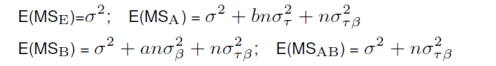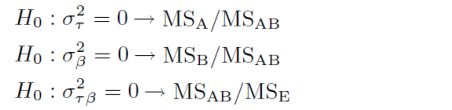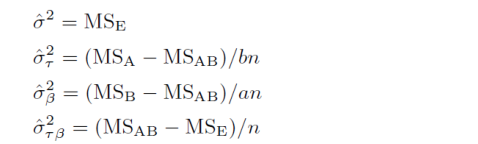UA MATH571B 试验设计VI 随机效应与混合效应
现在回到试验设计III 单因素试验设计1 中介绍的模型,
y
i
j
=
μ
+
τ
i
+
ϵ
i
j
,
ϵ
i
j
∼
i
i
d
N
(
0
,
σ
2
)
i
=
1
,
2
,
⋯
,
a
;
j
=
1
,
2
,
⋯
,
n
y_{ij} = \mu + \tau_i + \epsilon_{ij},\epsilon_{ij}\sim_{iid}N(0,\sigma^2)\\ i = 1,2,\cdots,a; j=1,2,\cdots,n
y i j = μ + τ i + ϵ i j , ϵ i j ∼ i i d N ( 0 , σ 2 ) i = 1 , 2 , ⋯ , a ; j = 1 , 2 , ⋯ , n
其中
μ
\mu
μ
τ
i
\tau_i
τ i
i
i
i
μ
i
=
μ
+
τ
i
\mu_i=\mu+\tau_i
μ i = μ + τ i 不同level 对response的影响。用最小二乘法估计这个模型的时候,我们得到的方程是
a
n
μ
^
+
∑
i
=
1
a
τ
^
i
=
y
.
.
n
μ
^
+
n
τ
^
i
=
y
i
.
,
i
=
1
,
⋯
,
a
an\hat{\mu}+\sum_{i=1}^a \hat{\tau}_i=y_{..}\\n\hat{\mu}+ n\hat{\tau}_i=y_{i.},i=1,\cdots,a
a n μ ^ + i = 1 ∑ a τ ^ i = y . . n μ ^ + n τ ^ i = y i . , i = 1 , ⋯ , a
线性独立的方程只有
a
a
a
a
+
1
a+1
a + 1
∑
i
=
1
a
τ
^
i
=
0
\sum_{i=1}^a \hat{\tau}_i = 0
i = 1 ∑ a τ ^ i = 0
并称满足这个方程的factor为fixed factor 。引入这个假设意味着我们认为treatment factor的level 是人为设计,并且包含了treatment factor的绝大多数可能性 ,这样的因素模型我们称之为固定效应模型。固定效应模型中缺一个方程的原因是总体均值与treatment effec的线性相关性,除了增加额外的约束外,还可以考虑增加模型的随机性。固定模型要求穷尽treatment factor所有取值是可能实现的,那么当treatment factor有非常多的可能的值时,样本中的treatment factor level其实是对level的population的抽样,treatment effect也就不会是固定的,而是与treatment factor level一样是随机的。称factor level和factor effect是随机变量的factor为random factor ,只含有random factor的模型为随机效应模型 ;同时含有random factor与fixed factor的模型为混合效应模型 。
假设我们关注A和B两个factor的effects,它们都是random factors,模型设定为:
y
i
j
k
=
μ
+
τ
i
+
β
j
+
(
τ
β
)
i
j
+
ϵ
i
j
k
ϵ
i
j
k
∼
i
i
d
N
(
0
,
σ
2
)
;
i
=
1
,
⋯
,
a
;
j
=
1
,
⋯
,
b
;
k
=
1
,
⋯
,
n
τ
i
∼
i
i
d
N
(
0
,
σ
τ
2
)
,
β
j
∼
i
i
d
N
(
0
,
σ
β
2
)
,
(
τ
β
)
i
j
∼
i
i
d
N
(
0
,
σ
τ
β
2
)
y_{ijk} = \mu + \tau_i + \beta_j +(\tau \beta)_{ij}+ \epsilon_{ijk}\\ \epsilon_{ijk} \sim_{iid}N(0,\sigma^2);i=1,\cdots,a;j=1,\cdots,b;k=1,\cdots,n \\ \tau_i \sim_{iid} N(0,\sigma_{\tau}^2),\beta_j \sim_{iid} N(0,\sigma^2_{\beta}),(\tau \beta)_{ij} \sim_{iid} N(0,\sigma_{\tau \beta}^2)
y i j k = μ + τ i + β j + ( τ β ) i j + ϵ i j k ϵ i j k ∼ i i d N ( 0 , σ 2 ) ; i = 1 , ⋯ , a ; j = 1 , ⋯ , b ; k = 1 , ⋯ , n τ i ∼ i i d N ( 0 , σ τ 2 ) , β j ∼ i i d N ( 0 , σ β 2 ) , ( τ β ) i j ∼ i i d N ( 0 , σ τ β 2 )
从而方差分解为:
V
a
r
(
y
i
j
k
)
=
σ
τ
2
+
σ
β
2
+
σ
τ
β
2
+
σ
2
Var(y_{ijk}) = \sigma^2_{\tau} + \sigma^2_{\beta} + \sigma^2_{\tau \beta} + \sigma^2
V a r ( y i j k ) = σ τ 2 + σ β 2 + σ τ β 2 + σ 2
因素模型中我们讨论的最基本的问题永远是某个因素对试验结果是否存在显著的效应,具体表现为在总体均值以外,因素的不同水平是否会造成试验结果的显著区别。在固定效应模型中,我们比较的方式是用ANOVA做多组level的effect均值的检验,比较他们是否同时显著为0;在随机效应模型中,不同level的effect相同则意味着factor effect的方差为0,因此随机效应模型中我们需要做的检验是:
H
0
:
σ
τ
2
=
0
H
0
:
σ
β
2
=
0
H
0
:
σ
τ
β
2
=
0
H_0:\sigma_{\tau}^2=0 \\ H_0:\sigma_{\beta}^2=0\\ H_0:\sigma_{\tau \beta}^2=0
H 0 : σ τ 2 = 0 H 0 : σ β 2 = 0 H 0 : σ τ β 2 = 0
接下来,我们要试图修正之前一直在用的ANOVA分析框架使之能够用在随机效应模型中。先定义几个符号:
y
i
.
.
=
∑
j
=
1
b
∑
k
=
1
n
y
i
j
k
,
y
ˉ
i
.
.
=
y
i
.
.
a
n
y
.
j
.
=
∑
i
=
1
a
∑
k
=
1
n
y
i
j
k
,
y
ˉ
.
j
.
=
y
.
j
.
b
n
y
i
j
.
=
∑
k
=
1
n
y
i
j
k
,
y
ˉ
i
j
.
=
y
i
j
.
n
y
.
.
.
=
∑
i
=
1
a
y
i
.
.
=
∑
j
=
1
b
y
.
j
.
,
y
ˉ
.
.
.
=
y
.
.
.
N
,
N
=
a
b
n
y_{i..} = \sum_{j=1}^b\sum_{k=1}^n y_{ijk}, \bar{y}_{i..} = \frac{y_{i..}}{an} \\ y_{.j.} = \sum_{i=1}^a \sum_{k=1}^n y_{ijk}, \bar{y}_{.j.} = \frac{y_{.j.}}{bn} \\ y_{ij.} = \sum_{k=1}^n y_{ijk}, \bar{y}_{ij.} = \frac{y_{ij.}}{n}\\ y_{...} = \sum_{i=1}^a y_{i..}=\sum_{j=1}^b y_{.j.}, \bar{y}_{...} = \frac{y_{...}}{N},N=abn
y i . . = j = 1 ∑ b k = 1 ∑ n y i j k , y ˉ i . . = a n y i . . y . j . = i = 1 ∑ a k = 1 ∑ n y i j k , y ˉ . j . = b n y . j . y i j . = k = 1 ∑ n y i j k , y ˉ i j . = n y i j . y . . . = i = 1 ∑ a y i . . = j = 1 ∑ b y . j . , y ˉ . . . = N y . . . , N = a b n
考虑平方和分解,总平方和为:
S
S
T
=
∑
i
=
1
a
∑
j
=
1
b
∑
k
=
1
n
(
y
i
j
k
−
y
ˉ
.
.
.
)
2
SST = \sum_{i=1}^a \sum_{j=1}^b \sum_{k=1}^n (y_{ijk}-\bar{y}_{...})^2
S S T = i = 1 ∑ a j = 1 ∑ b k = 1 ∑ n ( y i j k − y ˉ . . . ) 2
做一个替换
y
i
j
k
−
y
ˉ
.
.
.
=
(
y
ˉ
i
.
.
−
y
ˉ
.
.
.
)
+
(
y
ˉ
.
j
.
−
y
ˉ
.
.
.
)
+
(
y
ˉ
i
j
.
−
y
ˉ
i
.
.
−
y
ˉ
.
j
.
+
y
ˉ
.
.
.
)
+
(
y
i
j
k
−
y
ˉ
i
j
.
)
y_{ijk} - \bar{y}_{...} = (\bar{y}_{i..}-\bar{y}_{...}) + (\bar{y}_{.j.}-\bar{y}_{...}) + (\bar{y}_{ij.}-\bar{y}_{i..} -\bar{y}_{.j.} + \bar{y}_{...} ) + (y_{ijk} - \bar{y}_{ij.})
y i j k − y ˉ . . . = ( y ˉ i . . − y ˉ . . . ) + ( y ˉ . j . − y ˉ . . . ) + ( y ˉ i j . − y ˉ i . . − y ˉ . j . + y ˉ . . . ) + ( y i j k − y ˉ i j . )
可以自行验证下面的结果:
S
S
T
=
b
n
∑
i
=
1
n
(
y
ˉ
i
.
