基于深度学习的图像重照明实践学习笔记_2
项目摘要
项目任务是什么?
One-to-one Relighting:目标是将输入图像从一组预定义
的照明设置(即北,6500K)转换为另一组预定义的照明
设置(东,4500K)。图像的分辨率为1024×1024,包括
输入和输出,仅提供输入图像。
解决这个任务的基本模型架构是怎样的?
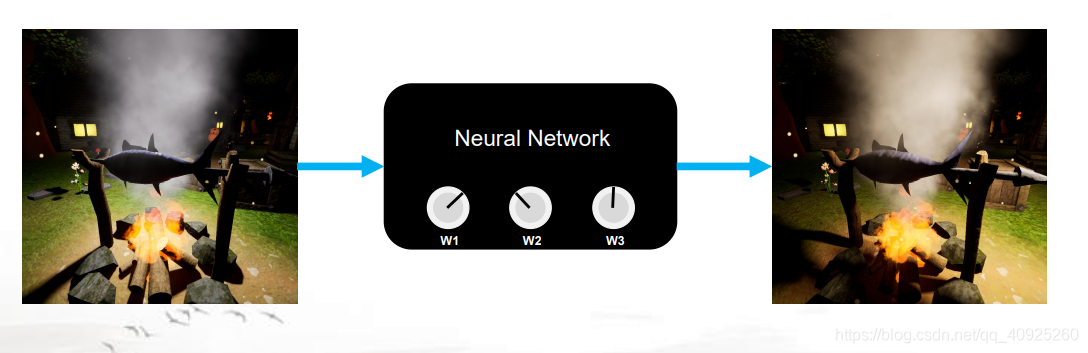
大体上来说,将输入图片放入我们的“黑盒”中从而得到输出图片,而这个“黑盒”就是我们所使用的模型(Neural Network),"黑盒"中则有着大量的参数需要我们去通过输入输出进行调整(W1,W2等),这也就是我们所常说的模型训练过程。
至于这里我们所说的“黑盒”内部的具体细节,也将在后面的课程中进行详细的讲述。
使用什么数据训练模型?
本次项目我们使用的数据为VIDIT(Virtual Image Dataset for Illumination Transfer),是一种专门进行光源变换训练的数据集。
- 其包含390个不同的场景(这些场景都是来源于虚幻引擎),每个场景采集40张图片(即40种不同的光照设置)。
- 40中不同的关照设置由5种不同的色温和8个光照方向组合而来(就该任务而言,采用点光源的图像更容易实现一些)。
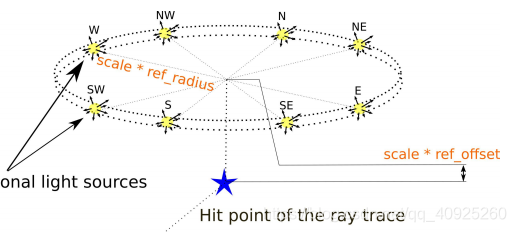
- 该数据集在GitHub上是开源的。
- 其训练集有300张,验证集与测试集都为45张,而项目的最终评测效果也就是看模型在这45张测试集上的测试效果(测试集我们自身是拿不到ground truth的)。
模型如何设计?
