3.4 滑动窗口的卷积实现(Convolutional implementation of sliding windows)
上节课,我们学习了如何通过卷积网络实现滑动窗口对象检测算法,但效率很低。这节课我们讲讲如何在卷积层上应用这个算法。
为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层。我们先讲解这部分内容,下一张幻灯片,我们将按照这个思路来演示卷积的应用过程。
假设对象检测算法输入一个14×14×3的图像,图像很小,不过演示起来方便。在这里过滤器大小为5×5,数量是16,14×14×3的图像在过滤器处理之后映射为10×10×16。然后通过参数为2×2的最大池化操作,图像减小到5×5×16。然后添加一个连接400个单元的全连接层,接着再添加一个全连接层,最后通过softmax单元输出。为了跟下图区分开,我先做一点改动,用4个数字来表示,它们分别对应softmax单元所输出的4个分类出现的概率。这4个分类可以是行人、汽车、摩托车和背景或其它对象。
现在我要演示的就是如何把这些全连接层转化为卷积层,画一个这样的卷积网络,它的前几层和之前的一样,而对于下一层,也就是这个全连接层,我们可以用5×5的过滤器来实现,数量是400个(编号1所示),输入图像大小为5×5×16,用5×5的过滤器对它进行卷积操作,过滤器实际上是5×5×16,因为在卷积过程中,过滤器会遍历这16个通道,所以这两处的通道数量必须保持一致,输出结果为1×1。假设应用400个这样的5×5×16过滤器,输出维度就是1×1×400,我们不再把它看作一个含有400个节点的集合,而是一个1×1×400的输出层。从数学角度看,它和全连接层是一样的,因为这400个节点中每个节点都有一个5×5×16维度的过滤器,所以每个值都是上一层这些5×5×16激活值经过某个任意线性函数的输出结果。
我们再添加另外一个卷积层(编号2所示),这里用的是1×1卷积,假设有400个1×1的过滤器,在这400个过滤器的作用下,下一层的维度是1×1×400,它其实就是上个网络中的这一全连接层。最后经由1×1过滤器的处理,得到一个softmax激活值,通过卷积网络,我们最终得到这个1×1×4的输出层,而不是这4个数字(编号3所示)。
以上就是用卷积层代替全连接层的过程,结果这几个单元集变成了1×1×400和1×1×4的维度。
参考论文:Sermanet, Pierre, et al. "OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks." Eprint Arxiv (2013).
掌握了卷积知识,我们再看看如何通过卷积实现滑动窗口对象检测算法。讲义中的内容借鉴了屏幕下方这篇关于OverFeat的论文,它的作者包括Pierre Sermanet,David Eigen,张翔,Michael Mathieu,Rob Fergus,Yann LeCun。

假设向滑动窗口卷积网络输入14×14×3的图片,为了简化演示和计算过程,这里我们依然用14×14的小图片。和前面一样,神经网络最后的输出层,即softmax单元的输出是1×1×4,我画得比较简单,严格来说,14×14×3应该是一个长方体,第二个10×10×16也是一个长方体,但为了方便,我只画了正面。所以,对于1×1×400的这个输出层,我也只画了它1×1的那一面,所以这里显示的都是平面图,而不是3D图像。
假设输入给卷积网络的图片大小是14×14×3,测试集图片是16×16×3,现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络(红色笔标记)生成0或1分类。接着滑动窗口,步幅为2个像素,向右滑动2个像素,将这个绿框区域输入给卷积网络,运行整个卷积网络,得到另外一个标签0或1。继续将这个橘色区域输入给卷积网络,卷积后得到另一个标签,最后对右下方的紫色区域进行最后一次卷积操作。我们在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签。
