论文题目:《Rich feature hierarchies for accurate object detection and semantic segmentation
》
论文地址:R-CNN
1. 概述
R-CNN是two-stage目标检测算法的开篇之作,也是将深度学习引入目标检测的开山之作。
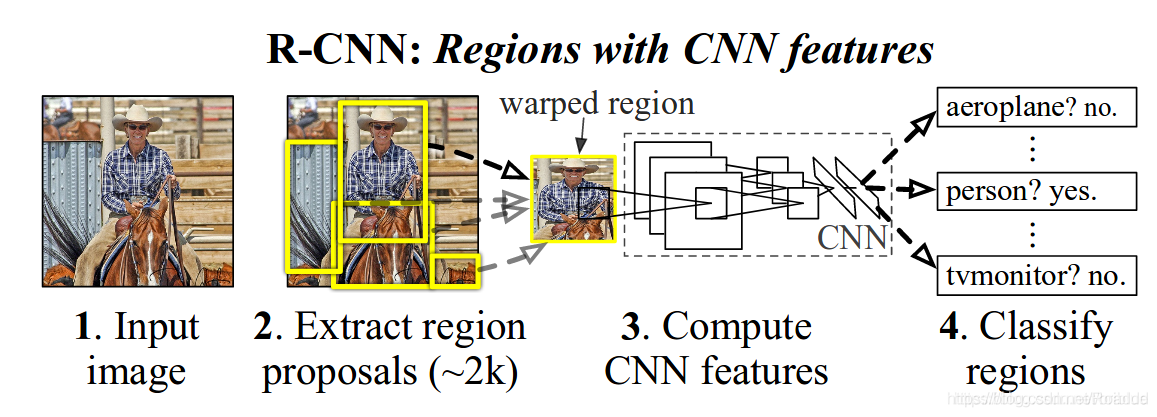
如上图所示,R-CNN算法大致可以分为4个步骤:
1)使用selective Search算法在图像中确定约2000个候选区域(region proposal)。
2)对于每个候选框内图像块,使用CNN提取特征(在送入CNN之前需要将所有候选框裁剪到相同大小(227*227),因为FC层需要固定输入图像的尺寸)。
3)对于候选框中提取出的特征,使用SVM判别是否属于某一特定类。
4)使用回归器精细修正候选框的位置。
2. 候选区域(region proposal)
2.1. 选取候选区域
R-CNN使用了Selective Search算法从一张图像上生成约2000个候选区域。Selective Search算法流程如下:
step1:生成原始分割区域R={r1,r2,…,rn}
step2:初始化相似度集合S={}
step3:计算两两相邻区域之间的相似度,将其添加到相似度集合S中。
while S ≠ {}
step4:从相似度集合S中找出相似度最大的两个区域ri和rj,将其合并成为一个区域rt,并将其添加到R中。
step5:从相似度集合S中除去原先与ri和rj相邻区域之间计算的相似度。
step6:重新计算rt与其相邻区域(原先与ri或rj相邻的区域)的相似度,将其结果添加到相似度集合S中。
-区域相似度主要是考虑颜色、纹理、尺寸和交叠四个方面。
2.2. 缩放候选区域
因为CNN的全连接层对输入图像的大小有限制,所以在将候选区域输入CNN之前,要将候选区域进行固定尺寸(227*227)的缩放。缩放分为两大类(该部分在原文附录A):
- 各向同性缩放(长宽放缩相同的倍数):
考虑到图片扭曲会对分类精度有影响,提出各向同性缩放,有如下两种方式:
1) 将region proposal的边界向外延伸,使图片成正方形,然后裁剪。如果延伸到原来图片的外界,则用region proposal中的颜色补齐。图(B)
2)先将region proposal中的图片裁剪出来,然后用固定的背景颜色填充成正方形(背景颜色是region proposal的像素颜色均值)。图(C) - 各向异性缩放(长宽放缩的倍数不同):
不管图片长宽比例,不管是否扭曲,只管缩放到cnn要求的比例(227*227)。图(D)

在放缩之前,作者考虑,在region proposal周围补额外的原始图片像素(pad p)。上图中,第一层p=0,第二层p=16。最后试验发现,采用各向异性缩放并且p=16的时候效果最好。
3. 特征提取
采用AlexNet进行对每个候选区域提取4096维的特征向量,即把一个227×227大小的图像,通过五个卷积层和两个全连接层进行前向传播,最终得到一个4096维的特征向量。为了计算候选区域的特征,我们首先要对图像进行转换,使得它符合CNN的输入(架构中的CNN只能接受固定大小:277×277)。这个变换有很多办法,我们使用了最简单的一种。无论候选区域是什么尺寸和宽高比,我们都把候选框变形成想要的尺寸。具体的,变形之前,我们现在候选框周围加上16的padding,再进行各向异性缩放。
4. 测试
5. 训练
缺点
1)计算量大:每个候选区域都需要通过CNN计算特征。
2)质量不够好:Selective Search提取的区域质量不够好。
3)训练耗时长:特征提取,SVM分类器是分模块独立训练,没有联合起来系统性优化。