1.准备工作
前提是安装过node
准备一个文件夹, 比如:“drag-data”
依次安装依赖 npm install https request cheerio --save
在文件夹drag-data下创建data和image两个文件,用来存储抓取的数据
(抓取豆瓣电影url=“https://movie.douban.com/subject/1291843/?from=subject-page”)
2. 编写启动js文件
在drag-data文件下创建index.js文件
// 引入和定义初始变量
let http = require('https')
let fs = require('fs') // 文件读写
let request = require('request') // 发送request请求
let cheerio = require('cheerio') // jquery写法-获得所欲页面dom元素
let url = 'https://movie.douban.com/subject/1291843/?from=subject-page'
let i = 0
function fetchPage (x) {
startRequest(x)
}
// 开始函数
function startRequest (x) {
// 用http模块向服务器发起get请求
http.get(x, function(res) {
// 存储请求网页的整个html内容
let html = ''
res.setEncoding('utf-8') // 防止中文乱码
// 监听data事件,每次取一块数据
res.on('data', function (chunk) {
html += chunk
})
// console.info(html)
// 监听end事件,如果整个页面的内容获取完毕,执行回调函数
res.on('end', function () {
let $ = cheerio.load(html) // 用cheerio模块解释html
let news_item = {
// 电影标题
title: $('.related-info h2 i').text().trim(),
// i是用来判断获取页数
i: i = i + 1
}
console.info(news_item) // 新闻信息打印
let news_title = $('.related-info h2 i').text().trim()
saveContent($, news_title) // 存储每篇文章内容及标题
saveImg($, news_title) // 存储每篇文章图片及标题
// 下一篇电影的url
nextlink = $('.recommendations-bd dl:last-child dd a').attr('href')
if (i <= 10) {
fetchPage(nextlink)
}
}).on('error', function (err) {
console.info(err)
})
})
}
// 存储标题函数
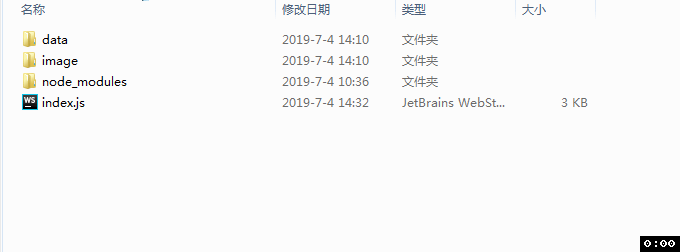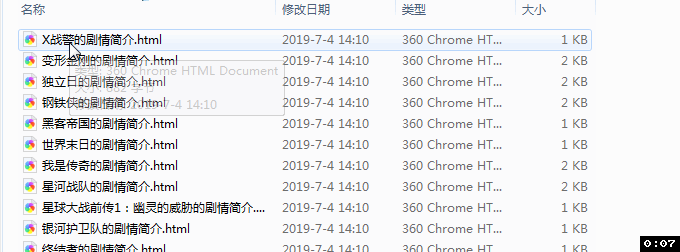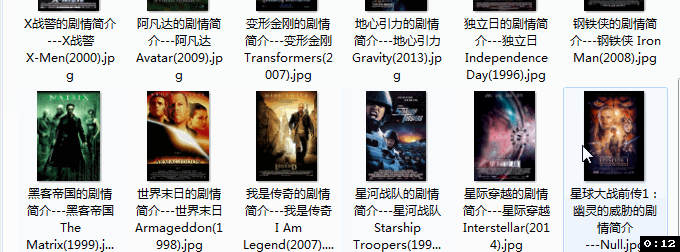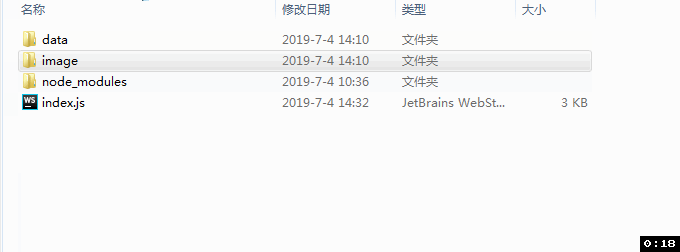
function saveContent ($, news_title) {
$('#link-report span').each(function (index, item) {
let x = $(this).text()
x = x + '\n'
// 将新闻文本内容一段一段添加到/data文件夹下,并用新闻标题命名文件
// fs.appendFile('./data/' + news_title + '.txt', x, 'utf-8', function(err) {
// if (err) {
// console.info(err)
// }
// })
fs.writeFile('./data/' + news_title + '.html', x, 'utf-8', function(err) {
if (err) {
console.info(err)
}
})
})
}
// 在本地存储爬取得图片资源
function saveImg ($, news_title) {
$('#mainpic img').each(function (index, item) {
// 图片标题
let img_title = $('#content h1 span').text().trim()
if (img_title.length > 35 || img_title === '') {
img_title = 'Null' // 图片标题过长
}
let img_filename = img_title + '.jpg'
let img_src = $(this).attr('src') // 获取图片url
// 用request模块,想服务器发请求,获取图片资源
request.head(img_src, function (err, res, body) {
if (err) {
console.info(err)
}
})
request(img_src).pipe(fs.createWriteStream('./image/' + news_title + '---' + img_filename))
})
}
fetchPage(url)
3. 启动js文件
在git中执行 node index.js
结果如下图