Node.js:是一个基于前端的服务器,主要的特点:单线程,异步I/O(对这个没有了解,开发起来真的会踩很多坑),事件驱动
前言:本人主要是一个以使用.Net平台下的语言,进行开发的一个菜鸡,之前面试这家公司的时候,面试官问我一个问题给你一个页面里面有十页的分页数据,你能使用什么技术将这些数据全部抓取出来。对于当时刚毕业的我听到这个问题,心里一下想到python(对它没有任何的了解,我以为python只是用来做数据挖掘的,对着门语言完全没了解过贸然吹牛感觉会被打脸),然后我尴尬的说了句在网页控制台里使用jquery或者js,抓当前页的数据(只是在控制台里展示出来,还不能入库),面试官听到这个回答,我只看到了他嘴角上扬了一下,但是最后居然还是奇迹般的通过了面试,进入了这家公司直到现在,非常感恩这次机会,算是让我正式步入了IT这个行业,成为一名专业的编程人员吧。
之后我尝试过使用c#的WebBrowser对象,Python的HTMLSession包来抓这个薄荷网的数据,最后在对比的时候还是觉得Node.js(异步搞清楚之后)好使,在Node.js里那些已经被大神们封装好的包,直接拿来使用就行,几乎只需要一点点的HTML层级结构知识,一点jQuery选择器知识差不多就能将整个网页的数据进行爬取了。
薄荷网地址:http://www.boohee.com/food/,这个网站的 热量查询板块 非常适合拿来练手( 还是程序员自己人坑自己人呀!哈哈哈哈哈,还是给人家打一波广告吧,虽然没什么流量,哈哈哈哈) 薄荷 减肥健身 掌控人生 专业的在线体重管理平台 强大的食品营养数据库
源码
GitHub:https://github.com/loyking/NodeJs.git
下载包语法:
npm install packagename
需要导入的包: var http = require("http"), //http协议请求
url = require("url"), //url地址
sql = require("mssql"), //数据库操作
express = require("express"), //框架
superagent = require("superagent"), //网络请求(注意:没有连接网络,则请求不了网页)
eventproxy = require("eventproxy"), //异步回调
cheerio = require("cheerio"), //node.js中的jquery库
uuid = require("uuid/v4"), //v1:产生时间戳的uuid 使用的数据库为SQL server2017版,表中定义的主键类型为uniqueidentifier,在nodejs中对应的则是uuid
async = require("async") //异步
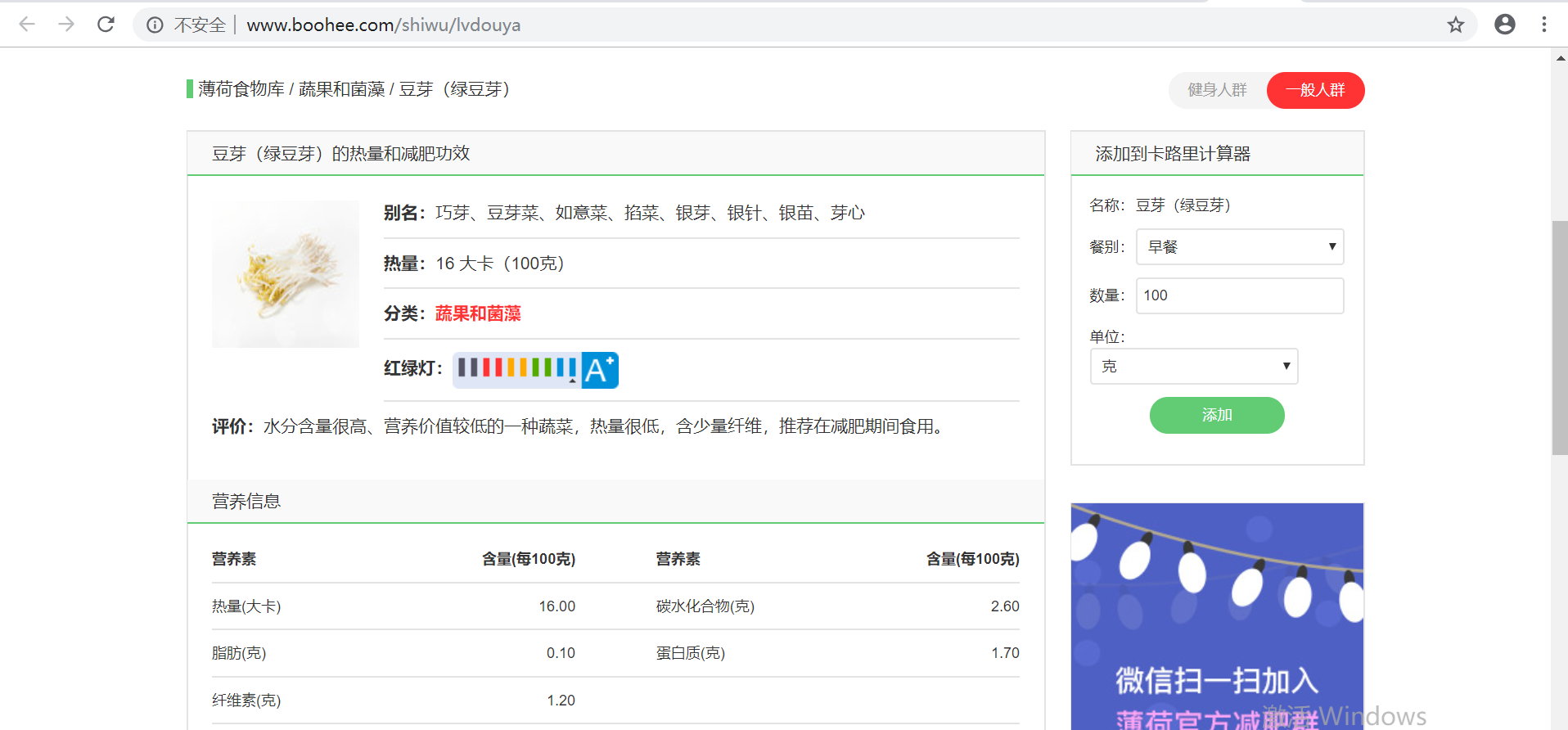
目标:将热量查询板块 =》 薄荷食物库 =》 每个分类中的食物名称、热量、评价.....等等相关数据进行爬取(画的有点丑)

首先进去之后就能看到如下板块了,一共是11个板块分类(图没有截全请不要介意.........)
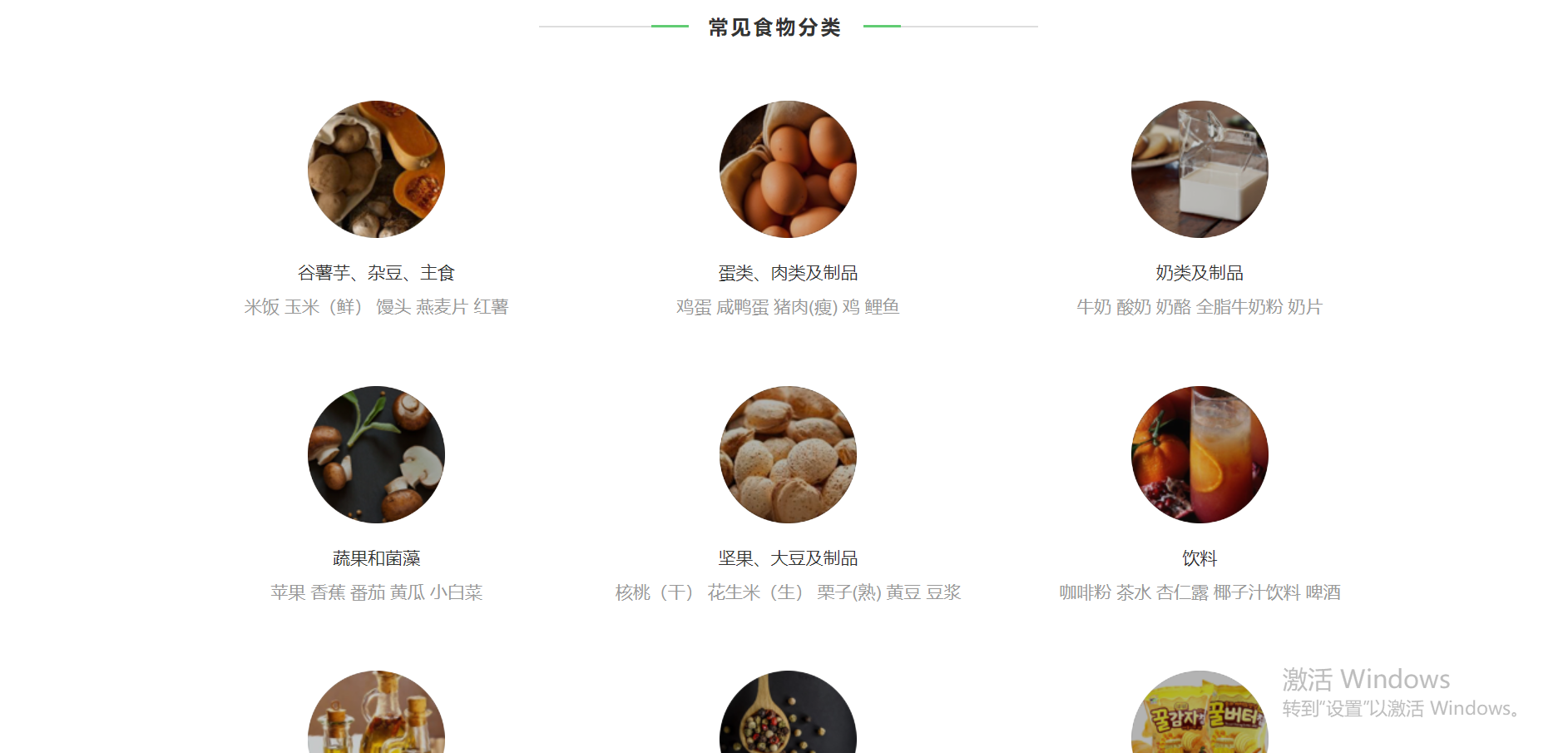
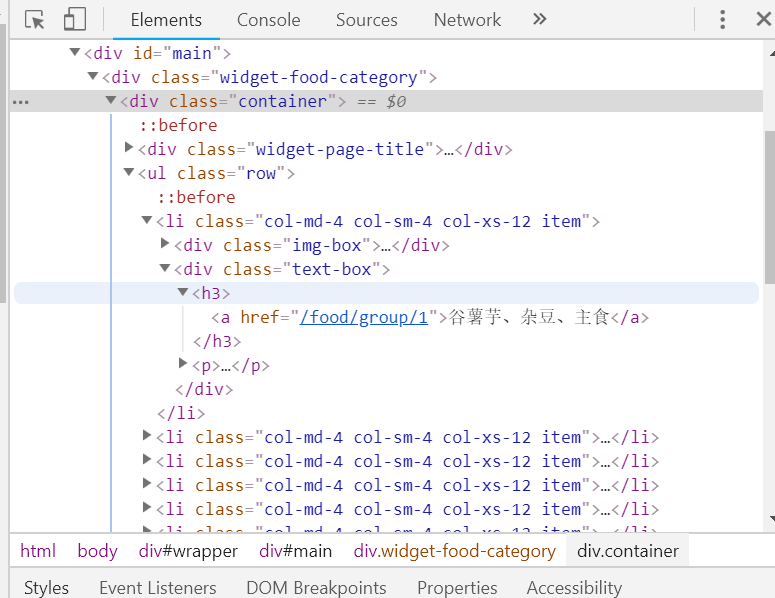
我们现在需要做的第一步就是对这个页面的层级结构进行分析一波,得到我们想要的数据(每个分类板块的url地址),按下F12键打开 开发者工具 查看一下这些分类的层级结构 就是如下图了,我们需要的一级数据(对数据进行一个排序,从父级(分类板块)开始)就是那个a表的href属性了
然后它的层级结构是(我们用jquery选择器来做实例,cheerio包是支持这种jq语法的)
$("#main .container ul[class='row'] li div[class='text-box'] h3 a").attr('href') 其实根本不需要写的这么复杂,这里只是让大家对这个层级有一个清晰的了解
由于我们取到的是对应的分类路径没有带域名的,所以我们等下在程序中是需要定义一个常量来保存域名信息,然后对获取到的href进行字符拼接
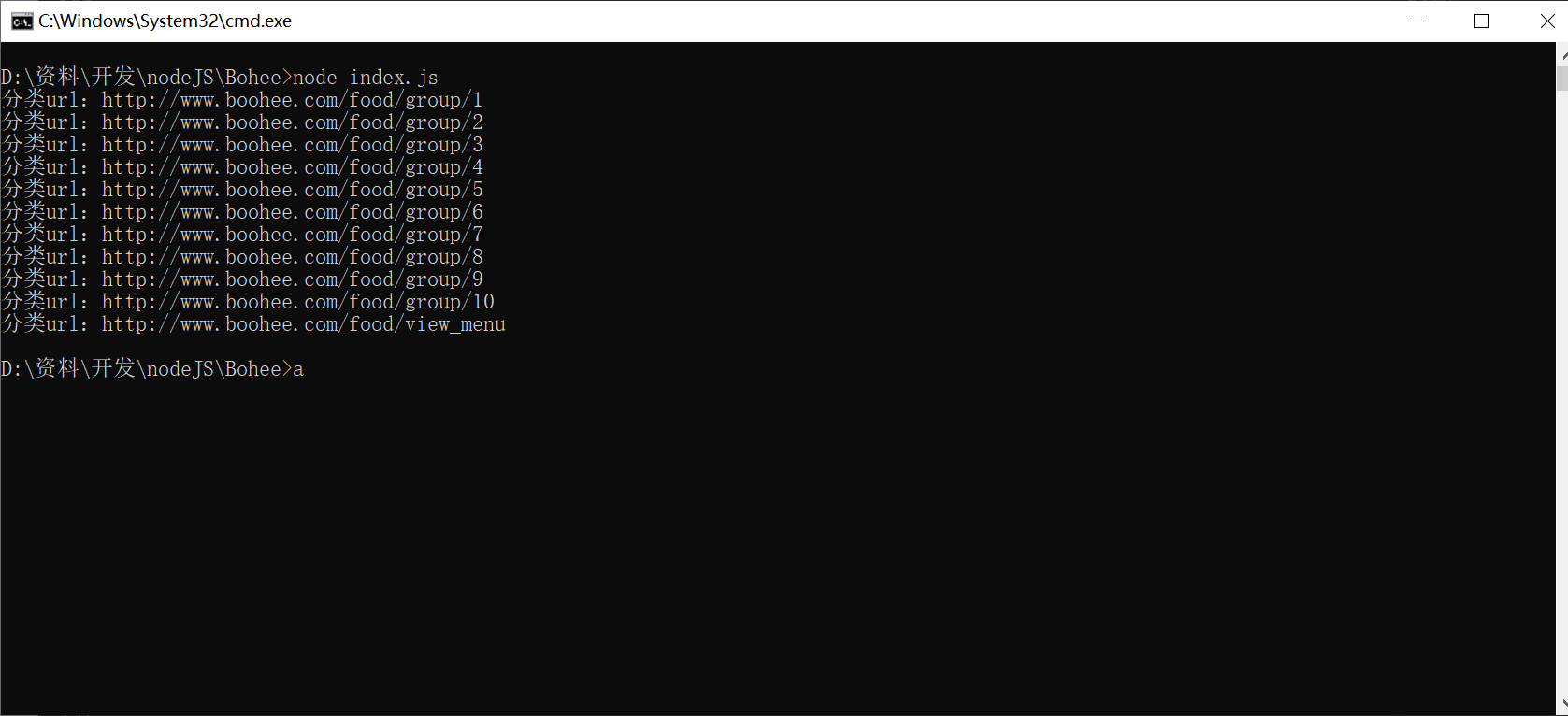
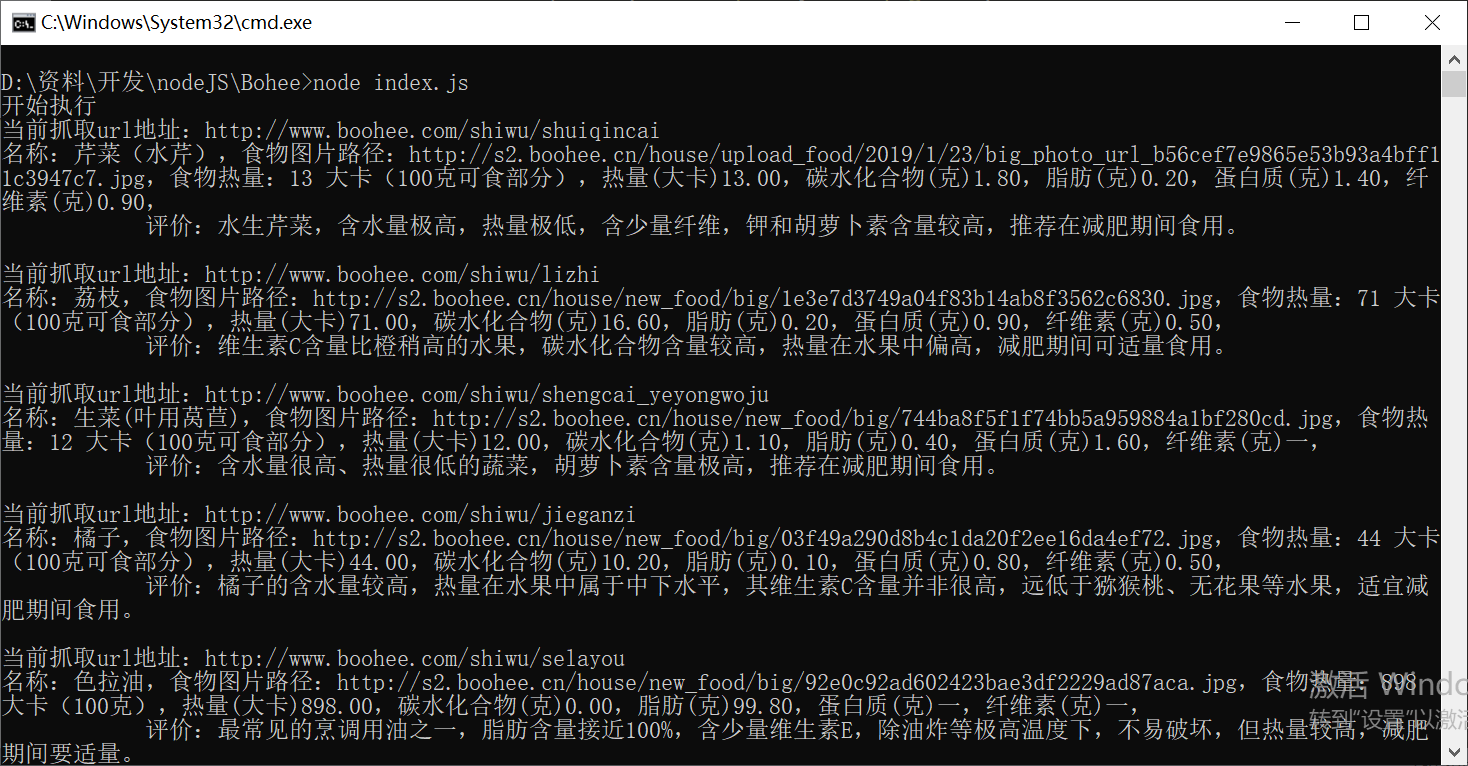
我使用的是Windows下的环境,启动程序之后,控制台进行输出所有的分类url(每个食品分类板块的url)
对分类url进行循环遍历,得到所有该板块下所有的食物信息

根据当前板块的url得到所有的食品url信息,根据html层级结构布局来看想要得到所有的食品信息是肯定需要使用循环遍历的
首先得到该食品链接的a标签:$("div[class='img-box pull-left'] a[target='_blank']") ,进行遍历循环然后再单个元素进行attr("href")取得属性值
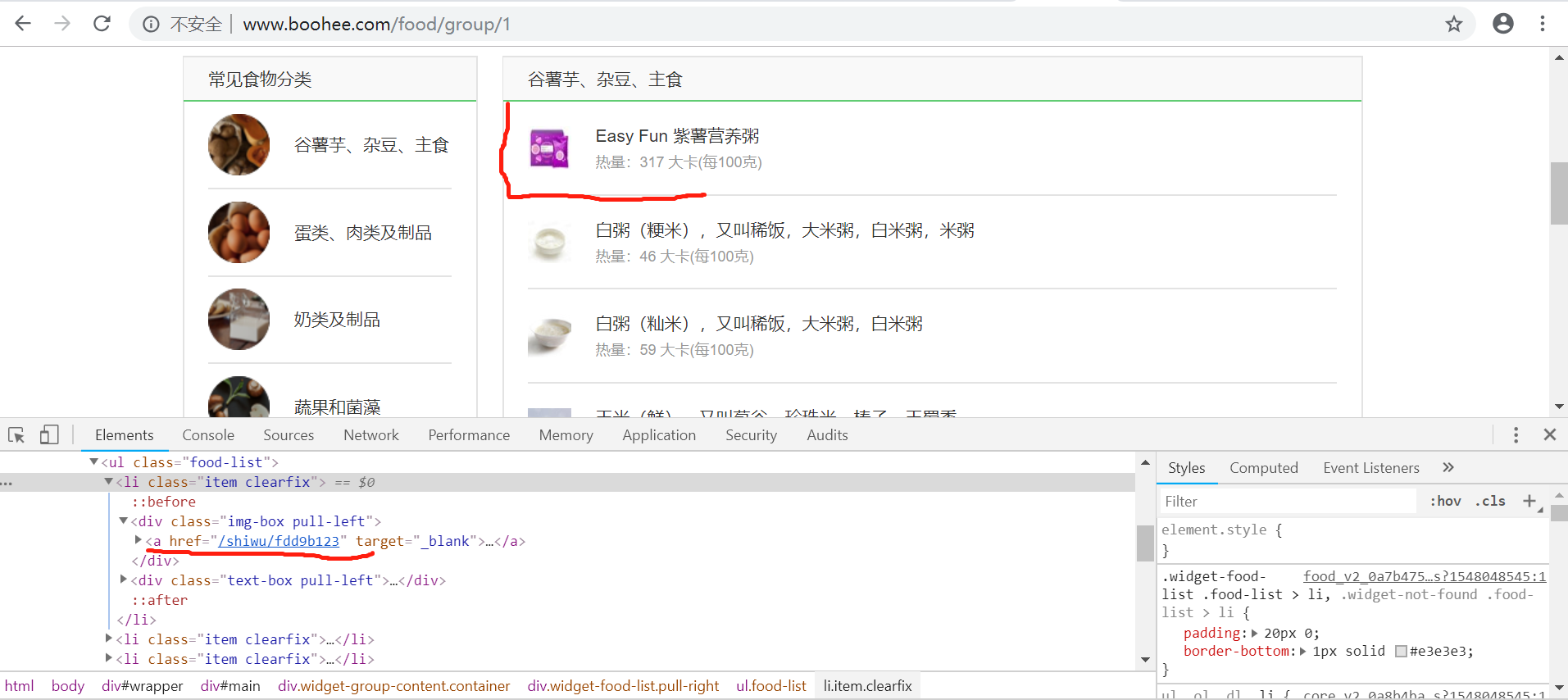
然后将所有的a标签的href属性进行输出得到如下图信息(在异步的执行中可能不是按照原有页面排版的顺序进行输出)

得到所有的食物url后就能直接请求页面抓取我们想要的数据了
具体内部实现可从GitHub上复制源码下载至本地阅读,抓取数据也许不是程序员开发必备的技能,但是稍微了解了解也是好的,当作成一个辅助技能挺好的
2019转折点的一年啊,加油
开工大吉,哈哈哈接了公司好多红包哦