一、引言
昨天接到Mentor给的任务,让我写一个爬虫,根据给定的论文中中文作者的英文名字(实际上就是拼音),去GitHub和LinkedIn上爬去作者的邮箱,说是公司要用。对于一个爬虫小白的我来说,也算是一个艰巨的挑战了,毕竟这将是我写的第一个爬虫程序。大脑一片空白毫无思路可言。然后就开始了我的漫漫搜索之路,网上关于爬虫的文章确实不少,也找到不少干货,不够对于我这样的爬虫小白来说,确实比较难懂。不过最后还是找到了一篇可以让我入门的文章https://www.jianshu.com/p/628a0747c492,在这里我找到了GitHub的API接口。
- 教科书般的API接口信息
Github作为一个出色的代码托管平台,也为开发者们提供了结构非常清晰的API接口信息,浏览器安装json插件后阅读更佳。 - 详细的开发者文档
想了解相关参数设置和可爬取的数据,可阅读Github Developer Guide
就这样我写出了我的第一个爬虫程序。废话不多说,赶紧上思路。
二、思路
爬取目标:
用户的基本信息,邮箱,地址,GitHub主页地址。
逻辑思路:
- 先根据GitHub提供的search接口,根据用户的名字(fullname)搜索到用户信息,其中大多是和用户相关的URL地址。
- 过滤存储用户个人信息的URL地址。
- 得到存储用户个人信息的URL地址,将所需要的用户字段爬去下来。
- 过滤需要的用户信息字段,并返回。
具体实现:
- 单步讲解:
- 首先代码是使用Node.js的express框架写的。
- 查看GitHub的开发者文档,查看爬去用户信息的方法及参数设置。开发者文档如下所示。
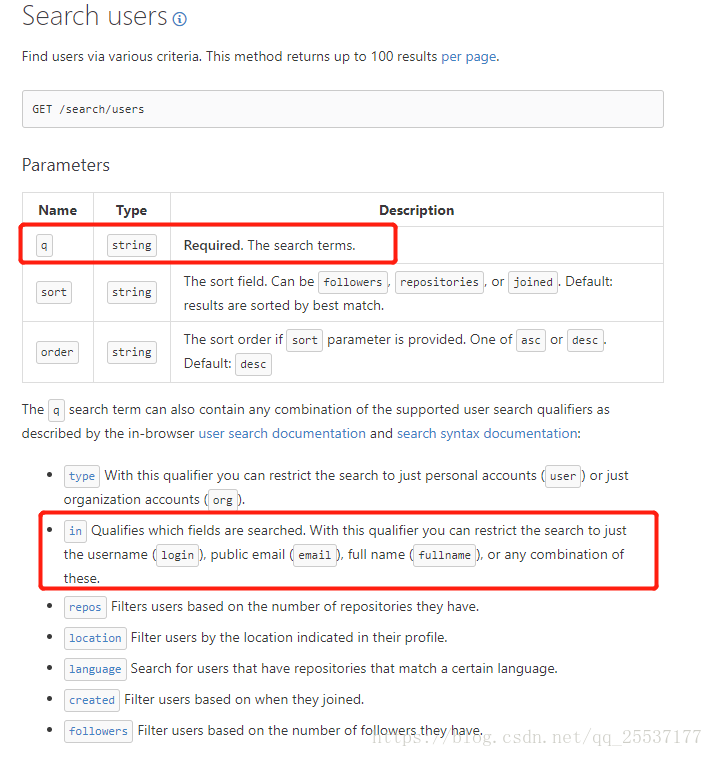
function
gethomepage(
username,
req,
res) {
return
new
Promise(
function (
resolve,
reject) {
//根据名字,搜索基本信息
var
options = {
url:
'https://api.github.com/search/users?q=fullname:' +
username,
headers: {
'User-Agent'
:
'Mozilla/5.0',
'Authorization'
:
'token 78e380f2e6d1a4b8239d9c3baea026b6d248fe14',
'Content-Type'
:
'application/json',
'method'
:
'GET',
'Accept'
:
'application/json'
}
}
var
info =
"";
request(
options,
function (
err,
response,
body) {
if (!
err &&
response.
statusCode ==
200) {
info =
JSON.
parse(
body);
resolve(
info);
}
})
})
}
var
info =
await
gethomepage(
arguments,
req,
res);
//把url解析出来
var
nickname =
" ";
var
html_url =
"";
var
homeurl =
"";
//将爬取出来的信息迭代出来
for (
var
item
of
info.
items) {
nickname =
item[
'login'];
html_url =
item[
'html_url'];
homeurl =
item[
'url'];
}
将请求的结果存储在Info中,然后在第二步的逻辑中调用请求到的info,过滤出用户想要的字段,并将过滤数据返回。
request(
options,
function (
err,
response,
body) {
if (!
err &&
response.
statusCode ==
200) {
var
info1 =
JSON.
parse(
body);
res.
json({
name:
info1.
name,
nickname:
info1.
login,
html_url:
info1.
html_url,
location:
info1.
location,
email:
info1.
email
});
}
else {
res.
send(
{
error:
err.
message,
result:
"have no this person infomation"
}
);
}
})
var
arguments =
process.
argv.
splice(
2);
console.
log(
"您要搜索的对象为:" +
arguments);
var
info =
await
gethomepage(
arguments,
req,
res);
运行方式

- 完善后成功爬取数据的代码如下:
var
express =
require(
'express');
var
app =
express();
var
request =
require(
'request');
var
cheerio =
require(
'cheerio');
app.
get(
'/',
async
function (
req,
res) {
//var info = await gethomepage("Longhui Wei", req, res);
var
arguments =
process.
argv.
splice(
2);
console.
log(
"您要搜索的对象为:" +
arguments);
var
info =
await
gethomepage(
arguments,
req,
res);
//把url解析出来
var
nickname =
" ";
var
html_url =
"";
var
homeurl =
"";
//将爬取出来的信息迭代出来
for (
var
item
of
info.
items) {
nickname =
item[
'login'];
html_url =
item[
'html_url'];
homeurl =
item[
'url'];
}
var
options = {
url:
homeurl,
headers: {
'User-Agent'
:
'Mozilla/5.0',
'Authorization'
:
'token yourTokenvalue',
'Content-Type'
:
'application/json',
'method'
:
'GET',
'Accept'
:
'application/json'
}
}
request(
options,
function (
err,
response,
body) {
if (!
err &&
response.
statusCode ==
200) {
var
info1 =
JSON.
parse(
body);
res.
json({
name:
info1.
name,
nickname:
info1.
login,
html_url:
info1.
html_url,
location:
info1.
location,
email:
info1.
email
});
}
else {
res.
send(
{
error:
err.
message,
result:
"have no this person infomation"
}
);
}
})
});
function
gethomepage(
username,
req,
res) {
return
new
Promise(
function (
resolve,
reject) {
//根据名字,搜索基本信息
var
options = {
url:
'https://api.github.com/search/users?q=fullname:' +
username,
headers: {
'User-Agent'
:
'Mozilla/5.0',
'Authorization'
:
'token yourTokenValue',
'Content-Type'
:
'application/json',
'method'
:
'GET',
'Accept'
:
'application/json'
}
}
var
info =
"";
request(
options,
function (
err,
response,
body) {
if (!
err &&
response.
statusCode ==
200) {
info =
JSON.
parse(
body);
resolve(
info);
}
})
})
}
var
server =
app.
listen(
3001,
function () {
console.
log(
'listening at 3001');
});
问题总结:
一、用户验证Token的问题。https://developer.github.com/v3/auth/
二、返回403 Forbidden https://developer.github.com/v3/#user-agent-required
三、参考文档 https://developer.github.com/v3
详细接口信息 API接口
请详细阅读 Github Developer Guide
未完待续。。。。。。。。。。。。。。。。。。