1 ElasticSearch简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎。是使用Java开发的。
1.1 使用场景
-
为用户提供关键字查询的全文搜索功能。
-
实现企业海量数据的处理分析。ELK框架(ElasticSearch、Logstash、Kibana)
-
作为OLAP数据库,对数据进行统计分析。
OLTP:联机事务处理,是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,如银行交易。
OLAP:联机分析处理,是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供只管易懂的查询结果。
1.2 几种数据库比较
| redis | mysql | elasticsearch | hbase | hadoop/hive | |
|---|---|---|---|---|---|
| 容量容量扩展 | 低 | 中 | 较大 | 海量 | 海量 |
| 查询时效性 | 极高 | 较高(需要索引优化) | 较高 | 较高(rowkey方式) 较低(scan方式) | 低 |
| 查询灵活性 | 较差 k-v模式 | 非常好,支持sql | 较好,关联查询较弱,但是可以全文检索,DSL语言可以处理过滤、匹配、排序、聚合等各种操作 | 较差,主要靠rowkey, scan的话性能不行,或者安装phoenix插件来实现sql及二级索引 | 非常好,支持sql |
| 写入速度 | 极快 | 中等 | 较快 | 较快 | 慢 |
| 一致性、事务 | 弱 | 强 | 弱 | 弱 | 弱 |
1.3 elasticsearch特点
①分片&集群
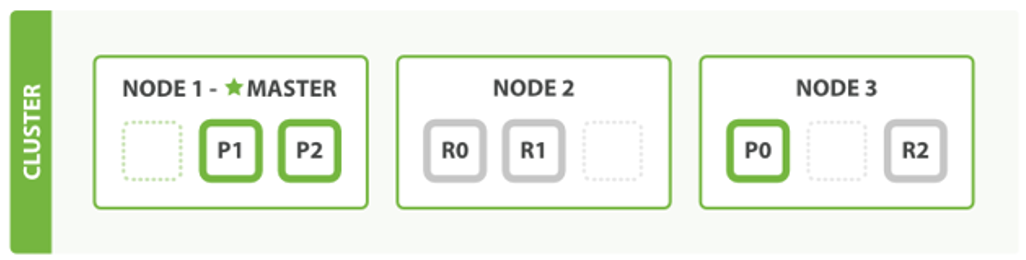
上图es将数据分成3个shard切片,有两个副本。就算一台node节点挂掉了,也能够凑出来一份完整的数据。
随着数据的不断增加,集群可以增加多个分片,把多个分片放在多个机器上,达到负载均衡和横向扩展。
②es的读数据过程
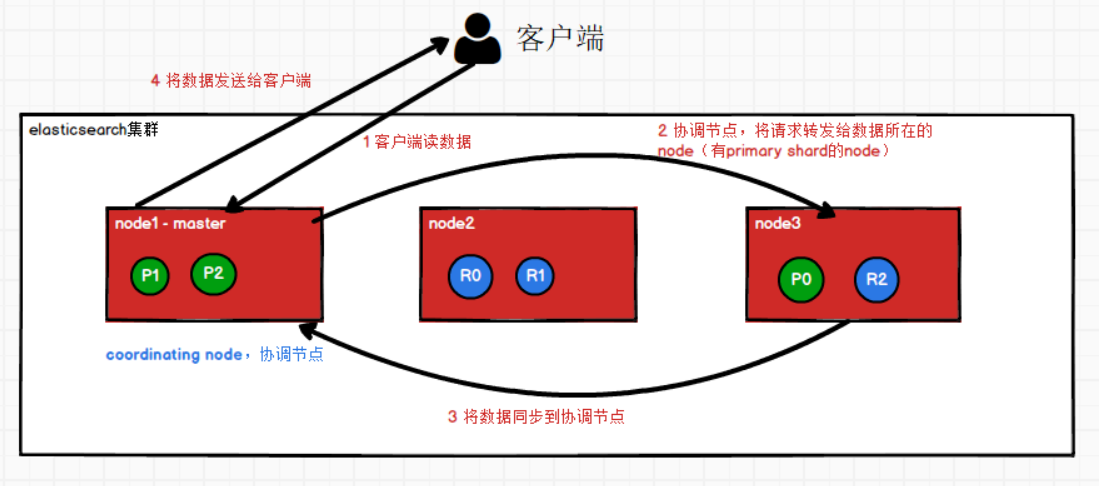
- 客户端发送请求给任意一个node,这个node成为coordinating node
- coordinating node对doc id进行哈希路由,将请求转发到对应的node(也就是primary shard所在的节点),此时会使用round-robin轮询算法,在primary shard以及其所有的副本中随机选择一个,让读请求负载均衡。
- 接收到请求的node,将数据document同步到coordinating node
- coordinating node返回document给客户端
③es写数据过程
- 客户端发送写请求给任意一个node,这个node成为coordinating node
- coordinating node对document进行路由,将请求转发给对应的node(有primary shard所在的节点)
- 实际的node(primary shard)处理写数据请求,然后将写完的数据同步给replication node。(同步数据)
- coordinating node发现,写数据过程primary node 和replication node数据都同步完成后。
- 将写数据成功发送给客户端。
④倒排索引
ES所有数据都是默认进行索引的。全文搜索引擎主流的索引技术:倒排索引。
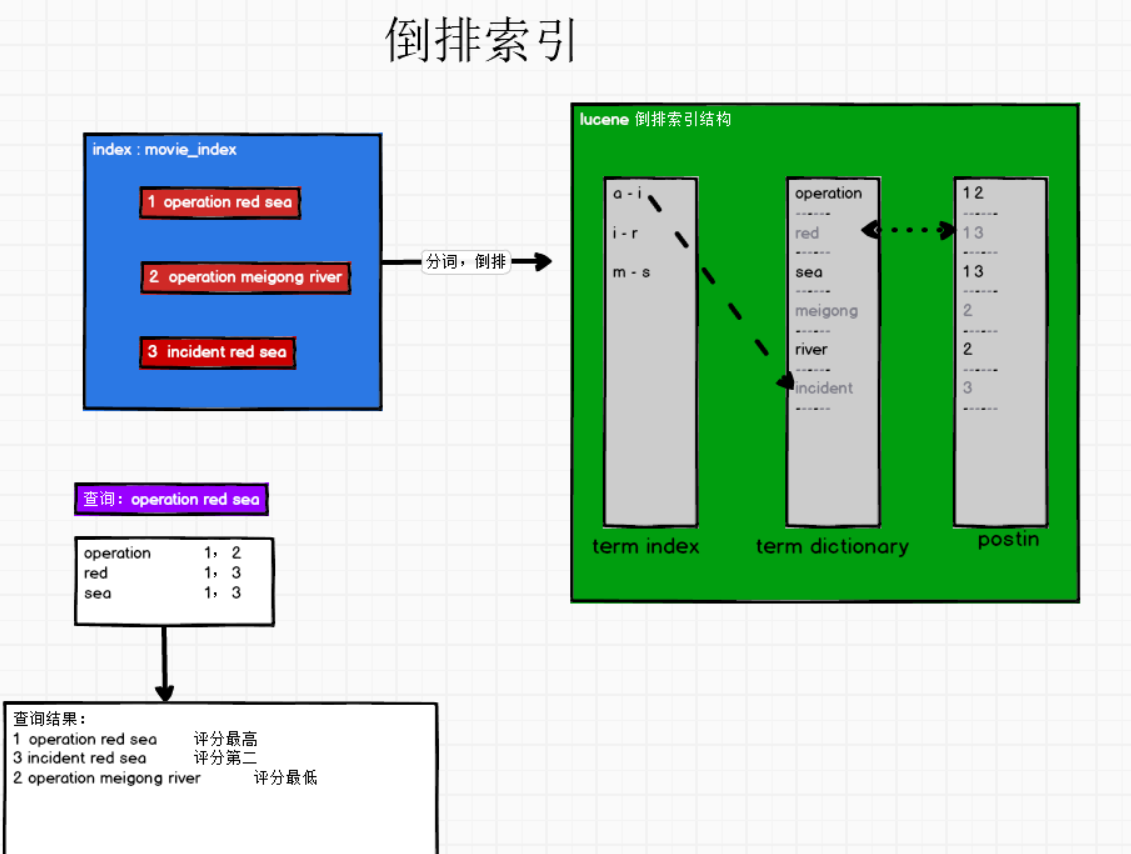
什么是倒排索引?