.
−
y
ˉ
.
.
.
)
2
+
a
n
∑
j
=
1
b
(
y
ˉ
.
j
.
−
y
ˉ
.
.
.
)
2
+
n
∑
i
=
1
a
∑
j
=
1
b
(
y
ˉ
i
j
.
−
y
ˉ
i
.
.
−
y
ˉ
.
j
.
+
y
ˉ
.
.
.
)
2
+
∑
i
=
1
a
∑
j
=
1
b
∑
k
=
1
n
(
y
i
j
k
−
y
ˉ
i
j
.
)
2
SST = bn \sum_{i=1}^n(\bar{y}_{i..}-\bar{y}_{...})^2 + an\sum_{j=1}^b(\bar{y}_{.j.}-\bar{y}_{...})^2 + n\sum_{i=1}^a\sum_{j=1}^b (\bar{y}_{ij.}-\bar{y}_{i..} -\bar{y}_{.j.} + \bar{y}_{...} )^2 +\sum_{i=1}^a\sum_{j=1}^b\sum_{k=1}^n (y_{ijk} - \bar{y}_{ij.})^2
S S T = b n i = 1 ∑ n ( y ˉ i . . − y ˉ . . . ) 2 + a n j = 1 ∑ b ( y ˉ . j . − y ˉ . . . ) 2 + n i = 1 ∑ a j = 1 ∑ b ( y ˉ i j . − y ˉ i . . − y ˉ . j . + y ˉ . . . ) 2 + i = 1 ∑ a j = 1 ∑ b k = 1 ∑ n ( y i j k − y ˉ i j . ) 2
定义等式右边的平方和为
S
S
A
,
S
S
B
,
S
S
A
B
,
S
S
E
SS_A,SS_B,SS_{AB},SSE
S S A , S S B , S S A B , S S E
S
S
T
=
S
S
A
+
S
S
B
+
S
S
A
B
+
S
S
E
SST = SS_A + SS_B + SS_{AB} + SSE
S S T = S S A + S S B + S S A B + S S E
总平方和的自由度为
d
f
T
=
N
−
1
df_T = N-1
d f T = N − 1
S
S
A
SS_A
S S A
d
f
A
=
a
−
1
df_A = a-1
d f A = a − 1
S
S
B
SS_B
S S B
d
f
B
=
b
−
1
df_B = b-1
d f B = b − 1
S
S
A
B
SS_{AB}
S S A B
∑
j
=
1
b
y
ˉ
i
j
.
=
b
y
ˉ
i
.
.
,
i
=
1
,
⋯
,
a
;
∑
i
=
1
a
y
ˉ
i
j
.
=
a
y
ˉ
.
j
.
,
j
=
1
,
⋯
,
b
;
n
y
ˉ
.
.
.
=
∑
i
=
1
a
y
i
.
.
=
∑
j
=
1
b
y
.
j
.
\sum_{j=1}^b \bar{y}_{ij.} = b\bar{y}_{i..},i=1,\cdots,a; \sum_{i=1}^a \bar{y}_{ij.} = a\bar{y}_{.j.},j=1,\cdots,b; n\bar{y}_{...} = \sum_{i=1}^a y_{i..}=\sum_{j=1}^b y_{.j.}
j = 1 ∑ b y ˉ i j . = b y ˉ i . . , i = 1 , ⋯ , a ; i = 1 ∑ a y ˉ i j . = a y ˉ . j . , j = 1 , ⋯ , b ; n y ˉ . . . = i = 1 ∑ a y i . . = j = 1 ∑ b y . j .
自由方程数目为
a
+
b
−
1
a+b-1
a + b − 1
d
f
A
B
=
a
b
−
a
−
b
+
1
=
(
a
−
1
)
(
b
−
1
)
d
f
M
o
d
e
l
=
d
f
A
+
d
f
B
+
d
f
A
B
=
a
b
−
1
df_{AB} = ab - a - b + 1 = (a-1)(b-1) \\ df_{Model} = df_{A} + df_{B} + df_{AB} = ab - 1
d f A B = a b − a − b + 1 = ( a − 1 ) ( b − 1 ) d f M o d e l = d f A + d f B + d f A B = a b − 1
所以残差的自由度为
d
f
E
=
d
f
T
−
d
f
M
o
d
e
l
=
a
b
n
−
a
b
=
a
b
(
n
−
1
)
df_E = df_T - df_{Model} = abn - ab = ab(n-1)
d f E = d f T − d f M o d e l = a b n − a b = a b ( n − 1 )
根据平方和与自由度可以定义均方和,下面是一些常用结果,可以自行验证: