0.Task总体概览
1.载入数据科学必备库
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
from scipy.special import jn
from IPython.display import display , clear_output
import time
warnings.filterwarnings('ignore')
%matplotlib inline
#模型预测
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
from sklearn.decomposition import PCA, FastICA, FactorAnalysis, SparsePCA
#数据降维
#笔记本安装xgboost失败,台式机安装成功,先不管
import lightgbm as lgb
#import xgboost as xgb
#参数搜索和评价
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
2.载入数据
①载入数据
#数据来源,阿里云
Train_data = pd.read_csv('C:/ml_data/tianchi/used_car_train_20200313.csv',sep = ' ')
Test_data = pd.read_csv('C:/ml_data/tianchi/used_car_testA_20200313.csv',sep = ' ')
②简单观察数据
#如果数据载入错了,可以第一时间发现
.shape()查看数据形状
print("Train_data_shape:",Train_data.shape)
print("Test_data_shape:",Test_data.shape)
Train_data_shape: (150000, 31)
Test_data_shape: (50000, 30)
.head()查看头5个数据信息
Train_data.head()

使用.head()和.shape()这两个功能没有什么大的作用,基本上就是为了防止载入错数据。一步错则步步错。
3.总体数据概览
#了解一下数据的大致情况
①.describe()查看统计数值特征
Train_data.describe()
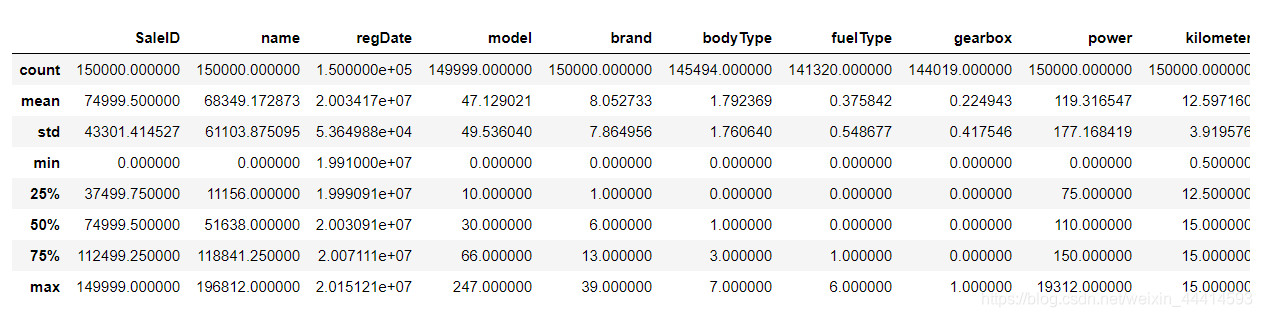
可以看到数据的count(数量),mean(均值),std(标准差),min(最小值),max(最大值),25%,50%,75%(排序)。同时也可以看到有些特征存在着缺失(count<150000)。
②.info()查看数据的数据结构
Train_data.info()

这里可以看到数值使用的数据结构,更容易看到缺失的数据。
4.缺失值和异常值的处理
① .isnull().sum()查看缺失值的总体情况
Train_data.isnull().sum()
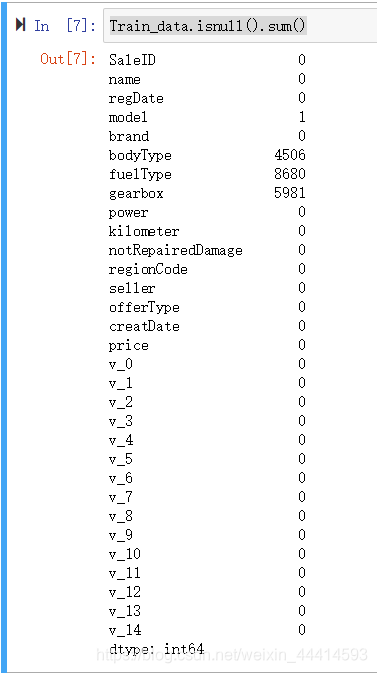
训练集中主要是bodytype,fueltype,gearbox这三个特征存在大量缺失,model仅缺失一项数据。
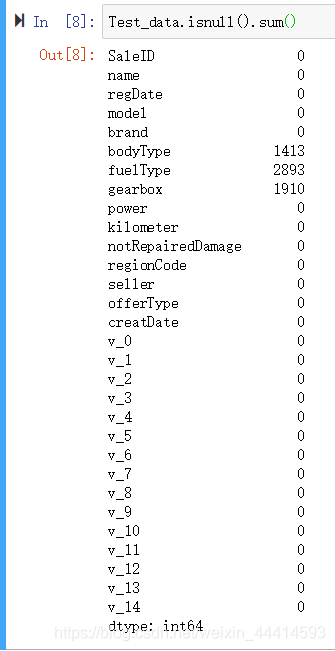
测试集数据缺失情况与训练集基本一致。
②缺失数据可视化
train_missing = Train_data.isnull().sum()
train_missing = train_missing [train_missing > 0]
train_missing.sort_values(inplace = True)
train_missing.plot.bar()
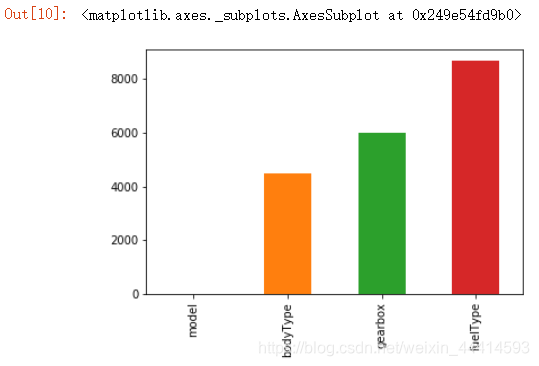
sort_values() 使用方法:pandas sort_values使用方法
缺失值处理建议:缺失值较少时,一般直接填充,使用lgb等树模型即可;缺失值较多则需要考虑删除数据。
这里本来以为缺失值只集中在这三种属性,但是又发现一些东西。在之前的.info()中查看数据结构,除了notRepairedDamage其他特征都是int类型,然而notRepairedDamage是object类型。
③.value_counts()查看特征大致数值
Train_data['notRepairedDamage'].value_counts()
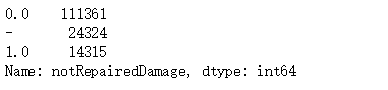
可以看到其中有很多的 ‘-’,因为很多模型会把nan替换成’-’,我们将它反向替换回来。
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
Test_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
此时再看看缺失值
Train_data.isnull().sum()

这才是缺失值的庐山真面目。
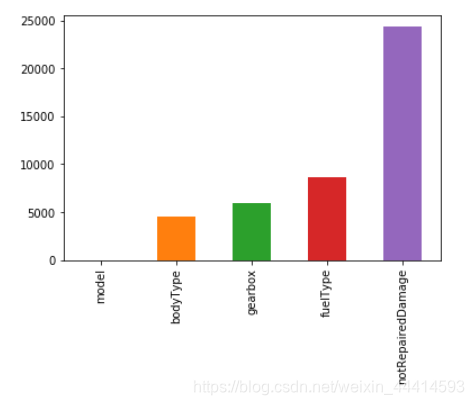
④删除不必要的特征
Train_data["seller"].value_counts()

Train_data["offerType"].value_counts()
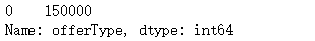
我们可以看到,这两个特征数值没有变化,对回归没有任何作用,还占用计算资源,所以直接删掉。
del Train_data["seller"]
del Train_data["offerType"]
del Test_data["seller"]
del Test_data["offerType"]
此时最好将删除无用特征的数据保存成csv文件,下次运行时直接read最好,可以节省内存和时间。
5.了解预测值分布
#知己知彼,百战不殆。
直接可视化price的分布。
y = Train_data['price']
sns.distplot(y,kde=False)
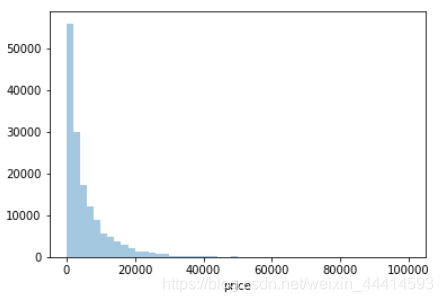
畸形的正态分布。
将其与各种分布拟合一下。
plt.figure(1);plt.title('Johnson SU')
sns.distplot(y,kde=False,fit=st.johnsonsu)
plt.figure(2);plt.title('Normal')
sns.distplot(y,kde=False,fit=st.norm)
plt.figure(3);plt.title('Log Normal')
sns.distplot(y,kde=False,fit=st.lognorm)
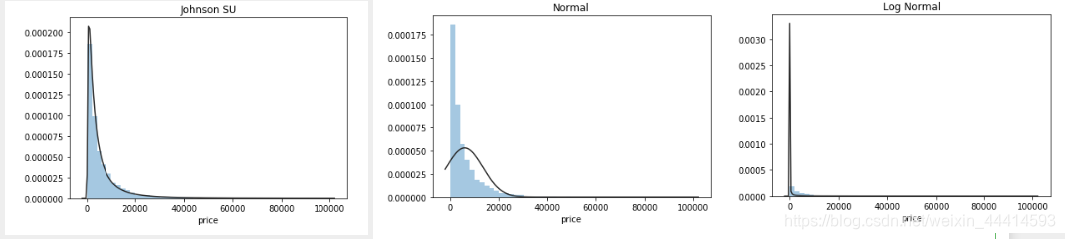
最佳拟合是Johnson分布。
我们喜欢正态分布的数据,此时我们可以查看一下数据对于正态分布的偏度和峰度。偏度:数据对于正态分布,是像左向偏离(负值)还是右向偏离(正值)。峰度:数据对于正态分布,是更高更尖了(正值),还是更矮更挫了(负值)。矮穷矬没有未来!详细的介绍请见该博文。高富帅与矮穷矬
sns.distplot(y)
print('y.skewness:%f'%y.skew())
print(('y.Kurtosis: %f'%y.kurt()))
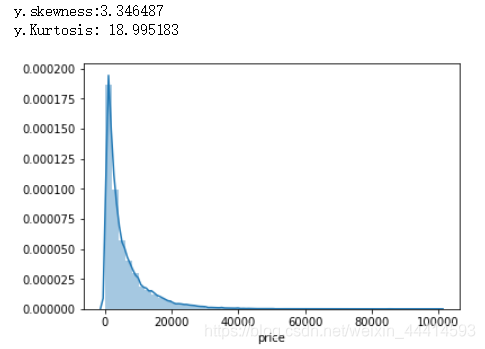
看图发现数据分布右向偏离严重,相应的偏度是正值;数据比常规的正态分布高(尖)的多,相应的峰值是正值。
同时也可以看到price中绝大部分的数值是在0~20000之间的,极小部分的数值大于20000.用柱状图感受一下。
plt.hist(y)
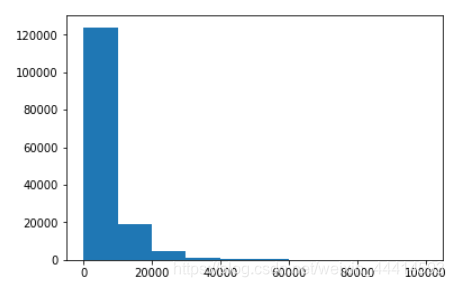
temp = len(y)
temp_count = 0
for i in y:
if i <= 20000:
temp_count += 1
print(' total : ',len(y),'\n number of below 20000 : ',temp_count)
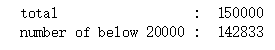
可见共有142833/150000项数据小于20000.在本例中,可以将大于20000的数据当成异常值处理,使用填充或者删除的方式处理(后续处理)。
对price进行log变换。
plt.hist(np.log(y))
log变换后比较符合正态分布,此时查看变换后的偏度和峰度。
y=np.log(y)
sns.distplot(y)
print('y.skewness:%f'%y.skew())
print(('y.Kurtosis: %f'%y.kurt()))
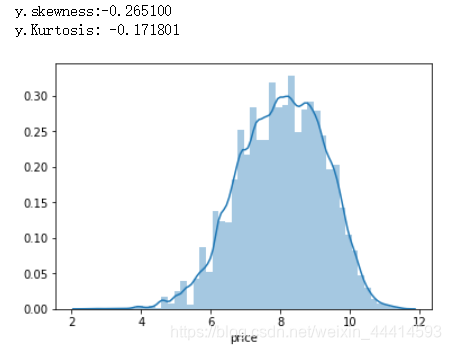
偏度和峰度都比较接近0了,从图像上看也比较符合正态分布了。这种变换方法是预测问题常用的技巧。目前这种技巧能带来什么收益我也不太懂,先记下。就像拉普拉斯变换,前期真是不懂,但是人家很NB,不服不行。
6.特征值分为:数字特征 + 类别特征
数字特征比较容易理解,简单的说就是纯数字意义的特征。比如说身高,体重,价格,公里数等。这些数字的值对特征工程存在很重要的意义,例如判断人是否健康身高体重很有意义,二手车价格来说,公里数越大,价格相应的也会偏低。
另外一些特征则不然。例如判定人健康指标中,性别不能用字符串’male’和’female’表示,通常使用数字0和1代替;二手车的品牌也不能用’Tesla’和’BWM’等,通常使用数字编码代替。这些特征的数值并没有实际意义,仅用来区分。这些特征称之为类别特征。
这两种特征需要区别对待。这两种特征是基于人类理解所分类的,深度学习是人类无法理解的,所以深度学习时,可以不分类。
本例中的数字特征和类别特征如下。
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
7.数字特征分析
数字特征加上price
numeric_features.append('price')
再看看各个特征对于price的相关性
price_numeric = Train_data[numeric_features]
corr = price_numeric.corr()
print(corr['price'].sort_values(ascending=False))

各个特征之间互相的相关性也可以看到。
print(corr)

原图底下还有,不截了。我们使用seaborn的heatmap将其可视化一下。
sns.heatmap(corr,square = True, vmax=0.8)
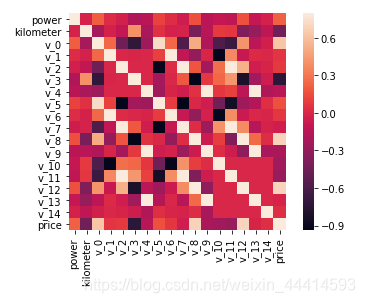
关于seaborn的heatmap使用方法,可以参考这篇博文。heatmap
可视化各个数字特征的分布。
del price_numeric['price']
f = pd.melt(Train_data,value_vars=numeric_features)
g =sns.FacetGrid(f,col='variable',col_wrap=2,sharex=False,sharey=False)
g =g.map(sns.distplot,'value')
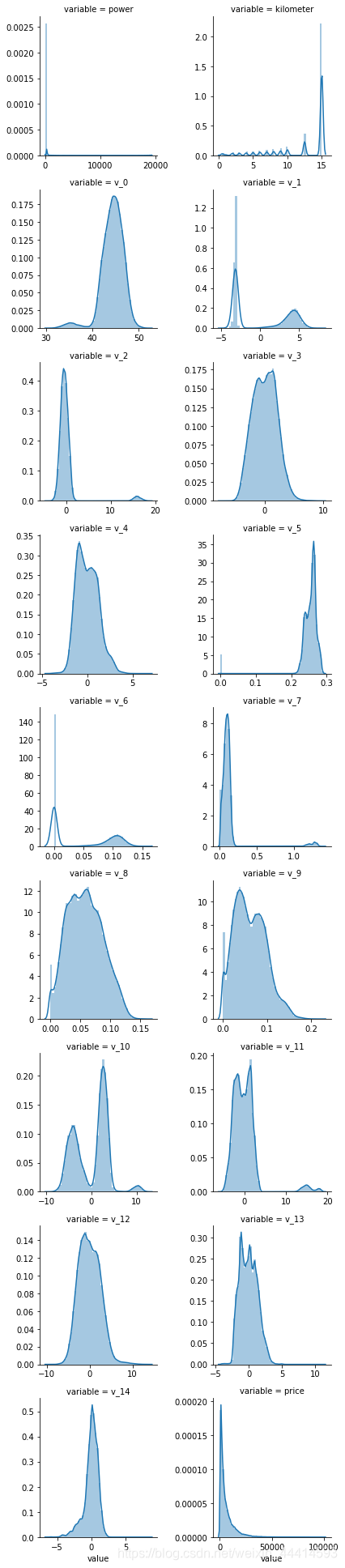
各个变量两两之间的可视化
sns.set()
colums = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
sns.pairplot(Train_data[colums],size=2,kind='scatter',diag_kind='kde')
plt.show(())

这种两两变量关系可视化的方法可以方便的看出互相之间的影响。有的两两变量之间是近似线性关系,有的是近似正态分布,有的是互相之间没有影响等等。
Learn more:pairplot
8.类别特征分析
与数字特征方法一样,这里不重复工作了。
9.使用pandas_profiling生成数据报告
未完待续。