- 传统的数据库:记录-单词
- 倒排索引:单词:记录
通过分词,然后记录单词在什么位置 单词在什么位置,对每个分词打分,然后根据评分倒序
2 ElasticSearch安装配置
本次安装的版本是elasticsearch-6.6.0
Elasticsearch官网:
https://www.elastic.co/products/elasticsearch
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-6-0
2.1 安装配置步骤
步骤1:上传安装包,将elasticsearch-6.6.0.tar.gz上传到/opt/software/目录下
步骤2:解压ES到/opt/module目录下
[atguigu@hadoop102 bin]$ tar -zxvf elasticsearch-6.6.0.tar.gz -C /opt/module/
步骤3:重命名elasticsearch
[atguigu@hadoop202 module]$ mv elasticsearch-6.6.0/ elasticsearch
步骤4:修改elasticsearch配置文件
elasticsearch.yml
注意yml文件key:后面要有一个空格!!!
# 集群名称,同一个集群名称需要相同
cluster.name: my-es
# 单个节点名称
node.name: node-1
# 关闭bootstrap自检程序
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 网络部分,改为当前的ip地址,端口号默认9200即可
network.host: 192.168.255.102
# 自发现配置:新节点向集群报道的主机名
discovery.zen.ping.unicast.hosts: ["hadoop102", "hadoop103"]
步骤5:Java虚拟机优化(非生产环境)
elasticsearch运行在Java虚拟机中,虚拟机默认启动内存1G内存。但是装在个人PC机,实际用不了1个G。所以可以改小一点内存。但是实际生产环境一般128G内存是标配。
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
#-Xms1g
-Xms512m
-Xmx512m
#-Xmx1g
步骤6:分发elasticsearch
[atguigu@hadoop202 module]$ xsync elasticsearch/
步骤7:修改hadoop103、hadoop104的elasticsearch.yml的配置
node.name: node-2
network.host: 192.168.255.103
node.name: node-3
network.host: 192.168.255.104
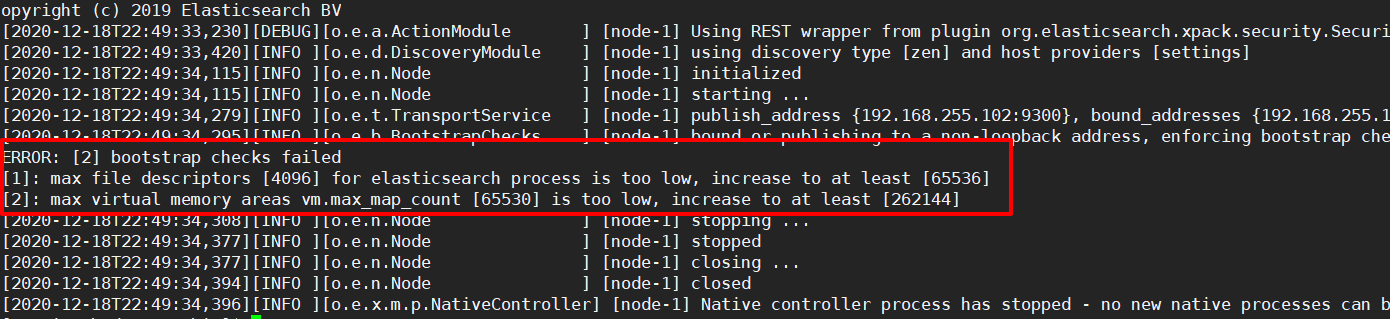
步骤8:单台启动测试,会报错
这是因为elasticsearch是单机访问模式,就是只能自己访问自己。但是我们已经设置成允许应用服务器通过网络方式访问,而且生产环境也是这种方式。
这时候elasticsearch会嫌弃单机版的低端配置而报错!!!无法启动。需要修改服务器的一些限制,支持更多并发。
[atguigu@hadoop102 bin]$ ./elasticsearch
-
错误1:[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
原因:系统允许ElasticSearch打开的最大文件数需要改成65536
解决方法:
[atguigu@hadoop102 bin]$ sudo vim /etc/security/limits.conf添加内容:(注意:“*” 不要省略掉)
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 65536分发文件:
[atguigu@hadoop102 bin]$ sudo /home/atguigu/bin/xsync /etc/security/limits.conf -
错误2:[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
原因:一个进程可以拥有的虚拟内存区域的数量
解决方法:
[atguigu@hadoop102 bin]$ sudo vim /etc/sysctl.conf在文件最后添加:
vm.max_map_count=262144分发文件:
[atguigu@hadoop102 bin]$ sudo /home/atguigu/bin/xsync /etc/sysctl.conf
步骤9:重启Linux机器,使配置生效
2.2 启动elasticsearch
①单台启动测试
单独启动elasticsearch
ES天然就是集群状态,就算是只有一个节点,也会当做集群处理,
默认节点name=主机名,cluster_name=elasticsearch
[atguigu@hadoop102 bin]$ ./elasticsearch
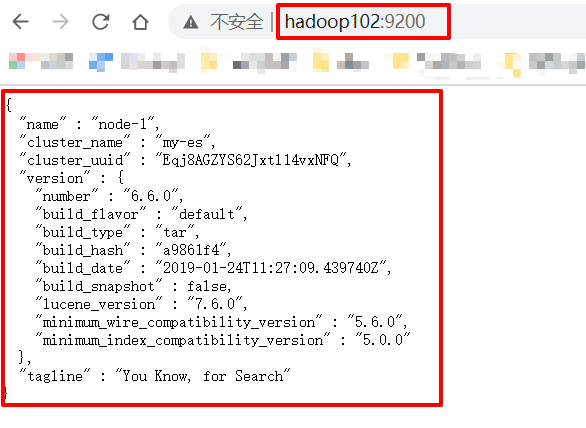
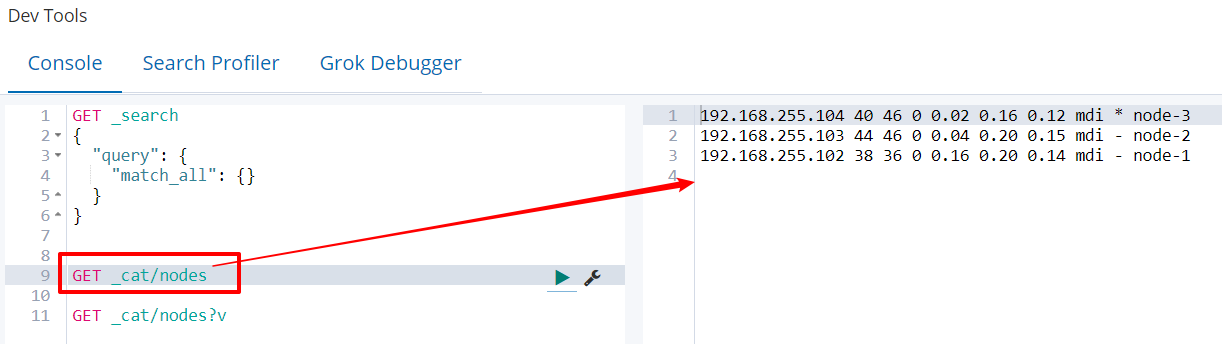
测试方式1:http://hadoop102:9200/_cat/nodes?v

测试方法2:http://hadoop102:9200/
②集群启动脚本
profile.d下不用source /etc/profile也可以~
#!/bin/bash
es_home=/opt/module/elasticsearch
case $1 in
"start") {
for i in hadoop102 hadoop103 hadoop104;
do
echo "=============== $i starting ES ==============="
ssh $i "source /etc/profile;${es_home}/bin/elasticsearch > /dev/null 2>&1 &"
done
};;
"stop") {
for i in hadoop102 hadoop103 hadoop104;
do
echo "=============== $i stoping ES ==============="
ssh $i "ps -ef | grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
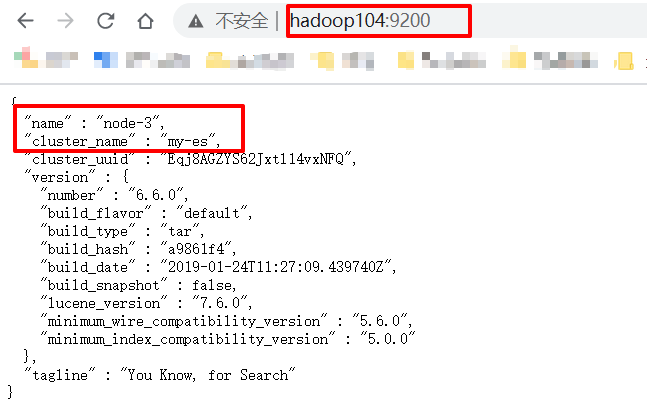
测试方式1:http://hadoop102:9200/_cat/nodes?v

测试方式2:http://hadoop104:9200/
3 Kibana安装配置
3.1 安装配置步骤
步骤1:上传安装包到/opt/software
步骤2:解压kibana-6.6.0-linux-x86_64到/opt/module下
[atguigu@hadoop102 module]$ tar -zxvf kibana-6.6.0-linux-x86_64.tar.gz -C /opt/module/
步骤3:重命名kibana
[atguigu@hadoop102 module]$ mv kibana-6.6.0-linux-x86_64/ kibana
步骤4:修改kibana配置文件
# 授权远程访问
#server.host: "localhost"
server.host: "0.0.0.0"
# 指定ElasticSearch地址,可以指定多个
#elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.hosts: ["http://hadoop102:9200","http://hadoop103:9200","http://hadoop104:9200"]
步骤5:启动、测试
[atguigu@hadoop102 kibana]$ bin/kibana
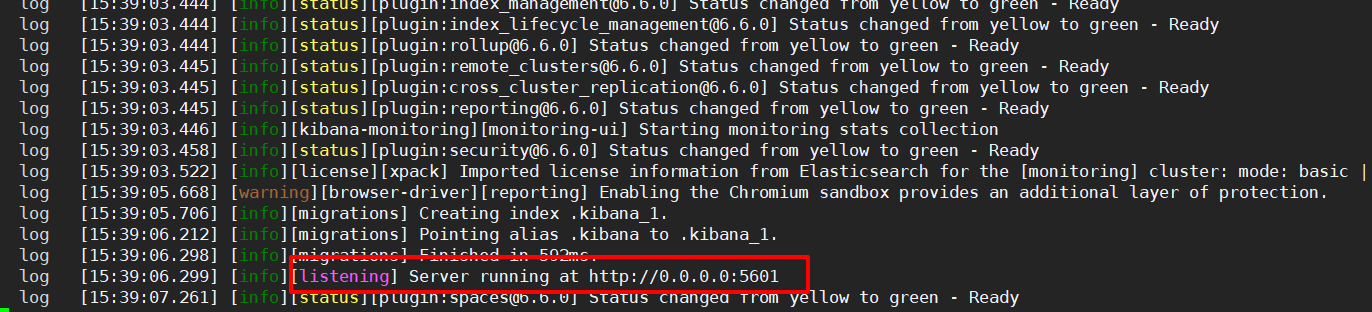
步骤6:访问Web监听页面http://hadoop102:5601/
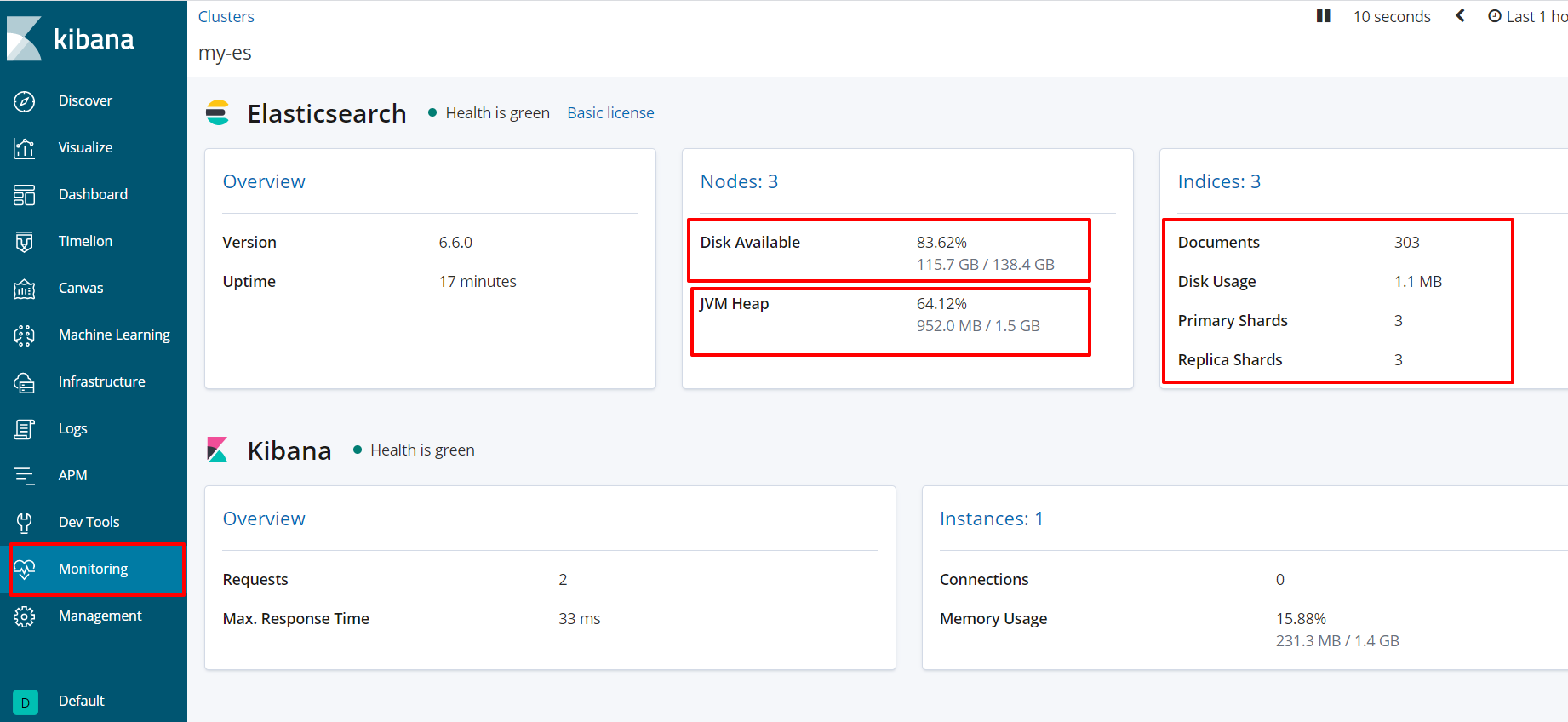
kibana如果出现.kibana的索引red问题,导致kibana起不来!解决方式:
- 删除.kibana_1这个索引:正常情况下删除索引是DELETE /.kibana_1
- 如果kibana起不来:删除操作为curl -XDELETE http://hadoop102:9200/.kibana*
3.2 启动脚本
首先创建文件夹
[atguigu@hadoop102 kibana]$ mkdir -p /opt/module/kibana/logs
#!/bin/bash
es_home=/opt/module/elasticsearch
kibana_home=/opt/module/kibana
case $1 in
"start") {
for i in hadoop102 hadoop103 hadoop104;
do
echo "=============== $i starting ES ==============="
ssh $i "source /etc/profile;${es_home}/bin/elasticsearch > /dev/null 2>&1 &"
done
echo "=============== starting kibana =============="
nohup ${kibana_home}/bin/kibana >${kibana_home}/logs/kibana.log 2>&1 &
};;
"stop") {
echo "=============== stoping kibana ==============="
ps -ef|grep ${kibana_home} |grep -v grep|awk '{print $2}'|xargs kill
for i in hadoop102 hadoop103 hadoop104;
do
echo "=============== $i stoping ES ==============="
ssh $i "ps -ef | grep $es_home |grep -v grep|awk '{print \$2}'|xargs kill" >/dev/null 2>&1
done
};;
esac
3.3 Kibana console
4 ElasticSearch result API(DSL)
4.1 es名词概念
| cluster | 整个elasticsearch默认就是集群状态,整个集群是一份完整、互备的数据 |
| node | 集群中的一个节点,一般指一个进程就是一个node |
| shard | 分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。(7.0默认1片) |
| index | 索引,相当于table |
| type | 区,对表的数据再进行划分。(6.0只允许建一个,7.0废弃) |
| document | 类似于面向对象中的object、rdbms的row |
| field | 字段、属性 |
文档document:相当于一条一条的 数据!
索引index里面是一条一条document。
6.x版本中:index相当于database,type相当于table,document相当于一条条数据,field是字段。
7.x版本中:index就相当于table了,废弃了type。
6.x版本中默认5个分片,1个副本
7.x版本中默认1个分片,1个副本
4.2 es中的数据结构
public class Movie {
String id;
String name;
Double doubanScore;
List<Actor> actorList;
}
public class Actor{
String id;
String name;
}
上面的两个对象如果放在关系型数据库保存,会被拆成2张表,但是在elasticsearch是用一个json来表示一个document文档。
{
"id":"1",
"name":"operation red sea",
"doubanScore":"8.5",
"actorList":[
{
"id":"1","name":"zhangyi"},
{
"id":"2","name":"haiqing"},
{
"id":"3","name":"zhanghanyu"}
]
}

4.3 服务状态查询
其实在kibana中的get,可以在hadoop102:9200后面加上,比如查询集群健康状态:
http://hadoop102:9200/_cat/health?v
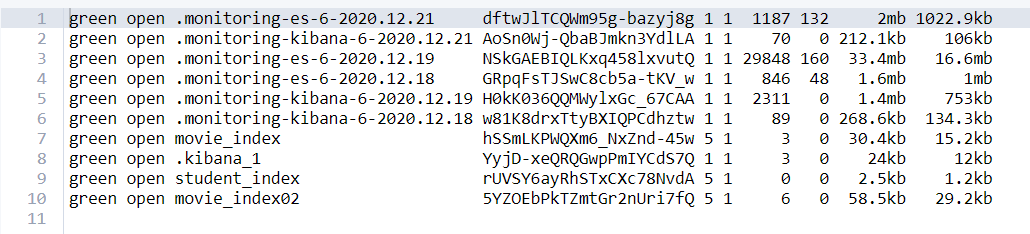
①查看各个索引的状态
GET _cat/indices
②给索引添加头信息
GET _cat/indices?v
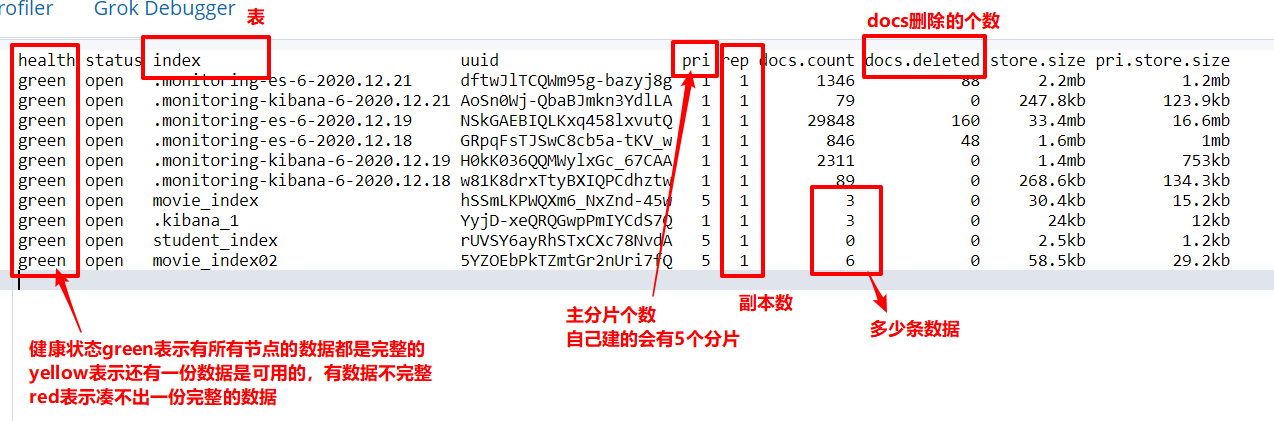
- health:索引的健康状态;
- status:是否可用
- index:索引名,也就是表名;
- pri:索引主分片数量;
- rep:索引复制分片数量;
- store.size:索引主分片+复制分片,分片总占用空间;
- pri+store.size:索引总占用空间,不计算复制分片占用空间。
③服务整体状态查询
GET _cat/health?v

- cluster:集群名称
- status:集群健康状态,green所有主分片都正常而且每个主分片都至少有一个副本,集群状态;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整,主片副本都在单点;red代表部分主分片不可用,可能已经丢失数据。
- node.total:表示在线的节点总数
- node.data:表示在新的数据节点数量
- shards:表示存活的分片数量
- pri:表示存活的主分片数量,正常情况下 shards的数量是pri的两倍
- relo,表示迁移中的分片数量,正常情况下为0
- init,表示初始化中的分片数量,正常情况下为0
- unassign,未分配的分片,正常情况下为0
- pending_tasks,准备中的任务,任务指迁移分片等,正常情况下为0
- max_task_wait_time,任务的最长等待时间
- active_shards_percent,正常分片百分比,正常情况为100%
④查询各个节点状态
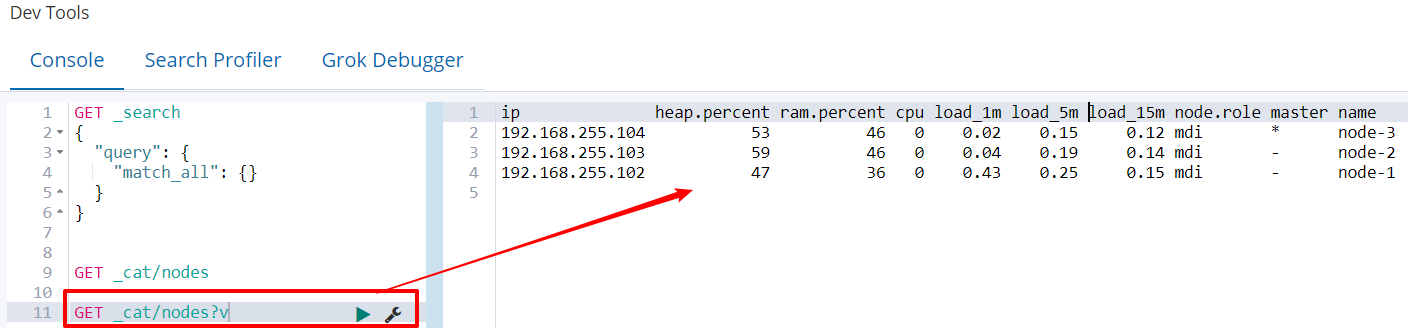
GET _cat/nodes?v

- heap.percent 堆内存占用百分比
- ram.percent 内存占用百分比
- cpu CPU占用百分比
- load_5m,每5分钟加载的情况
- master *表示节点是集群中的主节点
⑤查询某个索引的分片情况
-- GET _cat/shards/索引名
GET _cat/shards/movie_index?v
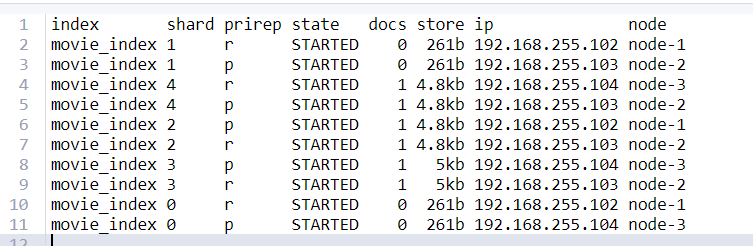
- index:索引名称
- shard:分片序号,默认是5个分片
- prirep:p是主分片,r是复制分片
- state:该分片的状态
- docs:分片存放的文档数
- store:该分片占用存储空间
4.4 对数据的操作
1 增加一个索引(put)
添加一张表
PUT student_index
2 查看创建的索引(get)
get _cat/indices?v
3 删除一个索引(delete)
删除一张表
- 删除索引会立即释放空间,不存在标记删除逻辑
- 删除文档的时候,是将新文档写入,同时将就文档标记为已删除。
- 也可以手动执行post/_forcemerge进行合并触发
DELETE student_index
4 新增文档(put幂等性)
添加一条数据,如果没有的index或type,elasticsearch会自动创建。
其中的id字段如果不写:会自增!!!
文档的id和文档中的id属性不是一回事!
-- put index/type/id
-- 这里的index是表;type是区,6.x只允许建一个,7.x废弃了;id是rowkey主键,一条数据的唯一标识
PUT movie_index/movie/1
{
"id":100,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{
"id":1, "name":"zhang yi"},
{
"id":2, "name":"hai qing"},
{
"id":3, "name":"zhang han yu"}
]
}
PUT movie_index/movie/2
{
"id":200,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{
"id":1, "name":"zhang han yu"}
]
}
PUT movie_index/movie/3
{
"id":300,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{
"id":1, "name":"zhang chen"}
]
}
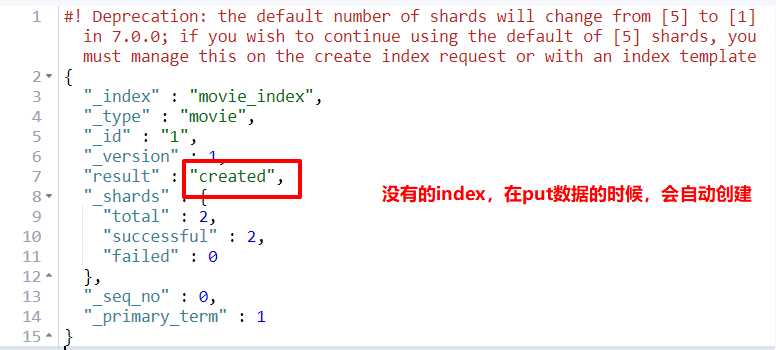
响应结果中看到的_shards=2,为啥不是5呢?这里创建的文档会在其中一个分片上存一份,副本上存一份。
幂等性检测:
幂等性操作:当数据出现问题的时候,数据要重发,幂等性是保证数据是一条数据,数据不能重复。
我又多次执行了put添加操作:
PUT movie_index/movie/3
{
"id":3,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{
"id":1, "name":"zhang chen"}
]
}
查询结果表示:数据不会重复!!!
