首先打开spss软件,在菜单栏"文件"中导入相关数据文件
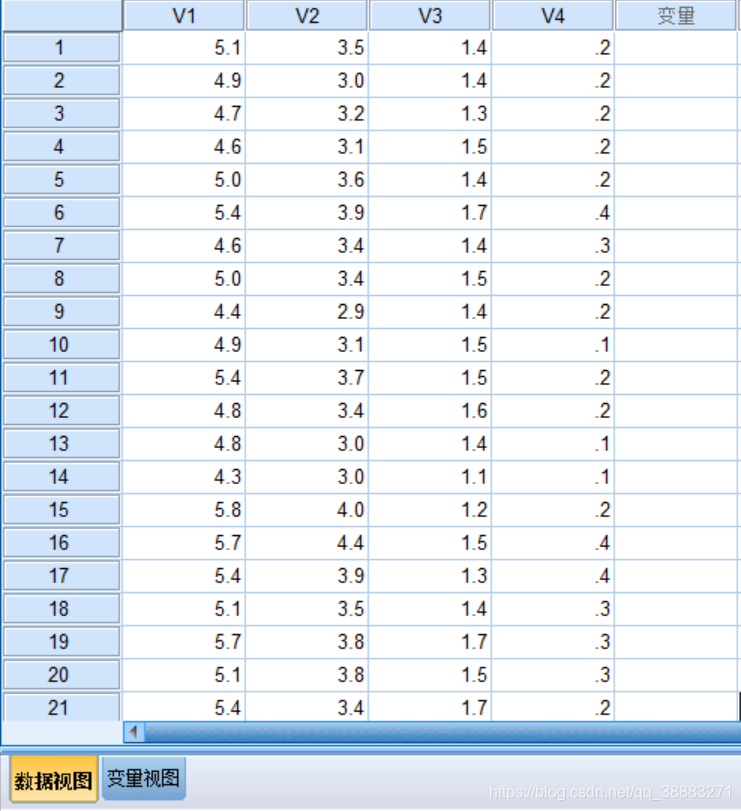
导入的数据如下所示:
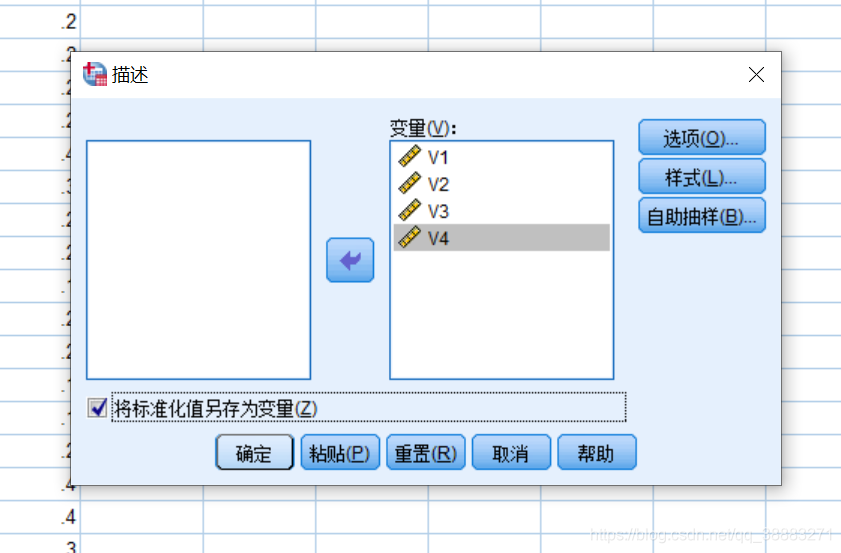
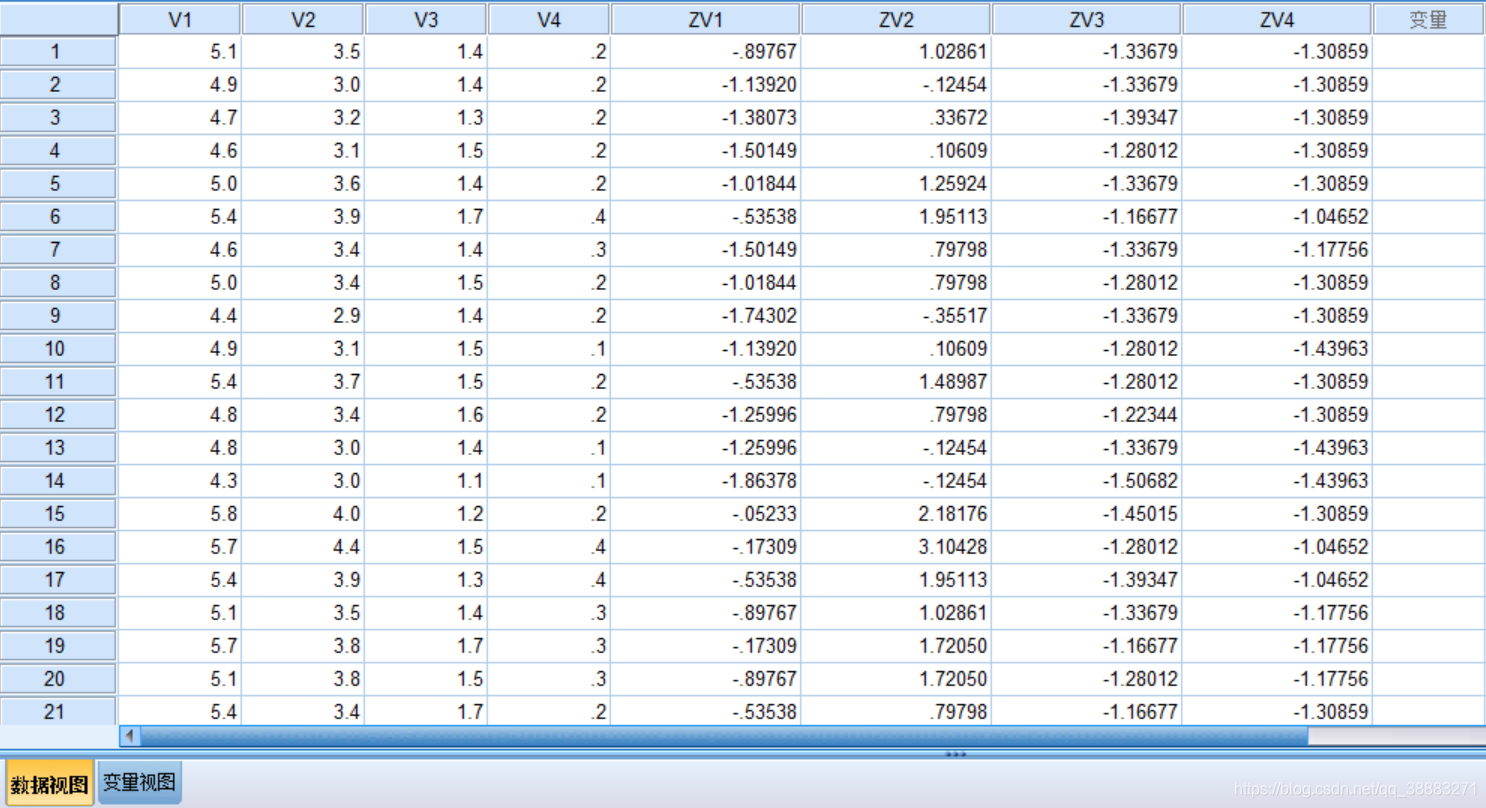
我们先对数据进行标准化处理,在菜单栏中点击"分析",选中"描述统计",点击"描述",将需要进行标准化处理的数据选入右侧框中,勾选下方复选框,点击确定,得到标准化处理后的数据:
接下来对数据进行主成分分析。
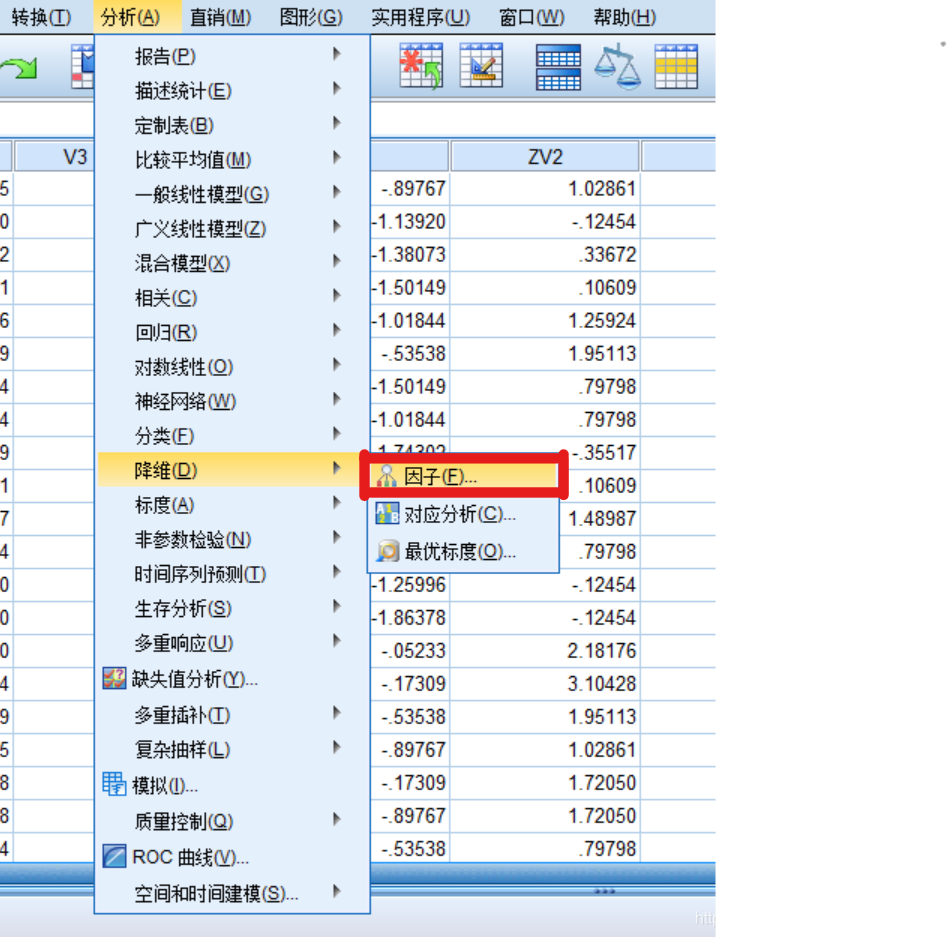
