```handlebars
const http = require('https');
const fs = require('fs');
const cheerio = require('cheerio');
let url = 'https://www.csdn.net/';
http.get(url, (res) => {
const {
statusCode } = res;
const contentType = res.headers['content-type'];
console.log(statusCode, contentType);
let err = null;
if (statusCode !== 200) {
err = new Error('请求状态错误')
} else if (!/^text\/html/.test(contentType)) {
err = new Error('请求类型错误')
}
if (err) {
console.log(err);
res.resume();
return false;
}
let rawData = '';
res.on('data', (chuck) => {
console.log("----");
rawData += chuck.toString('utf8');
})
res.on('end', (chuck) => {
console.log("数据传输完毕")
fs.writeFileSync('./bibi.html', rawData);
let $ = cheerio.load(rawData);
$('img').each((index, el) => {
console.log($(el).attr('src'))
})
})
}).on('error', (err) => {
console.log(err)
})
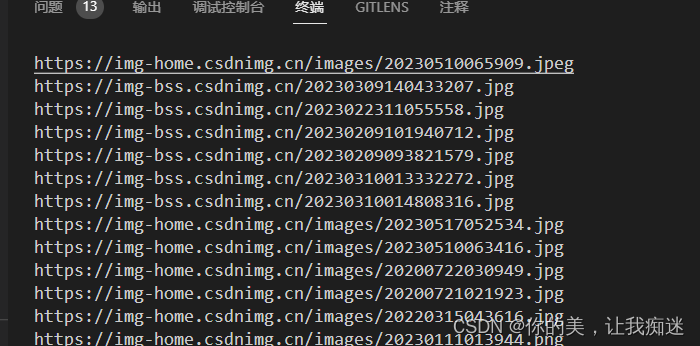
爬取效果图: