1. 案例背景
对于用户价值度模型而言,由于用户的状态是动态变化的,因此一般需要定期更新,业务方的主要需求是至少每周更新一次。由于要兼顾历史状态变化,因此在每次更新是都要保存历史数据,不同时间点下的数据将通过日期区分。
每次模型结果的数据,一部分是要给运营直接做分析,一部分是要“回吐”到数据库中,作为其他数据建模的基本数据维度,因此数据的输出需要本地文件和写数据库两种方式。
用户价值细分是了解用户价值度的重要途径,常用的细分模型包括:基于属性的方法、ABC分类法、聚类法等。
1. 基于属性的方法
常用的细分属性包括:地域、产品类别、用户类别(大客户、普通客户、VIP客户等)、性别、消费等级等。这种细分方法可根据数据库中数据直接得到。
2. ABC分类法
ABC法则是二八法则衍生出的一种法则。不同的是,二八法则强调是抓住关键,ABC法则强调分清主次,将管理对象划分为A、B、C三类。
在ABC分析法中先将目标数据列倒叙排序,然后做累积百分比统计,最后将得到的累积百分比按照下面的比例值划分为A、B、C三类。
例:

3. 聚类法
无需任何先验经验,只要指定要划分的群体数量即可。
2. 案例主要应用技术
本案例没有直接使用成熟模型包,而是通过 Python 代码手动实现 RFM 模型。
RFM 模型是根据会员最近一次购买时间 R(Recency)、购买频率 F(Frequency)、购买金额 M(Monetary)计算得出 RFM 得分。
RFM模型基本实现过程:
步骤1:设置截止时间节点(例如2020-6-28)。
步骤2:以今天为时间界限,向前推固定周期(例如1年)。
步骤3:数据预计算。找出各个会员最近购买时间;以会员ID为维度统计每个用户购买频率,将用户多个订单的金额求和得到总订单金额。由此得到R、F、M三个原始数据量。
步骤4:R、F、M分区。对R、F、M分别使用五分位法(三分位也可以,分位数越多划分越详细)做数据区分。需要注意的是,对 R 需要倒过来划分。因为对F、M来说,值越大代表购买频率,订单金额越高,对R来说,值越小代表离截止时间越近,我们需要倒过来划分,离截止时间越近的值划分越大。
步骤5:将三个值组合或相加得到总的RFM得分。RFM总得分的两种计算方式,一种直接将三个值拼接到一起,例如RFM得分为312、333、132;另一种将三个值相加得到一个新的汇总值,例如RFM得分为6、9、6。
根据步骤5产生的两种结果有不同的应用思路:
思路1:基于三个维度值做用户群体划分和解读,对用户的价值度做分析。例如得分为212会员购买频率低,针对购买频率低的客户定期发送促销活动邮件;针对得分为321的会员购买频率高但订单金额低,可以考虑通过关联或搭配销售方式提升金额。
思路2:基于 RFM 的汇总得分评估会员的价值度,并可以做价值度排名;同时,该得分还可以作为输入维度跟其他维度一起作为其他数据分析或数据挖掘的输入变量。
3. 案例数据
数据概况:
- 特征变量数:4
- 数据记录数:86135
- 是否有NA值:有
- 是否有异常值:有
数据集的4个特征变量:
- USERID:用户ID
- ORDERDATE:订单日期
- ORDERID:订单ID
- AMOUNTINFO:订单金额
4. 案例过程
import time import numpy as np import pandas as pd import pymysql # 读取原始数据 dtypes = {'ORDERDATE': object, 'ORDERID': object, 'AMOUNTINFO': np.float} raw_data = pd.read_csv('sales.csv', dtype=dtypes, index_col='USERID') # 数据概览、缺失值审查 print(raw_data.describe()) """ 对DataFrame来说,describe()默认情况下,只返回数字字段。 describe(include='all')返回数据的所有列。 """

从结果看出,最大值30000元,最小值0.5元,经过沟通,最大值正常,为某客户一次性购买多个大型电商品;0.5元订单属于促销优惠券生成的订单,这些订单为用户消费时的优惠券,没有实际意义,因此可以去掉这些数据,所有低于1元的订单均有这个问题。
na_cols = raw_data.isnull().any(axis=0) # 查看每一列是否有缺失值 print(na_cols) na_lines = raw_data.isnull().any(axis=1) # 查看每一行是否有缺失值 print('总的NA行数:{}'.format(na_lines.sum())) print(raw_data[na_lines]) # 查看具有缺失值的行信息
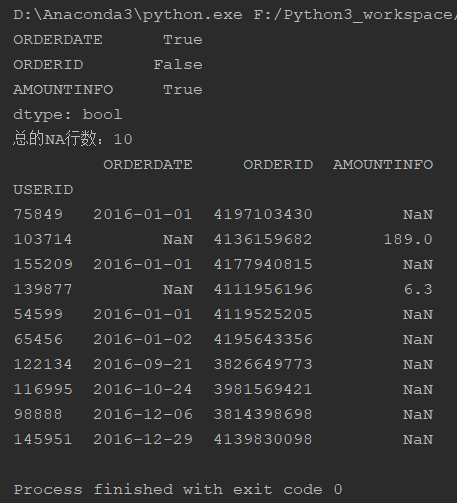
# 异常值处理 sales_data = raw_data.dropna() sales_data = sales_data[sales_data['AMOUNTINFO'] > 1] # 丢弃金额≤1 # 日期格式转换 sales_data['ORDERDATE'] = pd.to_datetime(sales_data['ORDERDATE'], format='%Y-%m-%d') """ format参数以原始数据字符串格式来写,只有格式对应才能实现解析 """ print(sales_data.dtypes)

日期转换的目的是计算时间间隔,算出 R 距离指定日期的天数。
计算RFM得分