我们按照上图选中“因子”,弹出对话框,将需要进行主成分分析的标准化处理后的数据导入右侧框中:
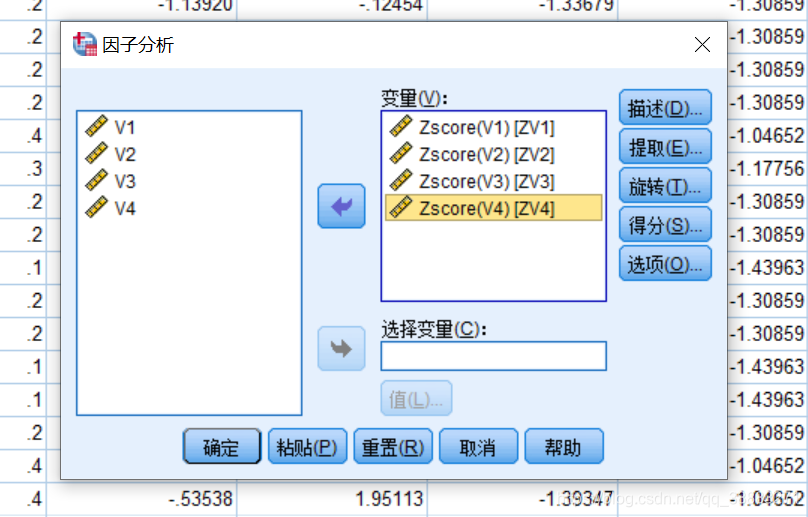
先点击“描述”按钮,弹出的对话框中选中需要显示的对主成分分析的描述信息,一般情况下选中以下描述信息即可。
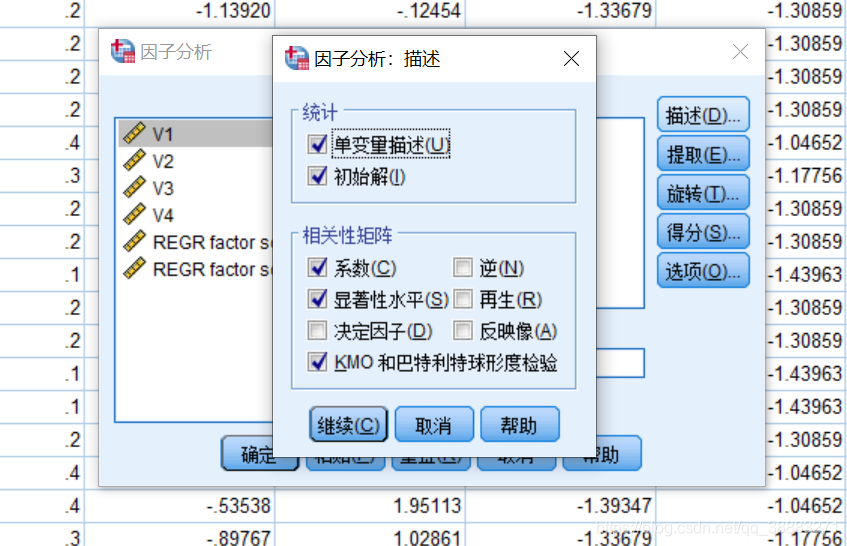
之后我们再点击“提取”按钮,弹出的对话框中,“方法”选中“主成分”,“分析”既可以选中“相关性矩阵”也可以选中“协方差矩阵”,“提取”的方法有两种,一种基于特征值提取,该方法事先我们并不确定需要将数据降维成几维的,而是让spss自己通过我们