name_prefix = line.strip().split()[0]
print(name_prefix)
added.add(name_prefix)
#ann_path = os.path.join(annotation_dir, name_prefix + '.xml')
ann_path = annotation_dir + '/' + name_prefix + '.xml'
print(ann_path)
#img_path = os.path.join(img_dir, name_prefix + '.jpg')
img_path = img_dir + '/' + name_prefix + '.jpg'
assert os.path.isfile(ann_path), 'file %s not found.' % ann_path
assert os.path.isfile(img_path), 'file %s not found.' % img_path
img_ann_list.append((img_path, ann_path))
print(img_ann_list)
return trainval_list, train_list, val_list, test_list
def prepare_filelist(devkit_dir, output_dir):
trainval_list = []
train_list = []
val_list = []
test_list = []
trainval, train, val, test = walk_dir(devkit_dir)
trainval_list.extend(trainval)
train_list.extend(train)
val_list.extend(val)
test_list.extend(test)
#print(trainval)
with open(os.path.join(output_dir, 'trainval.txt'), 'w') as ftrainval:
for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'train.txt'), 'w') as ftrain:
for item in train_list:
ftrain.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'val.txt'), 'w') as fval:
for item in val_list:
fval.write(item[0] + ' ' + item[1] + '\n')
with open(os.path.join(output_dir, 'test.txt'), 'w') as ftest:
for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')
if __name__ == '__main__':
prepare_filelist(devkit_dir, output_dir)
最终创建完成的VOC数据集如下:
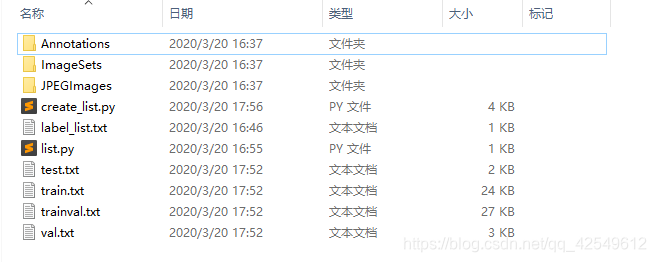
将整个文件拷贝至 ./PaddleDetection/dataset/voc 下
以上全部完成后,还需要修改两个地方,ssd_mobilenet_v1_voc源码中是以20类目标为准设计的,本项目的目标仅为两类
- 找到 ./PaddleDetection/configs/ssd/ssd_mobilenet_v1_voc.yml文件,修改第12行的num_classes,3代表2个标签加一个背景
# 2(label_class) + 1(background)
num_classes: 3
- 找到 ./PaddleDetection/ppdet/data/source/voc.py文件,修改167行的pascalvoc_label()函数,按照前面设定的label_list.txt文件里的标签顺序依次修改,并将多余的内容删掉
def pascalvoc_label(with_background=True):
labels_map = {
'PepsiCola': 1,
'CocaCola': 2
}
if not with_background:
labels_map = {k: v - 1 for k, v in labels_map.items()}
return labels_map
至此,整个数据集制作及配置完成。
创建项目
进入AI Studio创建项目

确认创建项目前,需要将数据集添加进去,点击创建数据集,将第一步做好的“PaddleDetection”整个文件夹压缩打包上传。
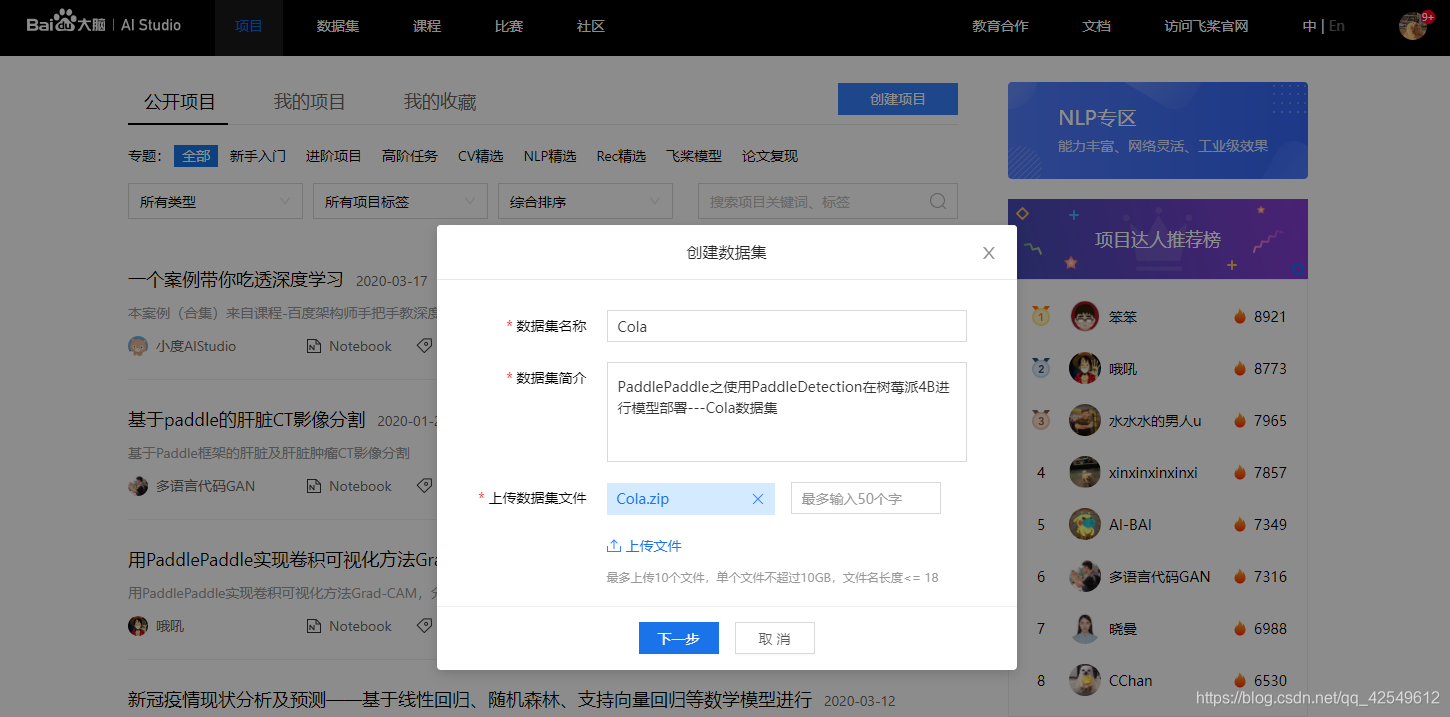
至此,创建项目完成。
