Elasticsearch基本概念
1.Cluster 集群,Node节点
Elasticsearch可以实现分布式的搭建,可以有多个节点,我们先试用单机版的Elasticsearch进行检索。
集群中的每一台服务器为一个节点,可以存储数据,并参与群集的索引和搜索功能。
2.Index索引
索引是具有相似特性的文档集合。例如,可以为客户数据提供索引,为产品目录建立另一个索引,以及为订单数据建立另一个索引。索引由名称(必须全部为小写)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在单个群集中,您可以定义尽可能多的索引。
3.Type类型
在索引中,可以定义一个或多个类型。类型是索引的逻辑类别/分区,其语义完全取决于您。一般来说,类型定义为具有公共字段集的文档。例如,假设你运行一个博客平台,并将所有数据存储在一个索引中。在这个索引中,您可以为用户数据定义一种类型,为博客数据定义另一种类型,以及为注释数据定义另一类型。
4.Document文档
文档是可以被索引的信息的基本单位。例如,您可以为单个客户提供一个文档,单个产品提供另一个文档,以及单个订单提供另一个文档。
5.类型和映射
类型 在 Elasticsearch 中表示一类相似的文档,类型由名称和映射( mapping)组成。
映射 mapping, 就像数据库中的 schema ,描述了文档可能具有的字段或属性、 每个字段的数据类型—比如 string, integer 或 date。

6.相关概念在关系型数据库和ElasticSearch中的对应关系
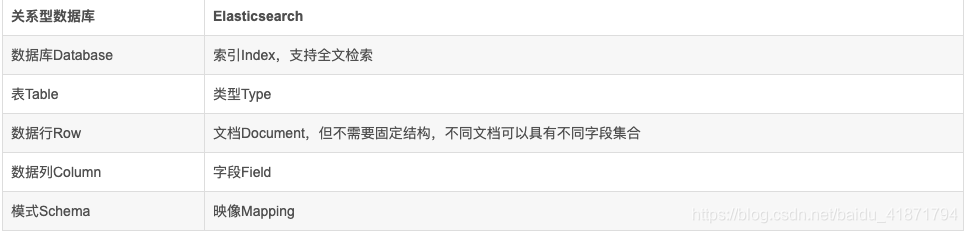
参考文章:https://juejin.im/post/5d4394def265da03a95017c2
在springboot项目中即成elasticsearch
1.添加配置文件
elasticsearch:
cluster:
name: elasticsearch
ip: 127.0.0.1
pool: 5
port: 9300
server:
port: 48080
spring:
elasticsearch:
rest:
uris: http://localhost:9200
2.添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3.读取Elasticsearch的配置
@Configuration
public class ElasticsearchConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(ElasticsearchConfig.class);
/**
* elk集群地址
*/
@Value("${elasticsearch.ip}")
private String hostName;
/**
* 端口
*/
@Value("${elasticsearch.port}")
private String port;
/**
* 集群名称
*/
@Value("${elasticsearch.cluster.name}")
private String clusterName ;
/**
* 连接池
*/
@Value("${elasticsearch.pool}")
private String poolSize;
/**
* Bean name default 函数名字
*
* @return
*/
@Bean(name = "transportClient")
public TransportClient transportClient() {
LOGGER.info("Elasticsearch初始化开始。。。。。");
TransportClient transportClient = null;
try {
// 配置信息
Settings esSetting = Settings.builder()
.put("cluster.name", clusterName) //集群名字
.put("client.transport.sniff", true)//增加嗅探机制,找到ES集群
.put("thread_pool.search.size", Integer.parseInt(poolSize))//增加线程池个数,暂时设为5
.build();
//配置信息Settings自定义
transportClient = new PreBuiltTransportClient(esSetting);
TransportAddress transportAddress = new TransportAddress(InetAddress.getByName(hostName), Integer.valueOf(port));
transportClient.addTransportAddresses(transportAddress);
} catch (Exception e) {
LOGGER.error("elasticsearch TransportClient create error!!", e);
}
return transportClient;
}
}
4.创建博客文章ElasticSearch实体类
@Document(indexName = "articles", type = "doc")
@Data
public class EsArticle implements Serializable {
@Id
private String id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String author;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
}
5.创建ES数据访问接口
@Repository
public interface EsRepository extends ElasticsearchRepository<EsArticle,String> {
}
6.检索逻辑的实现Service
(1)简单的根据id查询
@Autowired
private EsRepository esRepository;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
/**
* 查询
* @param id
* @return
*/
public EsArticle findbyId(String id){
Optional<EsArticle> byId = esRepository.findById(id);
return byId.get();
}
(2)根据关键词进行分页检索
/**
* matchQuery : 单个字段查询
* matchAllQuery : 匹配所有
* multiMatchQuery : 多个字段匹配某一个值
* wildcardQuery : 模糊查询
* boost : 设置权重,数值越大权重越大
* 混合搜索
* @param content
* @return
*/
public Page<EsArticle> querySearch(String content){
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 构造ES查询条件
queryBuilder.should(QueryBuilders.matchPhraseQuery("title", content))