预设的特征值判断,使得特征值大于1(默认情况)的成分为主成分而得以保留;另外一种方法是因子的固定数目,该方法需要我们提前设定好降维至低维的维数,一旦设定好spss就通过我们设定的值取主成分。
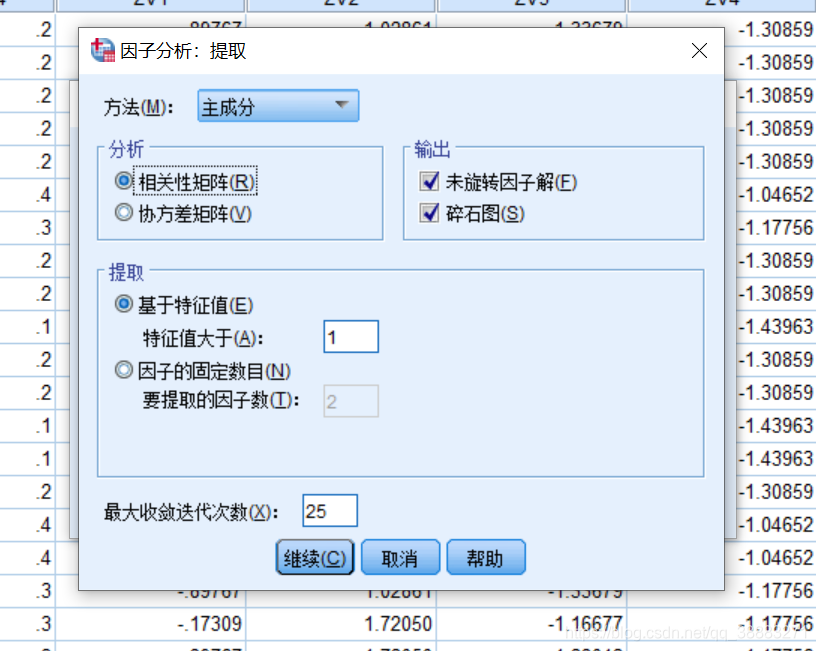
至于“旋转”按钮,如果不需要进行因子分析就无需点开。
下面我们点击“得分”按钮,勾选相应复选框,得到各成分的评价指标。
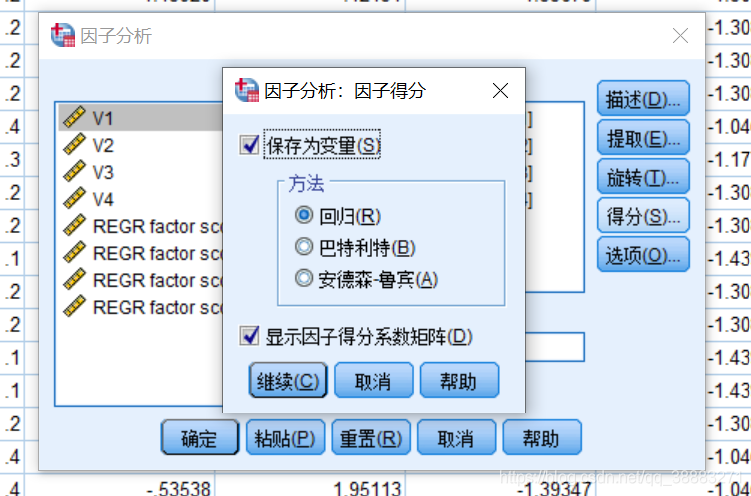
最后点击“选项”按钮,在缺失值处理中,一般情况下都是将缺失值替换为平均值,如果数据中不含有缺失值,那么该选项可以忽略掉。点击“因子分析”对话框下方的确定按钮,在输出文档中可以查看主成分分析的最终结果。
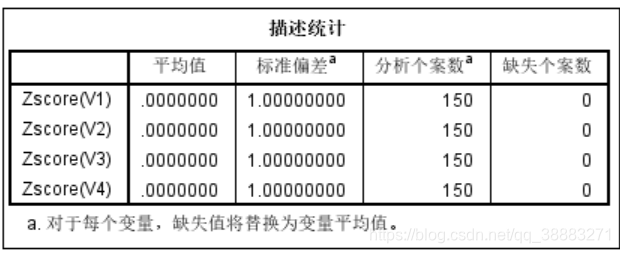
上图显示出4个变量的平均值、标准偏差,以及样本数和缺失样本数。由于数据已经通过标准化处理,所以数据的平均值均为0,标准偏差为1。
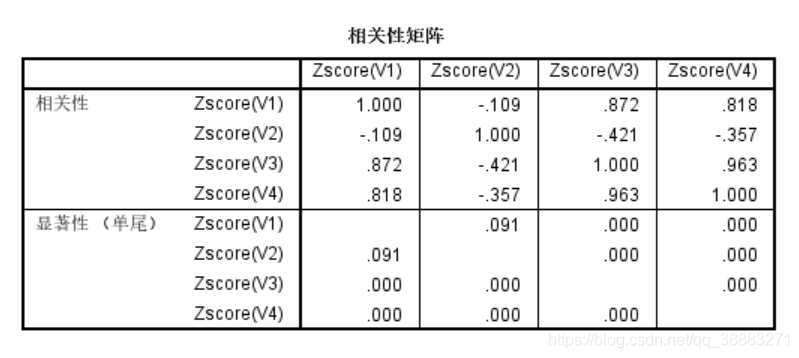
在相关性矩阵中,我们可以看到任意两个变量之间的相关性和显著性,相关性大于0为正相关,小于0为负相关,为1则表示存在严格的线性关系,显然任意变量相对自身而言相关性必定等于1。