结果发现,这4次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这4次前向传播过程中共享很多计算,尤其是在这一步操作中(编号1),卷积网络运行同样的参数,使得相同的5×5×16过滤器进行卷积操作,得到12×12×16的输出层。然后执行同样的最大池化(编号2),输出结果6×6×16。照旧应用400个5×5的过滤器(编号3),得到一个2×2×400的输出层,现在输出层为2×2×400,而不是1×1×400。应用1×1过滤器(编号4)得到另一个2×2×400的输出层。再做一次全连接的操作(编号5),最终得到2×2×4的输出层,而不是1×1×4。最终,在输出层这4个子方块中,蓝色的是图像左上部分14×14的输出(红色箭头标识),右上角方块是图像右上部分(绿色箭头标识)的对应输出,左下角方块是输入层左下角(橘色箭头标识),也就是这个14×14区域经过卷积网络处理后的结果,同样,右下角这个方块是卷积网络处理输入层右下角14×14区域(紫色箭头标识)的结果。
如果你想了解具体的计算步骤,以绿色方块为例,假设你剪切出这块区域(编号1),传递给卷积网络,第一层的激活值就是这块区域(编号2),最大池化后的下一层的激活值是这块区域(编号3),这块区域对应着后面几层输出的右上角方块(编号4,5,6)。
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个4个14×14的方块一样。
下面我们再看一个更大的图片样本,假如对一个28×28×3的图片应用滑动窗口操作,如果以同样的方式运行前向传播,最后得到8×8×4的结果。跟上一个范例一样,以14×14区域滑动窗口,首先在这个区域应用滑动窗口,其结果对应输出层的左上角部分。接着以大小为2的步幅不断地向右移动窗口,直到第8个单元格,得到输出层的第一行。然后向图片下方移动,最终输出这个8×8×4的结果。因为最大池化参数为2,相当于以大小为2的步幅在原始图片上应用神经网络。
总结一下滑动窗口的实现过程,在图片上剪切出一块区域,假设它的大小是14×14,把它输入到卷积网络。继续输入下一块区域,大小同样是14×14,重复操作,直到某个区域识别到汽车。
但是正如在前一页所看到的,我们不能依靠连续的卷积操作来识别图片中的汽车,比如,我们可以对大小为28×28的整张图片进行卷积操作,一次得到所有预测值,如果足够幸运,神经网络便可以识别出汽车的位置。
以上就是在卷积层上应用滑动窗口算法的内容,它提高了整个算法的效率。不过这种算法仍然存在一个缺点,就是边界框的位置可能不够准确。下节课,我们将学习如何解决这个问题。
3.5 Bounding Box预测(Bounding box predictions)
在上一个视频中,你们学到了滑动窗口法的卷积实现,这个算法效率更高,但仍然存在问题,不能输出最精准的边界框。在这个视频中,我们看看如何得到更精准的边界框。
在滑动窗口法中,你取这些离散的位置集合,然后在它们上运行分类器,在这种情况下,这些边界框没有一个能完美匹配汽车位置,也许这个框(编号1)是最匹配的了。还有看起来这个真实值,最完美的边界框甚至不是方形,稍微有点长方形(红色方框所示),长宽比有点向水平方向延伸,有没有办法让这个算法输出更精准的边界框呢?
其中一个能得到更精准边界框的算法是YOLO算法,YOLO(You only look once)意思是你只看一次,这是由Joseph Redmon,Santosh Divvala,Ross Girshick和Ali Farhadi提出的算法。
是这么做的,比如你的输入图像是100×100的,然后在图像上放一个网格。为了介绍起来简单一些,我用3×3网格,实际实现时会用更精细的网格,可能是19×19。基本思路是使用图像分类和定位算法,前几个视频介绍过的,然后将算法应用到9个格子上。(基本思路是,采用图像分类和定位算法,本周第一个视频中介绍过的,逐一应用在图像的9个格子中。)更具体一点,你需要这样定义训练标签,所以对于9个格子中的每一个指定一个标签y,y是8维的,和你之前看到的一样,
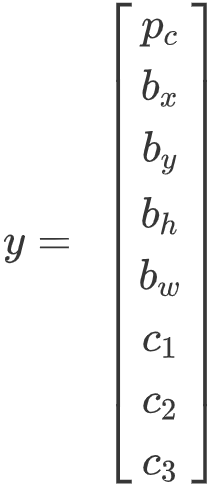 ,
,![]() 等于0或1取决于这个绿色格子中是否有图像。然后
等于0或1取决于这个绿色格子中是否有图像。然后作用就是,如果那个格子里有对象,那么就给出边界框坐标。然后
就是你想要识别的三个类别,背景类别不算,所以你尝试在背景类别中识别行人、汽车和摩托车,那么
可以是行人、汽车和摩托车类别。这张图里有9个格子,所以对于每个格子都有这么一个向量。
我们看看左上方格子,这里这个(编号1),里面什么也没有,所以左上格子的标签向量y是
![]() 。然后这个格子(编号2)的输出标签y也是一样,这个格子(编号3),还有其他什么也没有的格子都一样。
。然后这个格子(编号2)的输出标签y也是一样,这个格子(编号3),还有其他什么也没有的格子都一样。