.should(QueryBuilders.matchPhraseQuery("content", content))
.should(QueryBuilders.matchPhraseQuery("author", content));
Page<EsArticle> search = (Page<EsArticle>)esRepository.search(queryBuilder);
return search;
}
(3)实现查询高亮的处理
public interface EsHighlight {
/**
* 高亮显示 - 开始标签
*/
String HIGH_LIGHT_START_TAG = "<javayh>";
/**
* 高亮显示 - 结束标签
*/
String HIGH_LIGHT_END_TAG = "</javayh>";
/**
* 索引名称
*/
class INDEX_NAME {
/**
* 游记
*/
public static final String ARTICLE = "articles";
}
}
/**
* 高亮检索
* @param content
* @return
*/
public List<Article> querySearchType(String content){
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
QueryBuilder titleQuery = QueryBuilders.matchPhraseQuery("title", content);
QueryBuilder contentQuery = QueryBuilders.matchPhraseQuery("content", content);
// QueryBuilder authorQuery = QueryBuilders.matchPhraseQuery("author", content);
List<String> highlightFields = new ArrayList<String>();
highlightFields.add("title");
// highlightFields.add("author");
highlightFields.add("content");
HighlightBuilder.Field[] fields = new HighlightBuilder.Field[highlightFields.size()];
for (int x = 0; x < highlightFields.size(); x++) {
fields[x] = new HighlightBuilder.Field(highlightFields.get(x)).preTags(EsHighlight.HIGH_LIGHT_START_TAG)
.postTags(EsHighlight.HIGH_LIGHT_END_TAG);
}
queryBuilder.should(titleQuery);
queryBuilder.should(contentQuery);
// queryBuilder.should(authorQuery);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withHighlightFields(fields)
//.withPageable(PageRequest.of(1, 10))
.build();
//不需要高亮就直接分页返回
//Page<EsEntiy> esEntiys = esRepository.search(searchQuery);
//高亮显示