KMO(Kaiser-Meyer-Olkin)检验统计量是用于比较变量间简单相关系数和偏相关系数的指标。主要应用于多元统计的因子分析。KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。
显著性,也叫做Significance(简写为Sig),一般我们认为KMO值大于0.5,显著性(也称为P值)小于0.05时,各变量才有意义做主成分分析。上图显示KMO的值等于0.536,P等于0,显然满足条件,适合做主成分分析
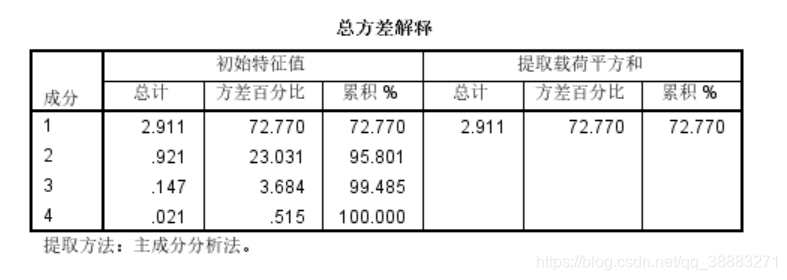
在总方差解释中,只有第一主成分的特征值为2.911大于1,方差百分比为72.77%,剩余成分的特征值均小于1,前两个主成分方差累计占到95.801%,显然包含了数据中的绝大多数信息。