本文参考:https://zhuanlan.zhihu.com/p/410587234
本章主要内容如下:
- 序列填充
- 预训练词嵌入
- LSTM
- 双向 RNN
- 多层 RNN
- 正则化
- 优化
1.准备数据
首先设置seed,并将其分类训练、测试、验证集。
注意:由于 RNN 只能处理序列中的非 padded 元素(即非0数据),对于任何 padded 元素输出都是 0 。所以在准备数据的时候将include_length设置为True,以获得句子的实际长度。
import torch
from torchtext.legacy import data
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize = 'spacy',
tokenizer_language = 'en_core_web_sm',
include_lengths = True)
LABEL = data.LabelField(dtype = torch.float)加载数据
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)从训练集中选取部分做验证集
import random
train_data, valid_data = train_data.split(random_state = random.seed(SEED))2. 词向量
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)接下来,使用预训练词向量进行初始化操作,其中获取这些词向量是通过指定参数传递给 build_vocab 得到的。
本文使用的是 "glove.6B.100d" ,其中,6B表示词向量是在60亿规模的tokens上训练得到的,100d表示词向量是100维的。
理论上,预训练词向量在词嵌入向量空间中的距离在一定程度上表征了词之间的语义关系,例如,“terrible”、“awful”、“dreadful” ,它们的词嵌入向量空间的距离会非常近。
TEXT.build_vocab表示从预训练的词向量中,将当前训练数据中的词汇的词向量抽取出来,构成当前训练集的 Vocab(词汇表)。对于当前词向量语料库中没有出现的单词(记为UNK),通过高斯分布随机初始化(unk_init = torch.Tensor.normal)。
3. 创建迭代器+选取GPU
BATCH_SIZE = 64
# 根据当前环境选择是否调用GPU进行训练
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建数据迭代器
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)4. 构建模型
LSTM
LSTM是标准RNN的一种变体,它增加了一种携带信息跨越多个时间步的方法,一定程度上克服了标准的RNN存在梯度消失的问题。 具体来说,LSTM加入记忆单元 ,其可看作是LSTM的“内存”,存储了 时刻LSTM的记忆,可以认为其中保存了从过去到 时刻的所有必要信息,同时使用多个门控制信息流入和流出内存,具体地看此处。 因此我们可以将LSTM看作是 、 和 的函数,而不仅仅是
和
。
因此,使用LSTM的模型结构看起来类似下面这种构造(省略了嵌入层):
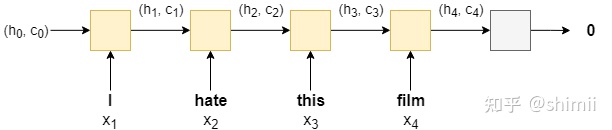
与初始隐藏状态一样,初始记忆状态 初始化为全零张量。需要注意的是,情感预测只使用最终隐藏状态,而不是最终记忆单元状态,即 ̂ = ( )。
双向RNN
双向RNN在之前的标准RNN层上添加了一个反方向处理的RNN层。然后,拼接各个时刻的两个RNN层的隐藏状态,将其作为最后的隐藏状态向量。也就是在时间步 时,前向RNN处理单词 ,后向RNN处理单词 。通过这样的双向处理,每个单词对应的隐藏状态可以从左右两个方向聚集信息,这样一来,这些向量就编码了更均衡的信息。
我们使用前向RNN的最后一个隐藏状态(从句子的最后一个单词获得) 和后向RNN的最后一个隐藏状态(从句子的第一个单词获得) 进行情感预测,即 ̂ = ,下图显示了一个双向RNN,前向RNN为橙色,后向RNN为绿色,线性层为银色。

多层RNN
多层RNN(也称为深层RNN):在初始标准RNN上多加几层RNN。第一个(底部)RNN在时间步 时输出的隐藏状态将是在时间步 时其上方RNN的输入,然后根据最终(最高)层的最终隐藏状态进行预测。下图显示了多层单向RNN,其中层号以上标形式给出。还要注意,每个层都需要自己的初始隐藏状态, 。
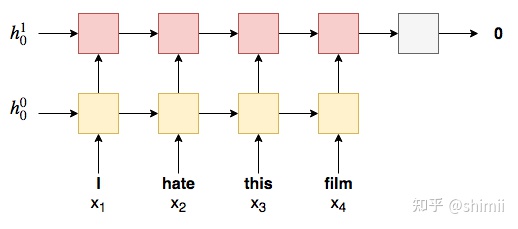
正则化
我们已经对模型进行了各方面的改进,但是我们需要注意的是,当模型的参数逐渐增加的同时,模型过拟合的可能性就越大。为了解决这个问题,我们添加dropout正则化。Dropout的工作原理是在前向传播过程中,层中的神经元随机Dropout(设置为0)。每个神经元是否被drop的概率则由一个超参数设置,并不受其他神经元影响。
关于为什么dropout有效的一种理论是,参数dropout的模型可以被视为“weaker”(参数较少)的模型。因此,最终的模型可以被认为是所有这些weaker模型的集合,这些模型都没有过度参数化,因此降低了过拟合的可能性。
Implementation Details
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
# embedding嵌入层(词向量)
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
# RNN变体——双向LSTM
self.rnn = nn.LSTM(embedding_dim, # input_size
hidden_dim, #output_size
num_layers=n_layers, # 层数
bidirectional=bidirectional, #是否双向
dropout=dropout) #随机去除神经元
# 线性连接层
self.fc = nn.Linear(hidden_dim * 2, output_dim) # 因为前向传播+后向传播有两个hidden sate,且合并在一起,所以乘以2
# 随机去除神经元
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
#text 的形状 [sent len, batch size]
embedded = self.dropout(self.embedding(text))
#embedded 的形状 [sent len, batch size, emb dim]
# pack sequence
# lengths need to be on CPU!
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.to('cpu'))
packed_output, (hidden, cell) = self.rnn(packed_embedded)
#unpack sequence
output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
#output的形状[sent len, batch size, hid dim * num directions]
#output中的 padding tokens是数值为0的张量
#hidden 的形状 [num layers * num directions, batch size, hid dim]
#cell 的形状 [num layers * num directions, batch size, hid dim]
#concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers
#and apply dropout
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
#hidden 的形状 [batch size, hid dim * num directions]
return self.fc(hidden)- 针对模型训练过程中的一点补充:在模型训练过程中,对于每个样本中补齐后加上的pad token,模型是不应该对其进行训练的,也就是并不会学习“<pad>”标记的嵌入。因为padding token跟句子的情感是无关的。这就意味着pad token的嵌入层(词向量)会一直保持初始化的状态(初始化为全零)。具体而言,我们是通过往nn.Embedding 层传入pad token 的index索引,作为padding_idx参数。
- 因为Bi-LSTM的包含了前向传播和后向传播过程,所以最后的隐藏状态向量包含了前向和后向的隐藏状态,所以在下一层nn.Linear层中的输入的形状就是隐藏层维度形状的两倍。
- 在将embeddings(词向量)输入RNN前,我们需要借助
nn.utils.rnn.packed_padded_sequence将它们‘打包’,以此来保证RNN只会处理不是pad的token。我们得到的输出包括packed_output(a packed sequence)以及hidden sate和cell state。如果没有进行‘打包’操作,那么输出的hidden state和cell state大概率是来自句子的pad token。如果使用packed padded sentences,输出的就会是最后一个非padded元素的hidden state和cell state。 - 之后我们借助
nn.utils.rnn.pad_packed_sequence将输出的句子‘解压’转换成一个tensor张量。需要注意的是来自padding tokens的输出是零张量,通常情况下,我们只有在后续的模型中使用输出时才需要‘解压’。虽然在本案例中下不需要,这里只是为展示其步骤。 - final hidden sate:也就是hidden,其形状是[num layers * num directions, batch size, hid dim]。因为我们只要最后的前向和后向传播的hidden states,我们只要最后2个hidden layers就行hidden[-2,:,:] 和hidden[-1,:,:],然后将他们合并在一起,再传入线性层linear layer。
5. 实例化模型+传入参数
为了保证pre-trained 词向量可以加载到模型中,EMBEDDING_DIM 必须等于预训练的GloVe词向量的大小。
INPUT_DIM = len(TEXT.vocab) # 250002: 之前设置的只取25000个最频繁的词,加上pad_token和unknown token
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] #指定参数,定义pad_token的index索引值,让模型不管pad token
model = RNN(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)查看模型参数量
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')接下来,把前面加载好的预训练词向量复制进我们模型中的embedding嵌入层,用预训练的embeddings词向量替换掉原来模型初始化的权重参数。
我们从字段的vocab中检索嵌入,并检查它们的大小是否正确,[vocab size, embedding dim]
pretrained_embeddings = TEXT.vocab.vectors
# 检查词向量形状 [vocab size, embedding dim]
print(pretrained_embeddings.shape)
# 用预训练的embedding词向量替换原始模型初始化的权重参数
model.embedding.weight.data.copy_(pretrained_embeddings)因为我们的<unk> 和<pad> token不在预训练词表里,它们已经在构建我们自己的词表时,使用 unk_init (一个0-1标准分布)初始化了。所以,最好显式地告诉模型,将它们初始化变为0,它们与情感无关。
我们是通过手动设置他们的词向量权重为0的。
注意:与初始化嵌入一样,这应该在“weight.data”而不是“weight”上完成!
#将unknown 和padding token设置为0
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data)我们现在可以看到嵌入权重矩阵的前两行值都是0,需要注意的是,pad token的词向量在模型训练过程中始终不会被学习。而unknown token的词向量是会被学习的。
6. 训练模型
将随机梯度下降优化器从'SGD'更改为'Adam'。SGD使用我们设定好的学习率同步更新所有参数,而Adam会调整每个参数的学习率,给出更新频率更高的参数,以及更新频率更低的参数和更新频率不高的参数。有关“Adam”(和其他优化器)的更多信息,请参见此处。
要将'SGD'更改为'Adam',我们只需将'optim.SGD'更改为'optim.Adam',还要注意,我们不提供 Adam初始学习率,因为PyTorch提供了默认的初始学习率。
6.1 设置优化器
import torch.optim as optim
optimizer = optim.Adam(model.parameters())6.2 设置损失函数和GPU
训练模型的其它步骤保持不变。
criterion = nn.BCEWithLogitsLoss() # 损失函数. criterion 在本task中时损失函数的意思
model = model.to(device)
criterion = criterion.to(device)6.3 计算精确度
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc6.4 定义一个训练函数,用来训练模型
正如我们设置的“include_length=True”,我们的“batch.text”现在是一个元组,第一个元素是数字张量,第二个元素是每个序列的实际长度。在将它们传递给模型之前,我们将它们分成各自的变量“text”和“text_length”。
注意:因为现在使用的是dropout,我们必须记住使用model.train()以确保在训练时开启 dropout。
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad() # 梯度清零
text, text_lengths = batch.text # batch.text返回的是一个元组(数字化的张量,每个句子的长度)
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)6.5 定义一个测试函数
注意:因为现在使用的是dropout,我们必须记住使用model.eval()以确保在评估时关闭 dropout。
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
text, text_lengths = batch.text #batch.text返回的是一个元组(数字化的张量,每个句子的长度)
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)6.6 正式训练模型
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# 保留最好的训练结果的那个模型参数,之后加载这个进行预测
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut2-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')6.7 最终测试结果
model.load_state_dict(torch.load('tut2-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')7. 模型验证
我们现在可以使用这个模型来预测我们给出的任何句子的情感了,注意需要提供的句子是电影评论方面的。
当使用模型进行实际预测时,模型要始终在evaluation mode评估模式。
“predict_sentiment”函数的作用如下:
- 将模型切换为evaluate模式
- 对句子进行分词操作
- 将分词后的每个词,对应着词汇表,转换成对应的index索引,
- 获取句子的长度
- 将indexes,从list转化成tensor
- 通过unsqueezing 添加一个batch维度
- 将length转化成张量tensor
- 用sigmoid函数将预测值压缩到0-1之间
- 用item()方法,将只有一个值的张量tensor转化成整数
负面评论返回接近0的值,正面评论返回接近1的值。
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
length = [len(indexed)]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
length_tensor = torch.LongTensor(length)
prediction = torch.sigmoid(model(tensor, length_tensor))
return prediction.item()负面评论的例子:
predict_sentiment(model, "This film is terrible")正面评论的例子:
predict_sentiment(model, "This film is great")