冠军模型:Wavelet Decomposed RelightNet (WDRN)
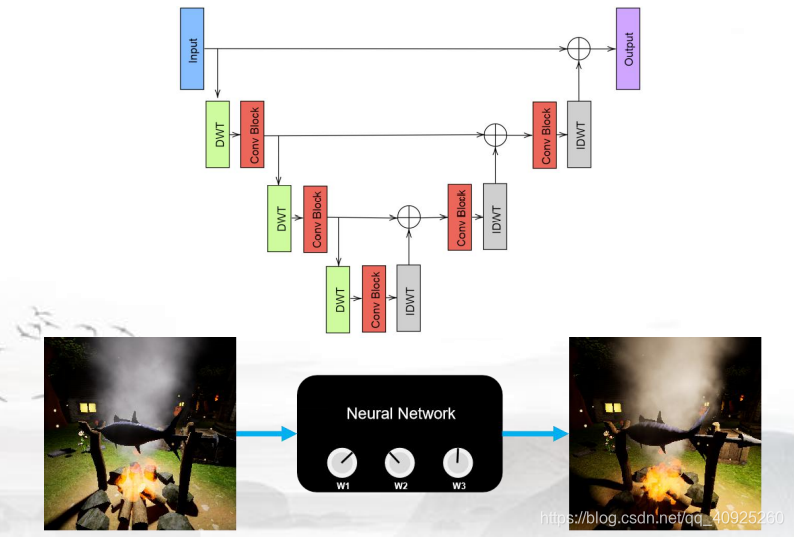
注:IDWT为DWT的逆变换
(网络的具体内部解说会在第四次课程中结合论文详细说明)
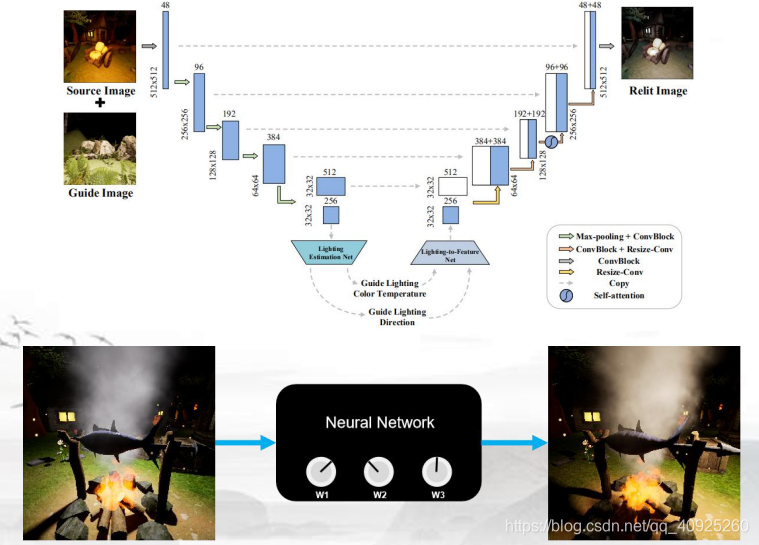
经典模型:Norm-Relighting-U-Net (NRUNet)
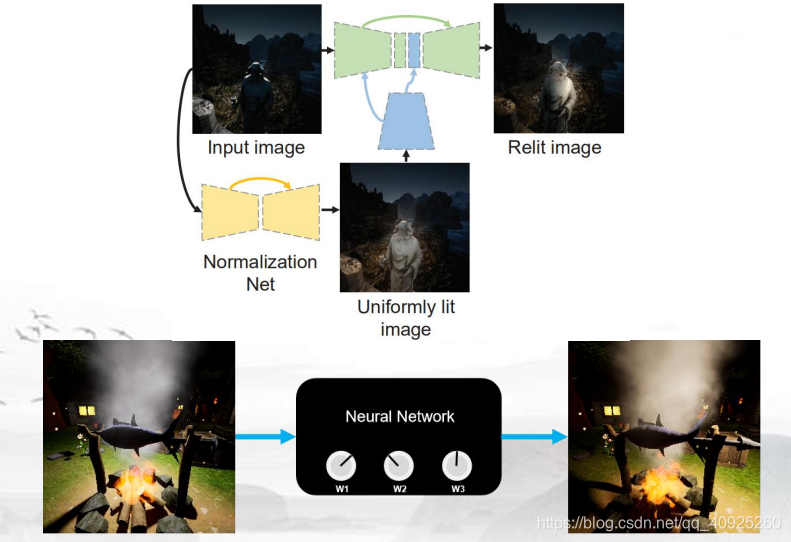
梯形可以理解为神经网络的降维或者升维。
Deep Residual Network for Image Relighting (DRNIR)
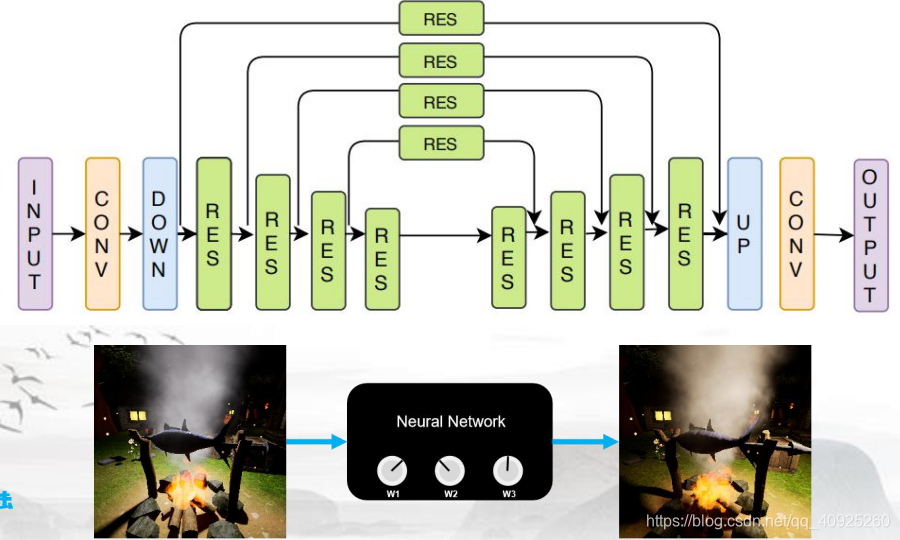
Self-Attention AutoEncoder (SA-AE)
该网络属于赛道三的网络,属于Any-to-any类型
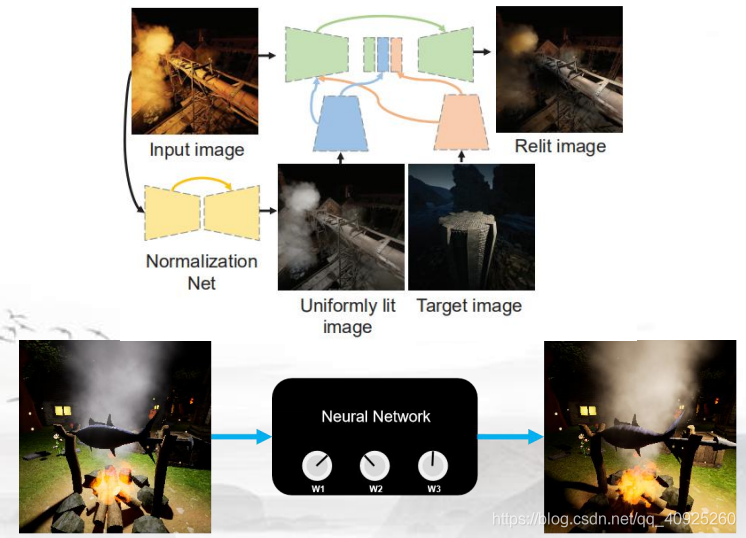
Norm-Relighting-U-Net (NRUNet)
该网络同样属于赛道三的网络,属于Any-to-any类型
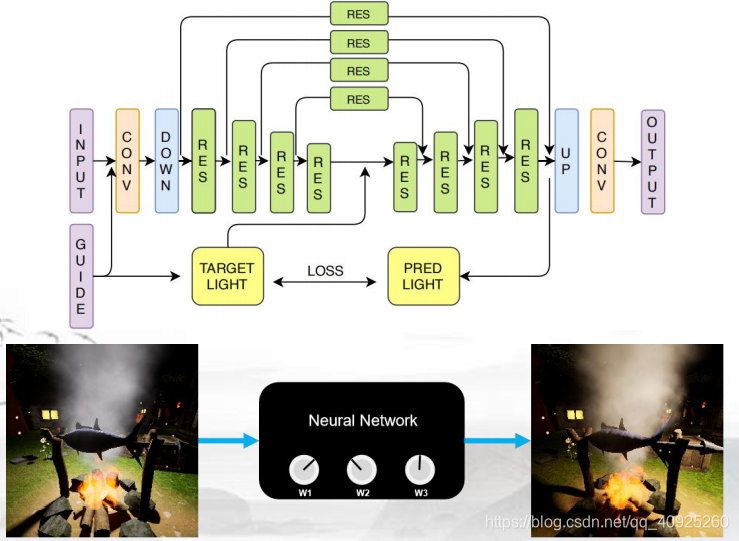
Deep Residual Network for Image Relighting (DRNIR)
该网络同样属于赛道三的网络,属于Any-to-any类型
模型效果如何评价?
就One-to-one问题而言
在刷榜期间使用的是PSNR和SSIM指标进行评判,而在评判冠亚军时所采用的是MPS(Mean Perceptual Score)指标,即主观评价指标——人为进行打分。再将其标准化SSIM和LPIPS得分的平均。
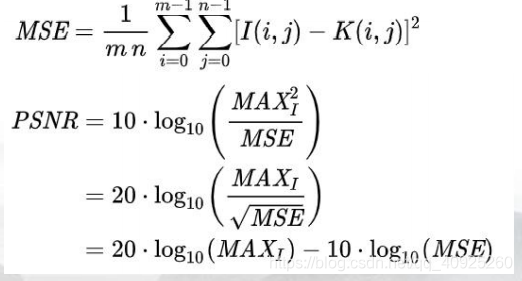
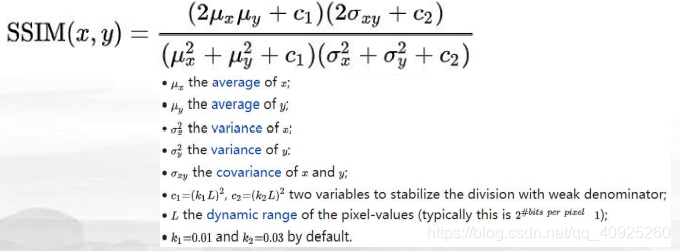


(上述值都应该越大越好)
相关论文推荐:The Unreasonable Effectiveness of Deep Features as a Perceptual Metric

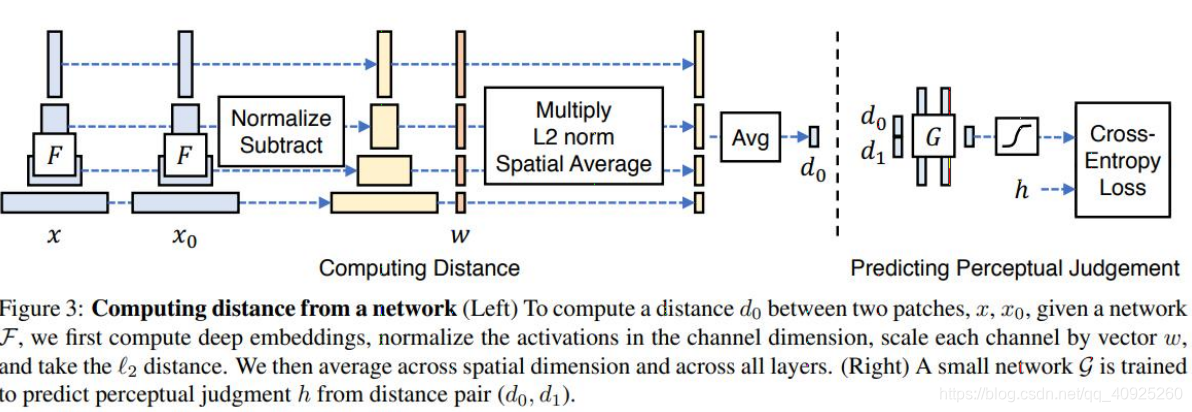
网络核心为获取不同层级的特征,相同层级的特征做减法最后计算距离。
其他一些问题
项目代码如何写?
对初学者而言,强烈建议先抄写官方代码。
项目有实际应用场景吗?
-
三维人脸建模

-
照片补光

-
将真实建筑物3D化并改变光影效果
更多相关学习资源获取

第二次课程直播回放链接:https://www.bilibili.com/video/BV1Ch4112734