Node.js 爬虫爬取电影信息
我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713
爬取的是1905电影网的信息,使用的是正则匹配。
本来为了更好地学习异步编程打好基础,没想到这玩意这么上头。
代码也写了好几天,自己技术不到家,肯定有写的不好的地方,还需要多努力。
下个月争取把vue学完,九月估计该开学了。
代码在最下面
const request=require('request');
const url="https://www.1905.com/vod/list/n_1/o3p1.html";
const fs=require('fs');
const { resolve } = require('path');
function req(url){
return new Promise((resolve,reject)=>{
request.get(url,(err,response,body)=>{
if(err) reject(err)
else resolve({response,body});
})
})
}
//获取起始界面的所有分类地址
async function getClassUrl(){
let {response,body}=await req(url);
// console.log(body);
let reg1=/<span class="search-index-L">类型 :<\/span>(.*?)<div class="grid-12x">/igs; //i不区分大小写 g全局 s让.匹配换行
let result1=reg1.exec(body)[1];
let reg2=/<a href="javascript\:void\(0\);" onclick="location\.href='(.*?)';return false;"(.*?)>(.*?)<\/a>/igs;
let result2="";
// console.log(reg2.exec(result1));
let urlArr=[];
while(result2=reg2.exec(result1)){
if(result2[3]!="全部"){
let obj={
className:result2[3],
url:result2[1]
}
urlArr.push(obj);
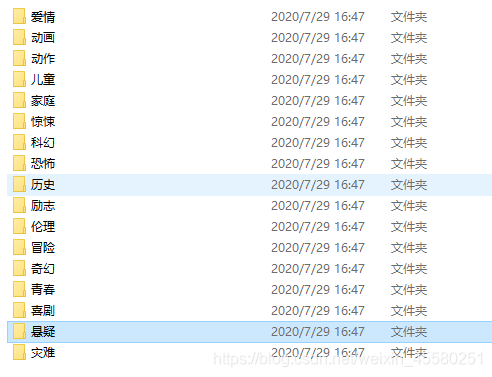
fs.mkdir("./movies/"+result2[3],{ recursive: true },(err) => {
if (err) throw err;
});
getMovies(result2[1],result2[3]);
// console.log(result2.index);
// console.log(reg2.lastIndex);
}
}
// console.log(urlArr.length); //17个分类
};
//通过分类栏,获取页面中的电影连接
async function getMovies(url,className){
let {response,body}=await req(url);
let reg3=/<a class="pic-pack-outer" target="_blank" href="(.*?)".*?><img/igs;
let result3="";
let urlArr=[];
while(result3=reg3.exec(body)){
urlArr.push(result3[1]);
getDate(result3[1],className);
}
}
//对电影详情页进行分析
async function getDate(url,className){
let {response,body}=await req(url);
let reg1=/<h1 class="playerBox-info-name playerBox-info-cnName">(.*?)<\/h1>/;
// let reg4=/<!-- 文字简介 -->.*?<span id="playerBoxIntroCon">(.*?)<a href="(.*?)" target="_blank" data-hrefexp="fr=vodplay_ypzl_xx">\.\.\.<span>[详细]/;
let result1=reg1.exec(body);
// console.log(result1[1]);
let reg2=/<span id="playerBoxIntroCon">(.*?)<a href="(.*?)" /;
let result2=reg2.exec(body);
// console.log(result2[2]);
writeFile(result1,result2,url,className);
}
//写入文件
async function writeFile(result1,result2,url,className){
let movie={
name:result1[1],
brief:result2[1],
url:url,
details:result2[2]
};
let data=JSON.stringify(movie);
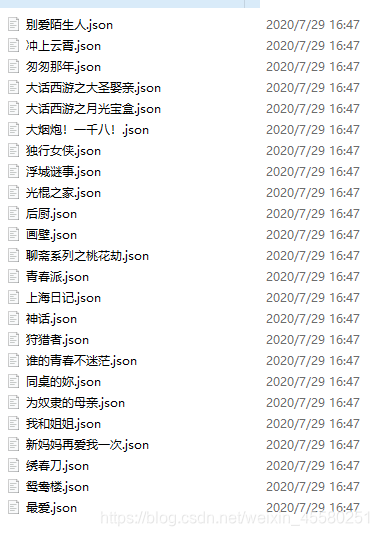
fs.writeFile(`./movies/${className}/${movie.name}.json`,data,(err)=>{
if (err) {return console.log(err)}
});
//下面的写入流写法也可以
// let w = fs.createWriteStream(`./movies/${className}/${movie.name}.json`);
// w.write(data,'utf-8');
// w.end;
// w.on('error', function(err){
// console.log(err.stack);
// });
};
getClassUrl();