在这篇博客之前,花了些时间了解红黑树的内容,但是没有形成自己的知识图谱,也没有一条清晰的逻辑主线将知识串联起来,这次重新整理了一下。
首先,这里过滤了树模型的一些基础概念上的内容,比如父节点,子节点,叶子节点(叶节点),兄弟节点,树的深度,树的高度,树的层数等,在这篇博客中没有叙述。
首先以最基本的二叉树开始,由浅入深,逐渐了解各个算法的优缺点适用场景,可以解决什么样的问题,优缺点有哪些,实现权衡等。
章节和对应的主要内容:
| 序号 | 内容 |
|---|---|
| 1 | 二叉树 |
| 2 | 二叉查找树 |
| 3 | 平衡二叉查找树 |
| 4 | 红黑树 |
| 5 | 总结 |
目录:
- 二叉树
- 二叉查找树
2.1 二叉查找树的查找
2.2 二叉查找树的插入
2.3 二叉查找树的删除
2.4 二叉查找树的时间复杂度分析
2.5 二叉查找树的总结 - 平衡二叉树
3.1 平衡二叉树的概念
3.2 平衡二叉树带来的问题 - 红黑树
4.1 红黑树近似平衡的简单证明 - 总结
1:二叉树
二叉树可以分为以下几种:
- 普通二叉树——对应编号1
- 满二叉树——对应编号2
- 完全二叉树——对应编号3
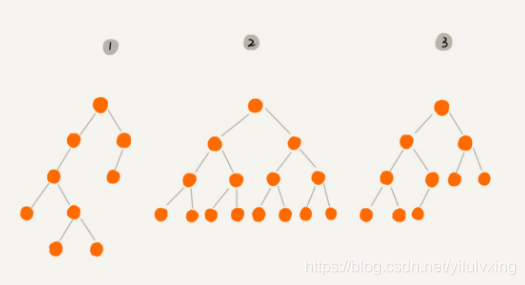
(1)普通二叉树
- 编号1,由一个根节点加上两棵分别称为左子树和右子树组成
(2)满二叉树
- 编号 2 的二叉树中,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点
(3)完全二叉树
- 编号 3 的二叉树中,叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大
在理解二叉树的定义和类别后,进一步思考,如何存储一棵二叉树?
想要存储一棵二叉树,一种方法是基于指针或者引用的二叉链式存储法,一种是基于数组的顺序存储法。
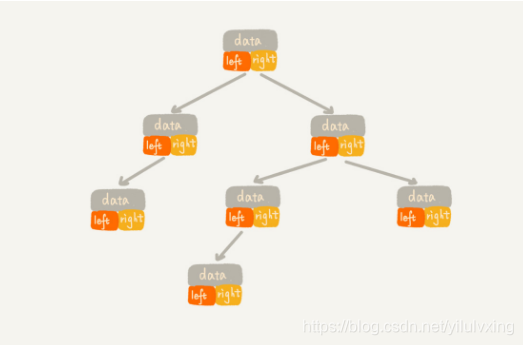
下图表示的就是二叉树的链式存储法,链式存储更为直观,也比较简单。图中,每个节点有三个字段,其中一个存储数据,另外两个指向左右子节点的指针。只要找到根节点,就可以通过左右子节点的指针,把整棵树都串联起来,大部分二叉树都是通过这种结构实现的。
另一种方法,如下图所示,基于数组的顺序存储法,图中,我们把根节点A存储在下标i=1的位置,那么左子节点B存储在下标2*i=2的位置,右子节点C存储在2 * i +1=3的位置,以此类推。总结:如果节点X存储在数组中下标为i的位置,下标为2i的位置存储的就是其左子节点,下标为2 * i +1的位置存储的就是右子节点,反过来也可以倒推。因此,我们只要知道根节点的存储位置(一般情况下,为了方便计算,根节点都会存储在下标为1的位置),这样就可以通过下标计算,把整棵树的节点串联起来。
由于图中显示的是一颗完全二叉树,所以仅仅浪费了一个下标为0的存储位置。
![[外链图片转存失败(img-1QwyyrCV-1562332114148)(C:\Users\weidai\AppData\Local\Temp\1561981522287.png)]](https://img-blog.csdnimg.cn/20190705211338528.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
下图中,由于是一个非完全二叉树,所以在用数组存储的时候,会浪费比较多的存储空间。
![[外链图片转存失败(img-kbvb0JEh-1562332114148)(C:\Users\weidai\AppData\Local\Temp\1561982185267.png)]](https://img-blog.csdnimg.cn/20190705211410915.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
二叉树的遍历
遍历有三种方式:前序遍历、中序遍历和后序遍历。其中,前、中、后序,表示的是节点与它的左右子树接地那遍历的先后顺序
-
前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树——根左右
-
中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树——左根右
-
后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身——左右根
2:二叉查找树
二叉查找树是二叉树中最常用的一种类型,是为了实现快速查找的,不仅仅支持快速查找一个数,还支持快速插入和删除数据。二叉查找树的这些性能都依赖于二叉查找树的特殊结构,二叉查找树的要求,在树中的任意一个接地那,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都要大于这个节点的值。
