通过前面几个小节的学习,现在我们想要把之前学到的知识点给串联起来,实现一个很小型的Web框架。虽然很小,但是用到的知识点都是比较多的。如Socket编程,装饰器传参在实际项目中如何使用。通过这一节的学习,希望能把我们以前的知识点掌握的更加牢靠!
一、客户端与服务器通信过程
在这里我们以浏览器来说明访问服务器时,会做什么处理!
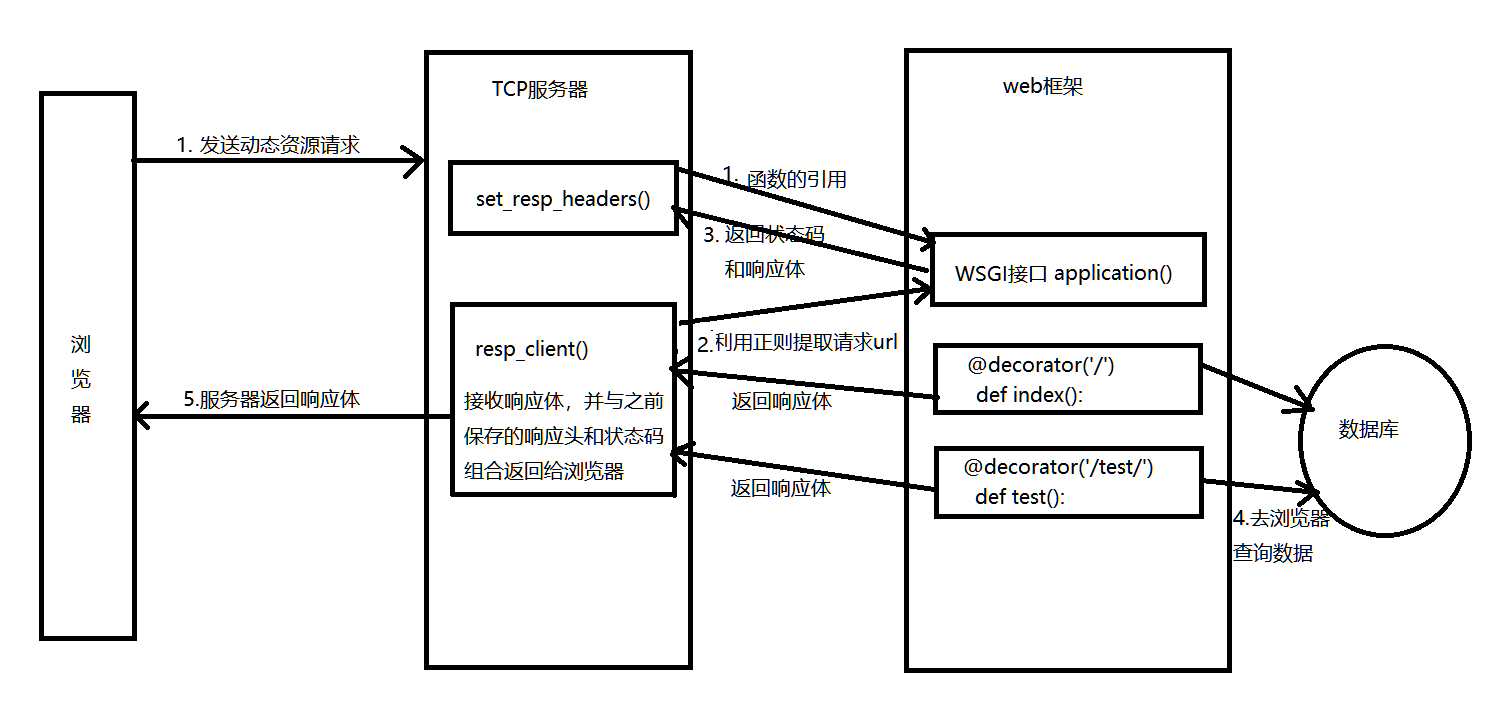
说明:
TCP服务器:
1. 服务器主要是用来处理客户端的连接请求,然后把请求的url,传递给框架来处理具体的逻辑;
2. 服务器中需要定义一个处理响应头和状态码的函数,并作为参数传递给web框架的接口;
3. 服务器与web框架之间的通信主要是通过WSGI协议提供的接口,这样他们各司其职,耦合度很低
web框架:
在框架中需要解决的难题:
如何把url与相应的函数建立起关联?