5 新增文档(post非幂等性)
而post就是非幂等性的操作了,当执行多次post相同的数据,数据会重复;
会自动生成随机的id!!!
POST movie_index02/movie
{
"id":1,
"name":"incident red sea",
"doubanScore":6.0,
"actorList":[
{
"id":1,"name":"zhang han yu"},
{
"id":2,"name": "Tom"}
]
}
6 查询表中的所有数据(get + _search)
因为elasticsearch只允许有1个type,所以查询全部数据,下面两种都行
GET movie_index/_search
GET movie_index/movie/_search
查询的结果如下:
- took,表示查询的耗时时间。
- time_out,是否超时
- _shards,表示切片信息
- hits,表示我成功插入一条,就命中一条!
{
"took" : 1, //耗费时间,毫秒
"timed_out" : false, //是否超时
"_shards" : {
//分片信息
"total" : 5, //分片数
"successful" : 5, //成功的
"skipped" : 0, //跳过的
"failed" : 0 //失败的
},
"hits" : {
"total" : 1, //命中的总条数,也就是成功插入的总条数
"max_score" : 1.0, //最大评分,评分规则:
"hits" : [ //命中的结果
{
"_index" : "movie_index02",
"_type" : "movie",
"_id" : "W1DfhHYBrx9nWXZTCG2h",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "incident red sea",
"doubanScore" : 6.0,
"actorList" : [
{
"id" : 1,
"name" : "zhang han yu"
},
{
"id" : 2,
"name" : "Tom"
}
]
}
}
}
7 修改-整体替换(put)
和新增没有区别,要求是必须包括全部字段。 ==> 幂等性操作
最后面的77是主键,修改替换77这个主键的所有数据。
PUT movie_index/movie/77
{
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{
"id":1, "name":"zhang chen333"}
]
}
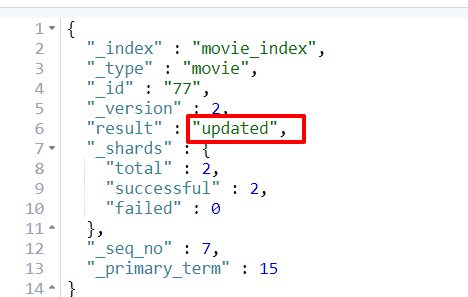
8 修改某一个字段(post + doc)
修改某一字段,使用post!!!不能使用put!!!
语法:
post index/type/rowKey/_update
{
“doc”:{
修改的内容
}
}
POST movie_index/movie/77/_update
{
"doc":{
"doubanScore":9.9
}
}
9 删除一个文档(delete)
语法是 delete index/type/rowkey,就删掉某条主键的document
- 删除索引会立即释放空间,不存在标记删除逻辑
- 删除文档的时候,是将新文档写入,同时将就文档标记为已删除。
- 也可以手动执行post/_forcemerge进行合并触发
DELETE movie_index/movie/77
10 查询指定id数据(get)
查找某个主键的document
GET movie_index/movie/1
11 查询 几条 数据(get + _search + size)
虽然能命中hit多条,但是可以指定显示size条数据!
GET movie_index/movie/_search
{
"size": 2
}
12 按条件查询(全部)(query + match_all)
--方式1:
GET movie_index/_search
{
"query": {
"match_all": {}
}
}
--方式2:简写形式
GET movie_index/_search
13 按分词查询(query + match)
根据匹配的程度,也就是结果中的"_score" 的数值排序。
评分公式的影响因素:
- 正向因素:命中次数、命中长度的比例。
- 负面因素:关键词在该字段的其他词条中出现的次数。
GET movie_index/_search
{
"query": {
"match": {
"name": "red"
}}
}
14 按分词子属性查询(query + match)
elasticsearch默认是按照分词查询的 ==> text,这样会根据分词,查询出所有匹配的结果,按照_score排序
如果想精确的查找某个条件 ==> keyword,这样不会分词,会精确匹配结果。
-- 这个时候的查询的是按照分词区查的!!!text
GET movie_index/_search
{
"query": {
"match": {
"actorList.name": "zhang"
}}
}
--上面查询的结果就是所有匹配zhang的演员名,会有多个~
-- 这个是不按照分词查询的,就是精确的查keyword
GET movie_index/_search
{
"query": {
"match": {
"actorList.name.keyword": "zhang"
}}
}
--上面查询的结果就是[],空,因为没有叫zhang的演员名
15 不适用分词匹配查询 (query + match_phrase)
不再利用分词技术。直接用短语在原始数据中匹配。
-- 普通的使用match 会将"operation red"分词成:"operation"和"red",然后根据倒排索引匹配。
GET movie_index/_search
{
"query": {
"match": {
"name": "operation red"
}}
}
-- 而使用match phrase不使用分词技术,直接在原数据中匹配。
GET movie_index/_search
{
"query": {
"match_phrase": {
"name": "operation red"
}}
}
--使用keyword,也可以使用分词匹配
GET movie_index/_search
{
"query": {
"match": {
"actorList.name.keyword": "zhang san feng"
}
}
}
--也可以使用精准匹配,term一定要和keyword一起使用
GET movie_index/_search
{
"query": {
"term": {
"actorList.name.keyword": {
"value": "zhang san feng"
}
}
}
}
16 容错匹配查询(query + fuzzy)
校正匹配分词,当一个单词无法精确匹配,es会通过一种算法对非常接近的单词进行评分,查询出来,但是会消耗更多的性能。
– 默认是仅可以允许有一个差别
GET movie_index/_search
{
"query": {
"fuzzy": {
"name": "rad"
}}
}
17 查询后过滤(query + post_filter)
查询是用“query”:{“match”}
过滤式用“post_filter”:{“term”:{}},其中term是直等
-- 查询电影名中含有red,并且演员id=3的document
GET movie_index/_search
{
"query": {
"match": {
"name": "red"
}},
"post_filter": {
"term": {
"actorList.id": "3"
}}
}
18 查询前过滤(bool + filter + must)
--先过滤保留下演员id含有1和含有3的document,然后匹配电影名中含有red的
GET movie_index/movie/_search
{
"query":{
"bool":{
"filter":[ {
"term": { "actorList.id": "1" }},
{
"term": { "actorList.id": "3" }}
],
"must":{
"match":{
"name":"red"}}
}
}
}
19 按照范围过滤
| gt | 大于 |
|---|---|
| lt | 小于 |
| gte | 大于等于 great than or equals |
| lte | 小于等于 less than or equals |
GET movie_index/_search
{
"query": {
"bool": {
"filter": {
"range": {
"doubanScore": {
"gte": 6,
"lte": 9
}
}
}
}
}
}
-- 这样也可以啊!
GET movie_index/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 6,
"lte": 9
}
}
}
}
20 直等(term)
term直等一般是和不分词的keyword一起使用。
-- term和text一起使用,下面的查询结果为[],这是因为分词将zhang chen分成了zhang和chen就无法直等
GET movie_index/_search
{
"query": {
"term": {
"actorList.name":"zhang chen"
}
}
}
-- term一般是和keyword一起使用的!这样就能查出来。
GET movie_index/_search
{
"query": {
"term": {
"actorList.name.keyword":"zhang chen"
}
}
}
20 根据查询条件进行删除、修改(_delete_by_query)(updete_by_query)
根据查询条件删除:post index/type/_delete_by_query{查询条件}
POST movie_index/movie/_delete_by_query
{
"query":{
"term":{
"actorList.name.keyword":"zhang chen"
}
}
}
根据查询结果修改
POST movie_index/movie/_update_by_query
{
"script":"ctx._source['actorList '][0][ 'name']='zhang san feng'",
"query":{
"term": {
"actorList.name.keyword": "zhang chen"
}
}
}
21 排序(sort + order)
-- 先查询,然后对结果进行降序排序:查询电影名含有red的电影,按照豆瓣评分降序排序
GET movie_index/movie/_search
{
"query": {
"match": {
"name": "red"
}
},
"sort": [
{
"doubanScore": {
"order": "desc"
}
}
]
}
--和范围一起使用:查询豆瓣评分7.0-8.5之间的电影,按照豆瓣评分降序排序
GET movie_index/_search
{
"query": {
"range": {
"doubanScore": {
"gte": 7.0,
"lte": 8.5
}
}
},
"sort": [
{
"doubanScore": {
"order": "desc"
}
}
]
}
22 分页查询(query + from + size)
-- from:表示从第几个document开始,size:表示分页显示几个
GET movie_index/_search
{
"query": {
"match_all": {}},
"from": 2,
"size": 2
}
23 指定查询的字段(query + _source)
-- 查询豆瓣评分这一条件
GET movie_index/_search
{
"query": {
"match_all": {}},
"_source": "doubanScore"
}
-- 查询电影名和豆瓣评分这两个条件
GET movie_index/_search
{
"query": {
"match_all": {}},
"_source": ["name", "doubanScore"]
}
24 高亮显示(highlight)
-- 不分词情况下,电影名为"incident red sea",电影名字段高亮显示
GET movie_index/_search
{
"query": {
"match": {
"name.keyword": "incident red sea"
}},
"highlight": {
"fields": {
"name": {}}}
}
--分词情况下,电影名中匹配有“red”,的电影名字段高亮显示
GET movie_index/_search
{
"query": {
"match": {
"name": "red"
}},
"highlight": {
"fields": {
"name": {}}}
}
自定义高亮显示标签
GET movie_index/movie/_search
{
"query":{
"match": {
"name":"red sea"}
},
"highlight": {
"fields": {
"name":{
"pre_tags": "<span color='red'>","post_tags":"</span>"}}
}
}
25 聚合(aggs)
聚合操作是:“aggs”{“分组新生成字段名”:{分组条件}}
terms分组查询
GET movie_index/movie/_search
{
"aggs": {
"groupby_actor": {
"terms": {
"field": "actorList.name.keyword"
}
}
}
}
GET movie_index/_search
{
"aggs": {
"groupBy_actor": {
"terms": {
"field": "actorList.name.keyword",
"size": 10
}
}
}
}

每个演员参演电影的平均分是多少,并按评分排序
--
GET movie_index/_search
{
"aggs": {
"groupby_actor_id": {
"terms": {
"field": "actorList.name.keyword",
"order": {
"avg_score": "desc"
}
},
"aggs": {
"avg_score": {
"avg": {
"field": "doubanScore"
}
}
}
}
}
}
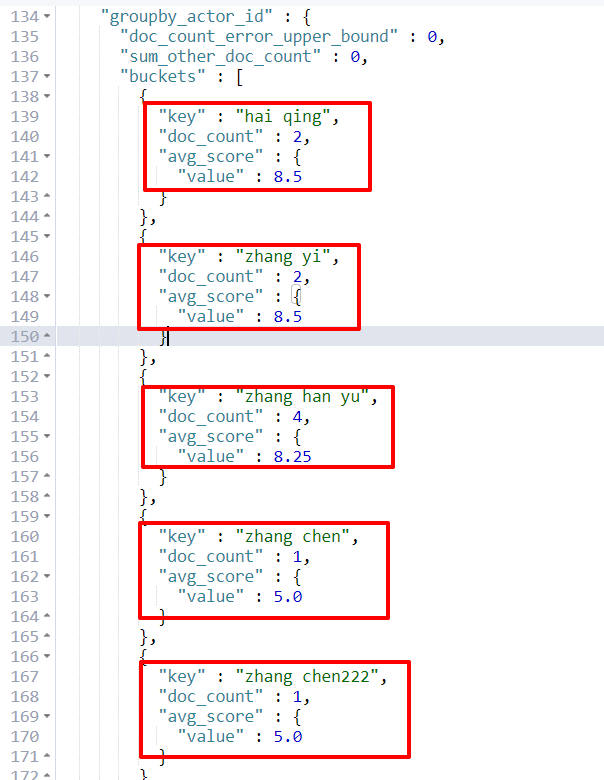
26 批量操作(_bulk)
--批量创建两个文档
POST movie_index/movie/_bulk
{
"index":{
"_id":44}}
{
"id":300,"name":"incident red sea44","doubanScore":5.0,"actorList":[{
"id":44,"name":"zhang san feng"}]}
{
"index":{
"_id":55}}
{
"id":301,"name":"incident red sea44","doubanScore":5.0,"actorList":[{
"id":55,"name":"zhang san feng"}]}
--批量操作:更新 + 删除
POST movie_index/movie/_bulk
{
"update":{
"_id":44}}
{
"doc":{
"name":"zhang sui shan"}}
{
"delete":{
"_id":55}}
4.5 SQL的使用
ElasticSearch SQL是6.3版本以后的功能,能够支持一些最基本的SQL查询语句。
- 只支持select操作,不支持update、insert、delete
- 6.3版本之前不支持
- 不支持窗口函数
- SQL比DSL有丰富的函数
- SQL少一些特殊功能,比如高亮、分页
GET _xpack/sql?format=txt
{
"query":"select actorList.name.keyword, avg(doubanScore) from movie_index where match(name,'red') group by actorList.name.keyword limit 1 "
}

4.6 中文分词
- elasticsearch支持的英文分词,是按照空格分词的
- elasticsearch本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。
分词器下载网址:https://github.com/medcl/elasticsearch-analysis-ik
还有的分词:smart chinese analysis(官方)、结巴
①安装分词器
步骤1:下载号的zip包,解压后放到…/elasticsearch/plugins/ik
步骤2:关闭es集群
myes.sh stop
步骤3:分发插件到其他的节点
[atguigu@hadoop102 module]$ xsync /opt/module/elasticsearch/plugins/
