需求:
统计各区域热门商品Top3
- 1、一共有3张表:1张用户行为表,1张城市表,1张产品表。
- 2、地区 商品名称 点击次数 城市备注(计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示。)
表一:城市表
1 北京 华北
2 上海 华东
3 深圳 华南
4 广州 华南
5 武汉 华中
6 南京 华东
7 天津 华北
8 成都 西南
9 哈尔滨 东北
10 大连 东北
11 沈阳 东北
12 西安 西北
13 长沙 华中
14 重庆 西南
15 济南 华东
16 石家庄 华北
17 银川 西北
18 杭州 华东
19 保定 华北
20 福州 华南
21 贵阳 西南
22 青岛 华东
23 苏州 华东
24 郑州 华北
25 无锡 华东
26 厦门 华南
表2:用户表

表3:商品表

import org.apache.spark.sql.{
SaveMode, SparkSession}
/**
* @ClassName: Hotgoods
* @Description: 统计各区域热门商品Top3
* 1、一共有3张表:1张用户行为表,1张城市表,1张产品表。
* 2、地区 商品名称 点击次数 城市备注(计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示。)
* @Author: kele
* @Date: 2021/2/2 16:30
**/
object Hotgoods {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("goods").master("local[4]").getOrCreate()
import org.apache.spark.sql.functions._
spark.udf.register("ACity",udaf(new AnalyzeCity))
//1、获取用户信息,只获取用户有点击的信息,完成后创建一张表
spark.read.option("sep","\t")
.option("inferSchema","true")
.csv("E:\\data\\user_visit_action.txt")
.toDF("date","user_id","session_id","page_id","action_time","search_keyword","click_category_id","click_product_id","order_category_ids","order_product_ids","pay_category_ids","pay_product_ids","city_id")
.filter("click_category_id !=-1 ")
.createOrReplaceTempView("user_info")
//2、获取商品信息
spark.read.option("sep","\t")
.option("interSchema","true")
.csv("E:\\data\\product_info.txt")
.toDF("product_id","product_name","extend_info")
.createOrReplaceTempView("product_info")
//3、获取地区信息
spark.read.option("sep","\t")
.option("interSchema","true")
.csv("E:\\data\\city_info.txt")
.toDF("city_id","city_name","area")
.createOrReplaceTempView("city_info")
spark.sql(
"""
|select c.area area,b.product_name product_name,c.city_name city_name
|from user_info as a join product_info as b
|on a.click_product_id = b.product_id
|join city_info as c
|on a.city_id=c.city_id
""".stripMargin).createOrReplaceTempView("InintForm")
//分组之后,查看城市及对应的次数没有相关API,所以自定义UDAF函数
spark.sql(
"""
|select area,product_name,count(1) num,ACity(city_name) cityinfo
|from InintForm
|group by area,product_name
""".stripMargin).createOrReplaceTempView("InintForm2")
spark.sql(
"""
|select t1.area,t1.product_name,t1.num,t1.cityinfo from(
|select area,product_name,num,cityinfo,rank() over(partition by area order by num desc) rk
|from InintForm2)t1
|where t1.rk<=3
""".stripMargin).repartition(1).write.mode(SaveMode.Overwrite).option("header","true").csv("E:/result")
}
}
自定义UDAF函数
查看城市及对应的点击次数
import org.apache.spark.sql.{
Encoder, Encoders}
import org.apache.spark.sql.expressions.Aggregator
import scala.collection.mutable
/**
* @ClassName: StaticCity
* @Description:
* @Author: kele
* @Date: 2021/2/2 18:32
**/
/** 中间变量的类型
* 中间变量需要两个 1、统计总数目(用来作为分母)
* 2、每个城市的名称及对应的点击数(每个城市的点击数作为分子)
*/
case class bufferValue(var count:Int,var city_info:mutable.Map[String,Int])
class AnalyzeCity extends Aggregator[String,bufferValue,String]{
/**
* 初始化buffer的值
* @return bufferValue类型
*/
override def zero: bufferValue = bufferValue(0,mutable.Map[String,Int]())
/**
* 单个task中的计算过程
* 统计总的count的个数,统计每个城市的city点击次数
* @param b
* @param a
* @return
*/
override def reduce(buffer: bufferValue, city: String): bufferValue = {
/**
* 如果city在map中存在,则累计,没有则添加到map中
*/
if(buffer.city_info.contains(city)){
val city_num = buffer.city_info.get(city).get+1
buffer.city_info.put(city,city_num)
}else{
buffer.city_info.put(city,1)
}
buffer.count = buffer.count +1
buffer
}
/**
*统计分区间的
* @param b1
* @param b2
* @return
*/
override def merge(b1: bufferValue, b2: bufferValue): bufferValue = {
val buffer = b1.city_info.toList:::b2.city_info.toList
val buff = buffer.groupBy(_._1).map(x=>{
val num = x._2.map(_._2).sum
(x._1,num)
})
b1.count = b1.count + b2.count
b1.city_info = mutable.Map[String,Int]().++=(buff)
b1
}
/**
* 统计最终结果
*注意使用格式
* @param reduction
* @return
*/
override def finish(reduction: bufferValue): String = {
val take2 = reduction.city_info.map(x=>{
val percent = x._2.toDouble/reduction.count*100
(x._1,percent)
}).toList.sortBy(_._2).reverse.take(2)
val other = 100 - take2.map(_._2).sum
val first2 = take2.map(x=>s"${x._1}:${x._2.formatted("%.3f")}%")
s"${first2.mkString(",")},other:${other}%"
}
override def bufferEncoder: Encoder[bufferValue] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
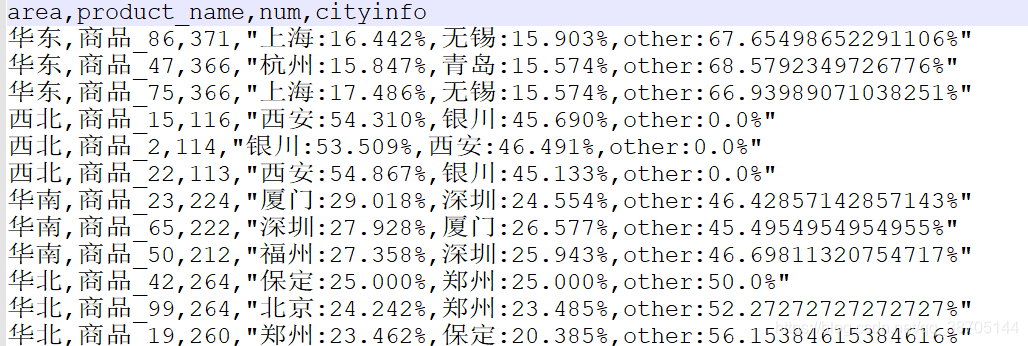
结果: