重复子字符串
问题描述:判断一个字符串是否由一个子字符串重复多次构成
比如"abab"就是一个由子字符串"ab"重复构成的,下面介绍一下这个问题的几种解决思路:
1. 暴力解
假设字符串s的长度为n,那我们就穷举s所有可能字串s_sub,值得注意的是字串s_sub的长度m一定是n的因子且小于n/2,然后我们就可以开始穷举字串了~
复杂度分析:
- 时间复杂度: O ( n 2 ) O(n^2) O(n2), 穷举所有长度时间复杂度为 O ( n ) O(n) O(n), 遍历
s字符串时间复杂度为 O ( n ) O(n) O(n) - 空间复杂度: O ( 1 ) O(1) O(1)
2. 双倍字符串
这是我感觉最神奇的解法,而且高效!
我们首先将两个s拼接在一起得到一个新的字符串,然后去掉首尾的两个字符,再判断s是否为该新串的字串即可!
怎么理解?我们不妨假设s是一个由重复字串构成的串(如下图), 去掉首位字符后s仍然会是新串的字串!
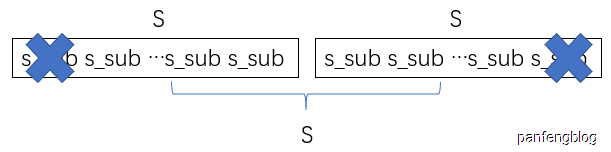
但是值得注意的是,我们只是说明了必要条件(s是是由重复字串构成 → s会具有上述性质),但是我们使用该算法时需要用到的是充分条件(s具有上述性质 → s是是由重复字串构成)
事实上充分条件是满足的,可以使用数学严谨的推导,可以参考leetcode官方解答
使用上述性质,我们就能轻松秒杀这道题了
#include<iostream>
#include<string>
using namespace std;
bool repeatedSubstringPattern(string s) {
return (s + s).find(s, 1) != s.size();
}
int main() {
ios::sync_with_stdio(false);
string s("abab");
cout << repeatedSubstringPattern(s) << endl;
return 0;
}
3. KMP算法
直接去阅读代码,是永远无法学会KMP算法的,读者甚至无法理解KMP算法关键代码中的任意一行
KMP算法有着良好的理论时间复杂度上限,但是大多数语言自带的字符串查找函数并不是用KMP算法,而是使用普通暴力匹配算法盒优化的BM算法,因为这些算法具有更优秀的平均时间复杂度。
我感觉这篇KMP算法讲的很通俗易懂,赞!