接着上一篇随笔,继续进行整理总结
注:以下内容基本都在以前的随笔中可以找到
Python定位模块:
导入模块时,系统会根据搜索路径进行寻找模块:
1.在程序当前目录下寻找该模块
2.在环境变量 PYTHONPATH 中指定的路径列表寻找
3.在 Python 安装路径中寻找
搜索路径是一个列表,所以具有列表的方法
使用 sys 库的 path 可以查看系统路径
import sys
# 以列表方式输出系统路径,可以进行修改
print(sys.path)
增加新目录到系统路径中
sys.path.append("新目录路径")
sys.path.insert(0,"新目录路径")
添加环境变量
set PYTHONPATH=安装路径\lib;
Python 会在每次启动时,将 PYTHONPATH 中的路径加载到 sys.path中。
Python命名空间和作用域:
变量拥有匹配对象的名字,命名空间包含了变量的名称(键)和所指向的对象(值)。
Python表达式可以访问局部命名空间和全局命名空间
注:当局部变量和全局变量重名时,使用的是局部变量
每个函数和类都具有自己的命名空间,称为局部命名空间
如果需要在函数中使用全局变量,可以使用 global 关键字声明,声明后,Python会将该关键字看作是全局变量
# global 全局变量名:
# 在函数中使用全局变量,可以对全局变量进行修改。
# 注:如果只是在函数中使用了和全局变量相同的名字,则只是局部变量
# 定义全局变量 total
total = 0
def add(num1,num2):
# 使用 global 关键字声明全局变量 total
global total
total = num1 + num2
# 输出全局变量
print(total)
add(4,6)
# 10
# 输出全局变量
print(total)
# 10
Python dir(模块名 或 模块名.方法名):
查看 模块名 或 模块名.方法名 的所有可以调用的方法
# 导入 math 库
import math
# 查看 math 可以调用的方法
print(dir(math))
'''
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
'''
import urllib.request
print(dir(urllib.request))
'''
['AbstractBasicAuthHandler', 'AbstractDigestAuthHandler', 'AbstractHTTPHandler', 'BaseHandler', 'CacheFTPHandler', 'ContentTooShortError', 'DataHandler', 'FTPHandler', 'FancyURLopener', 'FileHandler', 'HTTPBasicAuthHandler', 'HTTPCookieProcessor', 'HTTPDefaultErrorHandler', 'HTTPDigestAuthHandler', 'HTTPError', 'HTTPErrorProcessor', 'HTTPHandler', 'HTTPPasswordMgr', 'HTTPPasswordMgrWithDefaultRealm', 'HTTPPasswordMgrWithPriorAuth', 'HTTPRedirectHandler', 'HTTPSHandler', 'MAXFTPCACHE', 'OpenerDirector', 'ProxyBasicAuthHandler', 'ProxyDigestAuthHandler', 'ProxyHandler', 'Request', 'URLError', 'URLopener', 'UnknownHandler', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '__version__', '_cut_port_re', '_ftperrors', '_have_ssl', '_localhost', '_noheaders', '_opener', '_parse_proxy', '_proxy_bypass_macosx_sysconf', '_randombytes', '_safe_gethostbyname', '_splitattr', '_splithost', '_splitpasswd', '_splitport', '_splitquery', '_splittag', '_splittype', '_splituser', '_splitvalue', '_thishost', '_to_bytes', '_url_tempfiles', 'addclosehook', 'addinfourl', 'base64', 'bisect', 'build_opener', 'contextlib', 'email', 'ftpcache', 'ftperrors', 'ftpwrapper', 'getproxies', 'getproxies_environment', 'getproxies_registry', 'hashlib', 'http', 'install_opener', 'io', 'localhost', 'noheaders', 'os', 'parse_http_list', 'parse_keqv_list', 'pathname2url', 'posixpath', 'proxy_bypass', 'proxy_bypass_environment', 'proxy_bypass_registry', 'quote', 're', 'request_host', 'socket', 'ssl', 'string', 'sys', 'tempfile', 'thishost', 'time', 'unquote', 'unquote_to_bytes', 'unwrap', 'url2pathname', 'urlcleanup', 'urljoin', 'urlopen', 'urlparse', 'urlretrieve', 'urlsplit', 'urlunparse', 'warnings']
'''
Python globals和locals函数_reload函数:
globals( ):
返回所有能够访问到的全局名字
num = 5
sum = 0
def add(num):
func_sum = 0
func_sum += num
return func_sum
print(globals())
'''
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001F5F98CC2E0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'G:/code/time/1.py', '__cached__': None, 'num': 5, 'sum': 0, 'add': <function add at 0x000001F5F97E51F0>}
'''
注:我此处的代码是停留在昨天的time模块中,所以在路径下会出现G:/code/time/1.py
locals( ):
在函数中使用 locals ,返回形参和局部变量
num = 5
sum = 0
def add(num):
func_sum = 0
func_sum += num
print(locals())
return func_sum
add(num)
# {'num': 5, 'func_sum': 5}
reload(模块名):reload 在 importlib 模块中
重新导入之前导入过的模块
注:当一个模块导入到另一个脚本时,模块顶层部分的代码只会被执行一次
# 重新导入模块
import func
# 导入自定义的模块
from importlib import reload
# reload 函数在 importlib 模块中
reload(func)
# 重新导入 func 模块
from func import get_info
get_info()
# 获取到了 func 模块的信息
使用reload的前提,是reload的 模块,之前已经使用import或者from导入过,否则会失败
import 导入的模块,使用模块名.方法的方式,reload会强制运行模块文件,然后原来导入的模块会被新使用的导入语句覆盖掉
from 导入的模块,本质是一个赋值操作
即在当前文件中(即执行 from 语句的文件)进行 attr = module.attr
注:reload 函数对 reload 运行之前的from语句没有影响
Python包:
包是一种管理 Python 模块命名空间的形式,采用 “点模块名称”
例:A.B 表示 A 模块的 B子模块
当不同模块间存在相同的变量名时,一个是使用 模块名.变量名 另一个是 变量名
当导入一个包时,Python 会根据 sys 模块的 path 变量中寻找这个包
目录中只有一个 __init__.py 文件才会被认为是一个包
导包常见的几种方式:
import 模块名 或 包:调用方法,使用 模块名.方法
from 模块名 import 子模块(子模块 或 函数 或 类 或 变量):使用函数调用
from 模块名 import * :使用函数进行调用
注:如果 __init__.py 文件中存在 __all__变量,则导入 __all__变量的值,在更新包的时候,注意修改__all__的值
__all__ = ["echo", "surround", "reverse"] 导入 * 时,从 __all__ 导入
包还提供 __path__ ,一个目录列表,每一个目录都有为这个包服务的 __init__.py 文件,先定义,后运行其他的__init__.py文件
__path__ :主要用于扩展包里面的模块
float_num = 2.635
print("输出的是%f"%(float_num))
# 输出的是2.635000
# 保留两位小数
print("输出的是%.2f"%(float_num))
# 输出的是2.63
float_num = 5.99
print("输出的数字是{}".format(float_num))
# 输出的数字是5.99
# 指定参数名
float_num = 5.99
strs = 'happy'
print("输出的数字是{num},输出的字符串是{str}".format(num = float_num,str = strs))
# 输出的数字是5.99,输出的字符串是happy
input(字符串):字符串通常为提示语句
输入语句
注:通常使用变量进行接收,input 返回字符串类型,如果输入的为数字,可使用 int 转化为数字
# input(字符串):字符串通常为提示语句
# 输入语句
# 注:通常使用变量进行接收,input 返回字符串类型,如果输入的为数字,可使用 eval 转化为数字
strs = input("请输入一个字符串")
print(type(strs))
print("输入的字符串为:",strs)
# 请输入一个字符串HELLO
# <class 'str'>
# 输入的字符串为: HELLO
num = eval(input("请输入一个数字"))
print(type(num))
print("输入的数字为:",num)
# 请输入一个数字56
# <class 'int'>
# 输入的数字为: 56
注:
input 使用 eval 进行转换时,如果输入的是
[1,2,3] 那么转换的就是 [1,2,3] 为列表类型
Python打开和关闭文件:
open(文件名,打开文件的模式[,寄存区的缓冲]):
文件名:字符串值
注:文件名带有后缀名
# 打开创建好的 test.txt 文件
f = open("test.txt",'r')
# 输出文件所有的内容
print(f.readlines( ))
# ['hello,world.\n']
# 关闭文件
f.close()
打开文件的模式:
r
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件指针将会放在文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
寄存区的缓冲:
小于 0 的整数:系统默认设置寄存区的大小
0:不进行寄存
1:进行寄存
大于 1 的整数:整数即为寄存区的缓冲区大小
Python read和write方法:
read():
从文件中读取字符串
注:Python 字符串可以是二进制数据,而不仅仅是文字。
语法:
文件对象.read([count])
count:打开文件需要读取的字符数
注:read 函数不使用 count 会尽可能多地读取更多的内容,通常一直读取到文件末尾
# 使用 count
# 打开创建好的 test.txt 文件
f = open("test.txt",'r')
# 输出文件的前 11 个字符
print(f.read(11))
# 关闭文件
f.close()
# hello,world
文件位置:
tell():
返回文件内当前指向的位置
f = open("test.txt",'r')
# 输出文件的前 11 个字符
f.read(11)
print(f.tell())
# 11
seek(offset [,from]):
改变当前文件的位置
offset:表示要移动的字节数
from :指定开始移动字节的参考位置。
0:文件开头
1:当前位置
2:文件末尾
# 打开创建好的 test.txt 文件
f = open("test.txt",'r')
# 输出文件的前 11 个字符
print(f.read(11))
# hello,world
# 返回文件内当前指向的位置
print(f.tell())
# 11
print(f.seek(0,0))
# 0
print(f.tell())
# 0
print(f.read(11))
# hello,world
# 关闭文件
f.close()
write( ):
将任意字符串写入一个文件中
注:Python字符串可以是二进制数据 和 文字,换行符('\n') 需要自己添加
语法:
文件对象.write(字符串)
程序:
# write 方法
# 打开创建好的 test.txt 文件
f = open("test.txt",'w')
# 在开头,添加文件内容
f.write('hey boy')
# 关闭文件
f.close()
PythonFile对象的属性:
一个文件被打开后,使用对象进行接收,接收的对象即为 File 对象
file.closed
返回true如果文件已被关闭,否则返回false
file.mode
返回被打开文件的访问模式
file.name
返回文件的名称
file = open("test.txt",'r')
# file.name 返回文件的名称
print(file.name)
# test.txt
# file.closed 如果文件未关闭返回 False
print(file.closed)
# False
# file.mode 返回被打开文件的访问模式
print(file.mode)
# r
# file.closed 如果文件已关闭返回 True
file.close()
print(file.closed)
# True
os 的方法:
mkdir(目录名):
在当前目录下创建新的目录
程序:
import os
# 创建新的目录-包结构
os.mkdir('新目录-test')
getcwd()方法:
显示当前的工作目录。
程序:
import os
print(os.getcwd())
# G:\code\time
chdir(修改的目录名):
修改当前的目录名为 修改的目录名
程序:
import os
# 创建新的目录-包结构
print(os.getcwd())
# D:\见解\Python\Python代码\vacation\备课\新目录-test
os.chdir('新目录-test2')
print(os.getcwd())
# D:\见解\Python\Python代码\vacation\备课\新目录-test\新目录-test2
rmdir(目录名):
删除目录
注:目录名下为空,没有其他文件
程序:
import os
os.rmdir('新目录-test2')
删除后包文件消失
rename(当前的文件名,新文件名):
将当前的文件名修改为新文件名
程序:
# os.rename('旧名字',’新名字‘)
import os
os.rename('旧名字.txt','新名字.txt')
remove(文件名):
删除文件
程序:
import os
os.remove('名称.txt')
'''
编程完成一个简单的学生管理系统,要求如下:
(1)使用自定义函数,完成对程序的模块化
(2)学生信息至少包括:姓名、性别及手机号
(3)该系统具有的功能:添加、删除、修改、显示、退出系统
设计思路如下:
(1) 提示用户选择功能序号
(2) 获取用户选择的能够序号
(3) 根据用户的选择,调用相应的函数,执行相应的功能
'''
stu_lst = [[],[],[],[],[]]
# 创建存储五个学生的容器
def show_gn():
'''展示学生管理系统的功能'''
print("==========================")
print("学生管理系统v1.0")
print("1.添加学生信息(请先输入1)")
print("2.删除学生信息")
print("3.修改学生信息")
print("4.显示所有学生信息")
print("0.退出系统")
print("==========================")
def tj_gn(num):
'''添加功能'''
stu_lst[num].append(input("请输入新学生的名字:"))
# 第一个参数为新学生的名字
stu_lst[num].append(input("请输入新学生的性别:"))
# 第二个参数为新学生的性别
stu_lst[num].append(input("请输入新学生的手机号:"))
# 第三个参数为新学生的手机号
stu_lst[num].append(num)
# 第四个参数为新学生的默认学号(从 0 开始)
def sc_gn():
'''删除功能'''
stu_xlh = int(eval(input("请输入需要删除的学生序列号:")))
xs_gn_returni = xs_gn(stu_xlh)
pd_str = input("请问确定删除吗? 请输入全小写字母 yes / no ? ")
# pd_str 判断是否删除学生信息
if pd_str == 'yes':
del stu_lst[xs_gn_returni]
print("删除完毕")
