面试问题:找出一段日志中出现的IP地址以及IP地址出现的次数。
awk是一个强大的文本分析工具,之前面试的时候总会问到awk相关的东西,现在做一下总结。
awk命令:
基本语法:awk [选项参数] 具体表达式 filename
选项参数:
log.txt文件内容:
2 this is a test
3 Are you like awk
This’s a test
10 There are orange apple
-F :相当于内置变量FS,指定分隔符;
示例:awk -F, ‘{print $1,$2}’ log.txt 使用“,”进行分割,打印每一行第一个字符和第二个字符;
使用内建变量写法:awk ‘BEGIN{FS=","} {print $1,$2}’ log.txt
-v:设置变量
示例:awk -va=1 ‘{print $1,$1+a}’ log.txt 打印每一行第一个字符以及第一个字符+1后的值;
输出结果:
2 3
3 4
This’s 1
10 11
awk -va=1 -vb=s ‘{print $1,$1+a,$1b}’ log.txt
输出结果:
2 3 2s
3 4 3s
This’s 1 This’ss
10 11 10s
行匹配语句:awk ‘{[pattern] action}’ filenames 只能用’ ’ 单引号。
示例:awk ‘{print $1,$4}’ log.txt 输出每行的第一项和第四项
输出 :
2 a
3 like
This’s
10 orange
awk ‘$1>2’ log.txt 过滤第一列大于2的行;
输出:
3 Are you like awk
This’s a test
10 There are orange apple
awk ‘$1>2 && $2==“Are” {print $1,$2,$3}’ log.txt 过滤第一列大于2并且第二列等于’Are’的行,打印第一、第二、第三个字符
输出:
3 Are you
awk 脚本:
awk -f {awk脚本} {文件名}
示例:awk -f cal.awk log.txt
脚本语法规则:
BEGIN{ 这里面放的是执行前的语句 }
{这里面放的是处理每一行时要执行的语句}
END {这里面放的是处理完所有的行后要执行的语句 }
示例:
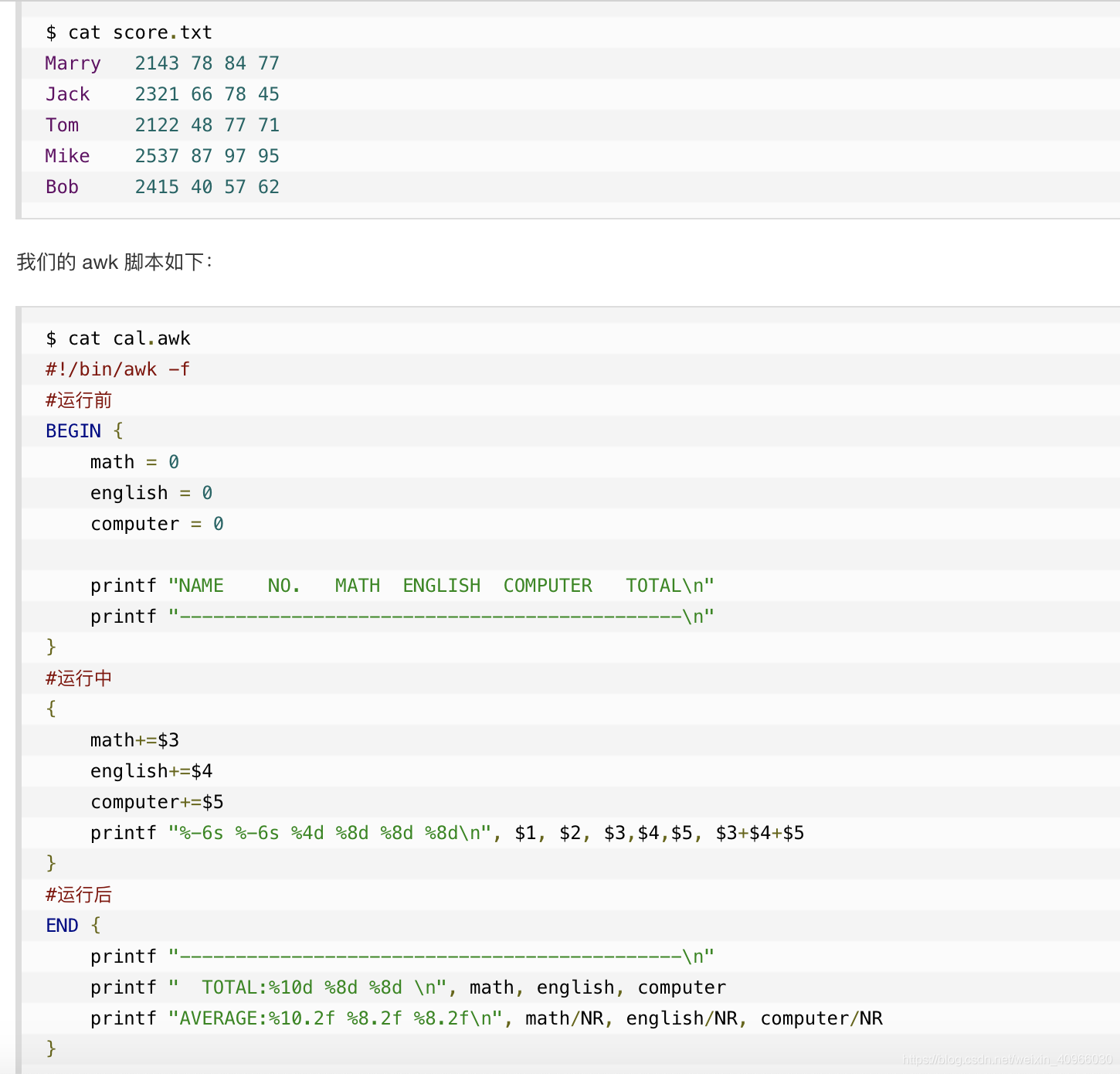
输出:
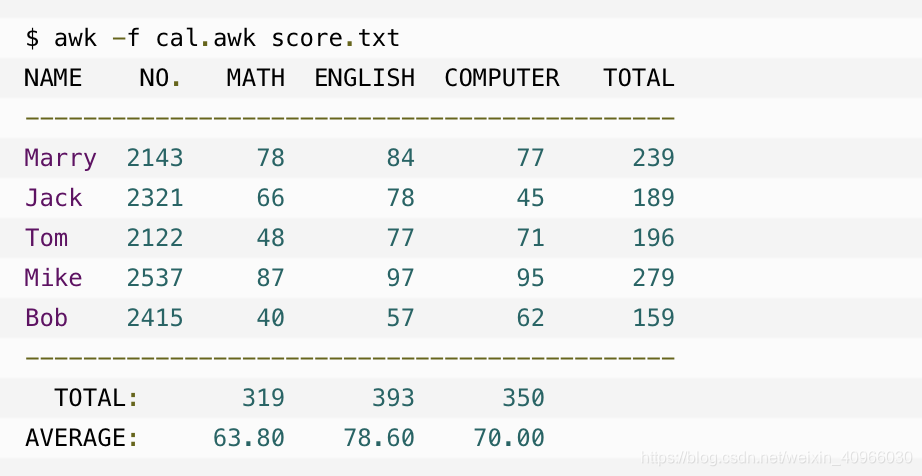
现在来看面试题:
写法一:cat aa.txt |awk -F " " ‘{print $1}’ |uniq -c |sort -r
uniq -c:对结果进行统计次数;
sort -r :对结果进行倒叙排序;
写法二:
awk ‘{a[$1]+=1;} END {for(i in a){print a[i]" "i;}}’ log/visit.log | sort -t " " -k 1 -n -r
sort默认是升序的,sort默认对一行的首字母进行排序,需要加入其它参数 -t 指定分隔符 -k 指定列 -g 按照常规数值排序 -n 根据字符串数值比较,
-r 降序排列。