![[外链图片转存失败(img-NqSiCOPy-1562332114150)(C:\Users\weidai\AppData\Local\Temp\1561982871660.png)]](https://img-blog.csdnimg.cn/20190705211426107.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
2.1:二叉查找树的查找
如果需要查找一个数,首先取根节点,如果它等于要查找的数据,则直接返回,如果小于要查找的数据,则在右子树中继续查找,如果大于要查找的数据,则在左子树中继续查找,也就是二分查找的思想,这样一直递归。
2.2:二叉查找树的插入
二叉树的插入类似于查找过程,首先还是从根节点开始,然后依次比较要插入的数据与接地那的关系。如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插到右子节点的位置;如果不为空,就再递归遍历右子树,查找插入位置。同理,如果要插入的数据比节点的数据小,也是类似的操作。
2.3:二叉查找树的删除
二叉查找树的删除相对于查找和插入要稍微复杂一点。主要有3种情况需要考虑:
- 如果要删除的节点没有子节点,只需要将父节点中,指向阐述接地那的指针置为NULL,比如删除图中的节点55
- 如果要删除的节点只有一个子节点(只有左子节点或者右子节点),只需要删除父节点中,指向要删除的指针,让它指向要删除的节点的子节点就可以了。比如要删除图中节点13
- 如果要删除的节点上有两个子节点,要稍微复杂一点。首先找到这个节点的右子树中最小的节点,把它替换到要删除的节点,然后再删除这个最小节点。因为最小节点肯定没有左子节点。比如删除节点18
![[外链图片转存失败(img-AJbidSQM-1562332114153)(C:\Users\weidai\AppData\Local\Temp\1561983513007.png)]](https://img-blog.csdnimg.cn/20190705211436683.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
2.4:二叉查找树的时间复杂度分析
二叉查找树的形态各式各样。比如这个图中,对于同一组数据,我们构造了三种二叉查找树,它们的查找、插入、删除操作的执行效率都是不一样的。
极端情况下,图中第一种二叉查找树,根节点的左右子树极度不平衡,已经退化成了链表,所以查找的时间复杂度就变成了 O(n)。
![[外链图片转存失败(img-judJkuqx-1562332114154)(C:\Users\weidai\AppData\Local\Temp\1561983897871.png)]](https://img-blog.csdnimg.cn/20190705211446697.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
而从图中可以看到,二叉查找树的插入,删除,查找,都是与树的高度有关。
那么我们考虑在最理想的情况下,问题就变成:如何求得一棵包含n个节点的完全二叉树的高度?
根据完全二叉树的定义,很容易求得:完全二叉树的高度是小于扥等于log2n。
2.5:二叉查找树的总结
二叉查找树,除了插入、删除、查找之外,还可以支持快速查找最大节点、最小节点、前继节点、后继节点。同事二叉查找树还有一个重要特性,就是 中序遍历二叉树,可以输出有序的数据序列,时间复杂度为O(n),非常高效。
进一步思考: 二叉查找树可以支持快速插入、删除、查找操作,各个操作的时间复杂度与树的高度成正比,最理想情况下,时间复杂度是O(logn)。
但在极端情况下,比如频繁的删除等操作,二叉树会退化成一个链表,那么时间复杂度就变成了O(n)。
因此,为了避免这种极端情况,后来又设计一种平衡二叉树,平衡二叉查找树的高度接近 logn,所以插入、删除、查找操作的时间复杂度也比较稳定,是 O(logn)。
3:平衡二叉树
3.1:平衡二叉树的概念
平衡二叉树定义二叉树中任意一个节点的左右子树的高度相差不能大于 1,所以上图中的满二叉树和完全二叉树都是平衡二叉树,但是非完全二叉树也可以是平衡二叉树。
![[外链图片转存失败(img-eQDQOCCY-1562332114155)(C:\Users\weidai\AppData\Local\Temp\1562326496635.png)]](https://img-blog.csdnimg.cn/20190705211500267.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
最先被发明的平衡二叉查找树是AVL树,它是一种非常严格的平衡二叉查找树,即任何节点的左右子树高度相差不超过 1。
实际上,平衡二叉查找树的出现就是为了避免二叉查找树在频繁的插入、删除等操作的情况下,出现极端情况(比如退化成链表),导致时间复杂度退化。
因此,平衡二叉查找树中的“平衡”,意思就是让整个树模型看起来更加对称,不会出现左边特别高,右边特别低,或者左边特别低,右边特别高的情况。这样,整棵树的高度相对来说更低一点,所以插入,删除,查找等操作的效率更高。
3.2:平衡二叉树带来的问题:
虽然平衡二叉树解决了二叉查找树可能退化了链表的极端情况,并且能够把查找时间控制在O(logn),所以”平衡“的意思就是为了使性能不退化。但是由于平衡二叉树严格的定义:每个节点的左子树和右子树的高度差至多等于1,导致每次在插入或者删除的时候,为了符合平衡二叉树严格的条件,需要进行一些操作来进行调整,比如左旋、右旋等操作,使其再次符合平衡二叉树的条件。
很明显,如果要是再插入和删除非常频繁的场景下,平衡二叉树每一次更新都必须要进行调整,这样太耗时了,性能也会受到很大影响。
因此,为了避免平衡二叉树在频繁更新过程中,所带来的维持树结构的时间消耗,从而引入了红黑树。
4:红黑树
上面说到,平衡二叉树的定义非常严格,因此导致在一些特定的场合中, 维持树结构的时间消耗较大。
因此,引入红黑树解决上述问题,红黑树是一个近似平衡的二叉树,它的定义如下:
- 具有二叉查找树的特点
- 根节点是黑色的
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存数据
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的
- 每个节点,从该节点到达其可达的叶子节点是所有路径,都包含相同数目的黑色节点。
![[外链图片转存失败(img-OKjBYYG1-1562332114155)(C:\Users\weidai\AppData\Local\Temp\1562328184794.png)]](https://img-blog.csdnimg.cn/20190705211515994.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
既然红黑树是一个近似平衡的二叉树,那么它的性能与平衡二叉树相比如何?
由上面第二节讲到,二叉查找树的很多操作性能都是与树的高度成正比,而一棵满二叉树、完全二叉树的高度大约是log2n。所以要证明红黑树是近似平衡的,只需要分析,红黑树的高度与二叉查找树最好情况下的log2n相比就可以。
4.1:红黑树近似平衡的简单证明
下图是两颗红黑树,首先,如果将红色节点从红黑树中删除,那只包含黑色节点的红黑树的高度是多少呢?
红色节点删除之后,有些节点就没有父节点了,它们会直接拿这些节点的祖父节点(父节点的父节点)作为父节点,所以,之前的二叉树就变成了四叉树。而完全二叉树的高度小于等于log2n,所以,这里的四叉黑树的高度要低于完全二叉树,所以去掉红色节点“黑树”的高度也不会超过log2n。
同时,由于红黑树中的定义:红色节点不能相邻,因此,有一个红色节点,其上父节点和其下子节点(如果有子节点的话)一定是黑色节点,也就是说黑色节点将红色节点与不在同一层的其他红色几点隔离开了,而去掉红色红色节点“黑树”的高度不会超过log2n,那么假如红色节点后,最长路径也不会超过2log2n(假设隔一层就有个红色节点将原始的黑色节点分开),也就是说,红黑树的高度近似 2log2n。
![[外链图片转存失败(img-WN7AIVmf-1562332114157)(C:\Users\weidai\AppData\Local\Temp\1562329325509.png)]](https://img-blog.csdnimg.cn/20190705211525366.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lpbHVsdnhpbmc=,size_16,color_FFFFFF,t_70)
所以,红黑树的高度只比高度平衡的 AVL 树的高度(log2n)仅仅大了一倍,在性能上,下降得并不多,但却保留了平衡二叉树优点,比如插入,删除,查找等特性。
5:总结
线性表,插入时间复杂度为O(1),但是因为内部无法保证有序,所以查找需要O(n)的时间复杂度,而删除则取决于所用实现是链表还是数组,链表为O(1),数组为O(n)。比较社会数据量较小,查询量也极小的情况(<= 100)。
二叉查找树,插入,查找,删除等操作,均摊时间复杂度为O(logn),时间表现效率较高,但极端情况下,很可能出现退化成链表的情况,导致时间复杂度变为O(n)。
为了避免二叉查找树退化成链表,引入平衡二叉树,平衡二叉树定义:二叉树中任意一个节点的左右子树的高度相差不能大于 1,所以不会出现左边特别高,右边特别低,或者左边特别低,右边特别高的情况(也就是整棵树看起来更加平衡)。
虽然平衡二叉树避免退化成链表的情况,并且能够把查找时间控制在O(logn),但是为了符合平衡二叉树严格的条件,如果有频繁的插入,删除的操作,每次在更新的时候,需要进行一些操作来进行调整,比如左旋、右旋等操作,使其再次满足平衡二叉树的条件,导致维持树结构的时间消耗较多,复杂度退化。
为了解决平衡二叉树在维持树结构上时间消耗的问题,引入了红黑树,由于红黑树的条件限制,红黑树在插入、删除等操作,不会像平衡树那样,频繁着破坏红黑树的规则,所以不需要频繁着调整。红黑树的高度近似, log2n,所以它是近似平衡,插入、删除、找操作的时间复杂度都是 O(logn)。
备注:图片来自极客时间