if pd_str == 'no':
print("删除失败")
def xg_gn():
'''修改功能'''
stu_xlh = int(eval(input("请输入需要修改的学生序列号:")))
xs_gn_returni = xs_gn(stu_xlh)
# xs_gn_returni 接收的是如果存在输入的学生序列号,则返回经过确认的索引下标
xg_str = input("请问需要修改该名学生哪一处信息,请输入提示后面的小写字母 (姓名)name,(性别)sex,(手机号)sjh")
if xg_str in ['name','sex','sjh']:
if xg_str == 'name':
stu_lst[xs_gn_returni][0] = input("请输入新的姓名值")
elif xg_str == 'sex':
stu_lst[xs_gn_returni][1] = input("请输入新的性别值")
else:
stu_lst[xs_gn_returni][2] = input("请输入新的手机号值")
else:
print("输入错误")
def xs_gn(stu_xlh = -1):
'''显示功能'''
print("姓名性别手机号序列号信息如下")
if stu_xlh == -1:
for i in stu_lst:
if i != []:
print(i)
else:
for i in range(len(stu_lst)):
if stu_xlh in stu_lst[i] and i != []:
print("该学生信息如下:")
print(stu_lst[i])
return i
show_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
# gn_num 功能对应的数字
num = 0
while 0 <= gn_num < 1000:
if gn_num == 1:
tj_gn(num)
num += 1
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 2:
sc_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 3:
xg_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 4:
xs_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 0:
print("退出系统")
exit()
else:
print("请重新运行该程序,输入的数字不在 0~4 之中")
exit()
a = 10
b = 8
print("a>b") if a>b else pass
pass 为何报错问题:
第一部分:print
第二部分:("a>b") if a>b else pass
第一种情况 print ("a>b")
第二种情况 print(pass)
pass 关键字,不用于输出,导致出错
Python 实现分层聚类算法
'''
1.将所有样本都看作各自一类
2.定义类间距离计算公式
3.选择距离最小的一堆元素合并成一个新的类
4.重新计算各类之间的距离并重复上面的步骤
5.直到所有的原始元素划分成指定数量的类
程序要点:
1.生成测试数据
sklearn.datasets.make_blobs
2.系统聚类算法
sklearn.cluster.AgglomerativeClustering
3.必须满足该条件不然会报错(自定义函数中的参数)
assert 1 <= n_clusters <= 4
4.颜色,红绿蓝黄
r g b y
5. o * v +
散点图的形状
6.[] 内可以为条件表达式,输出数组中满足条件的数据
data[predictResult == i]
7.访问 x 轴,y 轴坐标
subData[:,0] subData[:,1]
8.plt.scatter(x轴,y轴,c,marker,s=40)
colors = "rgby"
markers = "o*v+"
c 颜色 c=colors[i]
marker 形状 marker=markers[i]
9.生成随机数据并返回样本点及标签
data,labels = make_blobs(n_samples=200,centers=4)
make_blobs 为 sklearn.datasets.make_blobs 库
n_samples 为需要的样本数量
centers 为标签数
'''
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import AgglomerativeClustering
def AgglomerativeTest(n_clusters):
assert 1 <= n_clusters <= 4
predictResult = AgglomerativeClustering(
n_clusters=n_clusters,
affinity='euclidean',
linkage='ward'
).fit_predict(data)
# 定义绘制散点图时使用的颜色和散点符号
colors = "rgby"
markers = "o*v+"
# 依次使用不同的颜色和符号绘制每个类的散点图
for i in range(n_clusters):
subData = data[predictResult == i]
plt.scatter(
subData[:,0],
subData[:,1],
c = colors[i],
marker = markers[i],
s = 40
)
plt.show()
# 生成随机数据,200个点,4类标签,返回样本及标签
data , labels = make_blobs(n_samples=200,centers=4)
print(data)
AgglomerativeTest(2)
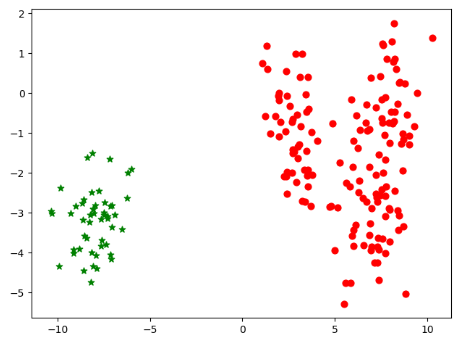
KNN算法基本原理与sklearn实现
'''
KNN 近邻算法,有监督学习算法
用于分类和回归
思路:
1.在样本空间中查找 k 个最相似或者距离最近的样本
2.根据这 k 个最相似的样本对未知样本进行分类
步骤:
1.对数据进行预处理
提取特征向量,对原来的数据重新表达
2.确定距离计算公式
计算已知样本空间中所有样本与未知样本的距离
3.对所有的距离按升序进行排列
4.选取与未知样本距离最小的 k 个样本
5.统计选取的 k 个样本中每个样本所属类别的出现概率
6.把出现频率最高的类别作为预测结果,未知样本则属于这个类别
程序要点:
1.创建模型需要用到的包
sklearn.neighbors.KNeighborsClassifier
2.创建模型,k = 3
knn = KNeighborsClassifier(n_neighbors = 3)
n_neighbors 数值不同,创建的模型不同
3.训练模型,进行拟合
knn.fit(x,y)
x 为二维列表数据
x = [[1,5],[2,4],[2.2,5],
[4.1,5],[5,1],[5,2],[5,3],[6,2],
[7.5,4.5],[8.5,4],[7.9,5.1],[8.2,5]]
y 为一维分类数据,将数据分为 0 1 2 三类
y = [0,0,0,
1,1,1,1,1,
2,2,2,2]
4.进行预测未知数据,返回所属类别
knn.predict([[4.8,5.1]])
5.属于不同类别的概率
knn.predict_proba([[4.8,5.1]])
'''
from sklearn.neighbors import KNeighborsClassifier
# 导包
x = [[1,5],[2,4],[2.2,5],
[4.1,5],[5,1],[5,2],[5,3],[6,2],
[7.5,4.5],[8.5,4],[7.9,5.1],[8.2,5]]
# 设置分类的数据
y = [0,0,0,
1,1,1,1,1,
2,2,2,2]
# 对 x 进行分类,前三个分为 0类,1类和2类
knn = KNeighborsClassifier(n_neighbors=3)
# 创建模型 k = 3
knn.fit(x,y)
# 开始训练模型
'''
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights='uniform')
'''
knn.predict([[4.8,5.1]])
# array([1]) 预测 4.8,5.1 在哪一个分组中
knn = KNeighborsClassifier(n_neighbors=9)
# 设置参数 k = 9
knn.fit(x,y)
'''
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=9, p=2,
weights='uniform')
'''
knn.predict([[4.8,5.1]])
# array([1])
knn.predict_proba([[4.8,5.1]])
# 属于不同类别的概率
# array([[0.22222222, 0.44444444, 0.33333333]])
# 返回的是在不同组的概率
'''
总结:
knn = KNeighborsClassifier(n_neighbors=3)
使用 KNeighborsClassifier 创建模型 n_neighbors 为 k
使用 knn.fit() 进行预测
第一个参数为 二维列表
第二个参数为 一维列表
使用 predict_proba([[num1,num2]])
查看num1,num2 在模型中出现的概率
'''
'''
程序要点:import numpy as np
1.查看 e 的 多少次方
np.exp(参数)
2.查看参数的平方根
np.sqrt(参数)
3.生成三维四列的随机值(-1,1)之间
np.random.random((3,4))
4.向下取整
a = np.floor(参数)
5.将矩阵拉平
a.ravel()
6.修改矩阵的形状
a.shape(6,2)
7.将矩阵转置
a.T
8.将矩阵横行进行拼接
a = np.floor(参数)
b = np.floor(参数)
np.hstack((a,b))
9.将矩阵纵行进行拼接
np.vstack((a,b))
10.按照行进行切分数组,切分为3份
np.hsplit(a,3)
注:第二个参数可以为元组(3,4)
11.按照列进行切分数组,切分为2份
np.vsplit(a,2)
'''
import numpy as np
a = np.floor(10 *np.random.random((3,4)))
'''
array([[6., 8., 0., 9.],
[9., 3., 7., 4.],
[2., 4., 9., 1.]])
'''
np.exp(a)
'''
array([[4.03428793e+02, 2.98095799e+03, 1.00000000e+00, 8.10308393e+03],
[8.10308393e+03, 2.00855369e+01, 1.09663316e+03, 5.45981500e+01],
[7.38905610e+00, 5.45981500e+01, 8.10308393e+03, 2.71828183e+00]])
'''
np.sqrt(a)
'''
array([[2.44948974, 2.82842712, 0. , 3. ],
[3. , 1.73205081, 2.64575131, 2. ],
[1.41421356, 2. , 3. , 1. ]])
'''
a.ravel()
'''array([6., 8., 0., 9., 9., 3., 7., 4., 2., 4., 9., 1.])'''
a = np.floor(10 *np.random.random((3,4)))
b = np.floor(10 *np.random.random((3,4)))
np.hstack((a,b))
'''
array([[8., 2., 3., 8., 0., 1., 8., 6.],
[7., 1., 0., 3., 1., 9., 6., 0.],
[6., 0., 6., 6., 4., 3., 6., 3.]])
'''
np.vstack((a,b))
'''
array([[8., 2., 3., 8.],
[7., 1., 0., 3.],
[6., 0., 6., 6.],
[0., 1., 8., 6.],
[1., 9., 6., 0.],
[4., 3., 6., 3.]])
'''
a = np.floor(10 *np.random.random((2,12)))
np.hsplit(a,3)
'''
[array([[6., 4., 2., 2.],
[6., 2., 2., 8.]]), array([[1., 8., 8., 8.],
[1., 9., 3., 6.]]), array([[2., 6., 0., 8.],
[7., 1., 4., 3.]])]
'''
a = np.floor(10 *np.random.random((12,2)))
np.vsplit(a,3)
'''
[array([[2., 6.],
[7., 1.],
[4., 7.],
[3., 1.]]), array([[2., 5.],
[4., 6.],
[2., 0.],
[4., 4.]]), array([[9., 5.],
[7., 1.],
[2., 1.],
[5., 1.]])]
'''
注:上中下的这三篇随笔,在分类方面都会比较乱.
不同复制操作对比(三种)
'''
1.b = a
b 发生变化 a 也会发生变化
2.浅复制
c = a.view()
c.shape 发生变化,a.shape 不会发生变化
c 和 a 共用元素值,id 指向不同
c[1,0] = 1234 , a 的值也会发生变化
3.深复制
d = a.copy()
d[0,0] = 999
d 发生改变,a 不会发生改变
'''
import numpy as np
a = np.arange(1,8)
# array([1, 2, 3, 4, 5, 6, 7])
b = a
b[2] = 999
b
# array([ 1, 2, 999, 4, 5, 6, 7])
a
# array([ 1, 2, 999, 4, 5, 6, 7])
a = np.arange(1,9)
c = a.view()
c.shape = 4,2
'''
array([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
'''
a
# array([1, 2, 3, 4, 5, 6, 7, 8])
d = a.copy()
d[3] = 888
d
# array([ 1, 2, 3, 888, 5, 6, 7, 8])
a
# array([1, 2, 3, 4, 5, 6, 7, 8])
'''
1.查看列上最大索引的位置
data.argmax(axis = 0)
2.输出索引位置上的元素
data[index,range(data.shape[1])]
使用 range 输出几个元素
3.对numpy 对象进行扩展
a = np.array([4,5,6,2])
np.tile(a,(2,3))
4.对数组按行排序,从小到大
a = np.array([[4,3,5],[1,7,6]])
np.sort(a,axis = 1)
5.对数组元素进行排序,返回索引下标
a = np.array([4,3,1,2])
j = np.argsort(a)
a[j]
'''
import numpy as np
data = np.array([
[4,5,6,8],
[7,4,2,8],
[9,5,4,2]
])
data.argmax(axis = 0)
# array([2, 0, 0, 0], dtype=int64)
data.argmax(axis = 1)
# array([3, 3, 0], dtype=int64)
index = data.argmax(axis = 0)
# array([9, 5, 6, 8])
a = np.array([4,5,6,2])
np.tile(a,(2,3))
'''
array([[4, 5, 6, 2, 4, 5, 6, 2, 4, 5, 6, 2],
[4, 5, 6, 2, 4, 5, 6, 2, 4, 5, 6, 2]])
'''
a = np.array([[4,3,5],[1,7,6]])
'''
array([[4, 3, 5],
[1, 7, 6]])
'''
np.sort(a,axis = 1)
'''
array([[3, 4, 5],
[1, 6, 7]])
'''
np.sort(a,axis = 0)
'''
array([[1, 3, 5],
[4, 7, 6]])
'''
a = np.array([4,3,1,2])
j = np.argsort(a)
# array([1, 2, 3, 4])
正则表达式
1. /b 和 /B
# /bthe 匹配任何以 the 开始的字符串
# /bthe/b 仅匹配 the
# /Bthe 任何包含但并不以 the 作为起始的字符串
2. [cr] 表示 c 或者 r
[cr][23][dp][o2]
一个包含四个字符的字符串,第一个字符是“c”或“r”,
然后是“2”或“3”,后面 是“d”或“p”,最后要么是“o”要么是“2”。
例如,c2do、r3p2、r2d2、c3po等
3.["-a]
匹配在 34-97 之间的字符
4.Kleene 闭包
* 匹配 0 次或 多次
+ 匹配一次或 多次
? 匹配 0 次或 1 次
5.匹配全部有效或无效的 HTML 标签
</?[^>]+>
6.国际象棋合法的棋盘移动
[KQRBNP][a-h][1-8]-[a-h][1-8]
从哪里开始走棋-跳到哪里
7.信用卡号码
[0-9]{15,16}
8.美国电话号码
\d{3}-/d{3}-/d{4}
800-555-1212
9.简单电子邮件地址
\w+@\w+\.com
[email protected]
10.使用正则表达式,使用一对圆括号可以实现
对正则表达式进行分组
匹配子组
对正则表达式进行分组可以在整个正则表达式中使用重复操作符
副作用:
匹配模式的子字符串可以保存起来
提取所匹配的模式
简单浮点数的字符串:
使用 \d+(\.\d*)?
0.004 2 75.
名字和姓氏
(Mr?s?\.)?[A-Z][a-z]*[A-Za-z-]+
11.在匹配模式时,先使用 ? ,实现前视或后视匹配 条件检查
(?P<name>) 实现分组匹配
(?P:\w+\.)* 匹配以 . 结尾的字符串
google twitter. facebook.
(?#comment) 用作注释
(?=.com) 如果一个字符串后面跟着 .com 则进行匹配
(?<=800-) 如果一个字符串之前为 800- 则进行匹配
不使用任何输入字符串
(?<!192\.168\.) 过滤掉一组 C 类 IP 地址
(?(1)y|x) 如果一个匹配组1(\1) 存在,就与y匹配,否则与x匹配
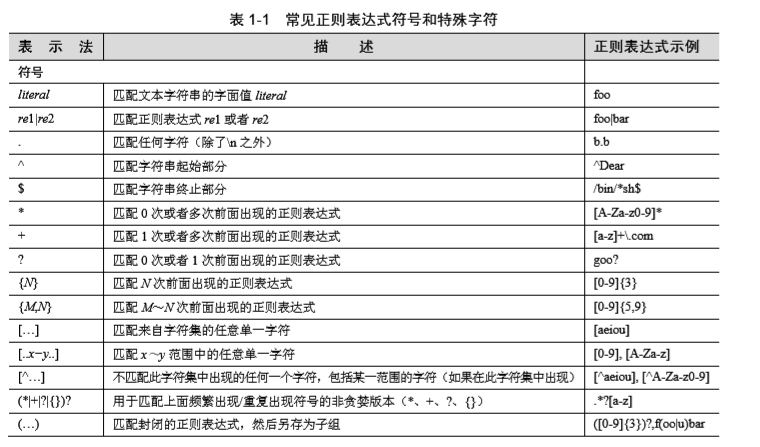
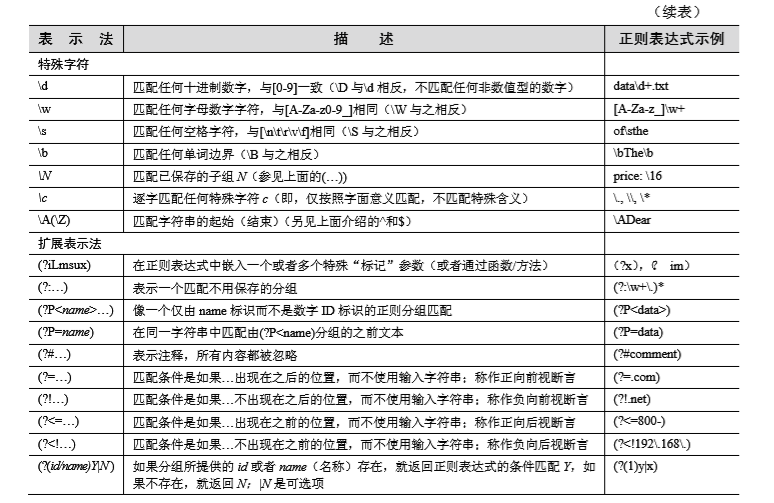










Pandas 复习
1.导包
import pandas as pd
2.数据读取,文件在该代码文件夹内
food_info = pd.read_csv('food_info.csv')
3.查看类型
food_info.dtypes
4.查看前五条数据
food_info.head()
查看前三条数据
food_info.head(3)
5.查看后四行数据
food_info.tail(4)
6.查看列名
food_info.columns
7.查看矩阵的维度
food_info.shape
8.取出第 0 号数据
food_info.loc[0]
使用切片获取数据
food_info.loc[3:6]
使用索引获取数据
food_info.loc['Name']
获取多个列
columns = ["Price","Name"]
food_info.loc[columns]
9.将列名放入到列表中
col_names = food_info.columns.tolist()
10.查看以 d 结尾的列
for c in col_names:
c.endswith("d")
11.将商品价格打一折
food_info["Price"]/10
12.最大值 最小值 均值
food_info["Price"].max()
food_info["Price"].min()
food_info["Price"].mean()
13.根据某一列进行排序
升序:
food_info.sort_values["Price",inplace=True]
降序:
food_info.sort_values["Price",inplace=True,ascending=False]
14.查看该数值是否为 NaN
price = food_info["Price"]
price_is_null = pd.isnull(price)
food_info[price_is_null]
Pandas 复习2
import pandas as pd
import numpy as np
food_info = pd.read_csv('food_info.csv')
1.处理缺失值(可使用平均数,众数填充)
查看非缺失值的数据:
price_is_null = pd.isnull(food_info["Price"])
price = food_info["Price"][price_is_null==False]
使用 fillna 填充
food_info['Price'].fillna(food_info['Price'].mean(),inplace = True)
2.求平均值
food_info["Price"].mean()
3.查看每一个 index 级,values 的平均值
food_info.pivot(index = "",values = "",aggfunc = np.mean)
4.查看总人数
food_info.pivot(index = "",values = ["",""],aggfunc = np.sum)
5.丢弃缺失值
dropna_columns = food_info.dropna(axis = 1)
将 Price 和 Time 列存在 NaN 的行去掉
new_food_info = food_info.dropna(axis = 0,subset = ["Price","Time"])
6.定位具体值到 83
row_index_83_price = food_info.loc[83,"Price"]
7.进行排序(sort_values 默认升序)
new_food_info.sort_values("Price")
8.将索引值重新排序,使用 reset_index
new_food_info.reset_index(drop = True)
9.使用 apply 函数
new_food_info.apply(函数名)
10.查看缺失值的个数
def not_null_count(column):
column_null = pd.isnull(column)
# column_null 为空的布尔类型
null = column[column_null]
# 将为空值的列表传递给 null
return len(null)
column_null_count = food_info.apply(not_null_count)
11.划分等级:年龄 成绩
def which_class(row):
pclass = row["Pclass"]
if pd.isnull(pclass):
return "未知等级"
elif pclass == 1:
return "第一级"
elif pclass == 2:
return "第二级"
elif pclass == 3:
return "第三级"
new_food_info.apply(which_class,axis = 1)
12.使用 pivot_table 展示透视表
new_food_info.pivot_table(index = " ",values=" ")
Series结构(常用)
1.创建 Series 对象
fandango = pd.read_csv("xxx.csv")
series_rt = fandango["RottenTomatoes"]
rt_scores = series_rt.values
series_film = fandango["FILM"]
# 获取数据 使用 .values
film_names = series_film.values
series_custom = Series(rt_scores,index = film_names)
2.使用切片获取数据
series_custom[5:10]
3.转换为列表
original_index = series_custom.index.tolist()
4.进行排序,此时的 original_index 是一个列表
sorted_index = sorted(original_index)
5.排序索引和值
series_custom.sort_index()
series_custom.sort_values()
6.将大于 50 的数据输出
series_custom[series_custom > 50]
7.设置索引值
fandango.set_index("FILM",drop = False)
8.显示索引值
fandango.index
9.显示数据类型
series_film.dtypes
10.在 apply 中使用匿名函数
series_film.apply(lambda x : np.std(x),axis = 1)
部分画图
import pandas as pd
unrate = pd.read_csv("unrate.csv")
1.转换日期时间
unrate["date"] = pd.to_datetime(unrate["DATE"])
import matplotlib.pyplot as plt
2.画图操作
plt.plot()
传递 x y 轴,绘制折线图
plt.plot(unrate["date"],unrate["values"])
3.展示
plt.show()
4.对 x 轴上的标签倾斜 45 度
plt.xticks(rotation = 45)
5.设置 x 轴 y 轴标题
plt.xlabel("xxx")
plt.ylabel("xxx")
6.设置名字
plt.title("xxx")
fig = plt.figure()
7.绘制子图
fig.add_subplot(行,列,x)
x 表示 在第几个模块
fig.add_subplot(4,3,1)
8.创建画图区域时指定大小
fig = plt.figure((3,6))
长为 3 宽为 6
9.画线时指定颜色
plt.plot(x,y,c="颜色")
10.将每一年的数据都显示出来
fig = plt.figure(figsize = (10,6))
colors = ['red','blue','green','orange','black']
# 设置颜色
for i in range(5):
start_index = i*12
end_index = (i+1)*12
# 定义开始和结束的位置
subset = unrate[start_index:end_index]
# 使用切片
label = str(1948 + i)
# 将标签 动态命名
plt.plot(subset['month'],subset['value'],c = colors[i],label = label)
# 进行绘制
plt.legend(loc = 'best')
loc = upper left 显示在左上角
# 打印右上角的数据
plt.show()
# 展示
11.柱状图:
明确:柱与柱之间的距离,柱的高度
高度:
cols = ['FILM','XXX','AAA','FFF','TTT','QQQ']
norm_reviews = reviews[cols]
num_cols = ['A','B','C','D','E','F']
bar_heights = norm_reviews.ix[0,num_cols].values
# 将每一列的高度都存起来
位置(距离 0 的距离):
bar_positions = arange(5) + 0.75
fig,ax = plt.subplots()
ax.bar(bar_positions,bar_heights,0.3)
先写位置后写距离
0.3 表示柱的宽度
ax.barh() 表示横着画
plt.show()
12.散点图
fig,ax = plt.subplots()
# 使用 ax 进行画图,ax 画图的轴,fig 图的样子
ax.scatter(norm_reviews['A'],norm_reviews['B'])
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
# 使用 add_subplot 绘制子图
fig = plt.figure(figsize = (5,10))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax1.scatter(x,y)
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax2.scatter(x2,y2)
ax2.set_xlabel('x')
ax2.set_ylabel('y')
plt.show()
13.当存在多个值时,可以指定区间进行画图
# 指定 bins 默认为 10
fig,ax = plt.subplots()
ax.hist(unrate['Price'],bins = 20)
ax.hist(unrate['Price'],range(4,5),bins = 20)
14.设置 x y 区间
sey_xlim(0,50)
set_ylim(0,50)
15.盒图:
num_cols = ['AA','BB','CC','DD']
fig,ax = plt.subplots()
ax.boxplot(norm_reviews[num_cols].values)
# 绘制盒图
ax.set_xticklabels(num_cols,rotation = 45)
# 设置 x 轴标签,并倾斜45度
ax.set_ylim(0,5)
# 设置 y 的区间
plt.show()
16.去掉图标后的尺
ax.tick_params(bottom = "off",top = "off",left = "off",right = "off")
17.展示在右上角
ax.legend(loc = "upper right")
提取txt文本有效内容
from re import sub
from jieba import cut
def getWordsFromFile(txtFile):
# 获取每一封邮件中的所有词语
words = []
# 将所有存储邮件文本内容的记事本文件都使用 UTF8 编码
with open(txtFile,encoding = "utf8") as fp:
for line in fp:
# 遍历每一行,删除两端的空白字符
line = line.strip()
# 过滤掉干扰字符
line = sub(r'[.【】 0-9、-。,!~\*]','',line)
# 对 line 进行分词
line = cut(line)
# 过滤长度为 1 的词
line = filter(lambda word:len(word) > 1 ,line)
# 将文本预处理得到的词语添加到 words 列表中
words.extend(line)
return words
chain 和 Counter
from collections import Counter
from itertools import chain
1.使用 chain 对 allwords 二维列表进行解包
解包: chain(*allwords)
将 allwords 里面的子列表解出来
2.获取有效词汇的数目
freq = Counter(chain(*allwords))
3.Counter 返回的是可迭代对象出现的次数
使用 most_common 方法返回出现次数最多的前三个
.most_common(3)
Counter ("dadasfafasfa")
Counter({'a': 5, 'f': 3, 'd': 2, 's': 2})
Counter ("dadasfafasfa").most_common(2)
[('a', 5), ('f', 3)]
1.特征向量
每一个有效词汇在邮件中出现的次数(使用一维列表方法)
word 词汇出现的次数
一维列表.count(word)
2.将列表转换为数组形式 array(参数)
创建垃圾邮件,正常邮件训练集
array(列表对象 或 表达式)
3.使用 朴素贝叶斯算法
model = MultinomialNB()
4.进行训练模型 model.fit
model.fit(array数组,array数组)
5.对指定 topWords 数据使用函数
map(lambda x:words.count(x),topWords)
6.预测数据 model.predict ,返回值为 0 或 1
result = model.predict(array数组.reshape(1,-1))[0]
7.查看在不同区间的概率
model.predict_proba(array数组.reshape(1,-1))
8.条件语句,预测的结果便于区分 1 为垃圾邮件,0 为 正常邮件
return "垃圾邮件" if result == 1 else "正常邮件"
函数进阶1
'''
1.print "a>b" if a>b else pass 出错问题
pass 不可以被输出,导致报错
2.定义函数:
def 函数名():
return 可选
3.print 输出时会运行函数
print func_name()
注:func_name 中有 print 后,最好不要再使用 print 输出
会返回两个结果
4.最好让函数拥有返回值,便于维护
没有返回值会返回 None
5.如何制造函数:
抽象需求,注意可维护性
当创造方法时,注意可维护性和健壮性
6.参数使用 * 号,函数内为元组对象
7.可选参数存在默认值,必选参数没有默认值
8.健壮性:
直到函数会返回什么(异常处理,条件判断)
返回的结果是你需要的
9.测试时使用断言 assert
程序:'''
def func_name():
return 1
print(func_name())
# 1
def func_name2():
print("hello")
print(func_name2())
# hello
# None
def add(num1,num2):
return num1 + num2
print(add(5,6))
# 11
def add(*num):
d = 0
for i in num:
d += i
return d
print(add(1,2,3,4))
# 10
def add(num1,num2 = 4):
return num1 + num2
print(add(5))
# 9
print(add(5,8))
# 13
def add(num1,num2):
# 健壮性
if isinstance(num1,int) and isinstance(num2,int):
return num1 + num2
else:
return "Error"
print(add('a',(1,2,3)))
# Error
print(add(3,4))
# 7
'''
1.在循环中不要使用 排序函数
2.解决问题先要有正确的思路
写出伪代码
第一步做什么
第二步做什么
...
慢慢实现
3.使用 filter 函数
当函数中参数类型为 int 时才进行比较
def func(*num):
num = filter(lambda x:isinstance(x,int),num)
4.参数为 module ,将参数输出
print("doc %s"%module)
5.不要将代码复杂化,让人一看到就知道实现了什么功能
6.os.path.exists(file) 作为条件判断语句,看是否存在该 file 文件
7.检测函数 assert:
类型断言、数据断言
8.将问题实现的越简单越好,测试完整
9.使用下划线或驼峰命名函数名
get_doc getDoc
10.伪代码:
将思路写出来
11.默认值的好处:
省事,方便配置,多写注释
传入参数的数据类型
返回的数据的类型
12.测试
程序:'''
def function(*num):
# 输出 最大值和最小值
num = filter(lambda x : isinstance(x,int),num)
# 过滤掉不是 int 类型的数据
a = sorted(num)
return "max:",a[-1],"min:",a[0]
print(function(5,6,"adaf",1.2,99.5,[4,5]))
# ('max:', 6, 'min:', 5)
Python异常及异常处理:
当程序运行时,发生的错误称为异常
例:
0 不能作为除数:ZeroDivisionError
变量未定义:NameError
不同类型进行相加:TypeError
异常处理:
'''
try:
执行代码
except:
发生异常时执行的代码
执行 try 语句:
如果发生异常,则跳转到 except 语句中
如果没有异常,则运行完 try 语句,继续 except 后面的语句
'''
False:布尔类型,假。当条件判断不成立时,返回False。
# == 判断两个对象的值是否相等
print('' == False)
# False
print(None == False)
# False
print([] == False)
# False
print(() == False)
# False
print({} == False)
# False
# is 判断两个对象是否引用自同一地址空间
print('' is False)
# False
print(None is False)
# False
print([] is False)
# False
print(() is False)
# False
print({} is False)
# False
正则表达式补充2
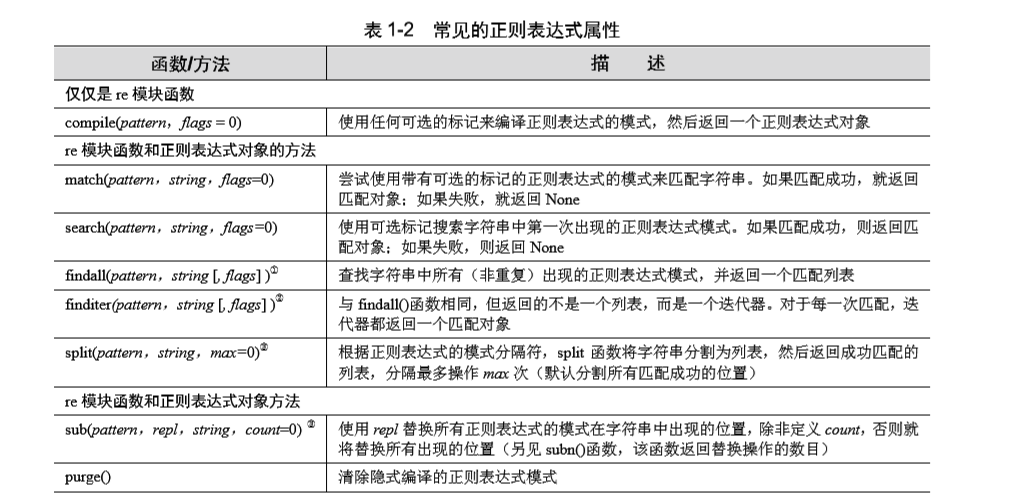
正则表达式基础1
'''
1.指定 eval()调用一个代码对象会提高性能
2.在进行模式匹配之前,正则表达式的模式必须编译为正则表达式对象
匹配时需要进行多次匹配,进行预编译可以提升速度
re.compile(pattern,flags = 0)
3.消除缓存
re.purge()
4.使用 re.S 后 . 可以匹配换行符 \n
5.使用了match() 和 search() 方法之后返回的对象称为匹配对象
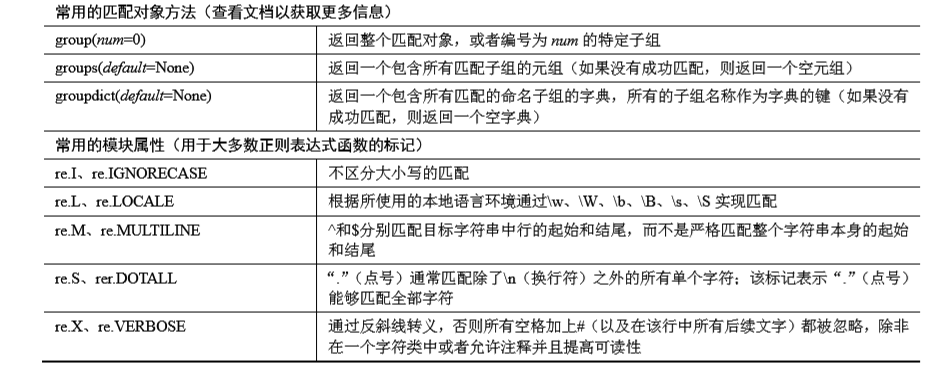
匹配对象常用 group() 和 groups() 方法
group() 返回整个匹配对象 或 特定子组
groups() 返回一个包含唯一 或 全部子组的元组
6.match() 方法 对字符串的起始部分进行模式匹配
成功:返回一个匹配对象
失败:返回 None
7.search() 方法 对字符串任意位置进行模式匹配
成功:返回匹配对象
失败:返回 None
8.可以使用 pos , endpos 参数指定目标字符串的搜索范围
9.使用 . 匹配任何单个字符
.end 不能匹配 end
不能匹配 \n 换行符
使用 \. 匹配 .
10.创建字符集 [ ]
[cr][23] 表示 匹配第一个字符 c 或者 r
第二个字符 2 或者 3
程序:'''
import re
# match(pattern,string,flags = 0) 匹配示例
m = re.match('foo','foo')
if m is not None:
# 如果匹配成功则输出匹配内容
print(m.group())
# print(m.groups()) 返回空元组 因为没有子组
# foo
# 匹配对象具有 group() 和 groups() 方法
print(m)
# <re.Match object; span=(0, 3), match='foo'>
# search(pattern,string,flags = 0) 匹配示例
m = re.search('foo','sea food')
if m is not None:
print(m.group())
# foo
print(m)
# <re.Match object; span=(4, 7), match='foo'>
# 返回第四个元素的位置
# | 或 示例
bt = 'bat|bet'
m = re.match(bt,'bat')
# match 只匹配开头
m2 = re.search(bt,'abat')
# search 从开始到结尾
print(m.group())
# bat
print(m2.group())
# bat
# . 匹配任意字符示例
anyend = '.end'
m = re.match(anyend,'aend')
print(m.group())
# aend
m2 = re.search(anyend,'abcdend')
print(m2.group())
# dend
pi_pattern = '3.14'
m = re.match(pi_pattern,'3.14')
print(m.group())
# 3.14
pi_pattern = '3\.14'
# 将 . 转义
m = re.match(pi_pattern,'3.14')
print(m.group())
# 3.14
# [ ] 创建字符集
m = re.match('[cr][23][dp][po]','c3po')
print(m.group())
# c3po
m = re.match('[cr][23][dp][po]','c2do')
print(m.group())
# c2do
两数相加(B站看视频总结)
'''
两数相加:
给出两个 非空 的链表用来表示两个非负的整数
各自的位数是按照逆序的方式存储的 每一个节点只能保存 一位数
示例:
输入:(2->4->3) + (5->6->4)
输出:7->0->8
原因:342 + 465 = 807
'''
class ListNode:
def __init__(self,x):
# 在类声明时进行调用
self.val = x
self.next = None
# self 指的是自身,在类中声明函数需要添加才可以访问自身元素和其他函数
a = ListNode(10086)
# print(a,a.val)
# <__main__.ListNode object at 0x000001F76D46A148> 10086
# # 实现尾部元素指向头部元素
# move = a
# for i in range(4):
# temp = ListNode(i)
# # temp 为 ListNode 节点
# move.next = temp
# # move 下面的节点为 temp
# move = move.next
# # 将节点向下移动
# move.next = a
# # 重新指向头节点 a
class Solution1:
def addTwoNumbers(self,l1:ListNode,l2:ListNode) ->ListNode:
res = ListNode(10086)
move = res
carry = 0
# 进位
while l1 != None or l2 != None:
if l1 == None:
l1,l2 = l2,l1
# 替换位置,将 l1 作为输出
if l2 == None:
carry,l1.val = divmod((l1.val + carry),10)
# 对 l1 进行刷新
move.next = l1
# 设置数据
l1,l2,move = l1.next,l2.next,move.next
# 将数据向下移动
else:
carry,l1.val = divmod((l1.val + l2.val + carry),10)
# 如果都不为 None,则对应位置进行相加,然后进行求余
move.next = l1
# 更新数据
l1,move = l1.next,move.next
# 向下移动
if carry == 1:
move.next = ListNode(carry)
return res.next
class ListNode:
def __init__(self,x):
# 在类声明时进行调用
self.val = x
self.next = None
# self 指的是自身,在类中声明函数需要添加才可以访问自身元素和其他函数
# a = ListNode(10086)
# 使用迭代写法
class Solution1:
def addTwoNumbers(self,l1:ListNode,l2:ListNode) -> ListNode:
def recursive(n1,n2,carry = 0):
if n1 == None and n2 == None:
return ListNode(1) if carry == 1 else None
# 如果存在进位 则 输出 1
if n1 == None:
n1,n2 = n2,n1
# 当 n1 为空时 将位置替换
return recursive(n1,None,carry)
# 进行递归 使用 n1 进行递归
if n2 == None:
carry,n1.val = divmod((n1.val + carry),10)
# 返回值为 进位和数值 将 n1 的值进行替换
n1.next = recursive(n1.next,None,carry)
# 对 n1 接下来的数据继续进行调用,更新 n1 链表
return n1
carry,n1.val = divmod((n1.val + n2.val + carry),10)
# 当不存在空值时,进行相加,更新 n1 值
n1.next = recursive(n1.next,n2.next,carry)
# 设置 n1 接下来的值为 所有 n1 和 n2 接下来的运算调用
return n1
return recursive(l1,l2)
# 返回到内部函数中
猜数字游戏
'''
分析:
参数->指定整数范围,最大次数
在指定范围内随机产生一个整数,让用户猜测该数
提示,猜大,猜小,猜对
给出提示,直到猜对或次数用尽
'''
import random
def fail(os_num):
'''输入数字范围错误,没有猜数字次数'''
print("猜数失败")
print("系统随机的数为:", os_num)
print("游戏结束,欢迎下次再来玩")
return
def cxsr(count):
'''重新输入一个数'''
count -= 1
print("提示:您还有 %d 次机会" % (count))
if count == 0:
fail(os_num)
else:
user_cs = int(eval(input("请重新输入一个 0~8 之间的整数:\n")))
csz(os_num,count,user_cs)
def csz(os_num,count,user_cs,num_range = 8):
'''这是一个猜数字的函数'''
# num_range 是整数范围,count为最大次数,user_cs 为用户猜到的数
if user_cs > num_range or user_cs < 0 :
print("请重新运行,输入错误~")
return
if count == 0:
fail()
else:
if os_num > user_cs:
print("您猜的数字比系统产生的随机数小")
cxsr(count)
elif os_num < user_cs:
print("您猜的数字比系统产生的随机数大")
cxsr(count)
else:
print("恭喜您,猜对了~")
print("欢迎下次再玩!")
os_num = random.randint(0,8)
# os_num 为系统产生的随机数
print("游戏开始~")
user_cs = int(eval(input("这是一个猜数字的游戏(您有三次猜数字的机会),请输入一个 0~8 之间的整数\n")))
# user_cs 为用户猜到的数
csz(os_num,3,user_cs)
由于以前的随笔中的习题和我手里现存的题太多了,大约1000多道左右,所以此处不做整理了.只做一些知识点上的积累
函数进阶3
'''
1.考虑可维护性
一行代码尽量简单
列表推导式 lambda 匿名函数
2.断言语句用于自己测试,不要写在流程控制中
assert 不要写在 for 循环中
3.程序的异常处理 参数处理
try 异常处理 ,参数类型是什么
4.函数->尽量不要在特定环境下使用
5.断言就是异常->出错了就会抛出异常
6.局部变量和全局变量的区别:
当局部变量与全局变量重名时,生成一个在局部作用域中的变量
使用 global 声明 可以让局部变量修改为全局变量
7.参数为可变参数时,使用索引下标会修改原数据
程序:'''
def func1(num1,num2):
return num1 + num2
# 打印变量名
print(func1.__code__.co_varnames)
# ('num1', 'num2')
print(func1.__code__.co_filename)
# 文件名
# 第六点:
arg = 6
def add(num = 3):
arg = 4
return arg + num
print(add())
# 7
arg = 6
def add(num = 3):
# 使用 global 声明
global arg
return arg + num
print(add())
# 9
函数进阶4
'''
1.匿名函数:
一个表达式,没有 return
没有名称
执行很小的功能
2.判断参数是否存在 如果不存在会怎样->给出解决办法
3.可以使用 filter 和 lambda 进行使用
如果不进行 list 转换,则只返回 filter 对象
4.参数:
位置匹配:
func(name)
关键字匹配:
func(key = value)
从最右面开始赋予默认值
收集匹配:
元组收集
func(name,arg1,arg2)
func(*args)
字典收集
func(name,key1 = value1,key2 = value2)
func(**kwargs)
参数顺序
5.递归:
递归就是调用自身
程序:'''
# 第一点:
d = lambda x:x+1
print(d(2))
# 3
d = lambda x:x + 1 if x > 0 else "不大于0"
print(d(3))
# 4
print(d(-3))
# 不大于0
# 列表推导
g = lambda x:[(x,i) for i in range(5)]
print(g(5))
# 只传递了一个参数
# [(5, 0), (5, 1), (5, 2), (5, 3), (5, 4)]
# 第三点:
t = [1,4,7,8,5,3,9]
g = list(filter(lambda x: x > 5,t))
# 使用 list 将结果转换为列表
print(g)
# [7, 8, 9]
# 第四点:
# 对应位置传递参数
def func(arg1,arg2,arg3):
return arg1,arg2,arg3
print(func(1,2,3))
# (1, 2, 3)
# 关键字匹配,不按照位置进行匹配
def func(k1 = '',k2 = '',k3 = ''):
return k1,k2,k3
print(func(k2 = 4 , k3 = 5 , k1 = 3))
# (3, 4, 5)
# 收集匹配
# 元组
def func(*args):
return args
print(func(5,6,7,8,[1,2,3]))
# (5, 6, 7, 8, [1, 2, 3])
def func(a,*args):
# 先匹配 a 后匹配 *args
return args
print(func(5,6,7,8,[1,2,3]))
# (6, 7, 8, [1, 2, 3])
# 字典
def func(**kwargs):
return kwargs
print(func(a = 5,b = 8))
# {'a': 5, 'b': 8}
列表推导式
lst = [1,2,3]
lst2 = [1,2,3,5,1]
lst3 = [1,2]
lst4 = [1,2,3,65,8]
lst5 = [1,2,3,59,5,1,2,3]
def length(*args):
# 返回长度
lens = []
lens = [len(i) for i in args]
return lens
print(length(lst,lst2,lst3,lst4,lst5))
# [3, 5, 2, 5, 8]
dic = dict(zip(['a','b','c','d','e'],[4,5,6,7,8]))
lst = ["%s : %s" %(key,value) for key,value in dic.items()]
print(lst)
# ['a : 4', 'b : 5', 'c : 6', 'd : 7', 'e : 8']
关于类和异常的笔记
原文链接:https://www.runoob.com/python/python-object.html
面向对象技术简介
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
局部变量:定义在方法中的变量,只作用于当前实例的类。
实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
class ClassName:
'类的帮助信息' #类文档字符串
class_suite #类体
类的帮助信息可以通过ClassName.__doc__查看
class_suite 由类成员,方法,数据属性组成
实例
以下是一个简单的 Python 类的例子:
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用 Employee.empCount 访问。
第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法
self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.__class__ 则指向类。
self 不是 python 关键字
"创建 Employee 类的第一个对象"
emp1 = Employee("Hany", 9000)
访问属性
可以使用点号 . 来访问对象的属性。使用如下类的名称访问类变量:
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
可以添加,删除,修改类的属性,如下所示:
del emp1.age # 删除 'age' 属性
你也可以使用以下函数的方式来访问属性:
getattr(obj, name[, default]) : 访问对象的属性。
hasattr(obj,name) : 检查是否存在一个属性。
setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
delattr(obj, name) : 删除属性。
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。
getattr(emp1, 'age') # 返回 'age' 属性的值
setattr(emp1, 'age', 8) # 添加属性 'age' 值为 8
delattr(emp1, 'age') # 删除属性 'age'
Python内置类属性
__dict__ : 类的属性(包含一个字典,由类的数据属性组成)
__doc__ :类的文档字符串
__name__: 类名
__module__: 类定义所在的模块(类的全名是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
__bases__ : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
Python内置类属性调用实例如下:
python对象销毁(垃圾回收)
Python 使用了引用计数这一简单技术来跟踪和回收垃圾。
在 Python 内部记录着所有使用中的对象各有多少引用。
一个内部跟踪变量,称为一个引用计数器。
当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为0 时, 它被垃圾回收。但是回收不是"立即"的,
由解释器在适当的时机,将垃圾对象占用的内存空间回收。
a = 40 # 创建对象 <40>
b = a # 增加引用, <40> 的计数
c = [b] # 增加引用. <40> 的计数
del a # 减少引用 <40> 的计数
b = 100 # 减少引用 <40> 的计数
c[0] = -1 # 减少引用 <40> 的计数
垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。
这种情况下,仅使用引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。
作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
析构函数 __del__ ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行:
类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
class 派生类名(基类名)
...
在python中继承中的一些特点:
1、如果在子类中需要父类的构造方法就需要显式的调用父类的构造方法,或者不重写父类的构造方法。详细说明可查看: python 子类继承父类构造函数说明。
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
3、Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class Parent: # 定义父类
parentAttr = 100
def __init__(self):
print "调用父类构造函数"
def parentMethod(self):
print '调用父类方法'
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print "父类属性 :", Parent.parentAttr
class Child(Parent): # 定义子类
def __init__(self):
print "调用子类构造方法"
def childMethod(self):
print '调用子类方法'
c = Child() # 实例化子类
c.childMethod() # 调用子类的方法
c.parentMethod() # 调用父类方法
c.setAttr(200) # 再次调用父类的方法 - 设置属性值
c.getAttr() # 再次调用父类的方法 - 获取属性值
以上代码执行结果如下:
调用子类构造方法
调用子类方法
调用父类方法
父类属性 : 200
你可以继承多个类
class A: # 定义类 A
.....
class B: # 定义类 B
.....
class C(A, B): # 继承类 A 和 B
.....
可以使用issubclass()或者isinstance()方法来检测。
issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
下表列出了一些通用的功能:
1 __init__ ( self [,args...] )
构造函数
简单的调用方法: obj = className(args)
2 __del__( self )
析构方法, 删除一个对象
简单的调用方法 : del obj
3 __repr__( self )
转化为供解释器读取的形式
简单的调用方法 : repr(obj)
4 __str__( self )
用于将值转化为适于人阅读的形式
简单的调用方法 : str(obj)
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods
Python 通过改变名称来包含类名:
Traceback (most recent call last):
File "test.py", line 17, in <module>
print counter.__secretCount # 报错,实例不能访问私有变量
AttributeError: JustCounter instance has no attribute '__secretCount'
Python不允许实例化的类访问私有数据,但可以使用 object._className__attrName( 对象名._类名__私有属性名 )访问属性:
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
原文链接:https://www.runoob.com/python3/python3-class.html
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
类定义
语法格式如下:
class ClassName:
<statement-1>
.
.
.
<statement-N>
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名:
类有一个名为 __init__() 的特殊方法(构造方法),该方法在类实例化时会自动调用
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
继承
Python 同样支持类的继承,如果一种语言不支持继承,类就没有什么意义。派生类的定义如下所示:
class DerivedClassName(BaseClassName1):
<statement-1>
.
.
.