浏览器发送不同的请求需要被不同的函数截取,并返回响应体。通过装饰器传递参数的方式就可以把url与函数建立对应关系。装饰器中的参数就是用来匹配url的。
二、代码实现
服务器端:
1 import logging
2 import socket
3 import select
4 import re
5
6
7 import wsgi_web
8
9
10 logging.basicConfig(level=logging.WARNING,
11 filename='./web框架日志.txt',
12 filemode='w',
13 format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
14
15
16 class WebServer:
17 """创建一个Web服务器"""
18 def __init__(self):
19 # 1.创建tcp socket
20 self.tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
21 # 2.设置地址可重用
22 self.tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
23 # 3.绑定到某个端口
24 self.tcp_socket.bind(('', 6060))
25 # 4.设置监听队列
26 self.tcp_socket.listen(128)
27
28 def run(self):
29 """运行服务器"""
30 # 1.设置tcp_socket为非阻塞状态
31 self.tcp_socket.setblocking(False)
32 # 2.创建epoll对象,并注册服务器的监听事件
33 epoll = select.epoll()
34 epoll.register(self.tcp_socket.fileno(), select.EPOLLIN)
35 client_dict = dict()
36 # 3.不断遍历epoll列表,检查fd上有无事件发生
37 while True:
38 epoll_list = epoll.poll()
39 for fd, event in epoll_list:
40 if fd == self.tcp_socket.fileno():
41 # 有客户端来连接服务器
42 client_socket, client_addr = self.tcp_socket.accept()
43 # 注册客户端的事件
44 epoll.register(client_socket.fileno(), select.EPOLLIN)
45 # 客户端与其fd要建立关联
46 client_dict[client_socket.fileno()] = client_socket
47 else:
48 # 说明客户端发送数据过来
49 # 通过fd来处理客户端的请求
50 self.response_client(fd, client_dict, epoll)
51
52 def response_client(self, client_fd, client_dict, epoll):
53 """处理客户端的请求"""
54 try:
55 req_heads = client_dict[client_fd].recv(1024).decode('utf-8')
56 except Exception as e:
57 logging.warning(e)
58 if not req_heads:
59 # 1.关闭客户端
60 client_dict[client_fd].close()
61 # 2.从监听队列中移除该客户端
62 client_dict.popitem()
63 # 3.取消该客户端的注册事件
64 epoll.unregister(client_fd)
65
66 try:
67 # print(req_heads.splitlines()[0])
68 # 1.解析客户端的请求url
69 match = re.match(r'[^/]+(/[^ ]*)', req_heads.splitlines()[0])
70 if match:
71 # 匹配成功
72 filename = match.group(1)
73 if filename == '/':
74 filename = '/index.html'
75 except Exception as e:
76 logging.warning(e)
77 # print('匹配数据出现了错误:{}'.format(e))
78 # 2.根据文件名去动态加载,然后伪装成静态页面发送
79 if filename.endswith('.html'):
80 url_params = dict()
81 # 1.使用WSGI接口
82 # 通过不同文件构造一个字典
83 url_params['filename'] = filename
84 # print(url_params)
85 # 定义一个函数传给框架
86 body = wsgi_web.application(url_params, self.resp_heads)
87 # 2.拼接数据然后发送给浏览器
88 # 构造响应头信息
89 # 空行
90 # 响应体
91 resp_head = 'HTTP/1.1 %s\r\n'%self.status_code
92 for field in self.resp_fields:
93 # 设置Content-Length的长度
94 resp_head += '%s:%s\r\n'%(field[0], field[1] if field[0] != 'Content-Length' else len(body.encode('utf-8')))
95 content = resp_head + '\r\n' + body
96 client_dict[client_fd].send(content.encode('utf-8'))
97 else:
98 # 返回静态数据
99 try:
100 f = open('./static%s'%filename, 'rb')
101 except Exception as e:
102 # 读取失败
103 body = 'Sorry! File not found!'
104 resp_head = 'HTTP/1.1 404 Not Found\r\n'
105 resp_head += 'Content-Length:%d\r\n'% len(body)
106 resp_head += '\r\n'
107 content = resp_head + body
108 client_dict[client_fd].send(content.encode('utf-8'))
109 # print('读取文件失败!')
110 logging.warning(e)
111 else:
112 # 读取成功
113 body = f.read()
114 resp_head = 'HTTP/1.1 200 OK\r\n'
115 resp_head += 'Content-Length:%d\r\n' % len(body)
116 resp_head += '\r\n'
117 try:
118 client_dict[client_fd].send(resp_head.encode('utf-8'))
119 client_dict[client_fd].send(body)
120 except Exception as e:
121 logging.warning(e)
122
123 def resp_heads(self, status_code, fields):
124 """在框架中使用的函数,框架用来返回响应头信息"""
125 self.status_code = status_code
126 self.resp_fields = fields
127
128
129 def main():
130 """程序入口"""
131 # 1.初始化服务器
132 server = WebServer()
133 # 2.运行服务器
134 server.run()
135
136
137 if __name__ == '__main__':
138 main()
框架部分:
1 # 服务器给数据,返回数据给服务器
2 import re
3 from urllib.request import unquote #解码中文,只用在浏览器自动对中文编码
4
5 import DBHelper
6
7 # 定义空字典,用来存储路径跟对应的函数引用
8 url_dict = dict()
9
10 # start_response框架给服务器传响应头的数据
11 # environ获取服务器传过来的文件路径
12 def application(environ, start_response):
13 """返回具体展示的界面给服务器"""
14 start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8'),
15 ('Content-Length', '')]) # 返回响应头
16
17 # 根据不同的地址进行判断
18 file_name = environ['filename']
19 for key, func in url_dict.items():
20 match = re.match(key, file_name) # 地址跟规则一致
21 if match:
22 # 匹配到了
23 return func(match) # 调用匹配到的函数引用,返回匹配的页面内容
24 else:
25 # 说明没找到
26 return"不好意思,页面走丢了!"
27
28
29 # 装饰器传参,用来完成路由的功能
30 def route(url_address): # url_address表示页面的路径
31 """目的自动添加路径跟匹配的函数到url字典中"""
32 def set_fun(func):
33 def call_fun(*args, **kwargs):
34 return func(*args, **kwargs)
35 # 根据不同的函数名称去添加到字典中
36 url_dict[url_address] = call_fun
37 return call_fun
38 return set_fun