目录
一、缓存使用方式
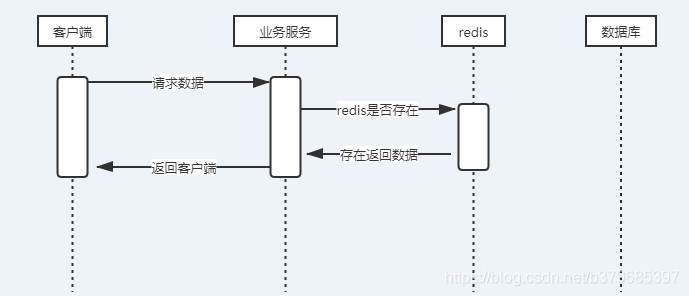
1、客户端请求业务系统
2、业务系统首先判断redis是否存在数据
3、如果数据存在redis则返回给业务系统
4、业务系统返回给客户端
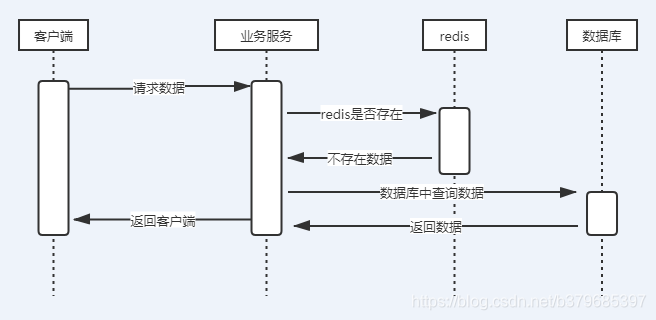
5、如果redis不存在数据,则业务服务区数据库中查询数据
6、然后将数据库中的数据返回给客户端
这个使用方法使我们在业务系统中再常见不过的方式。但是在高并发场景下,他们会存在什么样的问题呢?
二、缓存穿透问题
缓存穿透是指存在用户不断地访问缓存和数据库中都没有的数据,从而导致数据库压力过大,从而可能引发服务处理缓慢甚至数据库崩溃等问题。如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者。
解决方式
解决方法很多,一般有以下几种方式
1、接口层校验
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截,实现比较简单,但是只能拦截部分请求;
2、缓存空对象
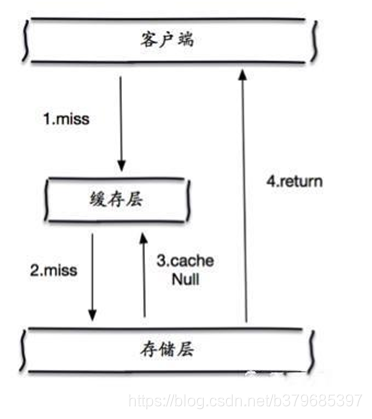
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。 这样可以防止攻击用户反复用同一个id暴力攻击,保护了后端数据源;
存在问题
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
3、布隆过滤器
布隆过滤器是一个bit向量或者bit,如果我们要映射一个值到布隆过滤器中,我们要使用多个不同的哈希函数生成多个哈希值,并将每个生成的哈希值指向的bit位设置为1。
可以看到,不同的词对应的bit位置可能相同,当词很多的情况时,可能大部分bit位置都是1,这时查询商品1可能对应的位置都为1,只能说明商品1一词可能存在,不是一定存在的。
布隆过滤器的巨大用处就是,能够迅速判断一个元素是否在一个集合中。命中的可能存在,但不命中的话肯定不存在!
如Gava给我们提供的布隆过滤器,以下程序实现了生成1000000数据进行初始化布隆过滤器,过滤器误判率为3%,然后故意取10000个不存在布隆过滤器里的值,输出误判数量为300.
public class BloomFilterTest {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.03);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
//故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
} 使用场景
- 网页爬虫对URL的去重,避免爬取相同的URL地址
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信)
- 缓存穿透,将所有可能存在的数据缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
优点
- 思路简单
- 保证一致性
- 性能强
缺点
- 代码复杂度增大
- 需要另外维护一个集合来存放缓存的Key
- 布隆过滤器不支持删值操作
- 初始化布隆过滤器和更新过滤器比较复杂
以下代码为redis中取不到值使用布隆过滤器方式判断数据是否存在数据库中,从而减少数据库访问IO。可以提供给大家参考。
三、缓存击穿问题
缓存击穿各位同学肯定经常和缓存穿透搞混,以为两个是同一个东西。因为我在面试中经常遇到这样的童鞋

缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方式
1、设置热点数据永远不过期。
嗯...场景有,但不科学。
2、互斥锁
当从缓存中没有取到数据时,那么为了防止大量数据打到数据库,我们可以通过加互斥锁的方式,进行限流。同一时间同一个数据只有一个请求可以进到数据库中拿到数据,当从数据库中拿到数据之后再将数据写回redis,其他阻塞的请求再从redis中取数据。以减少数据库压力。
互斥锁参考代码如下:
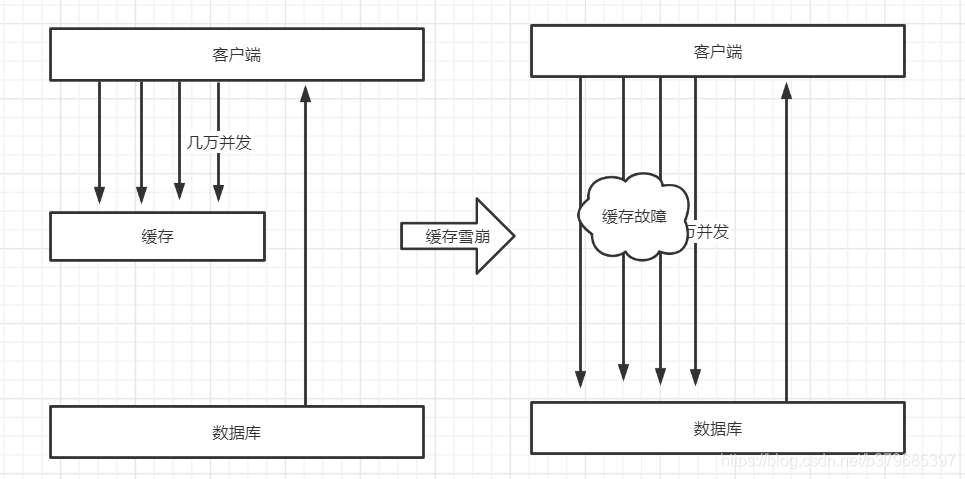
四、缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,或者缓存层故障不可用,而查询数据量巨大。请求直接绕过缓存而直接请求数据库,引起数据库压力过大甚至down机。
解决方案
1、redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。可以参考redis的高可用部署以及哨兵机制。这个后面我们会讲
2、过期时间分布均匀
将redis过期时间不要设置统一时间点,比如过期时间为1个小时,可以随机上下增加5分钟随机数,保证数据不在同一时间点过期。
五、几种故障对比
| 故障类型 | redis是否存在数据 | 数据库中是否存在数据 | key过期时间 |
| 缓存穿透 | 否 | 否 | 无 |
| 缓存击穿 | 否 | 是 | 无 |
| 缓存雪崩 | 否 | 是 | 存在大批量key同一时间过期或者缓存层不可用 |
按照故障类型以及表现方式列了个表格,希望可以方便大家的理解。