<statement-N>
BaseClassName(示例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
class DerivedClassName(modname.BaseClassName):
多继承
Python同样有限的支持多继承形式。多继承的类定义形如下例:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
类的实例化对象不能访问类中的私有属性
类的专有方法:
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
Python 子类继承父类构造函数说明
原文链接:https://www.runoob.com/w3cnote/python-extends-init.html
如果在子类中需要父类的构造方法就需要显式地调用父类的构造方法,或者不重写父类的构造方法。
子类不重写 __init__,实例化子类时,会自动调用父类定义的 __init__。
父类名称.__init__(self,参数1,参数2,...)
实例
class Father(object):
def __init__(self, name):
self.name=name
print ( "name: %s" %( self.name))
def getName(self):
return 'Father ' + self.name
class Son(Father):
def __init__(self, name):
super(Son, self).__init__(name)
print ("hi")
self.name = name
def getName(self):
return 'Son '+self.name
if __name__=='__main__':
son=Son('runoob')
print ( son.getName() )
输出结果为:
name: runoob
hi
Son runoob
Python 异常(菜鸟教程)
原文:https://www.runoob.com/python/python-exceptions.html
BaseException 所有异常的基类
SystemExit 解释器请求退出
KeyboardInterrupt 用户中断执行(通常是输入^C)
Exception 常规错误的基类
StopIteration 迭代器没有更多的值
GeneratorExit 生成器(generator)发生异常来通知退出
StandardError 所有的内建标准异常的基类
ArithmeticError 所有数值计算错误的基类
FloatingPointError 浮点计算错误
OverflowError 数值运算超出最大限制
ZeroDivisionError 除(或取模)零 (所有数据类型)
AssertionError 断言语句失败
AttributeError 对象没有这个属性
EOFError 没有内建输入,到达EOF 标记
EnvironmentError 操作系统错误的基类
IOError 输入/输出操作失败
OSError 操作系统错误
WindowsError 系统调用失败
ImportError 导入模块/对象失败
LookupError 无效数据查询的基类
IndexError 序列中没有此索引(index)
KeyError 映射中没有这个键
MemoryError 内存溢出错误(对于Python 解释器不是致命的)
NameError 未声明/初始化对象 (没有属性)
UnboundLocalError 访问未初始化的本地变量
ReferenceError 弱引用(Weak reference)试图访问已经垃圾回收了的对象
RuntimeError 一般的运行时错误
NotImplementedError 尚未实现的方法
SyntaxError Python 语法错误
IndentationError 缩进错误
TabError Tab 和空格混用
SystemError 一般的解释器系统错误
TypeError 对类型无效的操作
ValueError 传入无效的参数
UnicodeError Unicode 相关的错误
UnicodeDecodeError Unicode 解码时的错误
UnicodeEncodeError Unicode 编码时错误
UnicodeTranslateError Unicode 转换时错误
Warning 警告的基类
DeprecationWarning 关于被弃用的特征的警告
FutureWarning 关于构造将来语义会有改变的警告
OverflowWarning 旧的关于自动提升为长整型(long)的警告
PendingDeprecationWarning 关于特性将会被废弃的警告
RuntimeWarning 可疑的运行时行为(runtime behavior)的警告
SyntaxWarning 可疑的语法的警告
UserWarning 用户代码生成的警告
什么是异常?
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
以下为简单的try....except...else的语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
使用except而不带任何异常类型
你可以不带任何异常类型使用except,如下实例:
try:
正常的操作
......................
except:
发生异常,执行这块代码
......................
else:
如果没有异常执行这块代码
以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
使用except而带多种异常类型
你也可以使用相同的except语句来处理多个异常信息,如下所示:
try:
正常的操作
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
发生以上多个异常中的一个,执行这块代码
......................
else:
如果没有异常执行这块代码
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "Error: 没有找到文件或读取文件失败"
如果打开的文件没有可写权限,输出如下所示:
try:
fh = open("testfile", "w")
try:
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "关闭文件"
fh.close()
except IOError:
print "Error: 没有找到文件或读取文件失败"
当在try块中抛出一个异常,立即执行finally块代码。
finally块中的所有语句执行后,异常被再次触发,并执行except块代码。
变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。
元组通常包含错误字符串,错误数字,错误位置。
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
实例
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
定义一个异常非常简单,如下所示:
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行
注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串。
例如我们捕获以上异常,"except"语句如下所示:
try:
正常逻辑
except Exception,err:
触发自定义异常
else:
其余代码
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def mye( level ):
if level < 1:
raise Exception,"Invalid level!"
# 触发异常后,后面的代码就不会再执行
try:
mye(0) # 触发异常
except Exception,err:
print 1,err
else:
print 2
执行以上代码,输出结果为:
$ python test.py
1 Invalid level!
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
Python3 错误和异常
原文链接:
https://www.runoob.com/python3/python3-errors-execptions.html

异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
大多数的异常都不会被程序处理,都以错误信息的形式展现在这里:
实例
>>> 10 * (1/0) # 0 不能作为除数,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ZeroDivisionError: division by zero
>>> 4 + spam*3 # spam 未定义,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: name 'spam' is not defined
>>> '2' + 2 # int 不能与 str 相加,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 ZeroDivisionError,NameError 和 TypeError。
错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
异常处理
try/except
异常捕捉可以使用 try/except 语句。
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
try 语句按照如下方式工作;
首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
如果没有异常发生,忽略 except 子句,try 子句执行后结束。
如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
pass
try/except...else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。
以下实例在 try 语句中判断文件是否可以打开,如果打开文件时正常的没有发生异常则执行 else 部分的语句,读取文件内容:
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。例如:
>>> def this_fails():
x = 1/0
>>> try:
this_fails()
except ZeroDivisionError as err:
print('Handling run-time error:', err)
Handling run-time error: int division or modulo by zero
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
以下实例中 finally 语句无论异常是否发生都会执行:
实例
try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
以下实例如果 x 大于 5 就触发异常:
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
执行以上代码会触发异常:
Traceback (most recent call last):
File "test.py", line 3, in <module>
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
Exception: x 不能大于 5。x 的值为: 10
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>> try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere
用户自定义异常
你可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承,例如:
>>> class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
>>> try:
raise MyError(2*2)
except MyError as e:
print('My exception occurred, value:', e.value)
My exception occurred, value: 4
>>> raise MyError('oops!')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
__main__.MyError: 'oops!'
在这个例子中,类 Exception 默认的 __init__() 被覆盖。
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
大多数的异常的名字都以"Error"结尾,就跟标准的异常命名一样。
定义清理行为
try 语句还有另外一个可选的子句,它定义了无论在任何情况下都会执行的清理行为。 例如:
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
KeyboardInterrupt
以上例子不管 try 子句里面有没有发生异常,finally 子句都会执行。
如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后被抛出。
预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
这面这个例子展示了尝试打开一个文件,然后把内容打印到屏幕上:
for line in open("myfile.txt"):
print(line, end="")
以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:
for line in f:
print(line, end="")
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
Python assert(断言)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况
语法格式如下:
assert expression
等价于:
if not expression:
raise AssertionError
assert 后面也可以紧跟参数:
assert expression [, arguments]
等价于:
if not expression:
raise AssertionError(arguments)
非常感谢菜鸟教程.
以下为网址:
https://www.runoob.com/
以前学习的时候会经常翻阅,学习一些编程知识
已附上原文链接,推荐到原链接进行访问,毕竟显示效果会差很多
类 巩固小结
'''
1.当方法具有结构时,使用 class 比函数要好
2.类中定义的 方法 或 属性 如果没有声明权限
在类外使用实例化对象可以直接访问
3.类中的方法,第一个参数一定要写上 self ,self 是约定好的
4.析构方法通常调用不到,垃圾回收机制中引用计数后会自动销毁
5.写程序之前:
伪代码 小的程序->直接写流程
大项目-> 先分析结构
6.父类通常具有一些公共的方法,使用子类进行扩展
子类可以使用父类中定义的初始化方法 __init__ , 但是参数可能不全
7.找到最小的节点,将节点与节点之间发生的关系使用不同的类进行标识
8._xxx, __xxx 外界都不应该直接访问,放到类中的方法中使用
9.方法一定要先实现再进行优化
10.使用装饰器 @property 后 下面的方法会变为属性
@property
def function(self,args):
pass
类实例化对象.function 调用 function 方法
11.@staticmethod 静态方法,下面的方法声明为"内置方法"
不需要再使用 self 进行调用
@staticmethod
def function(object):pass
12.最小惊讶原则
让很多人一看就知道在写什么
13.注意代码的复杂度
'''
# 示例:
class stu(object):
# 继承 object 基类
a = 'a'
# 定义一个属性
def __init__(self,name,age):
# 初始化赋值
self.name = name
self.age = age
def showName(self):
print(self.name)
def __del__(self):
# 析构方法,通常自动销毁
del self.name
del self.age
student = stu('张三',20)
student.showName()
print(student.a)
# 输出类中的属性
# a
class stu_extends(stu):
""" 继承 stu 类"""
pass
class lst_extends(list):
def append(self):
pass
# 继承列表类
模块小结
1.import 模块名(文件)
导入模块
2.查看模块内的方法
dir(模块名)
3.if __name__ == "__main__":
需要测试的语句
4.from 模块名 import 方法/属性/*
再使用时 使用 方法即可 不再使用模块名.方法
5.使用 __all__ = ["方法1","方法2","属性名1","属性名2"]
在导入 * 时,只导入该 all 中的方法或属性
在 __init__.py 文件第一行
6.import 模块名(文件) as 模块别名
7.搜索模块:
import sys
sys.path.append(r'绝对路径')
绝对路径指 导入的模块的 文件夹的位置
a.py 程序:
import linecache
print(linecache.__file__)
def show( ):
print("我是 0411 的模块")
程序:
import linecache
# 导入模块
print(dir(linecache))
# 查看都具有哪些方法
'''
['__all__', '__builtins__', '__cached__',
'__doc__', '__file__', '__loader__', '__name__',
'__package__', '__spec__', 'cache', 'checkcache',
'clearcache', 'functools', 'getline', 'getlines',
'lazycache', 'os', 'sys', 'tokenize', 'updatecache']
'''
linecache.__file__
# 查看模块地址
# F:\Python IDLE\lib\linecache.py
from math import pi
import sys
sys.path.append(r'D:\见解\Python\Python代码\学习\0411')
if __name__ == "__main__":
# 执行文件时,进行测试
print(linecache.__file__)
# F:\Python IDLE\lib\linecache.py
print(pi)
# 使用 math 中的 pi 属性
# 3.141592653589793
import a
# 导入 0411 的 a.py 文件
a.show()
# 我是 0411 的模块
以下部分内容为对以前内容的巩固,部分存在重复现象.
异常 巩固1
'''
1.索引异常
IndexError: list index out of range
2.语法异常
SyntaxError
3.缩进异常
IndentationError: unexpected indent
4.try 语句完整形态:try except else finally
5.try 内的语句 出错之后不会运行出现异常之后的 try 内语句
6.开发某些功能时 任何地方都可能会出错
通常参数传递过来时
读取某些未知文件时
打开某个网页时
7.except 捕获正确的异常,对异常进行处理
程序:'''
# lst = [1,2,3,4,5]
# print(lst[5])
# 索引异常,不存在下标为 5 的元素
# IndexError: list index out of range
# print 444
# 语法异常
# SyntaxError
# print(444)
# 缩进异常
# IndentationError: unexpected indent
lst = [1,2,3,4,5]
try :
print(lst[5])
print("出错之后不会运行出现异常之后的语句")
except IndexError as e :
'''try 出现异常时执行'''
print("出现索引异常")
else:
'''try 正常运行时执行'''
print("程序运行 OK, 没有问题")
finally:
print("无论是否出错一定会运行到 finally")
# 出现索引异常
# 无论是否出错一定会运行到 finally
异常 巩固2
'''
1.找到可能会抛出异常的地方,仅对这几行代码进行异常处理
2.明确会出现的异常类型
缩进,类型,语法,索引等等
3.捕获出现的异常
import sys
exc = sys.exc_info()
exc[1] 为问题出现的原因
4.日志 logging 模块
import logging
logger = logging.getLogger()
# 获取日志对象
logfile = 'test.log'
hdlr = logging.FileHandler('senging.txt')
# 存储文件日志
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
# 以什么格式进行存储,时间,等级,日志信息
hdlr.setFormatter(formatter)
# 导入日志格式
logger.addHandler(hdlr)
# 将日志绑定
logger.setLevel(logging.NOTSET)
# 设置日志级别
5.断言 assert
assert 表达式,出错以后抛出的提示信息
表达式 : 1 > 4 3 > 2 1 == 2
断言绝对不能发生的错误,然后再处理异常
程序:'''
import logging
logger = logging.getLogger()
# 获取日志对象
logfile = 'test.log'
hdlr = logging.FileHandler('senging.txt')
# 存储文件日志
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
# 以什么格式进行存储,时间,等级,日志信息
hdlr.setFormatter(formatter)
# 导入日志格式
logger.addHandler(hdlr)
# 将日志绑定
logger.setLevel(logging.NOTSET)
# 设置日志级别
import sys
try:
print(a)
except:
exc = sys.exc_info()
print(exc[1])
# 查看异常的问题
# name 'a' is not defined
print(exc[0])
# <class 'NameError'>
print(exc)
# (<class 'NameError'>, NameError("name 'a' is not defined"),
# <traceback object at 0x000002A8BD9DA188>)
logging.debug(exc[1])
附:日志这个还是很不错的,以下为显示的内容,会将错误保存起来,便于以后的查看
2020-07-25 09:51:01,344 DEBUG name 'a' is not defined