(在统计学中,方差百分比即为贡献率,即有用信息占总信息量的比例)
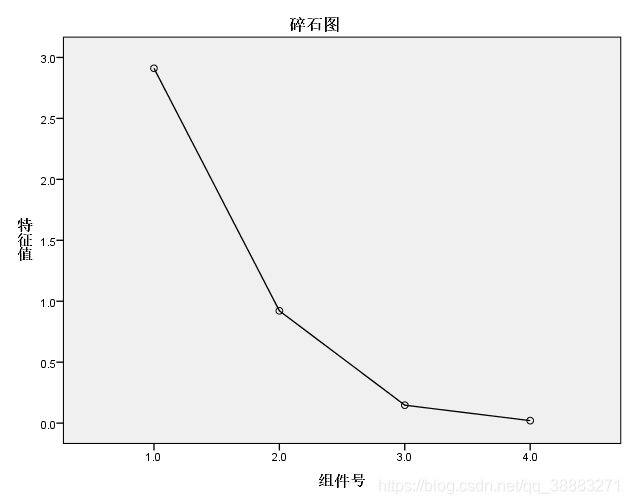
碎石图显示出各个成分的特征值以及特征值的递减趋势。除此之外,还得到成分矩阵、成分得分系数矩阵和成分得分协方差矩阵。
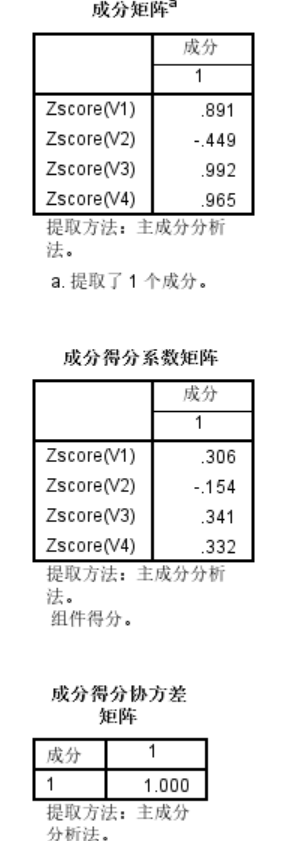
以上三个矩阵还有待研究,望高人指点迷津!
spss实现主成分分析

猜你喜欢
转载自blog.csdn.net/qq_38883271/article/details/105291263
今日推荐
周排行