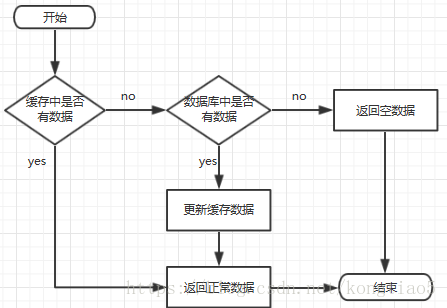
一般情况下缓存和DB访问的关系
缓存穿透
指查询一个一定不存在的数据,由于缓存中没有该查询对象(缓存始终无法命中对应的数据),这时会去数据库查询数据,如果数据库中也没有对应的数据也无法写入缓存,在这种情况下,每一次查询不存在数据的请求都将去查询数据库,这就是缓存穿透。
造成影响:
当在高并发的情况下,缓存穿透可能会拖慢数据库,进而拖慢整个系统,甚至宕机。
解决办法:
当在缓存中无法命中对应数据时,且访问数据库也没有查询到目标数据,这时向缓存中存入空结果。这样的情况下,每一次查询首先判断redis中是否有目标数据(即exist(String key)),key存在就直接返回缓存结果,即使缓存结果是空值。
缓存雪崩
当大量缓存在同一时间段内失效的时候,会在这段时间内引发大量数据库访问查询,给数据库带来较大的压力。
解决办法:
- 在数据库访问层面,加锁/队列式的穿行访问
- 分析系统缓存实际情况(包括用户使用场景等),设计分布较为均匀的失效时间。
- 数据预热,在能遇见的并发高峰来临前,提前均匀的、有计划的更新缓存数据,防止在并发高峰期出现缓存大量失效的情况。
- 设置业务热点数据永不过期,只做缓存更新操作
- 在分布式数据库的情况下,将热点数据均匀分布,分散缓存雪崩后带来的单个数据库访问压力
- 访问限流(最不推荐)
这里比较推荐通过使用 2 、3 、4 方法来预防解决缓存雪崩问题,加锁或者是队列式的访问控制,一定会带来性能的损耗,能提前避免的问题就尽量提前避免,最好不要等到意外发生了再做补救。
合理加锁
双重检测锁:
public User selectById(String id) {
User user = (User) hash.get(id);
if (null == user) {
synchronized (this) {
//这里多一次缓存的检查是关键
user = (User) hash.get(id);
if (null == user) {
user = //...查询数据库
hash.put("user", user);
}
}
}
return user;
}优点:当高并发,且缓存过期,又没有做热点数据预热的条件下,第一个线程访获得了锁对象,其他线程处于等待;在第一个线程查询数据库的时间内,大量线程挤压,当第一个线程的DB查询结果设置缓存后,其他挤压等待获得锁对象的线程依次拿到了锁,这时最关键的一步来了,再一次的检查缓存可以避免挤压的这些线程去做不必要的数据库访问。