logging 日志基础
import logging
logger = logging.getLogger()
# 获取日志对象
logfile = 'test.log'
hdlr = logging.FileHandler('senging.txt')
# 存储文件日志
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
# 以什么格式进行存储,时间,等级,日志信息
hdlr.setFormatter(formatter)
# 导入日志格式
logger.addHandler(hdlr)
# 将日志绑定
logger.setLevel(logging.NOTSET)
# 设置日志级别
注:此处只是显示了拥有哪些方法,具体实例还需要进行查阅相关资料
异常 巩固3
'''
1.with open("文件路径","模式") as fp:
操作
进入时 调用 __enter__ 方法
def __enter__(self):
print("开始执行 with 方法")
退出时 调用 __exit__ 方法
def __exit__(self,type,value,traceback):
print("退出 with 方法")
2.文件操作方法:
打开、读取、关闭
d = open('a','r')
d.read()
d.close()
3.可以自己定义异常,继承 Exception 类
程序:'''
# 查看 with 执行的方法
class sth(object):
def __enter__(self):
print("开始执行 with 方法")
def __exit__(self,type,value,traceback):
print("退出 with 方法")
with sth( ) as fp:
# with 自动关闭文件
pass
# 自定义异常
class myException(Exception):
# 继承 Exception
def __init__(self,error,msg):
self.args = (error,msg)
self.error = error
self.msg = msg
try:
raise myException(1,'my exception')
except Exception as e :
print(str(e))
# (1, 'my exception')
多线程复习1
多线程复习1
'''
1.进程在运行时会创建一个主线程,每一个进程只有一个主线程
2.子进程 pid 唯一标识符
3.任意时间里,只有一个线程在运行,且运行顺序不能确定(全局锁限制)
4.threading.Thread(target = test,args = [i])
target = 函数名 ,args = [ 参数 ]
5.可以继承 threading.Thread 然后重写 run 方法
class myThread(threading.Thread):
def run():
pass
程序:'''
import threading
# 导入线程库
def test():
print(1)
a = threading.Thread(target = test)
# 创建 a 线程
b = threading.Thread(target = test)
a.start()
# 启动线程
b.start()
a.join()
b.join()
# 结束之前使用 join 等待其他线程
import threading
# 导入线程库
import time
def test(i):
time.sleep(0.1)
print(i)
tests_thread = []
for i in range(0,10):
threads = threading.Thread(target = test,args = [i])
# 创建 a 线程
tests_thread.append(threads)
for i in tests_thread:
i.start()
# 启动线程
for i in tests_thread:
i.join()
# 结束之前使用 join 等待其他线程
print("线程结束")
'''
运行结果
2
0
1
8
7
9
6
534
线程结束
'''
多线程复习2
import time
def func_a():
print("a 函数开始")
time.sleep(2)
print("a 函数结束")
def func_b():
print("b 函数开始")
time.sleep(2)
print("b 函数结束")
b_time = time.time()
func_a()
func_b()
print(time.time() - b_time)
# 查看运行多少秒
'''
运行结果:
a 函数开始
a 函数结束
b 函数开始
b 函数结束
4.00050163269043
'''
import threading
import time
def func_a():
print("a 函数开始")
time.sleep(2)
print("a 函数结束")
def func_b():
print("b 函数开始")
time.sleep(2)
print("b 函数结束")
b_time = time.time()
_a = threading.Thread(target = func_a)
_b = threading.Thread(target = func_b)
_a.start()
_b.start()
# 开始
_a.join()
_b.join()
# 等待
print(time.time() - b_time)
# 查看时间
'''
运行结果:
a 函数开始
b 函数开始
b 函数结束a 函数结束
2.001542091369629
'''
通过使用了线程和不使用线程的对比,使用了线程的要快很多
线程里面的加锁和释放锁
# 加锁和释放
import threading
mlock = threading.Lock()
# 创建一把锁, mlock
# 当存在死锁时,防止死锁 可重用锁
num = 0
def a():
global num
mlock.acquire()
# 加锁
num += 1
mlock.release()
# 释放锁
print(num)
for i in range(10):
d = threading.Thread(target = a)
d.start()
'''
1.协程,微型进程:
yield 生成器
yield 会保存声明的变量,可以进行迭代
使用 接收函数返回的对象.__next__()
next(接收函数返回的对象)
.send() 方法
传递给函数中 yield 声明的对象
x = yield i
会发送给 x 变量
如果一直没有使用 send() ,x 值一直为 None
赋值之后如果没有修改则 x 一直为 send 后的值
2.此时 x 的值为 None ,并没有将 i 赋值给 x
x = yield i
程序:'''
# 创建一个包含 yield 声明的函数
def test_yield():
i = 0
a = 4
while i < a:
x = yield i
# x 通过 gener 进行赋值
i += 1
# 使用 .__next__() 查看迭代对象
gener = test_yield()
print(gener.__next__())
# 0
print(gener.__next__())
# 1
print(next(gener))
# 2
gener.send("x 通过 gener 进行赋值")
for i in test_yield():
# i 在 test_yield 中 yield 声明的迭代对象中
print(i,end = " ")
# 0 1 2 3
解决素数(质数)
def is_sushu(int_num):
# 判断输入的数是否为质数
if int_num == 1:
return False
if int_num == 2:
return True
else:
for i in range(2,int_num):
if int_num % i == 0:
return False
return True
def _get_sushu(max_num):
return [i for i in range(1,max_num) if is_sushu(i)]
# 使用列表推导式
if __name__ == "__main__":
a = _get_sushu(101)
# 返回判断素数的列表
print(a)
爬虫流程复习
设置爬虫终端:
URL 管理器 -> 网页下载器 -> 网页解析器 -> 产生价值数据
URL 管理器判断爬取网页链接
流程:
调度器询问 URL 管理器,是否存在要爬取的 URL
URL 管理器返回 是或否
调度器 从 URL 管理器中 取出一个 URL
URL 管理器 将 URL 传递给调度器
调度器将 URL 发送到下载器
下载器将 URL 下载的内容传递给调度器
调度器将 URL 下载的内容传递给解析器
解析器解析后传递给调度器
此时可以收集价值数据 调度器再将需要爬取的 URL 传递给 URL管理器 一直到没有需要爬取的 URL
URL 管理器:
管理待爬取的 URL 集合和已经爬取的 URL 集合
使用管理器是为了防止重复抓取和防止重复抓取一个 URL
URL 功能:
添加新的 URL 到待爬取的集合中
确定待添加的 URL 是否在 URL 中
获取待爬取的 URL
将 URL 从待爬取的移动到已爬取的集合中
判断是否还有待爬取的数据
URL 管理器实现方式:
将 待爬取的 和 已爬取的 URL 存储在集合中
set()
将 URL 存储在 关系数据库中,区分 URL 是待爬取还是已经爬取
MySQL urls(url,is_crawled)
缓存数据库 redis
网页下载器:
将 URL 对应的网页转换为 HTML 数据
存储到本地文件或者内存字符串中
requests 、 urllib 库实现下载
特殊情景处理器:
需要使用 Cookie 访问时:HTTPCookieProcessor
需要使用 代理 访问时:ProxyHandler
需要使用 加密 访问时:HTTPHandler
网页存在跳转关系访问时:HTTPRedirectHandler
网页解析器:
从网页提取有价值的数据
HTML 网页文档字符串
提取出价值数据
提取出新的 URL 列表
正则表达式 -> 模糊匹配
文档作为字符串,直接匹配
html.parser
BeautifulSoup -> 可以使用 html.parser 和 lxml
从 HTML 和 XHTML 中提取数据
语法:
创建 BeautifulSoup 对象
搜索节点 findall find
访问节点(名称,属性,文字)
lxml
->结构化解析
DOM 树
进行上下级的遍历
html
head
title
文本
body
a
href
文本
div
文本
爬虫:
确定目标
分析目标
URL 格式
数据的链接
数据的格式
网页编码
编写代码
执行爬虫
列表常用方法复习:
列表的常用操作:
1.使用 索引下标 或 切片
查找对应元素的值
修改特定位置上的值
2.删除列表元素
del 对象
对象.pop(index=-1)
对象.remove(元素)
对象.clear()
3.查看列表长度
len(对象)
4.重复 n 次
对象 * n
5.拼接两个列表对象
对象 + 对象
6.查看某一个元素是否在对象中
元素 in 对象
7.列表作为可迭代对象使用
for i in 对象
for i in range(len(对象))
8.列表可以嵌套
[[],[],[]]
9.列表内元素类型可以是任意类型
[任意类型,任意类型]
10.查看列表中最大值 最小值
max(对象) min(对象)
11.将其他类型数据转换为列表对象
list(对象)
list(可迭代对象)
12.在尾部增加元素
整体添加 对象.append(元素)
解包添加 对象.extend(元素)
13.在任意位置添加
对象.insert(index,元素)
14.排序
对象.sort()
倒序 对象.reverse()
15.查看元素索引位置
对象.index(元素)
字典常用操作复习
字典的常用操作:
1.创建字典对象
dict.fromkeys(seq[,value])
dic = {key1:value1,key2,value2}
dic = dict(zip([keys],[values]))
2.使用 对象['键值'] 访问字典元素
3.修改字典
对象['键值'] = 对象
4.删除字典元素或字典对象
del 对象['键值']
del 对象
对象.clear()
对象.pop(key)
对象.popitem()
5.获取字典长度
len(对象)
6.复制字典
对象.copy()
对象.update(对象2)
7.获取指定键值的元素
对象.get(key[,default=None])
8.查看 键 是否在字典中
key in 对象
9.获取字典中的元素
对象.keys()
对象.values()
对象.items()
10.对某一个元素设置默认值 如果该键已有值 则设置无效
对象.setdefault(key,default = None)
将"089,0760,009"变为 89,760,9
remove_zeros = lambda s: ','.join(map(lambda sub: str(int(sub)), s.split(',')))
remove_zeros("089,0760,009")
Linux最常用的基本操作复习
1.ctrl + shift + = 放大终端字体
2.ctrl + - 缩小终端字体
3.ls 查看当前文件夹下的内容
4.pwd 查看当前所在的文件夹
5.cd 目录名 切换文件夹
6.touch 如果文件不存在 则创建文件
创建一个文档
7.mkdir 创建目录
创建一个文件夹
8.rm 删除指定的文件名
9.clear 清屏
python连接数据库 MySQLdb 版本
import MySQLdb
# 导入 MySQL 库
class MysqlMethod(object):
def __init__(self):
# 前提:能够连接上数据库
self.get_connect()
def get_connect(self):
# 获取连接
try:
self.conn = MySQLdb.connect(
host = '127.0.0.1',
# 主机
user = 'root',
# 用户名
passwd = 'root',
# 密码
db = 'python_prac',
# 数据库
port = 3306,
# 端口号
charset = 'utf8'
# 避免字符编码问题
)
except MySQLdb.Error as e:
print("连接数据库时,出现错误")
print("错误信息如下:\n %s"%e)
else:
print("连接 MySQL 成功!")
def close_connect(self):
# 关闭连接
try:
# 关闭连接
self.conn.close()
# 关闭数据库连接
except MySQLdb.Error as e:
print("关闭数据库时出现错误")
print("错误信息如下:\n %s"%e)
else:
print("退出成功,欢迎下次使用!")
def get_onedata(self):
# 获取一条数据
cursor = self.conn.cursor()
# 获取游标
sql = 'select * from students where age between %s and %s'
# 查询语句
cursor.execute(sql,(15,25))
# execute(语句,(参数))
result = dict(zip([k[0] for k in cursor.description],cursor.fetchone()))
'''
zip(列表推导式,获取到的值)
字典的键:描述数据的值
字典的值:获取到的值
例:
lst_keys = ['a','b','c']
lst_values = [1,2,3]
dict(zip(lst_keys,lst_values))
得到的结果:
{'a': 1, 'b': 2, 'c': 3}
'''
# 元组类型转换为字典,便于通过索引查找数据
print("获取到一条数据:")
return result
def get_moredata(self,page,page_size):
# 添加多条数据
offset = (page - 1) * page_size
# 起始位置
cursor = self.conn.cursor()
sql = 'select * from students where age between %s and %s limit %s,%s;'
cursor.execute(sql,(15,45,offset,page_size))
result = list(dict(zip([k[0] for k in cursor.description],row)) for row in cursor.fetchall())
'''
使用 zip 将 列名 和 获取到的数据 压缩为一个个单独的二元组
但类型为 <class 'zip'> 需要进行转换才能看到具体的值
zip([k[0] for k in cursor.description],row)
('id', 1)···
使用 dict 将 zip 类型转换为字典类型
dict(zip([k[0] for k in cursor.description],row))
{'id': 1,···}
使用 列表推导式 将每一个 row 变为查找到的多个数据中的一个
原理:[元素操作 for 元素 in 序列对象]
list -> []
list[ row 的操作 for row in 数据集]
'''
print("获取到多条数据:")
# result 为[{},{}] 形式
return result
def insert_onedata(self):
# 添加一条数据
try:
sql = "insert into stu_0415(name,school) values (%s,%s);"
# 查询语句
cursor = self.conn.cursor()
# 获取游标
need_info = ('王五','厦大')
# 需要插入的数据
cursor.execute(sql,need_info)
# 运行 sql 语句
self.conn.commit()
# 提交,如果没有提交,数据库数据不会发生变化
except :
print("插入数据失败")
self.conn.rollback()
# 如果个别数据插入成功了,则也不算入数据库
print("插入数据成功")
def main():
sql_obj = MysqlMethod()
# 创建一个 sql 对象
data = sql_obj.get_onedata()
# 获取一条数据
print(data)
moredata = obj.get_moredata(1,5)
# 查看 0~5 的数据
for item in moredata:
print(item)
# 循环遍历输出字典对象
print("-------------")
obj.insert_onedata()
# 插入一条数据
if __name__ == '__main__':
main()
# 运行主程序
显示列表重复值
lst = [1,2,3,2,1,5,5]
lst = list(filter(lambda x:lst.count(x) != 1,lst))
此处使用了 filter 和 lambda 进行混合使用,
x 为 lst 中的元素
应用场景
列表常用场景:
存储不同类型的数据
任意类型均可
列表存储相同类型的数据
类 node结点 next、data
通过迭代遍历,在循环体内部(多为 while 内),对列表的每一项都进行遍历
树的深度遍历等等
列表推导式的使用等等
元组常用场景:
作为函数的参数和返回值
传递任意多个参数 *args
函数内为元组形式
一次返回多个数据
return (a,b) 或 a,b
return a,b,c
接收函数返回值时
value1,value2 = 函数(参数)
函数(参数)即为 return (a,b)
格式化字符串
s1 = "%s %s"
s2 = ('hello','world')
s1%s2
'hello world'
数据库execute语句
cursor.execute(sql,(15,25))
让列表不可以被修改,保护数据
tuple(list对象)
字典常用场景:
for in 遍历字典
dic = {'a':1,'b':2,'c':3}
遍历键值:
for key in dic.keys():
print(key,end = " ")
遍历值:
for value in dic.values():
print(value,end = " ")
遍历键值对:
for key,value in dic.items():
print(key,":",value,end = " ")
使用字典(多个键值对)存储一个物体的信息
{"name":"张三","age":23}
将多个字典放到列表中,循环时对每一个字典进行相同操作
students_info = [{"name":"张三","age":23},{"name":"李四","age":22}]
访问张三数据:
students_info[0]['name']
操作 for i in range(len(students_info)):
students_info[i] 即可进行操作数据
for stu in students_info:
print(stu) 输出的为单个字典元素
类 扩展
关于类和对象的理解:
类 -> 设计图纸,设计应该具有哪些属性和行为
对象 -> 使用图纸制造出来的模型
类中定义普通方法,第一个参数为 self
self可以修改为别的,但最好还是不要改变,约定好的
self.属性 self.方法 调用 self 指向的对象的属性和行为
在类外可以为实例化对象直接创建属性,但是该属性只适用于该对象
不推荐使用,如果一定要使用,必须先创建属性,后使用方法
在 __init__(self,..) 初始化方法内,定义属性初始值有利于表达属性,定义方法
打印类的实例化对象时,实际调用的是 类中的 __str__方法
__str__必须返回字符串,可以自己定义
如果实例化对象 先使用 del 方法删除了,那么不会再执行类中的 __del__方法
保护私有公有对象,保护私有共有方法 在方法内都可以调用
先开发被使用的类,被包含操作的类
复习 装饰器
'''
装饰器的作用
引入日志
函数执行时间的统计
执行函数前预备处理
执行函数后清理功能
权限校验等场景
缓存
'''
# 定义一个函数,遵循闭包原则(函数作为参数)
def decorator(func):
'''定义一个装饰器函数'''
print("func 函数开始")
def wrapper():
# 创建装饰器内容
print("进行装饰")
func()
print("装饰完毕")
print("func 函数结束")
return wrapper
@decorator
# 加载 wrapper 函数,将 wrapper 函数传递给使用装饰器的函数
def house():
print("大房子")
house()
'''
运行结果:
func 函数开始
func 函数结束
进行装饰
大房子
装饰完毕
'''
re 正则表达式练习
字符串重复出现
'''
有一段英文文本,其中有单词连续重复了 2 次,编写程序检查重复的单词并只保留一个
例: This is a a desk.
输出 This is a desk.
'''
# 方法一
import re
x = 'This is a a desk.'
# 设置字符串
pattern = re.compile(r'\b(\w+)(\s+\1){1,}\b')
# \b 匹配单词和空格间的位置
# \w 匹配包括下划线的任何单词字符 [A-Za-z0-9_]
# \s 匹配任何空白字符
# {1,} 大于 1 个
matchResult = pattern.search(x)
# 查找这样的结果
x = pattern.sub(matchResult.group(1),x)
# sub 进行替换字符
# group(1) 为 a group(0) 为 a a
print(x)
# This is a desk.
# 方法二
import re
x = 'This is a a desk.'