现在这个格子呢?讲的更具体一点,这张图有两个对象,YOLO算法做的就是,取两个对象的中点,然后将这个对象分配给包含对象中点的格子。所以左边的汽车就分配到这个格子上(编号4),然后这辆Condor(车型:神鹰)中点在这里,分配给这个格子(编号6)。所以即使中心格子(编号5)同时有两辆车的一部分,我们就假装中心格子没有任何我们感兴趣的对象,所以对于中心格子,分类标签y和这个向量类似,和这个没有对象的向量类似,即
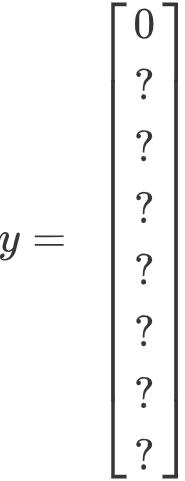 。而对于这个格子,这个用绿色框起来的格子(编号4),目标标签就是这样的,这里有一个对象
。而对于这个格子,这个用绿色框起来的格子(编号4),目标标签就是这样的,这里有一个对象![]() ,,然后你写出
,,然后你写出![]() 来指定边界框位置,然后还有类别1是行人,那么
来指定边界框位置,然后还有类别1是行人,那么![]() ,类别2是汽车,所以
,类别2是汽车,所以![]() ,类别3是摩托车,则数值
,类别3是摩托车,则数值![]() ,即
,即
 。右边这个格子(编号6)也是类似的,因为这里确实有一个对象,它的向量应该是这个样子的
。右边这个格子(编号6)也是类似的,因为这里确实有一个对象,它的向量应该是这个样子的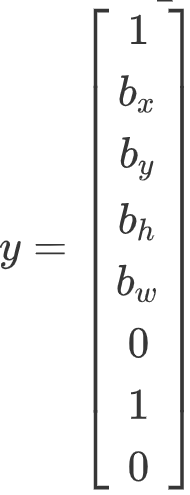 ,作为目标向量对应右边的格子。
,作为目标向量对应右边的格子。
所以对于这里9个格子中任何一个,你都会得到一个8维输出向量,因为这里是3×3的网格,所以有9个格子,总的输出尺寸是3×3×8,所以目标输出是3×3×8。因为这里有3×3格子,然后对于每个格子,你都有一个8维向量y,所以目标输出尺寸是3×3×8。
对于这个例子中,左上格子是1×1×8,对应的是9个格子中左上格子的输出向量。所以对于这3×3中每一个位置而言,对于这9个格子,每个都对应一个8维输出目标向量y,其中一些值可以是dont care-s(即?),如果这里没有对象的话。所以总的目标输出,这个图片的输出标签尺寸就是3×3×8。
如果你现在要训练一个输入为100×100×3的神经网络,现在这是输入图像,然后你有一个普通的卷积网络,卷积层,最大池化层等等,最后你会有这个,选择卷积层和最大池化层,这样最后就映射到一个3×3×8输出尺寸。所以你要做的是,有一个输入x,就是这样的输入图像,然后你有这些3×3×8的目标标签y。当你用反向传播训练神经网络时,将任意输入x映射到这类输出向量y。
所以这个算法的优点在于神经网络可以输出精确的边界框,所以测试的时候,你做的是喂入输入图像x,然后跑正向传播,直到你得到这个输出y。然后对于这里3×3位置对应的9个输出,我们在输出中展示过的,你就可以读出1或0(编号1位置),你就知道9个位置之一有个对象。如果那里有个对象,那个对象是什么(编号3位置),还有格子中这个对象的边界框是什么(编号2位置)。只要每个格子中对象数目没有超过1个,这个算法应该是没问题的。一个格子中存在多个对象的问题,我们稍后再讨论。但实践中,我们这里用的是比较小的3×3网格,实践中你可能会使用更精细的19×19网格,所以输出就是19×19×8。这样的网格精细得多,那么多个对象分配到同一个格子得概率就小得多。
重申一下,把对象分配到一个格子的过程是,你观察对象的中点,然后将这个对象分配到其中点所在的格子,所以即使对象可以横跨多个格子,也只会被分配到9个格子其中之一,就是3×3网络的其中一个格子,或者19×19网络的其中一个格子。在19×19网格中,两个对象的中点(图中蓝色点所示)处于同一个格子的概率就会更低。
所以要注意,首先这和图像分类和定位算法非常像,我们在本周第一节课讲过的,就是它显式地输出边界框坐标,所以这能让神经网络输出边界框,可以具有任意宽高比,并且能输出更精确的坐标,不会受到滑动窗口分类器的步长大小限制。其次,这是一个卷积实现,你并没有在3×3网格上跑9次算法,或者,如果你用的是19×19的网格,19平方是361次,所以你不需要让同一个算法跑361次。相反,这是单次卷积实现,但你使用了一个卷积网络,有很多共享计算步骤,在处理这3×3计算中很多计算步骤是共享的,或者你的19×19的网格,所以这个算法效率很高。
事实上YOLO算法有一个好处,也是它受欢迎的原因,因为这是一个卷积实现,实际上它的运行速度非常快,可以达到实时识别。在结束之前我还想给你们分享一个小细节,如何编码这些边界框![]() ,我们在下一张幻灯片上讨论。
,我们在下一张幻灯片上讨论。
这里有两辆车,我们有个3×3网格,我们以右边的车为例(编号1),红色格子里有个对象,所以目标标签y就是,![]() ,然后
,然后![]() ,然后
,然后![]() 即
即
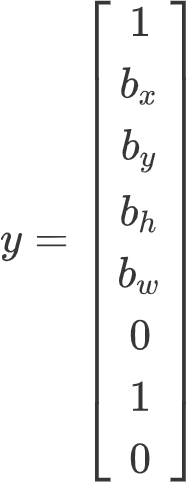 。你怎么指定这个边界框呢?
。你怎么指定这个边界框呢?
Specify the bounding boxes:


这就是YOLO算法,你只看一次算法,在接下来的几个视频中,我会告诉你一些其他的思路可以让这个算法做的更好。在此期间,如果你感兴趣,也可以看看YOLO的论文,在前几张幻灯片底部引用的YOLO论文。
Redmon, Joseph, et al. "You Only Look Once: Unified, Real-Time Object Detection." (2015):779-788.
不过看这些论文之前,先给你们提个醒,YOLO论文是相对难度较高的论文之一,我记得我第一次读这篇论文的时候,我真的很难搞清楚到底是怎么实现的,我最后问了一些我认识的研究员,看看他们能不能给我讲清楚,即使是他们,也很难理解这篇论文的一些细节。所以如果你看论文的时候,发现看不懂,这是没问题的,我希望这种场合出现的概率要更低才好,但实际上,即使是资深研究员也有读不懂研究论文的时候,必须去读源代码,或者联系作者之类的才能弄清楚这些算法的细节。但你们不要被我吓到,你们可以自己看看这些论文,如果你们感兴趣的话,但这篇论文相对较难。现在你们了解了YOLO算法的基础,我们继续讨论别的让这个算法效果更好的研究。
3.6 交并比(Intersection over union)
你如何判断对象检测算法运作良好呢?在本视频中,你将了解到并交比函数,可以用来评价对象检测算法。在下一个视频中,我们用它来插入一个分量来进一步改善检测算法,我们开始吧。
在对象检测任务中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏?所以交并比(loU)函数做的是计算两个边界框交集和并集之比。两个边界框的并集是这个区域,就是属于包含两个边界框区域(绿色阴影表示区域),而交集就是这个比较小的区域(橙色阴影表示区域),那么交并比就是交集的大小,这个橙色阴影面积,然后除以绿色阴影的并集面积。
一般约定,在计算机检测任务中,如果![]() ,就说检测正确,如果预测器和实际边界框完美重叠,loU就是1,因为交集就等于并集。但一般来说只要
,就说检测正确,如果预测器和实际边界框完美重叠,loU就是1,因为交集就等于并集。但一般来说只要![]() ,那么结果是可以接受的,看起来还可以。一般约定,0.5是阈值,用来判断预测的边界框是否正确。一般是这么约定,但如果你希望更严格一点,你可以将loU定得更高,比如说大于0.6或者更大的数字,但loU越高,边界框越精确。
,那么结果是可以接受的,看起来还可以。一般约定,0.5是阈值,用来判断预测的边界框是否正确。一般是这么约定,但如果你希望更严格一点,你可以将loU定得更高,比如说大于0.6或者更大的数字,但loU越高,边界框越精确。
所以这是衡量定位精确度的一种方式,你只需要统计算法正确检测和定位对象的次数,你就可以用这样的定义判断对象定位是否准确。再次,0.5是人为约定,没有特别深的理论依据,如果你想更严格一点,可以把阈值定为0.6。有时我看到更严格的标准,比如0.6甚至0.7,但很少见到有人将阈值降到0.5以下。
人们定义loU这个概念是为了评价你的对象定位算法是否精准,但更一般地说,loU衡量了两个边界框重叠地相对大小。如果你有两个边界框,你可以计算交集,计算并集,然后求两个数值的比值,所以这也可以判断两个边界框是否相似,我们将在下一个视频中再次用到这个函数,当我们讨论非最大值抑制时再次用到。
好,这就是loU,或者说交并比,不要和借据中提到的我欠你钱的这个概念所混淆,如果你借钱给别人,他们会写给你一个借据,说:“我欠你这么多钱(I own you this much money)。”,这也叫做loU。这是完全不同的概念,这两个概念重名。
现在介绍了loU交并比的定义之后,在下一个视频中,我想讨论非最大值抑制,这个工具可以让YOLO算法输出效果更好,我们下一个视频继续。