AggregatedPage<EsArticle> esEntiys = elasticsearchTemplate.queryForPage(searchQuery, EsArticle.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {
pageable = PageRequest.of(1, 10);
List<EsArticle> chunk = new ArrayList<>();
for (SearchHit searchHit : searchResponse.getHits()) {
if (searchResponse.getHits().getHits().length <= 0) {
return null;
}
EsArticle esEntiy = new EsArticle();
esEntiy.setId(searchHit.getId());
esEntiy.setContent(searchHit.getIndex());
//name or memoe
HighlightField verbalcontent = searchHit.getHighlightFields().get("content");
if (verbalcontent != null) {
esEntiy.setContent(verbalcontent.fragments()[0].toString());
} else {
Object esVerbalcontent = searchHit.getSourceAsMap().get("content");
if(esVerbalcontent == null)
{
esEntiy.setContent("");
}
else
{
esEntiy.setContent(esVerbalcontent.toString());
}
}
HighlightField title = searchHit.getHighlightFields().get("title");
if (title != null) {
esEntiy.setTitle(title.fragments()[0].toString());
}else {
Object esTitle= searchHit.getSourceAsMap().get("title");
if(esTitle == null )
{
esEntiy.setTitle("");
}
else
{
esEntiy.setTitle(esTitle.toString());
}
}
chunk.add(esEntiy);
}
if (chunk.size() > 0) {
return new AggregatedPageImpl<T>((List<T>) chunk);
}
return null;
}
});
List<Article> articleList = new ArrayList<>();
for(EsArticle esArticle : esEntiys)
{
Article article = new Article();
article.setAuthor(esArticle.getAuthor());
article.setTitle(esArticle.getTitle());
article.setId(Integer.parseInt(esArticle.getId()));
//将高亮的内容放在最前面
List<String> sentence = spiltSentence(esArticle.getContent());
StringBuffer sb = new StringBuffer();
for(String str :sentence)
{
if(str.contains(EsHighlight.HIGH_LIGHT_END_TAG) || str.contains(EsHighlight.HIGH_LIGHT_START_TAG))
{
sb.append(str);
sb.append(",");
}
}
for(String str :sentence)
{
if(!str.contains(EsHighlight.HIGH_LIGHT_END_TAG) && !str.contains(EsHighlight.HIGH_LIGHT_START_TAG))
{
sb.append(str);
sb.append(",");
}
}
article.setVerbalContent(sb.toString());
articleList.add(article);
}
return articleList;
}
/**
* 将文章分割为句子 分割依据为标点符号
* @param document
* @return
*/
static List<String> spiltSentence(String document)
{
List<String> sentences = new ArrayList<String>();
if (document == null) {
return sentences;
}
String regex1 = "[\r\n]";
String regex2 = "[,,。::“”??!!;;]";
for (String line : document.split(regex1)) {
line = line.trim();
if (line.length() == 0) {continue;}
for (String sent : line.split(regex2))
{
sent = sent.trim();
if (sent.length() == 0) {
continue;
}
sentences.add(sent);
}
}
return sentences;
}
标签中为高亮内容:
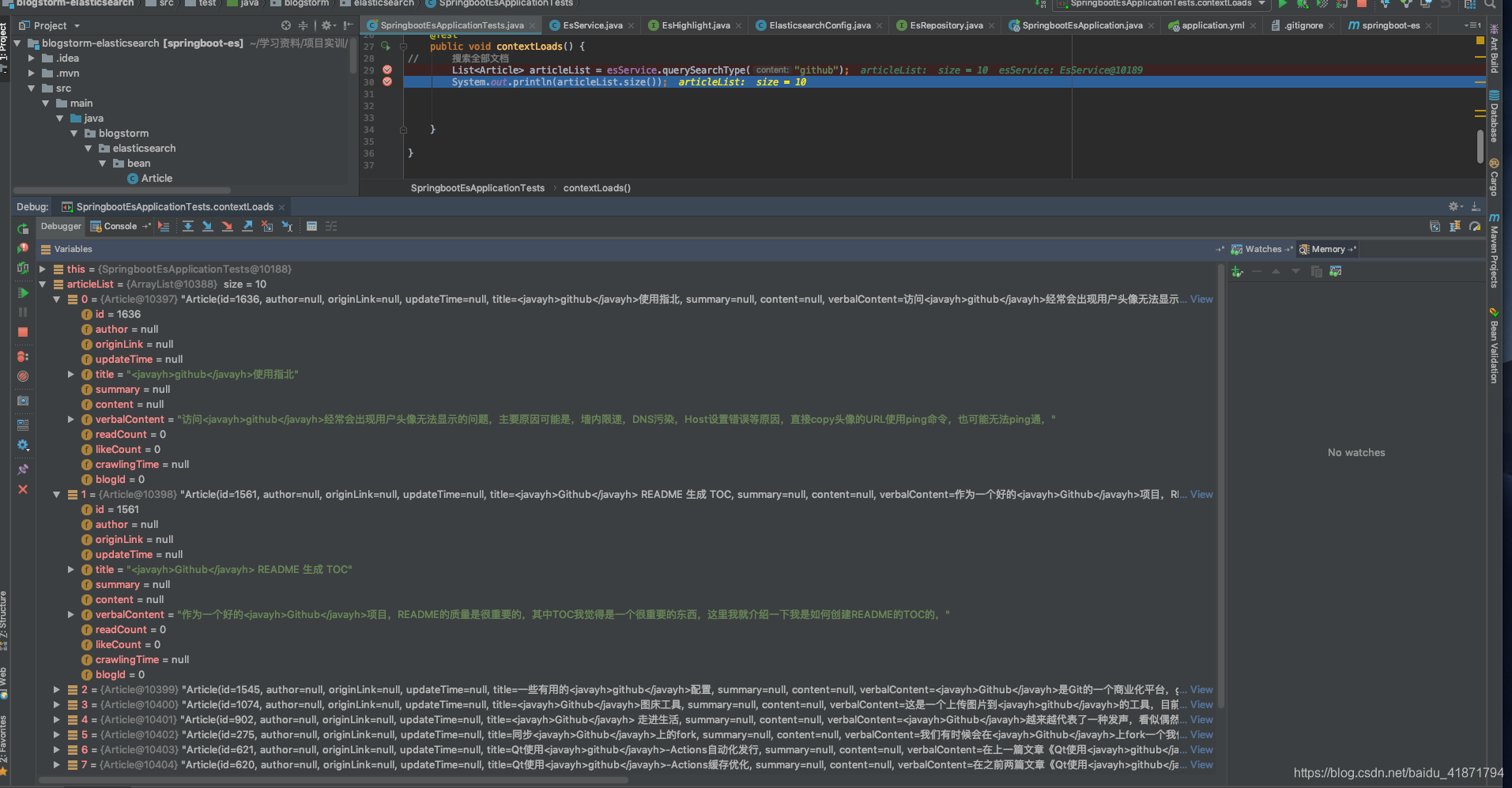
6.实现Controller,接受http请求,返回json数据
private EsService esService;
/**
* http://127.0.0.1:8080/api/es/query
* 搜索
* @param key
* @return
*/
@RequestMapping(value = "/query", method = RequestMethod.GET, produces = "application/json")
public Response query(@RequestParam String key) {
System.out.println(key);
List<Article> articleList = esService.querySearchType(key);
return Response.success("返回查询列表成功", articleList);
}
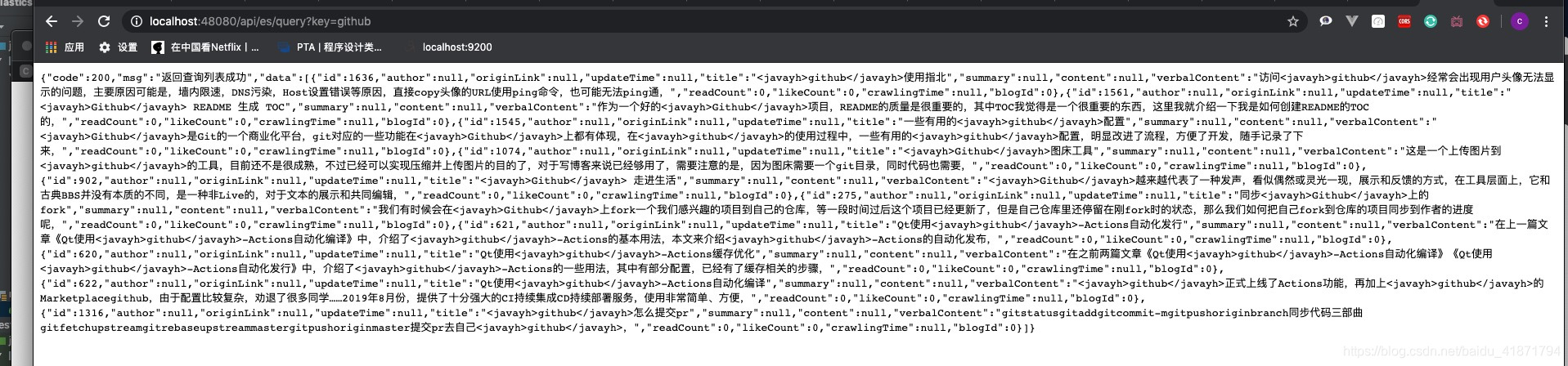
至此简单的检索工作就完成了
总结
虽然最终检索的代码没有很多,但是搭建环境,添加依赖中的坑有很多。
(1)一定要选择与elasticsearch对应版本的依赖,不然会有各种错误出现,不想细说了,太难顶了
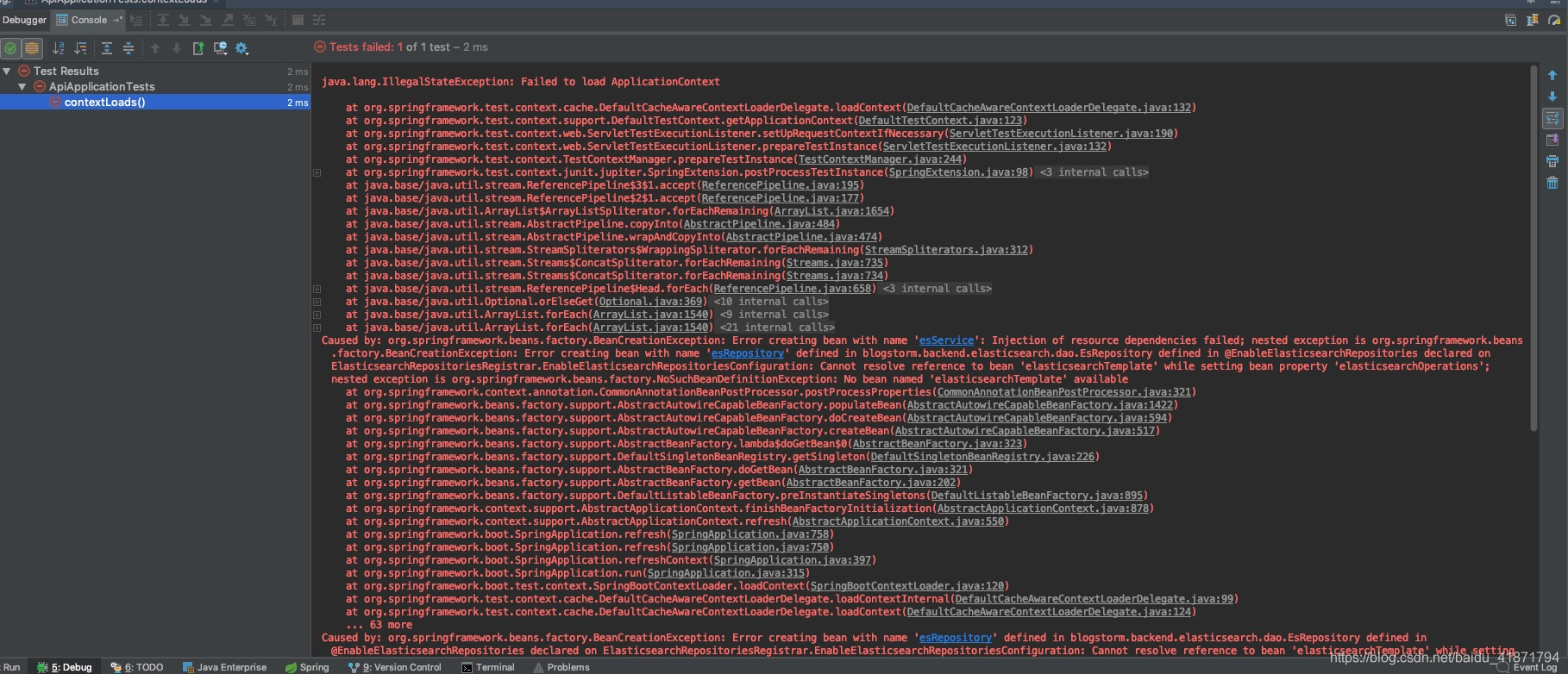

(2)还有其他坑,没截图了,今天就到这吧,太累了
(3)现在只能实现关键词的查询,如果想实现句子的查询,可以手动对输入的句子进行分词,然后使用elk进行查询最终输出结果