# 设置字符串
pattern = re.compile(r'(?P<f>\b\w+\b)\s(?P=f)')
# # \b 匹配单词和空格间的位置
# \w 匹配包括下划线的任何单词字符 [A-Za-z0-9_]
matchResult = pattern.search(x)
# 匹配到 a a
x = x.replace(matchResult.group(0),matchResult.group(1))
# 字符串对象.replace(旧字符串,新字符串)
# print(matchResult.group(0))
# a a
# print(matchResult.group(1))
# a
print(x)
# This is a desk.
最基本的Tkinter界面操作
'''
1.创建应用程序主窗口对象
root = Tk()
2.在主窗口中,添加各种可视化组件
btn1 = Button(root)
btn1["text"] = "点我"
3.通过几何布局管理器,管理组件得大小和位置
btn1.pack()
4.事件处理
通过绑定事件处理程序,响应用户操作所触发的事件
def songhua(e):
messagebox.showinfo("Message","送你一朵玫瑰花")
print("送花花")
btn1.bind("<Button-1>",songhua)
5.Tk() 的对象.mainloop() 方法会一直进行事件循环,监听用户操作
6.Button() 组件的参数为 Tk() 对象
Button() 的实例化对象 ["text"] 内容为显示在按钮上的内容
7.from tkinter import messagebox 显示点击之后提示的窗口
messagebox.showinfo("Message","送你一朵玫瑰花")
第一个参数为 标题
第二个参数为 显示信息
8.btn1.bind("<Button-1>",songhua)
使用创建好的按钮对象绑定鼠标事件和对应需要运行的函数
9.root.mainloop() 事件循环,一直监听用户操作
程序:'''
from tkinter import *
from tkinter import messagebox
root = Tk()
# 创建一个窗口对象
btn1 = Button(root)
btn1["text"] = "Submit"
btn1.pack()
# 将组件对象合理的放在窗口中
def songhua(e):
# e 为事件 event
messagebox.showinfo("Message","送你一朵玫瑰花")
print("送花花")
btn1.bind("<Button-1>",songhua)
# <Button-1> 表示鼠标左键单击
root.mainloop()
# root.mainloop() 事件循环,一直监听用户操作
Tkinter经典写法
'''
1.继承 tkinter.Frame 类,实现类的基本写法
2.创建 主窗口 及 主窗口大小 位置 及 标题
3.将需要添加的组件放入到类中进行创建,
继承的 Frame 类需要使用 master 参数作为父类的初始化使用
4.初始化时,将属性和方法都进行初始化,此时可以将 GUI 程序所要实现的功能确定好
5.在类中定义事件发生时,需要实现的功能
6.self.btn1["command"] = self.kuaJiang
btn1["command"] 为事件发生时进行相应的函数
7.self.btnQuit = Button(self,text = "退出",command = root.destroy)
退出按钮的写法
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.btn1 = Button(self)
# self 为组件容器
self.btn1["text"] = "Hany love Python."
# 按钮的内容为 btn1["text"]定义的内容
self.btn1.pack()
# 最佳位置
self.btn1["command"] = self.kuaJiang
# 响应函数
self.btnQuit = Button(self,text = "退出",command = root.destroy)
# 设置退出操作
self.btnQuit.pack()
def kuaJiang(self):
messagebox.showinfo("人艰不拆","继续努力,你是最棒的!")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("200x200+200+300")
# 创建大小
root.title("GUI 经典写法")
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
Label 组件基本写法
'''
1.width,height 指定区域大小
文本 汉字 2 个字节
2.font 指定字体和字体大小
font(font_name,size)
3.image 显示在 Label 上的图像 支持 gif 格式
4.fg 前景色
5.bg 背景色
6.justify 针对多行文字的对齐
left center right
7.self.lab1 = Label(self,text = "Label实现",width = 10,height = 2,
bg = 'black',fg = 'white')
8. photo_gif = PhotoImage(file = "images/小熊.gif")
self.lab3 = Label(self,image = photo_gif)
将照片传递给 photo_gif 然后使用 Label 将图片变量作为参数进行传递
9.self.lab4 = Label(self,text = " Hany加油\n 人艰不拆!"
,borderwidth = 1,relief = "solid",justify = "right")
borderwidth 设置文本线的宽度 justify 表示左对齐 右对齐
'''
from tkinter import *
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.lab1 = Label(self,text = "Label实现",width = 10,height = 2,
bg = 'black',fg = 'white')
self.lab1.pack()
self.lab2 = Label(self,text = "Labe2实现",width = 10,height = 2,
bg = 'black',fg = 'white',font = ("宋体",14))
self.lab2.pack()
# 显示图像
global photo_gif
# 将 photo_gif 设置为全局变量,防止方法调用后销毁
photo_gif = PhotoImage(file = "路径/图片名.gif")
self.lab3 = Label(self,image = photo_gif)
self.lab3.pack()
# 显示多行文本
self.lab4 = Label(self,text = " Hany加油\n 人艰不拆!"
,borderwidth = 1,relief = "solid",justify = "right")
self.lab4.pack()
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x300+400+300")
# 创建大小
root.title("Label 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
注:图片路径和图片要修改为自己的
类实例化的对象调用的方法或属性来自于类的哪个方法中
__init__ 构造方法 对象创建 p = Person()
__del__ 析构方法 对象回收
__repr__ , __str__ 打印,转换 print(a)
__call__ 函数调用 a()
__getattr__ 点号运算 a.xxx
__setattr__ 属性赋值 a.xxx = value
__getitem__ 索引运算 a[key]
__setitem__ 索引赋值 a[key]=value
__len__ 长度 len(a)
每个运算符实际上都对应了相应的方法
运算符+ __add__ 加法
运算符- __sub__ 减法
<,<=,== __lt__,__le__,__eq__ 比较运算符
>,>=,!= __gt__,_ ge__,__ne__ 比较运算符
|,^,& __or__,__xor__,__and__ 或,异或,与
<<,>>__lshift__,__ rshift__ 左移,右移
*,/,%,// __mul__,__truediv__,__mod__,__floordiv__ 乘,浮点除,模运算(取余),整数除
** __pow__ 指数运算
tkinter Button基本用语
'''
1.self.btn2 = Button(root,image = photo,command = self.login)
使用 image 图片作为按钮,command 作为响应
2.self.btn2.config(state = "disabled")
对按钮进行禁用
3.Button 中 anchor 控制按钮上的图片位置
N NE E SE SW W NW CENTER
默认居中
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.btn1 = Button(root,text = '登录',command = self.login,
width = 5,height = 2,anchor = E)
# command 进行操作的函数
self.btn1.pack()
global photo
photo = PhotoImage(file = "图片路径/图片名.gif")
self.btn2 = Button(root,image = photo,command = self.login)
self.btn2.pack()
# self.btn2.config(state = "disabled")
# # 设置按钮为禁用按钮
def login(self):
messagebox.showinfo("博客园","欢迎使用~")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x300+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
tkinter Entry基本用法
'''
1.BooleanVar() 布尔类型
2.IntVar() 整数类型
3.DoubleVar() 浮点数类型
4.StringVar() 字符串类型
5.self.entry1 = Entry(self,textviable = v1)
textviable 实现双向关联
6.v1.set("admin")
# 设置单行文本的值
7.v1.get() self.entry1.get() 获取的是单行文本框中的值
8.self.entry_passwd = Entry(self,textvariable = v2,show = "*")
textvariable 进行绑定 v2
v2 = StringVar()
用户输入后,show 显示为 *
9.Button(self,text = "登录",command = self.login).pack()
登录操作
10.点击登陆后执行的函数可以与数据库进行交互,达到验证的目的
self.组件实例化对象.get() 获取值
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.lab1 = Label(self,text = "用户名")
self.lab1.pack()
# StringVar() 绑定到指定的组件,StringVar 和 v1 一起变化
v1 = StringVar()
self.entry_user = Entry(self,textvariable = v1)
self.entry_user.pack()
v1.set("admin")
# 设置单行文本的值
# v1.get() self.entry_user.get() 获取的是单行文本框中的值
# 创建密码框
self.lab2 = Label(self,text = "密码")
self.lab2.pack()
v2 = StringVar()
self.entry_passwd = Entry(self,textvariable = v2,show = "*")
self.entry_passwd.pack()
Button(self,text = "登录",command = self.login).pack()
def login(self):
username = self.entry_user.get()
passwd = self.entry_passwd.get()
# 数据库进行操作,查看是否存在该用户
print("用户名:" + username)
print("密码:" + passwd)
if username == "Hany" and passwd == "123456":
messagebox.showinfo("博客园","欢迎使用~")
else:
messagebox.showinfo("Error","请重新输入~")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x300+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
此处的用户名是 Hany , 密码是 123456
Text多行文本框基本用法
#coding=gbk
'''
1.Text(root,width,height,bg)
主窗口,宽度,高度,背景色
2.使用 .insert() 方法添加内容
Text 对象.insert(几行.几列,"内容")
w1.insert(2.3,"···")
END 为最后位置
self.w1.insert(END,'[end]')
3.Button(窗口对象,text = "内容",command = "self.函数名").pack([side = "left"])
Button(self,text = "返回文本",command = self.returnText).pack(side = "left")
text 显示的内容 command 运行的函数 pack 位置,使用 side 后,按钮按照 pack 来
4.在类中定义的属性,不会因为运行函数方法后,就销毁
self.photo 不用再使用 global 进行声明
5.使用 PhotoImage 将图片存起来后,将图片显示在多行文本 Text 中
self.photo = PhotoImage(file = '图片路径/图片名.gif')
self.photo = PhotoImage(file = 'images/logo.gif')
使用 .image_create(位置,image = self.photo) 进行添加
self.w1.image_create(END,image = self.photo)
6.添加按钮组件到文本中
btn1 = Button(文本内容,text = "内容")
7.self.w1.tag_config (内容,background 背景颜色,foreground 文字颜色)
8.self.w1.tag_add("内容",起始位置,终止位置)
tag_add 加入内容
9.self.w1.tag_bind("内容","事件",self.函数名)
self.w1.tag_bind("baidu","<Button-1>",self.webshow)
10.webbrowser.open("网址")
打开一个网址
'''
from tkinter import *
from tkinter import messagebox
# 显示消息
import webbrowser
# 导入 webbrowser 到时候点击字体跳转使用
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
# 创建文字 Text(root 主窗口对象,width 宽度,height 高度,bg 背景色)
# 只对于文本有效
self.w1 = Text(root,width = 100,height = 40,bg = "gray")
# 设置背景色 bg = "gray"
self.w1.pack()
self.w1.insert(1.0,"0123456789\nabcdefg")
# 1.0 在 第一行 第零列 插入数据
self.w1.insert(2.3,"活在当下\n结发为夫妻,恩爱两不疑\n言行在于美,不在于多")
# 2.3 在 第二行 第三列
Button(self,text = "重复插入文本",command = self.insertText).pack(side = "left")
# 水平排列 side = "left"
Button(self,text = "返回文本",command = self.returnText).pack(side = "left")
Button(self,text = "添加图片",command = self.addImage).pack(side = "left")
Button(self,text = "添加组件",command = self.addWidget).pack(side = "left")
Button(self,text = "通过 tag 控制文本",command = self.testTag).pack(side = "left")
def insertText(self):
'''INSERT 索引表示在光标处插入'''
self.w1.insert(INSERT,'Hany')
# END 索引号表示在最后插入
self.w1.insert(END,'[end]')
# 在文本区域最后
self.w1.insert(1.2,"(.-_-.)")
def returnText(self):
'''返回文本内容'''
# Indexes(索引) 是用来指向 Text 组件中文本的位置
# Text 的组件索引 也是对应实际字符之间的位置
# 核心:行号从 1 开始,列号从 0 开始
print(self.w1.get(1.2,1.6))
print("文本内容:\n" + self.w1.get(1.0,END))
def addImage(self):
'''增加图片'''
self.photo = PhotoImage(file = 'images/logo.gif')
self.w1.image_create(END,image = self.photo)
def addWidget(self):
'''添加组件'''
btn1 = Button(self.w1,text = "Submit")
self.w1.window_create(INSERT,window = btn1)
# 添加组件
def testTag(self):
'''将某一块作为特殊标记,并使用函数'''
self.w1.delete(1.0,END)
self.w1.insert(INSERT,"Come on, you're the best.\n博客园\nHany 加油!!!")
