TCP 客户端
"""
创建客户端
绑定服务器ip地址和端口号(端口号是整型)
与服务器建立连接
发送给服务器要发送的数据(转码)
接收服务器返回的数据
关闭客户端
"""
from socket import *
# 创建tcp socket
tcp_client_socket = socket(AF_INET,SOCK_STREAM)
# tcp 使用STREAM
# udp 使用DGRAM
# 连接的服务器及端口号
server_ip = input("请输入服务器ip地址:")
server_port = eval(input("请输入服务器端口号:"))
# 建立连接
tcp_client_socket.connect((server_ip,server_port))#联系ip地址和端口号
# print(type((server_ip,server_port)))元组类型
# 提示用户输入数据
send_data = input("请输入要发送的数据")
tcp_client_socket.send(send_data.encode('gbk'))#对发送的数据进行转码
# 接收对方发送来的数据
recv_data = tcp_client_socket.recv(1024)
print("接收到的数据是:%s"%(recv_data.decode('gbk')))
# 关闭套接字
tcp_client_socket.close()
"""
TCP使用AF_INET,SOCK_STREAM
TCP需要先建立连接,使用connect函数连接服务器端ip地址和端口号(绑定在元组中)
使用send发送转码后的数据,str->bytes 使用encode
接收数据recv (1024)函数 最大接收1024字节
关闭客服端close()
"""
TCP 服务器端
"""
建立tcp服务器
绑定本地服务器信息(ip地址,端口号)
进行监听
获取监听数据(监听到的客户端和地址)
使用监听到的客户端client_socket获取数据
输出获取到的数据
并返回给客户端一个数据
关闭服务器端
"""
from socket import *
# 创建tcp socket
tcp_server_socket = socket(AF_INET,SOCK_STREAM)
# 本地信息 ip地址+端口号
local_address = (('',7788))
# 绑定本地地址,主机号可以不写,固定端口号
tcp_server_socket.bind(local_address)#绑定ip地址和端口号
# 使用socket默认为发送,服务端主要接收数据
tcp_server_socket.listen(128)#对客户端进行监听
# 当接收到数据后,client_socket用来为客户端服务
client_socket,client_address = tcp_server_socket.accept()
# 接收对方发送的数据,客户端socket对象和客户端ip地址
recv_data = client_socket.recv(1024)#使用接收到的客户端对象接收数据
print("接收到的数据为:%s"%(recv_data.decode('gbk')))#对数据进行转码,并输出
# 发送数据到客户端
client_socket.send("Hany在tcp客户端发送数据".encode('gbk'))
# 关闭客户端,如果还有客户需要进行连接,等待下次
client_socket.close()##关闭服务器端
"""
服务端先要绑定信息,使用bind函数((ip地址(默认为''即可),端口号))
进行监听listen(128) 接收监听到的数据 accept() 客户服务对象,端口号
使用客户服务对象,接收数据recv(1024) 输出接收到的bytes->str decode转码 数据
使用gbk 是因为windows使用gbk编码
服务器端发送数据给刚刚监听过的客户端send函数,str->bytes类型
关闭服务器端
"""
UDP 绑定信息
"""
建立->绑定本地ip地址和端口号->接收数据->转码输出->关闭客户端
"""
from socket import *
udp_socket = socket(AF_INET,SOCK_DGRAM)
# 绑定本地的相关信息,如果网络程序不绑定,则系统会随机分配
# UDP使用SOCK_DGRAM
local_addr = ('',7788)#ip地址可以不写
udp_socket.bind(local_addr)#绑定本地ip地址
# 接收对方发送的数据
recv_data = udp_socket.recvfrom(1024)#UDP使用recvfrom方法进行接收
# 输出接收内容
print(recv_data[0].decode('gbk'))
print(recv_data[1])#ip地址+端口号
udp_socket.close()
"""
UDP使用AF_INET,SOCK_DGRAM
绑定ip地址和端口号(固定端口号)
接收recvfrom(1024)传来的元组 (数据,端口号)
数据是以bytes类型传过来的,需要转码decode('gbk')
"""
UDP 网络程序-发送_接收数据
"""
创建udp连接
发送数据给
"""
from socket import *
# 创建udp套接字,使用SOCK_DGRAM
udp_socket = socket(AF_INET,SOCK_DGRAM)
# 准备接收方的地址
dest_addr = ('',8080)#主机号,固定端口号
# 从键盘获取数据
send_data = input("请输入要发送的数据")
# 发送数据到指定的电脑上
udp_socket.sendto(send_data.encode('UTF-8'),dest_addr)#使用sendto方法进行发送,发送的数据,ip地址和端口号
# 等待接收双方发送的数据
recv_data = udp_socket.recvfrom(1024)# 1024表示本次接收的最大字节数
# 显示对方发送的数据,recv_data是一个元组,第一个为对方发送的数据,第二个是ip和端口
print(recv_data[0].decode('gbk'))
# 发送的消息
print(recv_data[1])
# ip地址
# 关闭套接字
udp_socket.close()
WSGI应用程序示例
import time
# WSGI允许开发者自由搭配web框架和web服务器
def app(environ,start_response):
status = '200 OK'
response_headers = [('Content-Type','text/html')]
start_response(status,response_headers)
return str(environ)+" Hello WSGI ---%s----"%(time.ctime())
print(time.ctime()) #Tue Jan 14 21:55:35 2020
定义 WSGI 接口
# WSGI服务器调用
def application(environ,start_response):
start_response('200 OK',[('Content-Type','text/html')])
return 'Hello World'
'''
environ: 包含HTTP请求信息的dict对象
start_response: 发送HTTP响应的函数
'''
encode 和 decode 的使用
txt = '我是字符串'
txt_encode = txt.encode()
print(txt)
# 我是字符串
print(txt_encode)
# b'\xe6\x88\x91\xe6\x98\xaf\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2'
print(type(txt))
# <class 'str'>
print(type(txt_encode))
# <class 'bytes'>
txt_copy = txt_encode.decode( )
print(txt_copy)
# 我是字符串
print(type(txt_copy))
# <class 'str'>
# str->bytes encode
# bytes->str decode
abs,all,any函数的使用
'''
abs函数:如果参数为实数,则返回绝对值
如果参数为复数,则返回复数的模
'''
a = 6
b = -6
c = 0
# print("a = {0} , b = {1} , c = {2}".format(abs(a),abs(b),abs(c)))
# a = 6 , b = 6 , c = 0
# 负数变为正数,正数不变,零不变
d = 3 + 4j
# print("d的模为 = {0}".format(abs(d)))
# d的模为 = 5.0
'''
总结:返回值是本身的数: 正数,0
返回值是相反数的数: 负数
返回值是模: 复数
'''
'''
all函数,接收一个迭代器,如果迭代器对象都为真,则返回True
有一个不为真,就返回False
'''
a = 6
b = -6
c = 0
d = 1
# print(all([a,b,c]))
# False
# 因为 c 为 0 ,有一个假,则为 False
# print(all([a,b,d]))
# True
# 都为真,实数不为 0 则为真
s = ''
# print(all(s))
# True 字符串为空,返回值为True
e = [0+0j] #all只接收可迭代对象,复数和实数都要使用列表
# print(all(e))
# False
a = ['']
# print(all(a))
# False
# #''空字符串被列表化之后,结果为False
b = []
# print(all(b))
# True 空列表返回为 True
c = [0]
# print(all(c))
# False 列表中存在 0,返回False
d = {}
# print(all(d))
# True 空字典返回值为True
e = set()
# print(all(e))
# True 空集合返回值为True
f = [set()]
# print(all(f))
# False 列表中为空集合元素时,返回False
g = [{}]
# print(all(g))
# False 列表中为空字典时,返回False
'''
总结: True: '' , [] , 除了 0 的实数, {} , set()
False: [''] , [0+0j] , [0] ,[set()] ,[{}]
'''
'''
any函数:接收一个迭代器,如果迭代器中只要有一个元素为真,就返回True
如果迭代器中元素全为假,则返回False
'''
lst = [0,0,1]
# print(any(lst))
# True 因为 1 为真,当存在一个元素为真时,返回True
'''
总结:只要有一个元素为真,则返回True
'''
# 文件的某些操作(以前发过类似的)
#
# 文件写操作
'''
w 写入操作 如果文件存在,则清空内容后进行写入,不存在则创建
a 写入操作 如果文件存在,则在文件内容后追加写入,不存在则创建
with 使用 with 语句后,系统会自动关闭文件并处理异常
'''
import os
print(os.path)
from time import ctime
# 使用 w 方式写入文件
f = open(r"test.txt","w",encoding = "utf-8")
print(f.write("该用户于 {0} 时刻,进行了文件写入".format(ctime())))
f.close()
# 使用 a 方式写入文件
f = open(r"text.txt","a",encoding = 'utf-8')
print(f.write('使用 a 方式进行写入 {0} '.format(ctime())))
f.close()
# 使用 with 方式,系统自动关闭文件并处理异常情况
with open(r"text.txt","w") as f :
'''with方法,对文件进行关闭并处理异常结果'''
f.write('{0}'.format(ctime()))
# 文件读操作
import os
def mkdir(path):
'''创建文件夹,先看是否存在该文件,然后再创建'''
# 如果存在,则不进行创建
is_exist = os.path.exists(path)
if not is_exist:
# 如果不存在该路径
os.mkdir(path)
def open_file(file_name):
'''打开文件,并返回读取到的内容'''
f = open(file_name) #使用 f 接收文件对象
f_lst = f.read( ) #进行读取文件
f.close() #使用完文件后,关闭
return f_lst #返回读取到的内容
# 获取后缀名
import os
'''os.path.splitext('文件路径'),获取后缀名'''
# 将文件路径后缀名和前面进行分割,返回类型为元组类型
file_text = os.path.splitext('./data/py/test.py')
# print(type(file_ext)) #<class 'tuple'>元组类型
front,text = file_text
# front 为元组的第一个元素
# ext 为元组的第二个元素
print(front,file_text[0])
# ./data/py/test ./data/py/test
print(text,file_text[1])
# .py .py
''' os.path.splitext('文件路径')'''
# 路径中的后缀名
import os
'''使用os.path.split('文件路径') 获取文件名'''
file_text = os.path.split('./data/py/test.py')
# print(type(file_text))
# <class 'tuple'> 元组类型
'''第一个元素为文件路径,第二个参数为文件名'''
path,file_name = file_text
print(path)
# ./data/py
print(file_name)
# test.py
'''splitext获取文件后缀名'''
pymysql 数据库基础应用
'''
开始
创建 connection
获取cursor
执行查询,获取数据,处理数据
关闭cursor
关闭connection
结束
'''
from pymysql import *
conn = connect(host='localhost',port=3306,database=hany_vacation,user='root',password='root',charset='utf8')
# conn = connect(host连接的mysql主机,port连接的mysql的主机,
# database数据库名称,user连接的用户名,password连接的密码,charset采用的编码方式)
# 方法:commit()提交,close()关闭连接,cursor()返回Cursor对象,执行sql语句并获得结果
# 主要执行的sql语句:select , insert , update , delete
cs1 = conn.cursor()
# 对象拥有的方法:
'''
close()关闭
execute(operation[,parameters])执行语句,返回受影响的行数,主要执行insert,update,delete,create,alter,drop语句
fetchone()执行查询语句,获取查询结果集的第一个行数据,返回一个元组
fetchall()执行查询语句,获取结果集的所有行,一行构成一个元组,再将这些元组装入一个元组返回
'''
# 对象的属性
'''
rowcount 只读属性,表示最近一次execute()执行后受影响的行数
connection 获取当前连接的对象
'''
数据库进行参数化,查询一行或多行语句
参数化
from pymysql import *
def main():
find_name = input("请输入物品名称")
conn = connect(host='localhost',port=3306,user='root',password='root',database='jing_dong',charset='utf8')
# 主机名、端口号、用户名、密码、数据库名、字符格式
cs1 = conn.cursor()#获取游标
# 构成参数列表
params = [find_name]
# 对查询的数据,使用变量进行赋值
count = cs1.execute('select * from goods where name=%s'%(params))
print(count)
result = cs1.fetchall()
# 输出所有数据
print(result)
# 先关闭游标、后关闭连接
cs1.close()
conn.close()
if __name__ == '__main__':
main()
查询一行语句
from pymysql import *
import time
def main():
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='root',database='jing_dong',charset='utf8')
# 获得Cursor对象
cs1 = conn.cursor()
# 执行select语句,并返回受影响的行数:查询一条数据
count = cs1.execute('select id,name from goods where id>=4')
# count = cs1.execute('select id,name from goods where id between 4 and 15')
# 打印受影响的行数
print("查询到%d条数据:" % count)
for i in range(count):
# 获取查询的结果
result = cs1.fetchone() #每次只输出一条数据 fetchall全部输出
# 打印查询的结果
time.sleep(0.5)
print(result)
# 获取查询的结果
# 关闭Cursor对象
cs1.close()
conn.close()
if __name__ == '__main__':
main()
from pymysql import *
def main():
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='root',database='jing_dong',charset='utf8')
# 获得Cursor对象
cs1 = conn.cursor()
# 执行select语句,并返回受影响的行数:查询一条数据
count = cs1.execute('select id,name from goods where id>=4')
# 打印受影响的行数
print("查询到%d条数据:" % count)
# for i in range(count):
# # 获取查询的结果
# result = cs1.fetchone()
# # 打印查询的结果
# print(result)
# # 获取查询的结果
result = cs1.fetchall()#直接一行输出
print(result)
# 关闭Cursor对象
cs1.close()
conn.close()
if __name__ == '__main__':
main()
二分法查找
def binary_search(alist, item):
first = 0
last = len(alist) - 1
while first <= last:
midpoint = (first + last) // 2
if alist[midpoint] == item:
return True
elif item < alist[midpoint]:
last = midpoint - 1
else:
first = midpoint + 1
return False
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42, ]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
# 递归使用二分法查找数据
def binary_search(alist, item):
if len(alist) == 0:
return False
else:
midpoint = len(alist)//2
if alist[midpoint]==item:
return True
else:
if item < alist[midpoint]:
return binary_search(alist[:midpoint],item)
#从开始到中间
else:#item元素大于alist[midpoint]
return binary_search(alist[midpoint+1:],item)
#从中间到最后
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
正则表达式_合集上
$通配符,匹配字符串结尾
import re
email_list = ["[email protected]", "[email protected]", "[email protected]"]
for email in email_list:
ret = re.match("[\w]{4,20}@163\.com$", email)
# \w 匹配字母或数字
# {4,20}匹配前一个字符4到20次
if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
elif ret == None :
print("%s 不符合要求" % email)
'''
[email protected] 是符合规定的邮件地址,匹配后的结果是:[email protected]
[email protected] 不符合要求
[email protected] 不符合要求
'''
re.match匹配
import re
# re.match匹配字符(仅匹配开头)
string = 'Hany'
# result = re.match(string,'123Hany hanyang')
result = re.match(string,'Hany hanyang')
# 使用group方法提取数据
if result:
print("匹配到的字符为:",result.group( ))
else:
print("没匹配到以%s开头的字符串"%(string))
'''匹配到的字符为: Hany'''
re中findall用法
import re
ret = re.findall(r"\d+","Hany.age = 22, python.version = 3.7.5")
# 输出全部找到的结果 \d + 一次或多次
print(ret)
# ['22', '3', '7', '5']
re中search用法
import re
ret = re.search(r"\d+",'阅读次数为:9999')
# 只要找到规则即可,从头到尾
print(ret.group())
'''9999'''
re中匹配 [ ] 中列举的字符
import re
# 匹配[]中列举的字符
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
print(ret.group())
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
print(ret.group())
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
print(ret.group())
ret = re.match("[hH]","Hello Python")
print(ret.group())
ret = re.match("[hH]ello Python","Hello Python")
print(ret.group())
# 匹配0到9第一种写法
ret = re.match("[0123456789]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到9第二种写法
ret = re.match("[0-9]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到3 5到9的数字
ret = re.match("[0-3,5-9]Hello Python","7Hello Python")
print(ret.group())
# 下面这个正则不能够匹配到数字4,因此ret为None
ret = re.match("[0-3,5-9]Hello Python","4Hello Python")
# print(ret.group())
'''
h
H
h
H
Hello Python
7Hello Python
7Hello Python
7Hello Python
'''
re中匹配不是以4,7结尾的手机号码
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
for tel in tels:
ret = re.match("1\d{9}[0-3,5-6,8-9]", tel)
if ret:
print("想要的手机号是:{}".format(ret.group()))
else:
print("%s 不是想要的手机号" % tel)
'''
13100001234 不是想要的手机号
想要的手机号是:18912344321
10086 不是想要的手机号
18800007777 不是想要的手机号
'''
re中匹配中奖号码
import re
# 匹配中奖号码
str2 = '17711602423'
pattern = re.compile('^(1[3578]\d)(\d{4})(\d{4})$')
print(pattern.sub(r'\1****\3',str2))
# r 字符串编码转化
'''177****2423'''
re中匹配中文字符
import re
pattern = re.compile('[\u4e00-\u9fa5]')
strs = '你好 Hello hany'
print(pattern.findall(strs))
pattern = re.compile('[\u4e00-\u9fa5]+')
print(pattern.findall(strs))
# ['你', '好']
# ['你好']
re中匹配任意字符
import re
# 匹配任意一个字符
ret = re.match(".","M")
# ret = re.match(".","M123") # M
# 匹配单个字符
print(ret.group())
ret = re.match("t.o","too")
print(ret.group())
ret = re.match("t.o","two")
print(ret.group())
'''
M
too
two
'''
re中匹配多个字符_加号
import re
#匹配前一个字符出现1次或无限次
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
'''
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求
'''
re中匹配多个字符_星号
import re
# 匹配前一个字符出现0次或无限次
# *号只针对前一个字符
ret = re.match("[A-Z][a-z]*","M")
# ret = re.match("[a-z]*","M") 没有结果
print(ret.group())
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
'''
M
Mnn
Aabcdef
'''
re中匹配多个字符_问号
import re
# 匹配前一个字符要么1次,要么0次
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?","7")
print(ret.group())
ret = re.match("[1-9]?\d","33")
print(ret.group())
ret = re.match("[1-9]?\d[1-9]","33")
print(ret.group())
ret = re.match("[1-9]?\d","09")
print(ret.group())
'''
7
7
33
33
0
'''
re中匹配左右任意一个表达式
import re
ret = re.match("[1-9]?\d","8")
# ? 匹配1次或0次
print(ret.group()) # 8
ret = re.match("[1-9]?\d","78")
print(ret.group()) # 78
# 不正确的情况
ret = re.match("[1-9]?\d","08")
print(ret.group()) # 0
# 修正之后的
ret = re.match("[1-9]?\d$","08")
if ret:
print(ret.group())
else:
print("不在0-100之间")
# 添加|
ret = re.match("[1-9]?\d$|100","8")
print(ret.group()) # 8
ret = re.match("[1-9]?\d$|100","78")
print(ret.group()) # 78
ret = re.match("[1-9]?\d$|100","08")
# print(ret.group()) # 不是0-100之间
ret = re.match("[1-9]?\d$|100","100")
print(ret.group()) # 100
re中匹配数字
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print(ret.group())
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥3号发射成功")
print(ret.group())
'''
嫦娥1号
嫦娥2号
嫦娥3号
嫦娥1号
嫦娥2号
嫦娥3号
'''
re中对分组起别名
#(?P<name>)
import re
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
print(ret.group())
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>")
# (?P=name2) ----- (?P<name2>\w*)
# ret.group()
'''
<html><h1>www.itcast.cn</h1></html>
'''
re中将括号中字符作为一个分组
#(ab)将ab作为一个分组
import re
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
if ret:
print(ret.group())
else:
print("不是163、126、qq邮箱") # 不是163、126、qq邮箱
'''
[email protected]
[email protected]
[email protected]
不是163、126、qq邮箱
'''
正则表达式_合集下
re中引用分组匹配字符串
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</html>")
print(ret.group())
# 如果遇到非正常的html格式字符串,匹配出错</htmlbalabala>会一起输出
ret = re.match("<[a-zA-Z]*>\w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
#
print(ret.group())
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
# </\1>匹配第一个规则
print(ret.group())
# 因为2对<>中的数据不一致,所以没有匹配出来
test_label = "<html>hh</htmlbalabala>"
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", test_label)
if ret:
print(ret.group())
else:
print("%s 这是一对不正确的标签" % test_label)
'''
<html>hh</html>
<html>hh</htmlbalabala>
<html>hh</html>
<html>hh</htmlbalabala> 这是一对不正确的标签
'''
re中引用分组匹配字符串_2
import re
labels = ["<html><h1>www.itcast.cn</h1></html>", "<html><h1>www.itcast.cn</h2></html>"]
for label in labels:
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", label)
# <\2>和第二个匹配一样的内容
if ret:
print("%s 是符合要求的标签" % ret.group())
else:
print("%s 不符合要求" % label)
'''
<html><h1>www.itcast.cn</h1></html> 是符合要求的标签
<html><h1>www.itcast.cn</h2></html> 不符合要求
'''
re中提取区号和电话号码
import re
ret = re.match("([^-]*)-(\d+)","010-1234-567")
# 除了 - 的所有字符
# 对最后一个-前面的所有字符进行分组,直到最后一个数字为止
print(ret.group( ))
print(ret.group(1))#返回-之前的数据,不一定是最后一个-之前
print(ret.group(2))
re中的贪婪
import re
s= "This is a number 234-235-22-423"
r=re.match(".+(\d+-\d+-\d+-\d+)",s)
# .+ 尽量多的匹配任意字符,匹配到-前一个数字之前
# . 匹配任意字符
print(type(r))
print(r.group())
print(r.group(0))
print(r.group(1))
r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
print(r.group())
print(r.group(1))#到数字停止贪婪
'''
<class 're.Match'>
This is a number 234-235-22-423
This is a number 234-235-22-423
4-235-22-423
This is a number 234-235-22-423
234-235-22-423
'''
import re
ret = re.match(r"aa(\d+)","aa2343ddd")
# 尽量多的匹配字符
print(ret.group())
# 使用? 将re贪婪转换为非贪婪
ret = re.match(r"aa(\d+?)","aa2343ddd")
# 只输出一个数字
print(ret.group())
'''
aa2343
aa2
'''
re使用split切割字符串
import re
ret = re.split(r":| ","info:XiaoLan 22 Hany.control")
# | 或 满足一个即可
print(ret)
str1 = 'one,two,three,four'
pattern = re.compile(',')
# 按照,将string分割后返回
print(pattern.split(str1))
# ['one', 'two', 'three', 'four']
str2 = 'one1two2three3four'
print(re.split('\d+',str2))
# ['one', 'two', 'three', 'four']
re匹配中subn,进行替换并返回替换次数
import re
pattern = re.compile('\d+')
strs = 'one1two2three3four'
print(pattern.subn('-',strs))
# ('one-two-three-four', 3) 3为替换的次数
re匹配中sub将匹配到的数据进行替换
# import re
# ret = re.sub(r"\d+", '替换的字符串998', "python = 997")
# # python = 替换的字符串998
# print(ret)
# # 将匹配到的数据替换掉,替换成想要替换的数据
# re.sub("规则","替换的字符串","想要替换的数据")
import re
def add(temp):
strNum = temp.group()
# 匹配到的数据.group()方式
print("原来匹配到的字符:",int(temp.group()))
num = int(strNum) + 5 #字符串强制转换
return str(num)
ret = re.sub(r"\d+", add, "python = 997")
# re.sub('正则规则','替换的字符串','字符串')
print(ret)
ret = re.sub(r"\d+", add, "python = 99")
print(ret)
pattern = re.compile('\d')
str1 = 'one1two2three3four'
print(pattern.sub('-',str1))
# one-two-three-four
print(re.sub('\d','-',str1))
# one-two-three-four
'''
原来匹配到的字符: 997
python = 1002
原来匹配到的字符: 99
python = 104
one-two-three-four
one-two-three-four
'''
re匹配的小例子
import re
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?\.jpg", src)
print(ret.group())
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.search(res,strs).group( ))
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# print(re.finditer(res,strs)) #返回迭代器对象
'''
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
a
['a', 'b', 'c']
'''
匹配前一个字符出现m次
import re
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?\.jpg", src)
print(ret.group())
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.search(res,strs).group( ))
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# print(re.finditer(res,strs)) #返回迭代器对象
'''
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
a
['a', 'b', 'c']
'''
引用分组
import re
strs = 'hello 123,world 456'
pattern = re.compile('(\w+) (\d+)')
# for i in pattern.finditer(strs):
# print(i.group(0))
# print(i.group(1))
# print(i.group(2))#当存在第二个分组时
'''hello 123
hello
123
world 456
world
456
'''
print(pattern.sub(r'\2 \1',strs))
# 先输出第二组,后输出第一组
print(pattern.sub(r'\1 \2',strs))
当findall遇到分组时,只匹配分组
import re
pattern = re.compile('([a-z])[a-z]([a-z])')
strs = '123abc456asd'
# print(re.findall(pattern,strs))
# [('a', 'c'), ('a', 'd')]返回分组匹配到的结果
result = re.finditer(pattern,strs)
for i in result:
print(i.group( )) #match对象使用group函数输出
print(i.group(0))#返回匹配到的所有结果
print(i.group(1))#返回第一个分组匹配的结果
print(i.group(2))#返回第二个分组匹配的结果
# <re.Match object; span=(3, 6), match='abc'>
# <re.Match object; span=(9, 12), match='asd'>
# 返回完整的匹配结果
'''
abc
abc
a
c
asd
asd
a
d
'''
线程_apply堵塞式
'''
创建三个进程,让三个进程分别执行功能,关闭进程
Pool 创建 ,apply执行 , close,join 关闭进程
'''
from multiprocessing import Pool
import os,time,random
def worker(msg):
# 创建一个函数,用来使进程进行执行
time_start = time.time()
print("%s 号进程开始执行,进程号为 %d"%(msg,os.getpid()))
# 使用os.getpid()获取子进程号
# os.getppid()返回父进程号
time.sleep(random.random()*2)
time_end = time.time()
print(msg,"号进程执行完毕,耗时%0.2f"%(time_end-time_start))
# 计算运行时间
if __name__ == '__main__':
po = Pool(3)#创建三个进程
print("进程开始")
for i in range(3):
# 使用for循环,运行刚刚创建的进程
po.apply(worker,(i,))#进程池调用方式apply堵塞式
# 第一个参数为函数名,第二个参数为元组类型的参数(函数运行会用到的形参)
#只有当进程执行完退出后,才会新创建子进程来调用请求
po.close()# 关闭进程池,关闭后po不再接收新的请求
# 先使用进程的close函数关闭,后使用join函数进行等待
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("进程结束")
'''创建->apply应用->close关闭->join等待结束'''
线程_FIFO队列实现生产者消费者
import threading # 导入线程库
import time
from queue import Queue # 队列
class Producer(threading.Thread):
# 线程的继承类,修改 run 方法
def run(self):
global queue
count = 0
while True:
if queue.qsize() <1000:
for i in range(100):
count = count + 1
msg = '生成产品'+str(count)
queue.put(msg)#向队列中添加元素
print(msg)
time.sleep(1)
class Consumer(threading.Thread):
# 线程的继承类,修改 run 方法
def run(self):
global queue
while True:
if queue.qsize() >100 :
for i in range(3):
msg = self.name + '消费了' + queue.get() #获取数据
# queue.get()获取到数据
print(msg)
time.sleep(1)
if __name__ == '__main__':
queue = Queue()
# 创建一个队列
for i in range(500):
queue.put('初始产品'+str(i))
# 在 queue 中放入元素 使用 put 函数
for i in range(2):
p = Producer()
p.start()
# 调用Producer类的run方法
for i in range(5):
c = Consumer()
c.start()
线程_GIL最简单的例子
#解决多进程死循环
import multiprocessing
def deadLoop():
while True:
print("Hello")
pass
if __name__ == '__main__':
# 子进程死循环
p1 = multiprocessing.Process(target=deadLoop)
p1.start()
# 主进程死循环
deadLoop()
线程_multiprocessing实现文件夹copy器
import multiprocessing
import os
import time
import random
def copy_file(queue,file_name,source_folder_name,dest_folder_name):
f_read = open(source_folder_name+"/"+file_name,"rb")
f_write = open(source_folder_name+"/"+file_name,"wb")
while True:
time.sleep(random.random())
content = f_read.read(1024)
if content:
f_write.write(content)
else:
break
f_read.close()
f_write.close()
# 发送已经拷贝完毕的文件名字
queue.put(file_name)
def main():
# 获取要复制的文件夹
source_folder_name = input("请输入要复制的文件夹名字:")
# 整理目标文件夹
dest_folder_name = source_folder_name + "副本"
# 创建目标文件夹
try:
os.mkdir(dest_folder_name)#创建文件夹
except:
pass
# 获取这个文件夹中所有的普通文件名
file_names = os.listdir(source_folder_name)
# 创建Queue
queue = multiprocessing.Manager().Queue()
# 创建线程池
pool = multiprocessing.Pool(3)
for file_name in file_names:
# 向线程池中添加任务
pool.apply_async(copy_file,args=(queue,file_name,source_folder_name,dest_folder_name))#不堵塞执行
# 主进程显示进度
pool.close()
all_file_num = len(file_names)
while True:
file_name = queue.get()
if file_name in file_names:
file_names.remove(file_name)
copy_rate = (all_file_num - len(file_names)) * 100 / all_file_num
print("\r%.2f...(%s)" % (copy_rate, file_name) + " " * 50, end="")
if copy_rate >= 100:
break
print()
if __name__ == "__main__":
main()
线程_multiprocessing异步
from multiprocessing import Pool
import time
import os
def test():
print("---进程池中的进程---pid=%d,ppid=%d--"%(os.getpid(),os.getppid()))
for i in range(3):
print("----%d---"%i)
time.sleep(1)
return "hahah"
def test2(args):
print("---callback func--pid=%d"%os.getpid())
print("---callback func--args=%s"%args)
if __name__ == '__main__':
pool = Pool(3)
pool.apply_async(func=test,callback=test2)
# 异步执行
time.sleep(5)
print("----主进程-pid=%d----"%os.getpid())
线程_Process实例
from multiprocessing import Process
import os
from time import sleep
def run_proc(name,age,**kwargs):
for i in range(10):
print("子进程运行中,名字为 = %s,年龄为 = %d,子进程 = %d..."%(name,age,os.getpid()))
print(kwargs)
sleep(0.5)
if __name__ == '__main__':
print("父进程: %d"%(os.getpid()))
pro = Process(target=run_proc,args=('test',18),kwargs={'kwargs':20})
print("子进程将要执行")
pro.start( )
sleep(1)
pro.terminate()#将进程进行终止
pro.join()
print("子进程已结束")
from multiprocessing import Process
import time
import os
#两个子进程将会调用的两个方法
def work_1(interval):
# intercal为挂起时间
print("work_1,父进程(%s),当前进程(%s)"%(os.getppid(),os.getpid()))
start_time = time.time()
time.sleep(interval)
end_time = time.time()
print("work_1,执行时间为%f"%(end_time-start_time))
def work_2(interval):
print("work_2,父进程(%s),当前进程(%s)"%(os.getppid(),os.getpid()))
start_time = time.time()
time.sleep(2)
end_time = time.time()
print("work_2执行时间为:%.2f"%(end_time-start_time))
if __name__ == '__main__':
print("进程Id:", os.getpid())
pro1 = Process(target=work_1, args=(2,))
pro2 = Process(target=work_2, name="pro2", args=(3,))
pro1.start()
pro2.start()
print("pro2.is_alive:%s" % (pro2.is_alive()))
print("pro1.name:", pro1.name)
print("pro1.pid=%s" % pro1.pid)
print("pro2.name=%s" % pro2.name)
print("pro2.pid=%s" % pro2.pid)
pro1.join()
print("pro1.is_alive:", pro1.is_alive())
线程_Process基础语法
"""
Process([group[,target[,name[,args[,kwargs]]]]])
group:大多数情况下用不到
target:表示这个进程实例所调用的对象 target=函数名
name:为当前进程实例的别名
args:表示调用对象的位置参数元组 args=(参数,)
kwargs:表示调用对象的关键字参数字典
"""
"""
常用方法:
is_alive( ):判断进程实例是否还在执行
join([timeout]):是否等待进程实例执行结束或等待多少秒
start():启动进程实例(创建子进程)
run():如果没有给定target函数,对这个对象调用start()方法时,
就将执行对象中的run()方法
terminate():不管任务是否完成,立即停止
"""
"""
常用属性:
name:当前进程实例的别名,默认为Process-N,N从1开始
pid:当前进程实例的PID值
"""
线程_ThreadLocal
import threading
# 创建ThreadLocal对象
house = threading.local()
def process_paper():
user = house.user
print("%s是房子的主人,in %s"%(user,threading.current_thread().name))
def process_thread(user):
house.user = user
process_paper()
t1 = threading.Thread(target=process_thread,args=('Xiaoming',),name='佳木斯')
t2 = threading.Thread(target=process_thread,args=('Hany',),name='哈尔滨')
t1.start()
t1.join()
t2.start()
t2.join()
线程_互斥锁_Lock及fork创建子进程
"""
创建锁 mutex = threading.Lock()
锁定 mutex.acquire([blocking])
当blocking为True时,当前线程会阻塞,直到获取到这个锁为止
默认为True
当blocking为False时,当前线程不会阻塞
释放 mutex.release()
"""
from threading import Thread,Lock
g_num = 0
def test1():
global g_num
for i in range(100000):
mutexFlag = mutex.acquire(True)#通过全局变量进行调用函数
# True会发生阻塞,直到结束得到锁为止
if mutexFlag:
g_num += 1
mutex.release()
print("test1--g_num = %d"%(g_num))
def test2():
global g_num
for i in range(100000):
mutexFlag = mutex.acquire(True)
if mutexFlag:
g_num += 1
mutex.release()
print("----test2---g_num = %d "%(g_num))
mutex = Lock()
p1 = Thread(target=test1,)
# 开始进程
p1.start()
p2 = Thread(target=test2,)
p2.start()
print("----g_num = %d---"%(g_num))
fork创建子进程
import os
# fork()在windows下不可用
pid = os.fork()#返回两个值
# 操作系统创建一个新的子进程,复制父进程的信息到子进程中
# 然后父进程和子进程都会得到一个返回值,子进程为0,父进程为子进程的id号
if pid == 0:
print("哈哈1")
else:
print("哈哈2")
线程_gevent实现多个视频下载及并发下载
from gevent import monkey
import gevent
import urllib.request
#有IO操作时,使用patch_all自动切换
monkey.patch_all()
def my_downLoad(file_name, url):
print('GET: %s' % url)
resp = urllib.request.urlopen(url)
# 使用库打开网页
data = resp.read()
with open(file_name, "wb") as f:
f.write(data)
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, "1.mp4", 'http://oo52bgdsl.bkt.clouddn.com/05day-08-%E3%80%90%E7%90%86%E8%A7%A3%E3%80%91%E5%87%BD%E6%95%B0%E4%BD%BF%E7%94%A8%E6%80%BB%E7%BB%93%EF%BC%88%E4%B8%80%EF%BC%89.mp4'),
gevent.spawn(my_downLoad, "2.mp4", 'http://oo52bgdsl.bkt.clouddn.com/05day-03-%E3%80%90%E6%8E%8C%E6%8F%A1%E3%80%91%E6%97%A0%E5%8F%82%E6%95%B0%E6%97%A0%E8%BF%94%E5%9B%9E%E5%80%BC%E5%87%BD%E6%95%B0%E7%9A%84%E5%AE%9A%E4%B9%89%E3%80%81%E8%B0%83%E7%94%A8%28%E4%B8%8B%29.mp4'),
])
from gevent import monkey
import gevent
import urllib.request
# 有耗时操作时需要
monkey.patch_all()
def my_downLoad(url):
print('GET: %s' % url)
resp = urllib.request.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, 'http://www.baidu.com/'),
gevent.spawn(my_downLoad, 'http://www.itcast.cn/'),
gevent.spawn(my_downLoad, 'http://www.itheima.com/'),
])
线程_gevent自动切换CPU协程
import gevent
def f(n):
for i in range(n):
print (gevent.getcurrent(), i)
# gevent.getcurrent() 获取当前进程
g1 = gevent.spawn(f, 3)#函数名,数目
g2 = gevent.spawn(f, 4)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
import gevent
def f(n):
for i in range(n):
print (gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(f, 2)
g2 = gevent.spawn(f, 3)
g3 = gevent.spawn(f, 4)
g1.join()
g2.join()
g3.join()
import gevent
import random
import time
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
# 添加可以切换的协程
gevent.spawn(coroutine_work, "work0"),
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
from gevent import monkey
import gevent
import random
import time
# 有耗时操作时需要
monkey.patch_all()#自动切换协程
# 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
gevent.spawn(coroutine_work, "work"),
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
线程_使用multiprocessing启动一个子进程及创建Process 的子类
from multiprocessing import Process
import os
# 子进程执行的函数
def run_proc(name):
print("子进程运行中,名称:%s,pid:%d..."%(name,os.getpid()))
if __name__ == "__main__":
print("父进程为:%d..."%(os.getpid()))
# os.getpid()获取到进程名
pro = Process(target=run_proc,args=('test',))
# target=函数名 args=(参数,)
print("子进程将要执行")
pro.start()#进程开始
pro.join()#添加进程
print("子进程执行结束...")
from multiprocessing import Process
import time
import os
# 继承Process类
class Process_Class(Process):
def __init__(self,interval):
Process.__init__(self)
self.interval = interval
# 重写Process类的run方法
def run(self):
print("我是类中的run方法")
print("子进程(%s),开始执行,父进程为(%s)"%(os.getpid(),os.getppid()))
start_time = time.time()
time.sleep(2)
end_time = time.time()
print("%s执行时间为:%.2f秒" % (os.getpid(),end_time-start_time))
if __name__ == '__main__':
start_time = time.time()
print("当前进程为:(%s)"%(os.getpid()))
pro1 = Process_Class(2)
# 对一个不包含target属性的Process类执行start()方法,
# 会运行这个类中的run()方法,所以这里会执行p1.run()
pro1.start()
pro1.join()
end_time = time.time()
print("(%s)执行结束,耗时%0.2f" %(os.getpid(),end_time - start_time))
线程_共享全局变量(全局变量在主线程和子线程中不同)
from threading import Thread
import time
g_num = 100
def work1():
global g_num
for i in range(3):
g_num += 1
print("----在work1函数中,g_num 是 %d "%(g_num))
def work2():
global g_num
print("在work2中,g_num为 %d "%(g_num))
if __name__ == '__main__':
print("---线程创建之前 g_num 是 %d"%(g_num))
t1 = Thread(target=work1)
t1.start()
t2 = Thread(target=work2)
t2.start()
线程_多线程_列表当做实参传递到线程中
from threading import Thread
def work1(nums):
nums.append('a')
print('---在work1中---',nums)
def work2(nums):
print("-----在work2中----,",nums)
if __name__ == '__main__':
g_nums = [1,2,3]
t1 = Thread(target=work1,args=(g_nums,))
# target函数,args参数
t1.start()
t2 = Thread(target=work2,args=(g_nums,))
t2.start()
线程_threading合集
# 主线程等待所有子线程结束才结束
import threading
from time import sleep,ctime
def sing():
for i in range(3):
print("正在唱歌---%d"%(i))
sleep(2)
def dance():
for i in range(3):
print("正在跳舞---%d" % (i))
sleep(2)
if __name__ == '__main__':
print("----开始----%s"%(ctime()))
t_sing = threading.Thread(target=sing)
t_dance = threading.Thread(target=dance)
t_sing.start()
t_dance.start()
print("----结束----%s"%(ctime()))
#查看线程数量
import threading
from time import sleep,ctime
def sing():
for i in range(3):
print("正在唱歌---%d"%i)
sleep(1)
def dance():
for i in range(3):
print("正在跳舞---%d"%i)
sleep(i)
if __name__ == '__main__':
t_sing = threading.Thread(target=sing)
t_dance = threading.Thread(target=dance)
t_sing.start()
t_dance.start()
while True:
length = len(threading.enumerate())
print("当前运行的线程数为:%d"%(length))
if length<= 1:
break
sleep(0.5)
import threading
import time
class MyThread(threading.Thread):
# 重写 构造方法
def __init__(self, num, sleepTime):
threading.Thread.__init__(self)
self.num = num
# 类实例不同,num值不同
self.sleepTime = sleepTime
def run(self):
self.num += 1
time.sleep(self.sleepTime)
print('线程(%s),num=%d' % (self.name, self.num))
if __name__ == '__main__':
mutex = threading.Lock()
t1 = MyThread(100, 3)
t1.start()
t2 = MyThread(200, 1)
t2.start()
import threading
from time import sleep
g_num = 1
def test(sleepTime):
num = 1 #num为局部变量
sleep(sleepTime)
num += 1
global g_num #g_num为全局变量
g_num += 1
print('---(%s)--num=%d --g_num=%d' % (threading.current_thread(), num,g_num))
t1 = threading.Thread(target=test, args=(3,))
t2 = threading.Thread(target=test, args=(1,))
t1.start()
t2.start()
import threading
import time
class MyThread1(threading.Thread):
def run(self):
if mutexA.acquire():
print("A上锁了")
mutexA.release()
time.sleep(2)
if mutexB.acquire():
print("B上锁了")
mutexB.release()
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
if mutexB.acquire():
print("B上锁了")
mutexB.release()
time.sleep(2)
if mutexA.acquire():
print("A上锁了")
mutexA.release()
mutexB.release()
# 先看B是否上锁,然后看A是否上锁
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == "__main__":
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
多线程threading的执行顺序(不确定)
# 只能保证都执行run函数,不能保证执行顺序和开始顺序
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i)
print(msg)
def test():
for i in range(5):
t = MyThread()
t.start()
if __name__ == '__main__':
test()
多线程threading的注意点
import threading
import time
class MyThread(threading.Thread):
# 重写threading.Thread类中的run方法
def run(self):
for i in range(3):#开始线程之后循环三次
time.sleep(1)
msg = "I'm "+self.name+'@'+str(i)
# name属性是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()#使用threading.Thread的继承类
t.start()#继承线程之后要开始运行 start方法
线程_进程间通信Queue合集
# Queue的工作原理
from multiprocessing import Queue
q = Queue(3)#初始化一个Queue对象,最多可接收3条put消息
q.put("Info1")
q.put("Info2")
print("q是否满了",q.full())#查看q是否满了
q.put("Info3")
print("q是否满了",q.full())
try:
q.put_nowait("info4")
except:
print("消息列队已经满了,现有消息数量为:%s"%(q.qsize()))
# 使用q.qsize()查看数量
# 先验证是否满了,再写入
if not q.full():
q.put_nowait("info4")
# 读取信息时,先判断消息列队是否为空,再读取
if not q.empty():
print("开始读取")
for i in range(q.qsize()):
print(q.get_nowait())
from multiprocessing import Queue
from multiprocessing import Process
import os,time,random
def write(q):
for value in ['a','b','c']:
print("Put %s to q ..."%(value))
q.put(value)
time.sleep(random.random())
def read(q):
while True:
if not q.empty():
value = q.get(True)
print("Get %s from Queue..."%(value))
time.sleep(random.random())
else:
break
if __name__ == '__main__':
#父进程创建Queue,传给各个子进程
q = Queue()
pw = Process(target=write,args=(q,))
pr = Process(target=read,args=(q,))
pw.start()
# 等待pw结束
pw.join()
pr.start()
pr.join()
print("数据写入读写完成")
from multiprocessing import Manager,Pool
import os,time,random
# 名称为reader 输出子进程和父进程 os 输出q的信息
def reader(q):
print("reader启动,子进程:%s,父进程:%s"%(os.getpid(),os.getppid()))
for i in range(q.qsize()):#在0 ~ qsize范围内
print("获取到queue的信息:%s"%(q.get(True)))
def writer(q):
print("writer启动,子进程:%s,父进程:%s"%(os.getpid(),os.getppid()))
for i in "HanYang":#需要写入到 q 的数据
q.put(i)
if __name__ == '__main__':
print("%s 开始 "%(os.getpid()))
q = Manager().Queue()#Queue使用multiprocessing.Manager()内部的
po = Pool()#创建一个线程池
po.apply(writer,(q,))#使用apply阻塞模式
po.apply(reader,(q,))
po.close()#关闭
po.join()#等待结束
print("(%s) 结束"%(os.getpid()))
线程_进程池
from multiprocessing import Pool
import os,time,random
def worker(msg):
start_time = time.time()
print("(%s)开始执行,进程号为(%s)"%(msg,os.getpid()))
time.sleep(random.random()*2)
end_time = time.time()
print(msg,"(%s)执行完毕,执行时间为:%.2f"%(os.getpid(),end_time-start_time))
if __name__ == '__main__':
po = Pool(3)#定义一个进程池,最大进程数为3
for i in range(0,6):
po.apply_async(worker,(i,))
# 参数:函数名,(传递给目标的参数元组)
# 每次循环使用空闲的子进程调用函数,满足每个时刻都有三个进程在执行
print("---开始---")
po.close()
po.join()
print("---结束---")
"""
multiprocessing.Pool的常用函数:
apply_async(func[,args[,kwds]]):
使用非阻塞方式调用func,并行执行
args为传递给func的参数列表
kwds为传递给func的关键字参数列表
apply(func[,args[,kwds]])
使用堵塞方式调用func
堵塞方式:必须等待上一个进程退出才能执行下一个进程
close()
关闭Pool,使其不接受新的任务
terminate()
无论任务是否完成,立即停止
join()
主进程堵塞,等待子进程的退出
注:必须在terminate,close函数之后使用
"""
线程_可能发生的问题
from threading import Thread
g_num = 0
def test1():
global g_num
for i in range(1000000):
g_num += 1
print("---test1---g_num=%d"%g_num)
def test2():
global g_num
for i in range(1000000):
g_num += 1
print("---test2---g_num=%d"%g_num)
p1 = Thread(target=test1)
p1.start()
# time.sleep(3)
p2 = Thread(target=test2)
p2.start()
print("---g_num=%d---"%g_num)
内存泄漏
import gc
class ClassA():
def __init__(self):
print('对象产生 id:%s'%str(hex(id(self))))
def f2():
while True:
c1 = ClassA()
c2 = ClassA()
c1.t = c2#引用计数变为2
c2.t = c1
del c1#引用计数变为1 0才进行回收
del c2
#把python的gc关闭
gc.disable()
f2()
== 和 is 的区别
import copy
a = ['a','b','c']
b = a #b和a引用自同一块地址空间
print("a==b :",a==b)
print("a is b :",a is b)
c = copy.deepcopy(a)# 对a进行深拷贝
print("a的id值为:",id(a))
print("b的id值为:",id(b))
print("c的id值为:",id(c))#深拷贝,不同地址
print("a==c :",a==c)
print("a is c :",a is c)
"""
is 是比较两个引用是否指向了同一个对象(引用比较)。
== 是比较两个对象是否相等。
"""
'''
a==b : True
a is b : True
a的id值为: 2242989720448
b的id值为: 2242989720448
c的id值为: 2242989720640
a==c : True
a is c : False
'''
以下为类的小例子
__getattribute__小例子
class student(object):
def __init__(self,name=None,age=None):
self.name = name
self.age = age
def __getattribute__(self, item):#getattribute方法修改类的属性
if item == 'name':#如果为name属性名
print("XiaoMing被我拦截住了")
return "XiaoQiang " #返回值修改了name属性
else:
return object.__getattribute__(self,item)
def show(self):
print("姓名是: %s" %(self.name))
stu_one = student("XiaoMing",22)
print("学生姓名为:",stu_one.name)
print("学生年龄为:",stu_one.age)
'''
XiaoMing被我拦截住了
学生姓名为: XiaoQiang
学生年龄为: 22
'''
__new__方法理解
class Foo(object):
def __init__(self, *args, **kwargs):
pass
def __new__(cls, *args, **kwargs):
return object.__new__(cls, *args, **kwargs)
# 以上return等同于
# return object.__new__(Foo, *args, **kwargs)
class Child(Foo):
def __new__(cls, *args, **kwargs):
return object.__new__(cls, *args, **kwargs)
class Round2Float(float):
def __new__(cls,num):
num = round(num,2)
obj = float.__new__(Round2Float,num)
return obj
f=Round2Float(4.324599)
print(f)
'''派生不可变类型'''
ctime使用及datetime简单使用
from time import ctime,sleep
def Clock(func):
def clock():
print("现在是:",ctime())
func()
sleep(3)
print("现在是:",ctime())
return clock
@Clock
def func():
print("函数计时")
func()
import datetime
now = datetime.datetime.now()#获取当前时间
str = "%s"%(now.strftime("%Y-%m-%d-%H-%M-%S"))
"""
Y 年 y
m 月
d 号
H 时
M 分
S 秒
"""
# 设置时间格式
print(str)
functools函数中的partial函数及wraps函数
'''
partial引用函数,并增加形参
'''
import functools
def show_arg(*args,**kwargs):
print("args",args)
print("kwargs",kwargs)
q = functools.partial(show_arg,1,2,3)#1,2,3为默认值
# functools.partial(函数,形式参数)
q()#相当于将show_arg改写一下,然后换一个名字
q(4,5,6)#没有键值对,kwargs为空
q(a='python',b='Hany')
# 增加默认参数
w = functools.partial(show_arg,a = 3,b = 'XiaoMing')#a = 3,b = 'XiaoMing'为默认值
w()#当没有值时,输出默认值
w(1,2)
w(a = 'python',b = 'Hany')
import functools
def note(func):
"note function"
@functools.wraps(func)
#使用wraps函数消除test函数使用@note装饰器产生的副作用 .__doc__名称 改变
def wrapper():
"wrapper function"
print('note something')
return func()
return wrapper
@note
def test():
"test function"
print('I am test')
test()
print(test.__doc__)
gc 模块常用函数
1、gc.set_debug(flags) 设置gc的debug日志,一般设置为gc.DEBUG_LEAK
2、gc.collect([generation]) 显式进行垃圾回收,可以输入参数,0代表只检查第一代的对象,
1代表检查一,二代的对象,2代表检查一,二,三代的对象,如果不传参数,
执行一个full collection,也就是等于传2。 返回不可达(unreachable objects)对象的数目
3、gc.get_threshold() 获取的gc模块中自动执行垃圾回收的频率。
4、gc.set_threshold(threshold0[, threshold1[, threshold2]) 设置自动执行垃圾回收的频率。
5、gc.get_count() 获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
hashlib加密算法
# import hashlib
# mima = hashlib.md5()#创建hash对象,md5是信息摘要算法,生成128位密文
# print(mima)
# # mima.update('参数')使用参数更新哈希对象
# print(mima.hexdigest())#返回16进制的数字字符串
import hashlib
import datetime
KEY_VALUE = 'XiaoLiu'
now = datetime.datetime.now()
m = hashlib.md5()
# 创建一个MD5密文
str = "%s%s%s"%(KEY_VALUE," ",now.strftime("%Y-%m-%d"))
# strftime日期格式
m.update(str.encode('UTF-8'))
value = m.hexdigest()
# 以十六进制进行输出
print(str,value)
__slots__属性
使用__slots__时,子类不受影响
class Person(object):
__slots__ = ("name","age")
def __str__(self):
return "姓名:%s,年龄:%d"%(self.name,self.age)
p = Person()
class man(Person):
pass
m = man()
m.score = 78
print(m.score)
使用__slots__限制类添加的属性
class Person(object):
__slots__ = ("name","age")
def __str__(self):
return "姓名:%s,年龄:%d"%(self.name,self.age)
p = Person()
p.name = "Xiaoming"
p.age = 15
print(p)
try:
p.score = 78
except AttributeError :
print(AttributeError)
isinstance方法判断可迭代和迭代器
from collections import Iterable
print(isinstance([],Iterable))
print(isinstance( {}, Iterable))
print(isinstance( (), Iterable))
print(isinstance( 'abc', Iterable))
print(isinstance( '100', Iterable))
print(isinstance((x for x in range(10) ), Iterable))
'''
True
D:/见解/Python/Python代码/vacation/python高级/使用isinstance判断是否可以迭代.py:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
True
from collections import Iterable
True
True
True
True
'''
from collections import Iterator
print(isinstance( [ ], Iterator))
print(isinstance( 'abc', Iterator))
print(isinstance(() , Iterator))
print(isinstance( {} , Iterator))
print(isinstance( 123, Iterator))
print(isinstance( 5+2j, Iterator))
print(isinstance( (x for x in range(10)) , Iterator))
# 生成器可以是迭代器
'''
False
D:/见解/Python/Python代码/vacation/python高级/使用isinstance判断是否是迭代器.py:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
False
from collections import Iterator
False
False
False
False
True
'''
metaclass 拦截类的创建,并返回
def upper_attr(future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():#遍历字典
if not name.startswith("__"):#如果不是以__开头
newAttr[name.upper()] = value
# 将future_class_attr字典中的键大写,然后赋值
return type(future_class_name, future_class_parents, newAttr)#第三个参数为新修改好的值(类名,父类,字典)
class Foo(object, metaclass=upper_attr):
# 使用upper_attr对类中值进行修改
bar = 'bip'#一开始创建Foo类时
print(hasattr(Foo, 'bar'))# hasattr查看Foo类中是否存在bar属性
print(hasattr(Foo, 'BAR'))
f = Foo()#实例化对象
print(f.BAR)#输出
timeit_list操作测试
'''
timeit库Timer函数
'''
from timeit import Timer
def test1():
l = list(range(1000))
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = []
for i in range(1000):
l = l + [i]
def test4():
l = [i for i in range(1000)]
if __name__ == '__main__':
# Timer函数,函数名,导入包
t1 = Timer("test1()","from __main__ import test1")
# timeit运行次数
print(t1.timeit(number = 1000))
t2 = Timer("test2()","from __main__ import test2")
print(t2.timeit(number =1000))
t3 = Timer("test3","from __main__ import test3")
print(t3.timeit(number=1000))
t4 = Timer("test4","from __main__ import test4")
print(t4.timeit(number=1000))
nonlocal 访问变量
def counter(start = 0):
def incr():
nonlocal start #分别保存每一个变量的临时值、类似yield
start += 1
return start
return incr
c1 = counter(5)
print(c1())
c2 = counter(50)
print(c2())
# c1 继续上次,输出接下来的值
print(c1())
print(c2())
pdb 进行调试
import pdb
a = 'aaa'
pdb.set_trace( )
b = 'bbb'
c = 'ccc'
final = a+b+c
print(final)
import pdb
a = 'aaa'
pdb.set_trace( )
b = 'bbb'
c = 'ccc'
pdb.set_trace()
final = a+b+c
print(final)
import pdb
def combine(s1,s2):
pdb.set_trace( )
s3 = s1 + s2
return s3
a = 'aaa'
pdb.set_trace( )
b = 'bbb'
c = 'ccc'
pdb.set_trace( )
final = combine(a,b)
print(final)
使用property取代getter和setter方法
class Days(object):
def __init__(self):
self.__days = 0
@property
def days(self):#获取函数,名字是days days 是get方法
return self.__days
@days.setter #get方法的set方法
def day(self,days):
self.__days = days
dd = Days()
print(dd.days)
dd.day = 15 #通过day函数设置__days的值
print(dd.days)
'''
0
15
'''
使用types库修改函数
import types
class ppp:
pass
p = ppp()#p为ppp类实例对象
def run(self):
print("run函数")
r = types.MethodType(run,p) #函数名,类实例对象
r()
'''
run函数
'''
type 创建类,赋予类\静态方法等
类方法
class ObjectCreator(object):
pass
@classmethod
def testClass(cls):
cls.temp = 666
print(cls.temp)
test = type("Test",(ObjectCreator,),{'testClass':testClass})
t = test()
t.testClass()#字典中的键
静态方法
class Test:
pass
@staticmethod
def TestStatic():
print("我是静态方法----------")
t = type('Test_two',(Test,),{"TestStatic":TestStatic})
print(type(t))
print(t.TestStatic)
print(t.TestStatic())
class Test:
pass
def Method():
return "定义了一个方法"
test2 = type("Test2",(Test,),{'Method':Method})
# 第一个参数为类名,第二个参数为父类(必须是元组类型),
# 第三个参数为类属性,不是实例属性
# print(type(test2))
# print(test2.Method())
print(hasattr(test2,'Method'))
# hasattr查看test2是否包含有Method方法
迭代器实现斐波那契数列
class FibIterator(object):
"""斐波那契数列迭代器"""
def __init__(self, n):
"""
:param n: int, 指明生成数列的前n个数
"""
self.n = n
# current用来保存当前生成到数列中的第几个数了
self.current = 0
# num1用来保存前前一个数,初始值为数列中的第一个数0
self.num1 = 0
# num2用来保存前一个数,初始值为数列中的第二个数1
self.num2 = 1
def __next__(self):
"""被next()函数调用来获取下一个数"""
if self.current < self.n:
num = self.num1
self.num1, self.num2 = self.num2, self.num1+self.num2
self.current += 1
return num
else:
raise StopIteration
def __iter__(self):
"""迭代器的__iter__返回自身即可"""
return self
if __name__ == '__main__':
fib = FibIterator(10)
for num in fib:
print(num, end=" ")
在( ) 中使用推导式 创建生成器
G = (x*2 for x in range(4))
print(G)
print(G.__next__())
print(next(G))#两种方法等价
# G每一次读取,指针都会下移
for x in G:
print(x,end = " ")
动态给类的实例对象 或 类 添加属性
class Person(object):
def __init__(self,name = None,age = None):
self.name = name
self.age = age
def __str__(self):
return "%s 的年龄为 %d 岁 %s性"%(self.name,self.age,self.sex)
pass
Xiaoming = Person('小明',20)
Xiaoming.sex = '男'#只有Xiaoming对象拥有sex属性
print(Xiaoming)
小明 的年龄为 20 岁 男性
class Person(object):
def __init__(self,name = None,age = None):
self.name = name
self.age = age
def __str__(self):
return "%s 的年龄为 %d 岁 %s性"%(self.name,self.age,self.sex)
Xiaoming = Person('小明',20)
Xiaolan = Person('小兰',19)
Person.sex = None #类创建sex默认属性为None
Xiaolan.sex = '女'
print(Xiaoming)
print(Xiaolan)
小明 的年龄为 20 岁 None性
小兰 的年龄为 19 岁 女性
线程_同步应用
'''
创建mutex = threading.Lock( )
锁定mutex.acquire([blocking])
释放mutex.release( )
创建->锁定->释放
'''
from threading import Thread,Lock
from time import sleep
class Task1(Thread):
def run(self):
while True:
if lock1.acquire():
#对lock1锁定
print("------Task 1 -----")
sleep(0.5)
lock2.release()
# 释放lock2锁的绑定
# 锁1上锁,锁2解锁
class Task2(Thread):
def run(self):
while True:
if lock2.acquire():
print("------Task 2 -----")
sleep(0.5)
lock3.release()
# 锁2上锁,锁3解锁
class Task3(Thread):
def run(self):
while True:
if lock3.acquire():
print("------Task 3 -----")
sleep(0.5)
lock1.release()
#使用Lock创建出的锁默认没有“锁上”
lock1 = Lock()
#创建另外的锁,并且上锁
lock2 = Lock()
lock2.acquire()
lock3 = Lock()
lock3.acquire()
t1 = Task1()
t2 = Task2()
t3 = Task3()
t1.start()
t2.start()
t3.start()
垃圾回收机制_合集
#大整数对象池
b = 1500
a = 1254
print(id(a))
print(id(b))
b = a
print(id(b))
a1 = "Hello 垃圾机制"
a2 = "Hello 垃圾机制"
print(id(a1),id(a2))
del a1
del a2
a3 = "Hello 垃圾机制"
print(id(a3))
s = "Hello"
print(id (s))
s = "World"
print(id (s))
s = 123
print(id (s))
s = 12
print(id (s))
lst1 = [1,2,3]
lst2 = [4,5,6]
lst1.append(lst2)
lst2.append(lst1)#循环进行引用
print(lst1)
print(lst2)
class Node(object):
def __init__(self,value):
self.value = value
print(Node(1))
"""
创建一个新对象,python向操作系统请求内存,
python实现了内存分配系统,
在操作系统之上提供了一个抽象层
"""
print(Node(2))#再次请求,分配内存
import gc
class ClassA():
def __init__(self):
print('object born,id:%s'%str(hex(id(self))))
def f3():
print("-----0------")
# print(gc.collect())
c1 = ClassA()
c2 = ClassA()
c1.t = c2
c2.t = c1
del c1
del c2
print("gc.garbage:",gc.garbage)
print("gc.collect",gc.collect()) #显式执行垃圾回收
print("gc.garbage:",gc.garbage)
if __name__ == '__main__':
gc.set_debug(gc.DEBUG_LEAK) #设置gc模块的日志
f3()
协程的简单实现
import time
# yield配合next使用
def work1():
while True:
print("----work1---")
yield
time.sleep(0.3)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.3)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
if __name__ == "__main__":
main( )
实现了__iter__和__next__的对象是迭代器
class MyList(object):
"""自定义的一个可迭代对象"""
def __init__(self):
self.items = []
def add(self, val):
self.items.append(val)
def __iter__(self):
myiterator = MyIterator(self)
return myiterator
class MyIterator(object):
"""自定义的供上面可迭代对象使用的一个迭代器"""
def __init__(self, mylist):
self.mylist = mylist
# current用来记录当前访问到的位置
self.current = 0
def __next__(self):
if self.current < len(self.mylist.items):
item = self.mylist.items[self.current]
self.current += 1
return item
else:
raise StopIteration
def __iter__(self):
return self
if __name__ == '__main__':
mylist = MyList()
mylist.add(1)
mylist.add(2)
mylist.add(3)
mylist.add(4)
mylist.add(5)
for num in mylist:
print(num)
对类中私有化的理解
class Person(object):
def __init__(self,name,age,taste):
self.name = name
self._age = age
self.__taste = taste
def showPerson(self):
print(self.name)
print(self._age)
print(self.__taste)
def do_work(self):
self._work()
self.__away()
def _work(self):
print("_work方法被调用")
def __away(self):
print("__away方法被调用")
class Student(Person):
def construction(self,name,age,taste):
self.name = name
self._age = age
self.__taste = taste
def showStudent(self):
print(self.name)
print(self._age)
print(self.__taste)
@staticmethod
def testbug():
_Bug.showbug()
class _Bug(Student):
@staticmethod
def showbug():
print("showbug函数开始运行")
s1 = Student('Xiaoming',22,'basketball')
s1.showPerson()
# s1.showStudent()
# s1.construction( )
s1.construction('rose',18,'football')
s1.showPerson()
s1.showStudent()
Student.testbug()
'''
Xiaoming
22
basketball
rose
18
basketball
rose
18
football
showbug函数开始运行
'''
拷贝的一些生成式
a = "abc"
b = a[:]
print(a,b)#值相同
print(id(a),id(b))#地址相同(字符串是不可变类型)
d = dict(name = "Xiaoming",age = 22)
d_copy = d.copy()
print( d ,id(d))
print(d_copy ,id(d_copy))#地址不同(字典是可变类型)
q = list(range(10))
q_copy = list(q)
print( q ,id(q))#值相同,地址不同 (<class 'range'>)为可变类型
print(q_copy,id(q_copy))
'''
abc abc
2233026983024 2233026983024
{'name': 'Xiaoming', 'age': 22} 2233146632896
{'name': 'Xiaoming', 'age': 22} 2233027001984
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 2233146658048
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 2233164085888
'''
查看 __class__属性
查看complex的__class__属性
a = 5+2j
print(a.__class__)
print(a.__class__.__class__)
'''
<class 'complex'>
<class 'type'>
'''
查看int的__class__属性
a = 123
print(a.__class__)
print(a.__class__.__class__)
'''
<class 'int'>
<class 'type'>
'''
查看str的__class__属性
a = 'str'
print(a.__class__)
print(a.__class__.__class__)
'''
<class 'str'>
<class 'type'>
'''
class ObjectCreator(object):
pass
print(type(ObjectCreator))#输出类的类型
print(type(ObjectCreator()))#<class '__main__.ObjectCreator'>
print(ObjectCreator.__class__)#输出类的类型
'''
<class 'type'>
<class '__main__.ObjectCreator'>
<class 'type'>
'''
运行过程中给类添加方法 types.MethodType
class Person(object):
def __init__(self,name = None,age = None):
self.name = name#类中拥有的属性
self.age = age
def eat (self):
print("%s在吃东西"%(self.name))
p = Person("XiaoLiu",22)
p.eat()#调用Person中的方法
def run(self,speed):#run方法为需要添加到Person类中的方法
# run方法 self 给类添加方法,使用self指向该类
print("%s在以%d米每秒的速度在跑步"%(self.name,speed))
run(p,2)#p为类对象
import types
p1= types.MethodType(run,p)#p1只是用来接收的对象,MethodType内参数为 函数+类实例对象 ,接收之后使用函数都是对类实例对象进行使用的
# 第二个参数不能够使用类名进行调用
p1(2) #p1(2)调用实际上时run(p,2)
'''
XiaoLiu在吃东西
XiaoLiu在以2米每秒的速度在跑步
XiaoLiu在以2米每秒的速度在跑步
'''
import types
class Person(object):
num = 0 #num是一个类属性
def __init__(self, name = None, age = None):
self.name = name
self.age = age
def eat(self):
print("eat food")
#定义一个类方法
@classmethod #函数具有cls属性
def testClass(cls):
cls.num = 100
# 类方法对类属性进行修改,使用cls进行修改
#定义一个静态方法
@staticmethod
def testStatic():
print("---static method----")
P = Person("老王", 24)
#调用在class中的构造方法
P.eat()
#给Person类绑定类方法
Person.testClass = testClass #使用函数名进行引用
#调用类方法
print(Person.num)
Person.testClass()#Person.testClass相当于testClass方法
print(Person.num)#验证添加的类方法是否执行成功,执行成功后num变为100,类方法中使用cls修改的值
#给Person类绑定静态方法
Person.testStatic = testStatic#使用函数名进行引用
#调用静态方法
Person.testStatic()
'''
eat food
0
100
---static method----
'''
查看一个对象的引用计数
a = "Hello World "
import sys
print("a的引用计数为:",sys.getrefcount(a))
'''a的引用计数为: 4'''
浅拷贝和深拷贝
a = [1,2,3,4]
print(id(a))
b = a
print(id(b))
# 地址相同
a.append('a')
print(a)
print(b)#b和a的值一致,a改变,b就跟着改变
'''
2342960103104
2342960103104
[1, 2, 3, 4, 'a']
[1, 2, 3, 4, 'a']
'''
浅拷贝对不可变类型和可变类型的copy不同
import copy
a = [1,2,3]
b = copy.copy(a)
a.append('a')
print(a," ",b)
print(id(a),id(b))
a = (1,2,3)
b = copy.copy(a)
print(id(a),id(b))
# 浅拷贝copy.copy()对于可变类型赋予的地址不同,对于不可变类型赋予相同地址
'''
[1, 2, 3, 'a'] [1, 2, 3]
2053176165376 2053176165568
2053175778688 2053175778688
'''
深拷贝
import copy
a = [1,2,3,4]
print(id(a))
b = copy.deepcopy(a)
print(id(b))#地址不同
a.append('a')
print(a," ",b)
# 深拷贝:不跟着拷贝的对象发生变化
'''
2944424869376
2944424869568
[1, 2, 3, 4, 'a'] [1, 2, 3, 4]
'''
.format方式输出星号字典的值是键
dic = {'a':123,'b':456}
print("{0}:{1}".format(*dic))
# a:b
类可以打印,赋值,作为实参和实例化
class ObjectCreator(object):
pass
print(ObjectCreator)
# 打印
ObjectCreator.name = 'XiaoLiu'
# 对ObjectCreator类增加属性,以后使用ObjectCreator类时,都具有name属性
g = lambda x:x
# 把函数赋值给对象g
g(ObjectCreator)
# 将ObjectCreator作为实参传递给刚刚赋值过的g函数
Obj = ObjectCreator()
# 赋值给变量
'''
<class '__main__.ObjectCreator'>
'''
类可以在函数中创建,作为返回值(返回类)
def func_class(string):
if string == 'class_one':
class class_one:
pass
return class_one
else:
class class_two:
pass
return class_two
MyClass = func_class('')
print("MyClass为 " , MyClass)
m = MyClass()
print("m为 ",m)
'''
MyClass为 <class '__main__.func_class.<locals>.class_two'>
m为 <__main__.func_class.<locals>.class_two object at 0x000002BC0491B190>
'''
查看某一个字符出现的次数
#方法一
import random
range_lst = [random.randint(0,100) for i in range(100)]
# 创建一个包含有 100 个数据的随机数
range_set = set(range_lst)
# 创建集合,不包含重复元素
for num in range_set:
# 对集合进行遍历,查找元素出现的次数
# list.count(元素) 查看元素在列表中出现的次数
print(num,":",range_lst.count(num))
# 方法二
import random
range_lst = [random.randint(0,5) for i in range(10)]
range_dict = dict()
for i in range_lst:
# 默认为 0 次,如果出现一次就 + 1
range_dict[i] = range_dict.get(i,0) +1
print(range_dict)
闭包函数
def test(number):
#在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包
def test_in(number_in):
print("in test_in 函数, number_in is %d"%number_in)
return number+number_in#使用到了外部的变量number
return test_in #将内部函数作为返回值
#给test函数赋值,这个20就是给参数number
ret = test(20)#ret接收返回值(内部函数test_in)
#注意这里的100其实给参数number_in
print(ret(100)) #100+20
print(ret(200)) #200+20
def test1():
print("----test1----")
test1()
ret = test1#使用对象引用函数,使用函数名进行传递
print(id(ret))
# 引用的对象地址和原函数一致
print(id(test1))
ret()
'''
----test1----
1511342483488
1511342483488
----test1----
'''
def line_conf(a,b):
def line(x):
return "%d * %d + %d"%(a,x,b)
# 内部函数一定要使用外部函数,才能称为闭包函数
return line
line_one = line_conf(1,1)
# 使用变量进行接收外部函数,然后使用变量进行调用闭包函数中的内部函数
line_two = line_conf(2,3)
print(line_one(7))
print(line_two(7))
'''
1 * 7 + 1
2 * 7 + 3
'''
自定义创建元类
#coding=utf-8
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# __new__能够控制对象的创建
# 这里,创建的对象是类,自定义这个类,我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 可改写__call__特殊方法
def __new__(cls, future_class_name, future_class_parents, future_class_attr):
# cls、类名、父类、需要修改的字典
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for key,value in future_class_attr.items():
if not key.startswith("__"):
newAttr[key.upper()] = value
#使字典的键值大写
# 方法1:通过'type'来做类对象的创建
# return type(future_class_name, future_class_parents, newAttr)
# type 类名、父类名、字典(刚刚进行修改的字典)
# 方法2:复用type.__new__方法
# 这就是基本的OOP编程,没什么魔法
# return type.__new__(cls, future_class_name, future_class_parents, newAttr)
# 类名、父类名、字典(刚刚进行修改的字典)
# 方法3:使用super方法
return super(UpperAttrMetaClass,cls).__new__(cls, future_class_name, future_class_parents, newAttr)
# python3的用法
class Foo(object, metaclass = UpperAttrMetaClass):
# metaclass运行类的时候,根据metaclass的属性。修改类中的属性
bar = 'bip'
# hasattr 查看类中是否具有该属性
print(hasattr(Foo, 'bar'))
# 输出: False
print(hasattr(Foo, 'BAR'))
# 输出:True
f = Foo()
# 进行构造,产生 f 对象
print(f.BAR)
# 输出:'bip',metaclass修改了Foo类
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# 你很少用到__new__,除非你希望能够控制对象的创建
# 这里,创建的对象是类,我们希望能够自定义它,所以我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 还有一些高级的用法会涉及到改写__call__特殊方法,但是我们这里不用
def __new__(cls, future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():
if not name.startswith("__"):
newAttr[name.upper()] = value
# 方法1:通过'type'来做类对象的创建
return type(future_class_name, future_class_parents, newAttr)
# 方法2:复用type.__new__方法
# return type.__new__(cls, future_class_name, future_class_parents, newAttr)
#return type.__new__(cls,future_class_name,future_class_parents,newAttr)
# 方法3:使用super方法
return super(UpperAttrMetaClass, cls).__new__(cls, future_class_name, future_class_parents, newAttr)
# python3的用法
class Foo(object, metaclass = UpperAttrMetaClass):
bar = 'bip'
print(hasattr(Foo, 'bar'))
print(hasattr(Foo, 'BAR'))
f = Foo()
print(f.BAR)
迪杰斯特拉算法(网上找的)
"""
输入
graph 输入的图
src 原点
返回
dis 记录源点到其他点的最短距离
path 路径
"""
import json
def dijkstra(graph, src):
if graph == None:
return None
# 定点集合
nodes = [i for i in range(len(graph))] # 获取顶点列表,用邻接矩阵存储图
# 顶点是否被访问
visited = []
visited.append(src)
# 初始化dis
dis = {src: 0} # 源点到自身的距离为0
for i in nodes:
dis[i] = graph[src][i]
path = {src: {src: []}} # 记录源节点到每个节点的路径
k = pre = src
while nodes:
temp_k = k
mid_distance = float('inf') # 设置中间距离无穷大
for v in visited:
for d in nodes:
if graph[src][v] != float('inf') and graph[v][d] != float('inf'): # 有边
new_distance = graph[src][v] + graph[v][d]
if new_distance <= mid_distance:
mid_distance = new_distance
graph[src][d] = new_distance # 进行距离更新
k = d
pre = v
if k != src and temp_k == k:
break
dis[k] = mid_distance # 最短路径
path[src][k] = [i for i in path[src][pre]]
path[src][k].append(k)
visited.append(k)
nodes.remove(k)
print(nodes)
return dis, path
if __name__ == '__main__':
# 输入的有向图,有边存储的就是边的权值,无边就是float('inf'),顶点到自身就是0
graph = [
[0, float('inf'), 10, float('inf'), 30, 100],
[float('inf'), 0, 5, float('inf'), float('inf'), float('inf')],
[float('inf'), float('inf'), 0, 50, float('inf'), float('inf')],
[float('inf'), float('inf'), float('inf'), 0, float('inf'), 10],
[float('inf'), float('inf'), float('inf'), 20, 0, 60],
[float('inf'), float('inf'), float('inf'), float('inf'), float('inf'), 0]]
dis, path = dijkstra(graph, 0) # 查找从源点0开始带其他节点的最短路径
print(dis)
print(json.dumps(path, indent=4))
装饰器_上
def foo():
print("foo")
print(foo)
# 输出foo的地址
foo()#对foo函数的调用
def foo():
print("foo2")
foo = lambda x : x+1
# 使用foo对象接收函数
print(foo(2))
def w(func):
def inner():
# 验证、使用内部函数的inner函数进行验证
print("对函数进行验证中~~~")
func()#内部函数使用了外部函数的func函数
return inner#闭包函数、返回内部函数名
@w #对w的装饰
def fun1():
print("fun1验证完毕,开始接下来的工作")
@w
def fun2():
print("fun2验证完毕,开始接下来的工作")
fun1()#运行、先运行装饰器,后运行函数
fun2()
def makeBold(fn):
# fn形参实际上是使用了makeBold装饰器的函数
def wrapped():
return "<b>"+fn()+"</b>"
return wrapped
def makeitalic(fn):
def wrapped():
return "<i>"+fn()+"</i>"
return wrapped
@makeBold
def test1():
return "hello world -1 "
@makeitalic
def test2():
return "hello world -2 "
@makeBold#后使用makeBold
@makeitalic#先使用装饰器makeitalic
def test3():
return "hello world -3 " #@makeitalic先执行然后是@makeBold 先执行最近的
print(test1())
print(test2())
print(test3())
装饰器_下
# 示例1
from time import ctime,sleep
#导包就不需要使用包名.函数了
def timefun(func):
def wrappedfunc():
print("%s called at %s"%(func.__name__,ctime()))
func()#内部函数需要使用外部函数的参数
return wrappedfunc#返回内部函数
@timefun #timefun是一个闭包函数
def foo():#将foo函数传递给timefun闭包函数
print("I'm foo ")
foo()
sleep(3)
foo()
'''
foo called at Fri May 8 01:00:18 2020
I'm foo
foo called at Fri May 8 01:00:21 2020
I'm foo
'''
# 示例2
from time import ctime,sleep
import functools
def timefun(func):
#functools.wraps(func)
def wrappedfunc(a,b):#使用了timefun函数的参数a,b
print("%s called at %s"%(func.__name__,ctime()))
print(a,b)
func(a,b)
return wrappedfunc
@timefun
def foo(a,b):
print(a+b)
foo(3,5)
sleep(2)
foo(2,4)
'''
foo called at Fri May 8 01:01:16 2020
3 5
8
foo called at Fri May 8 01:01:18 2020
2 4
6
'''
# 示例3
from time import ctime,sleep
def timefun(func):
def wrappedfunc(*args,**kwargs):
# *args主要是元组,列表,单个值的集合
# **kwargs 主要是键值对,字典
print("%s called at %s"%(func.__name__,ctime()))
func(*args,**kwargs)
return wrappedfunc
@timefun
def foo(a,b,c):
print(a+b+c)
foo(3,5,7)
sleep(2)
foo(2,4,9)
'''
foo called at Fri May 8 01:01:38 2020
15
foo called at Fri May 8 01:01:40 2020
15
'''
# 示例4
def timefun(func):
def wrappedfunc( ):
return func( )#闭包函数返回调用的函数(原函数有return)
return wrappedfunc
@timefun
def getInfo():
return '----haha----'
info = getInfo()#接收函数的返回值
print(info)#输出getInfo 如果闭包函数没有return 返回,则为None
'''
----haha----
'''
# 示例5
from time import ctime,sleep
def timefun_arg(pre = "Hello"):#使用了pre默认参数
def timefun(func):
def wrappedfunc():#闭包函数嵌套闭包函数
print("%s called at %s"%(func.__name__,ctime()))
print(pre)
# func.__name__函数名 ctime()时间
return func#返回使用了装饰器的函数
return wrappedfunc
return timefun
@timefun_arg("foo的pre")#对闭包函数中最外部函数进行形参传递pre
def foo( ):
print("I'm foo")
@timefun_arg("too的pre")
def too():
print("I'm too")
foo()
sleep(2)
foo()
too()
sleep(2)
too()
'''foo called at Fri May 8 01:02:34 2020
foo的pre
foo called at Fri May 8 01:02:36 2020
foo的pre
too called at Fri May 8 01:02:36 2020
too的pre
too called at Fri May 8 01:02:38 2020
too的pre
'''
设计模式_理解单例设计模式
设计模式分类:
结构型
行为型
创建型
单例模式属于创建型设计模式
单例模式主要使用在
日志记录 ->将多项服务的日志信息按照顺序保存到一个特定日志文件
数据库操作 -> 使用一个数据库对象进行操作,保证数据的一致性
打印机后台处理程序
以及其他程序
该程序运行过程中
只能生成一个实例
避免对同一资源产生相互冲突的请求
单例设计模式的意图:
确保类有且只有一个对象被创建。
为对象提供一个访问点,以使程序可以全局访问该对象。
控制共享资源的并行访问
实现单例模式的一个简单方法是:
使构造函数私有化
并创建一个静态方法来完成对象的初始化
这样做的目的是:
对象将在第一次调用时创建
此后,这个类将返回同一个对象
实践:
1.只允许Singleton类生成一个实例。
2.如果已经有一个实例了 则重复提供同-个对象
class Singletion(object):
def __new__(cls):
'''
覆盖 __new__方法,控制对象的创建
'''
if not hasattr(cls,'instance'):
'''
hasattr 用来了解对象是否具有某个属性
检查 cls 是否具有属性 instance
instance 属性的作用是检查该类是否已经生成了一个对象
'''
cls.instance = super(Singletion,cls).__new__(cls)
'''
当对象s1被请求创建时,hasattr发现对象已经存在
对象s1将被分配到已有的对象实例
'''
return cls.instance
s = Singletion()
'''
s对象 通过 __new__ 方法进行创建
在创建之前,会检查对象是否已存在
'''
print("对象已经创建好了:",s)
s1 = Singletion()
print("对象已经创建好了:",s1)
'''
运行结果:
对象已经创建好了: <__main__.Singletion object at 0x000001EE59F93340>
对象已经创建好了: <__main__.Singletion object at 0x000001EE59F93340>
'''
设计模式_单例模式的懒汉式实例化
单例模式的懒汉式
在导入模块的时候,可能会无意中创建一个对象,但当时根本用不到
懒汉式实例化能够确保在实际需要时才创建对象
懒汉式实例化是一种节约资源并仅在需要时才创建它们的方式
class Singleton:
_instance = None
def __init__(self):
if not Singleton._instance:
print("__init__的方法使用了,在静态 getinstance 方法才创建了实例对象")
else:
# 在静态 getinstance 方法,改变了 _instance 的值
print("实例已创建",self.getinstance())
@classmethod
def getinstance(cls):
'''
在 getinstance 内写创建实例的语句
如果在 __init__ 内写明创建语句
如果那个对象创建之后没有立即使用,会造成资源浪费
'''
if not cls._instance:
cls._instance = Singleton()
'''
创建实例化对象时,还会再调用一次 __init__方法
cls._instance = Singleton() 修改了 _instance 属性的状态
'''
return cls._instance
s = Singleton()
# __init__的方法使用了,在静态 getinstance 方法才创建了实例对象
print('已创建对象',Singleton.getinstance())
'''
此时才是真正的创建了对象
运行结果:
__init__的方法使用了,在静态 getinstance 方法才创建了实例对象
已创建对象 <__main__.Singleton object at 0x00000206AA2436D0>
'''
print(id(s))
# 2227647559520
s1 = Singleton()
# 实例已创建 <__main__.Singleton object at 0x00000206AA2436D0>
print('已创建对象',Singleton.getinstance())
# 已创建对象 <__main__.Singleton object at 0x00000206AA2436D0>
print(id(s1))
# 2227647561248
创建一个静态变量 _instance = None
在 __init__ 方法内部,不进行创建对象的操作
在类方法 getinstance 方法中,进行类的创建
注:
此时会调用一次 __init__ 方法
创建对象时
s = Singleton() 还会调用一次 __init__ 方法
查看MySQL支持的存储引擎

查看当前所有数据库
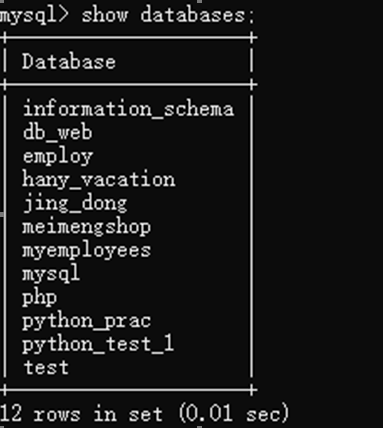
创建一个数据库

选择当前操作的数据库

删除数据库

查看数据库表
创建一个数据库表

显示表的结构
查看创建表的创建语句

向表中加入记录

删除记录

更新记录

删除表

在类外创建函数,然后使用类的实例化对象进行调用
def f(self,x):
y = x + 3
return y
class Add:
# 创建一个 Add 类
def add(self,a):
return a + 4
f1 = f
# 让 f1 等于外面定义的函数 f
n = Add()
# 创建实例化对象
print(n.add(4))
# 调用类内定义方法
print(n.f1(4))
# 调用类外创建的方法
运行结果:
8
7
[Finished in 0.2s]
需要注意的点:
外部定义的函数第一个参数为 self
创建类的实例化对象使用 Add()
括号不要丢
2020-07-25
查看MySQL支持的存储引擎
查看当前所有数据库
创建一个数据库
选择当前操作的数据库
删除数据库
查看数据库表
创建一个数据库表
显示表的结构
查看创建表的创建语句
向表中加入记录
删除记录
更新记录
删除表
在类外创建函数,然后使用类的实例化对象进行调用
def f(self,x):
y = x + 3
return y
class Add:
# 创建一个 Add 类
def add(self,a):
return a + 4
f1 = f
# 让 f1 等于外面定义的函数 f
n = Add()
# 创建实例化对象
print(n.add(4))
# 调用类内定义方法
print(n.f1(4))
# 调用类外创建的方法
运行结果:
8
7
[Finished in 0.2s]
需要注意的点:
外部定义的函数第一个参数为 self
创建类的实例化对象使用 Add()
括号不要丢
2020-07-25