# self.w1.tag_add("good",1.0,1.9)
# 选中标记区域
# self.w1.tag_config("good",background = "yellow",foreground = "red")
# 单独标记某一句,背景色 字体色
self.w1.tag_add("baidu",3.0,3.4)
#
self.w1.tag_config("baidu",underline = True,background = "yellow",foreground = "red")
self.w1.tag_bind("baidu","<Button-1>",self.webshow)
def webshow(self,event):
webbrowser.open("http://www.baidu.com")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("500x300+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
Radiobutton基础语法
'''
1.Radiobutton(root 主窗口,text 文本内容,value 值(可以通过set 和 get 获取到的值),variable 变量修改原来的StringVar)
self.radio_man = Radiobutton(root,text = "男性",value = "man",variable = self.v)
2.Button(root,text = "提交",command = self.confirm).pack(side = "left")
设置按钮进行提交,然后响应的函数
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.v = StringVar()
#String类型
self.v.set("man")
# 默认为 man 选中
self.radio_man = Radiobutton(self,text = "男性",value = "man",variable = self.v)
# Radiobutton(root/self 主窗口,text 文本内容,value 值(可以通过set 和 get 获取到的值),variable 变量修改原来的StringVar()变量也修改)
self.radio_woman = Radiobutton(self,text = "女性",value = "woman",variable = self.v)
self.radio_man.pack(side = "left")
self.radio_woman.pack(side = "left")
# 放到最佳位置
Button(self,text = "提交",command = self.confirm).pack(side = "left")
# 设置按钮进行提交,然后响应的函数
def confirm(self):
messagebox.showinfo("选择结果","选择的性别是 : "+self.v.get())
# 两个参数,一个是标题另一个是内容
# 显示内容
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x100+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
Checkbutton基本写法
'''
1.Checkbutton(self 窗口对象,text 按钮显示内容,variable 绑定变量->一起变化,
onvalue 用户点击时得到的值,offvalue 没有点击得到的值)
self.choose1 = Checkbutton(self,text = "玩游戏",variable = self.playHobby,
onvalue = 1,offvalue = 0)
2.self.playHobby.get() == 1 :
.get() 获取到值 判断是否时 onvalue 的值
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.playHobby = IntVar()
# 默认为 0
# .get() 获取值 .set() 设置值
self.travelHobby = IntVar()
self.watchTvHobby = IntVar()
# print(self.playHobby.get()) 0
self.choose1 = Checkbutton(self,text = "玩游戏",variable = self.playHobby,
onvalue = 1,offvalue = 0)
# Checkbutton(self 窗口对象,text 按钮显示内容,variable 绑定变量->一起变化,
# onvalue 用户点击时得到的值,offvalue 没有点击得到的值)
self.choose2 = Checkbutton(self,text = "去旅游",variable = self.travelHobby,
onvalue = 1,offvalue = 0)
self.choose3 = Checkbutton(self,text = "看电影",variable = self.watchTvHobby,
onvalue = 1,offvalue = 0)
self.choose1.pack(side = "left")
self.choose2.pack(side = "left")
self.choose3.pack(side = "left")
Button(self,text = "确定",command = self.confirm).pack(side = "left")
def confirm(self):
if self.playHobby.get() == 1 :
# 获取到的数据是 1 的话,进行接下来的操作
messagebox.showinfo("假期项目","玩游戏----")
if self.travelHobby.get() == 1 :
messagebox.showinfo("假期项目","去旅游----")
if self.watchTvHobby.get() == 1 :
messagebox.showinfo("假期项目","看电影----")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x200+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
# 一行代码合并字典
# {**{'键':'值','键':'值'},**{'键','值'}}
dic = {**{'a':1,'b':2},**{'c':3},**{'d':4}}
print(dic)
# {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 一行代码查看多个列表最大值
print(max([[1,2,3],[4,5,7,8],[6]],key = lambda v:max(v)))
# [4, 5, 7, 8]
print(max(max([[1,2,3],[4,5,7,8],[6]],key = lambda v:max(v))))
# 8
整理上课内容
加载数据集
sklearn.datasets 集成了部分数据分析的经典数据集·
load_boston 回归
load_breast_cancer 分类 聚类
fetch_california_housing 回归
load_iris 分类 聚类
load_digits 分类
load_wine 分类
from sklearn.datasets import load_breast_cancer
cancer=load_ breast_cancer()
print('breast_cancer数据集的长度为:',len(cancer))
print('breast_cancer数据集的类型为:',type(cancer))
数据集可以看作字典
可以使用 data target feature_names DESCR
分别获取数据集的数据 标签 特征名称 描述信息
cancer['data'] cancer['target']
cancer['feature_names'] cancer['DESCR']
将样本分为三部分
训练集(train set)用于估计模型
验证集(validation set) 用于确定 网络结构 或 控制模型复杂程度 的参数
测试集(test set) 检验最优的模型的性能
占比
50% 25% %25
通过一些数据建立一些模型 通过模型可以将新数据分组
K折交叉验证法
常用的方法是留少部分做测试集
对其余 N 个样本采用 K 折交叉验证法
将样本打乱 均匀分成K份。
轮流选择其中 K-1 份做训练 剩余的一份做验证。
计算预测误差平方和 把K次的预测误差平方和的均值作为选择最优模型结构的依据
对数据集进行拆分
sklearn.model_selection 的 train_test_split 函数
参数
*arrays 接收一个或多个需要划分的数据集
分类->数据和标签
聚类->数据
test_size 接收 float int None 数据
表示测试集的大小
float 类型 0-1 之间 表示测试集在总数中的占比
int 类型 表示测试集的绝对数目
test_size 默认为 25%
train_size 接收 float int None 类型的数据
表示训练集的大小 和 test_size 只能有一个
random_state 接收 int 类型 表示随机种子的编号
相同随机种子编号产生相同的随机结果
不同的随机种子编号产生不同的随机结果
shuffle 接收布尔类型 代表是否进行有放回抽样’
stratify 接收 array标签 或者 None
使用标签进行分层抽样
train_test_split 函数根据传入的数据
分别将传入的数据划分为训练集和测试集
如果传入的是1组数据,那么生成的就是这一组数据随机划分后训练集和测试集
如果传入的是2组数据,则生成的训练集和测试集分别2组
将breast_cancer数据划分为训练集和测试集
from sklearn.model_selection import train_test_split
cancer_data_train,cancer_data_test,cancer_target_train,cancer_target_test
= train_test_split(cancer_data,cancer_target,test_size=0.2,random_state=42)
.shape 查看形状
numpy.max() 查看最大值
使用 sklearn 转换器
fit 分析特征和目标值,提取有价值的信息 如 统计量 或 权值系数等。
transform 对特征进行转换
无信息转换 指数和对数函数转换等
有信息转换
无监督转换
只利用特征的统计信息 如 标准化 和 PCA 降维
有监督转换
利用 特征信息 和 目标值信息 如通过模型->选择特征 LDA降维等
fit_tranform 先调用 fit 方法 然后调用 transform 方法
使用 sklearn 转换器 能够实现对传入的 Numpy数组
进行标准化处理、归一化处理、二值化处理、PCA降维等操作
注 各类特征处理相关的操作都要将 训练集和测试集 分开
将训练集的操作规则、权重系数等应用到测试集中
.shape 查看形状
sklearn 提供的方法
MinMaxScaler 对特征进行离差标准化
StandardScaler 对特征进行标准差标准化
Normalizer 对特征进行归一化
Binarizer 对定量特征进行二值化处理
OneHotEncoder 对定性特征进行独热编码处理
Function Transformer 对特征进行自定义函数变换
from sklearn.decomposition import PCA
PCA 降维算法常用参数及作用
n_components 接收 None int float string 参数
未指定时,代表所有特征都会保留下来
int -> 降低到 n 个维度
float 同时 svd_solver 为full
string 如 n_components='mle'
自动选取特征个数为 n 满足所要求的方差百分比 默认为 None
copy 接收 布尔类型数据
True 运行后 原始数据不会发生变化
False 运行 PCA 算法后,原始数据 会发生变化
默认为 True
whiten 接收 布尔类型数据
表示白化 对降维后的数据的每个特征进行归一化
默认为 False
svd_solver 接收 'auto' 'full' 'arpack' 'randomized'
默认为auto
auto 代表PCA类会自动在上述三种算法中去权衡 选择一个合适的SVD算法来降维
full 使用SciPy库实现的传统SVD算法
arpack 和randomized的适用场景类似
区别是 randomized 使用的是 sklearn 的SVD实现
而arpack直接使用了 SciPy 库的 sparse SVD实现
randomized 一般适用于数据量大 数据维度多 同时主成分数目比例又较低的PCA降维 使用一些加快SVD的随机算法
聚类分析 在没有给定 划分类别 的情况下,根据 数据相似度 进行样本分组的一种方法
聚类模型 可以将 无类标记的数据 聚集为多个簇 视为一类 是一种 非监督的学习算法
聚类的输入是 一组未被标记的样本
根据 自身的距离 或 相似度 将他们划分为若干组
原则 组内样本最小化 组间距离最大化
常用的聚类算法
划分方法
K-Means算法(K-平均)
K-MEDOIDS算法(K-中心点)
CLARANS算法(基于选择的算法)
层次分析方法
BIRCH算法(平衡送代规约和聚类)
CURE算法(代表点聚类)
CHAMELEON算法(动态模型)
基于密度的方法
DBSCAN算法(基于高密度连接区域)
DENCLUE算法(密度分布函数)
OPTICS算法(对象排序识别)
基于网格的方法
STING算法(统计信息网络)
CLIOUE算法(聚类高维空间)
WAVE-CLUSTER算法(小波变换)
sklearn.cluster 提供的聚类算法
函数名称 K-Means
参数 簇数
适用范围 样本数目很大 聚类数目中等
距离度量 点之间的距离
函数名称 Spectral clustering
参数 簇数
适用范围 样本数目中等 聚类数目较小
距离度量 图距离
函数名称 Ward hierarchical clustering
参数 簇数
适用范围 样本数目较大 聚类数目较大
距离度量 点之间的距离
函数名称 Agglomerative clustering
参数 簇数 链接类型 距离
适用范围 样本数目较大 聚类数目较大
距离度量 任意成对点线图间的距离
函数名称 DBSCAN
参数 半径大小 最低成员数目
适用范围 样本数目很大 聚类数目中等
距离度量 最近的点之间的距离
函数名称 Birch
参数 分支因子 阈值 可选全局集群
适用范围 样本数目很大 聚类数目较大
距离度量 点之间的欧式距离
聚类算法实现需要sklearn估计器 fit 和 predict
fit 训练算法 接收训练集和标签
可用于有监督和无监督学习
predict 预测有监督学习的测试集标签
可用于划分传入数据的类别
将规则通过 fit 训练好后 将规则进行 预测 predict
如果存在数据 还可以检验规则训练的好坏
引入离差标准化
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
from sklearn.cluster import K-Means
iris = load_iris()
数据集的特征
iris_data = iris['data']
数据集的标签
iris_target = iris['target']
数据集的特征名
iris_names = iris['feature_names']
训练规则
scale = MinMaxScaler().fit(iris_data)
应用规则
iris_dataScale = scale.transform(iris_data)
构建并训练模型
kmeans = KMeans(n_components = 3,random_state = 123).fit(iris_dataScale)
n_components = 3 分为三类
预测模型
result = kmeans.predict([[1.5,1.5,1.5,1.5]])
查看预测类别
result[0]
使用 sklearn.manifold 模块的 TSNE 函数
实现多维数据的可视化展现
原理 使用 TSNE 进行数据降维
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
使用 TSNE 进行数据降维 降为两维
tsne = TSNE(n_components = 2,init = 'random',random_state = 177).fit(iris_data)
n_components = 2 降为两维
将原始数据转换为 DataFrame 对象
df = pd.DataFrame(tsne.embedding_)
转换为二维表格式
将聚类结果存到 df 数据表中
df['labels'] = kmeans.labels_
提取不同标签的数据
df1 = df[df['labels'] == 0]
df2 = df[df['labels'] == 1]
df3 = df[df['labels'] == 2]
绘制图形
fig = plt.figure(figsize = (9,6))
使用不同的颜色表示不同的数据
plt.plot(df1[0],df1[1],'bo',df2[0],df2[1],'r*')
储存为 .png 图片
plt.savefig('../tmp/名称.png')
plt.show()
聚类模型评价指标
标准
组内的对象相互之间是相似的(相关的)
不同组中的对象是不同的(不相关的)
sklearn.metrics 提供评价指标
ARI评价法(兰德系数) adjusted _rand_score
AMI评价法(互信息) adjusted_mutual_info_score
V-measure评分 completeness_score
FMI评价法 fowlkes_mallows_score
轮廓系数评价法 silhouette _score
Calinski-Harabasz指数评价法 calinski_harabaz_score
前四种更有说服力 评分越高越好
聚类方法的评价可以等同于分类算法的评价
FMI评价法 fowlkes_mallows_score
from sklearn.metrics import fowlkes_mallows_score
for i in range(2,7):
kmeans =KMeans(n_clusters =i,random_state=123).fit(iris_data)
score = fowlkes_mallows_score(iris_target,kmeans.labels_)
print('iris数据聚 %d 类FMI评价分值为:%f'%(i,score))
轮廓系数评价法 silhouette_score
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore=[]
for i in range(2,15):
kmeans=KMeans(n_clusters =i,random state=123).fit(iris data)
score = silhouette_score(iris_data,kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouettteScore,linewidth=1.5,linestyle="-")
plt.show()
使用 Calinski-Harabasz 指数评价 K-Means 聚类模型
分值越高聚类效果越好
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
kmeans=KMeans(n_clusters =i,random_state=123).fit(iris_data)
进行评价
score=calinski_harabaz_score(iris_data,kmeans.labels_)
print('iris数据聚%d类calinski harabaz指数为:%f'%(i,score)
构建并评价分类模型(有监督学习)
输入样本的特征值 输出对应的类别
将每个样本映射到预先定义好的类别
分类模型建立在已有模型的数据集上
用于 图像检测 物品分类
分类算法
模块名 函数名称 算法名称
linear_model LogisticRegression 逻辑斯蒂回归
svm SVC 支持向量机
neighbors KNeighborsClassifier K最近邻分类
naive_bayes GaussianNB 高斯朴素贝叶斯
tree DecisionTreeClassifier 分类决策树
ensemble RandomForestClassifier 随机森林分类
ensemble GradientBoostingClassifier 梯度提升分类树
以 breast_cancer 数据为例 使用sklearn估计器构建支持向量机(SVM)模型
import numpy as np
from sklearn.datasets import load_breast.cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
cancer = load_breast_cancer()
cancer_data = cancerf['data']
Cancer_target = cancert['target']
cancer_names = cancer['feature_names']
建立 SVM 模型
svm = SVC().fit(cancer_trainStd,cancer_target_train)
预测训练集结果
cancer_target_pred = svm.predict(cancer_testStd)
将预测结果和真实结果比对 求出预测对的结果和预测错的结果
true = np.sum(cancer_target_pred == cancer_target_test)
预测对的结果的数目
true
预测错的结果的数目
cancer_target_test.shape[0] - true
准确率
true/cancer_target_test.shape[0]
评价分类模型
分类模型对测试集进行预测得到的准确率并不能很好的反映模型的性能
结合真实值->计算准确率、召回率 F1 值和 Cohen's Kappa 系数等指标
方法名称 最佳值 sklearn 函数
Precision(精确率) 1.0 metrics.precision_score
Recall(召回率) 1.0 metrics.recall_score
F1值 1.0 metrics.f1_score
Cohen's Kappa 系数 1.0 metrics.cohen_kappa_score
ROC曲线 最靠近y轴 metrics.roc_curve
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
使用SVM预测breast_cancer数据的准确率为
accuracy_score(cancer_target_test,cancer_target_pred)
使用SVM预测breast_cancer数据的精确率为
precision_score(cancer_target_test,cancer_target_pred)
绘制ROC曲线
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
求出ROC曲线的x轴和y轴
fpr,tpr,thresholds = roc_curve(cancer_target_test,cancer_target_pred)
plIt.figure(figsize=(10,6))
plt.xlim(O,1)##设定x轴的范围
plt.ylim(0.0,1.1)##设定y轴的范围
plt.xlabel('False Postive Rate')
plt.ylabel('True Postive Rate')
plt.plot(fpr,tpr,linewidth=2,linestyle=*-".color='red")
plt.show()
ROC曲线 与 x 轴面积越大 模型性能越好
构建并评价回归模型
分类和回归的区别
分类算法的标签是离散的
回归算法的标签是连续的
作用 交通 物流 社交网络和金融领域等
回归模型
自变量已知
因变量未知 需要预测
回归算法实现步骤 分为 学习 和 预测 两个步骤
学习 通过训练样本数据来拟合回归方程
预测 利用学习过程中拟合出的回归方程 将测试数据放入方程中求出预测值
回归算法
模块名称 函数名称 算法名称
linear_model LinearRegression 线性回归
svm SVR 支持向量回归
neighbors KNeighborsRegressor 最近邻回归
tree DecisionTreeRegressor 回归决策树
ensemble RandomForestRegressor 随机森林回归
ensemble GradientBoostingRegressor 梯度提升回归树
以boston数据集为例 使用skllearn估计器构建线性回归模型
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
X = boston['data']
y = boston['target']
names = boston['feature_names']
划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,Y.test_size=0.2,random_state=125)
建立线性回归模型
clf = LinearRegression().fit(X_train.y_train)
预测训练集结果
y_pred = clf.predict(X_test)
前二十个结果
y_pred[:20]
使用不同的颜色表示不同的数据
plt.plot(range(y_test.shape[0]),y_test,color='blue',linewidth=1.5,linestyle='-')
评价回归模型
方法名称 最优值 sklearn函数
平均绝对误差 0.0 metrics.mean_absolute_error
均方误差 0.0 metrics.mean_squared_error
中值绝对误差 0.0 metrics.median_absolute_error
可解释方差值 1.0 metrics.explained_variance_score
R方值 1.0 metrics.r2_score
平均绝对误差 均方误差和中值绝对误差的值越靠近 0
模型性能越好
可解释方差值 和 R方值 则越靠近1 模型性能越好
from sklearn.metrics import explained_variance_score,mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
Boston数据线性回归模型的平均绝对误差为
mean_absolute_error(y_test,y_pred)
Boston数据线性回归模型的均方误差为
mean_squared_error(y_test,y _pred)
Boston数据线性回归模型的中值绝对误差为
median_absolute_error(y_test,y_pred)
Boston数据线性回归模型的可解释方差值为
explained_variance_score(y_test,y_pred)
Boston数据线性回归模型的R方值为
r2_score(y test,y_pred)
2020-07-25