步骤4:重启es集群
myes.sh start
②测试使用
-- 默认使用:
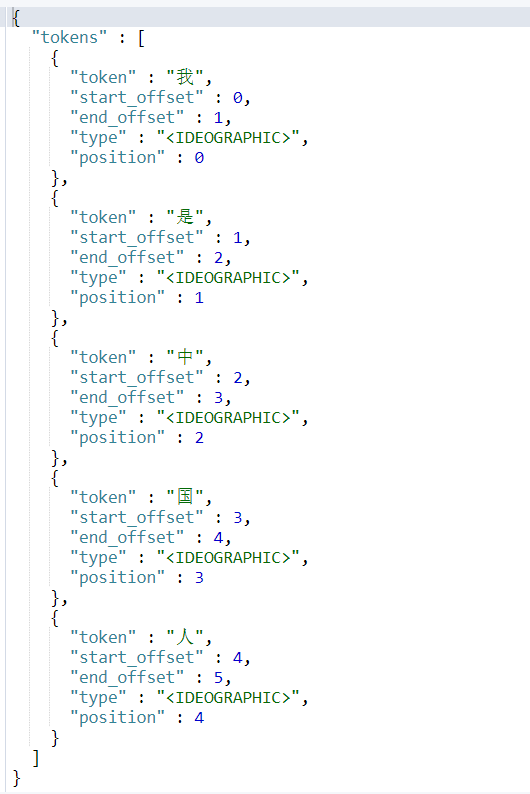
GET movie_index/_analyze
{
"text": "我是中国人"
}
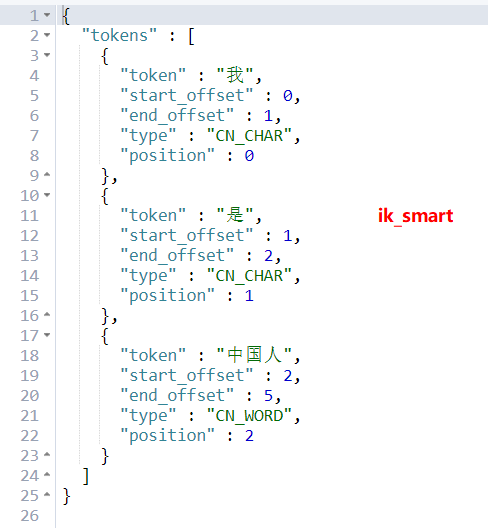
-- 使用ik中文分词器,ik_smart,不重复
GET movie_index/_analyze
{ "analyzer": "ik_smart",
"text": "我是中国人"
}
-- ik_max_word,会重复
GET movie_index/_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}

③自定义分词(本地)
步骤1:修改配置文件 IKAnalyzer.cfg.xml
[atguigu@hadoop102 config]$ vim IKAnalyzer.cfg.xml
- 自己的扩展字典:可以添加新扩展的词
- 扩展停止词字典:一些不想作为词的词,比如:我 的 了
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">./myword.txt</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!--<entry key="remote_ext_dict">http://192.168.255.102:8090/cict</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
步骤2:添加新增的扩展词字典
[atguigu@hadoop102 config]$ vim myword.txt
# 添加内容:
蓝瘦香菇
蓝瘦
步骤3:分发配置config到集群
xsync /opt/module/elasticsearch/plugins/ik/config
步骤4:重启es集群
步骤5:测试
GET _analyze
{
"text": "蓝瘦香菇",
"analyzer": "ik_max_word"
}

④自定义分词(远程)
使用nginx
4.7 mapping表定义类型
elasticsearch中的type分区的概念,其实也没什么作用,在7.x就取消了。
elasticsearch中的类型是通过mapping定义的。
- elasticsearch的mapping会自动推断出数据格式。默认只有text会进行分词,keyword不会分词
①查看mapping
GET movie_index/_mapping/movie
GET movie_index/_mapping
②查询结果
{
"movie_index" : {
"mappings" : {
"movie" : {
"properties" : {
"actorList" : {
"properties" : {
"id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"doubanScore" : {
"type" : "float"
},
"id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
③建立mapping
PUT movie_chn
{ "settings": {
"number_of_shards": 1 //设置分片数!
},
"mappings": {
"movie":{
"properties": {
"id":{
"type": "long"
},
"name":{
"type": "text"
, "analyzer": "ik_smart" //指定ik中文分词器
},
"doubanScore":{
"type": "double"
},
"actorList":{
"properties": {
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
插入数据
PUT /movie_chn/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{
"id":1,"name":"张译"},
{
"id":2,"name":"海清"},
{
"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{
"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{
"id":4,"name":"张晨"}
]
}
查询测试
GET /movie_chn/movie/_search
{
"query": {
"match": {
"name": "红海战役"
}
}
}
GET /movie_chn/movie/_search
{
"query": {
"term": {
"actorList.name": "张译"
}
}
}
4.8 分割索引
分割索引就是根据时间间隔把一个业务索引切分成多个索引。
比如把order_info变成:order_info_20200101、order_info_20200102 …
优点:
- 查询范围优化:因为一般情况并不会查询全部时间周期的数据,那么通过切分索引,物理上减少了扫描数据的范围,也是对性能的优化。
- 结构变化的灵活性:因为elasticsearch索引不允许对数据结构进行修改。但是实际使用中索引的结构和配置难免变化,最常见的是以天为间隔分割索引,这样每天就有了一次修改索引结构的机会。
4.9 索引别名 _aliases
索引别名可以指向一个或多个索引,也可以让多个索引指向。像mysql中的视图create view aaa as select …
优点:
-
给多个索引分组(例如:last_three_months):扩大

-
给索引的一个子集创建视图:缩小
-
在运行的集群中可以无缝的从一个索引切换到另一个索引
-- 类似于mysql中的视图,在代码中写视图名,那么如果业务修改,只需要修改视图和表结构即可。 create view 'v_base_category' as select * from base_category where id < 10; select * from base_category where id < 10; select * from v_base_category where id < 10; --如果修改了业务数据 drop view v_base_category; --删掉原来视图 --重新创建该视图 create view 'v_base_category' as select * from base_category11 where id < 10;
方式1:建索引的时候创建别名
aliases:{别名} + mapping定义表结构
PUT movie_chn_2020
{
"aliases": {
"movie_chn_2020_query": {}
},
"mappings": {
"movie":{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"text"
},
"doubanScore":{
"type":"double"
},
"actorList":{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}
}
}
}
方式2:为已存在的索引增加别名
POST _aliases
{
"actions": [
{
"add": {
"index": "teacher_index",
"alias": "teacher_index_aliases"
}
}
]
}
-- 这个时候就可以使用别名,查询了
GET teacher_index_aliases/_search
应用1:分组别名
POST _aliases
{
"actions": [
{
"add": {
"index": "movie_chn",
"alias": "movie_1001"
}},
{
"add": {
"index": "movie_index",
"alias": "movie_1001"
}}
]
}
-- 这样就能通过查询movie_1001查询到movie_chn和movie_index这两个索引中的数据了
GET movie_1001/_search
应用2:通过加过滤条件缩小查找范围,建立一个子集视图
POST _aliases
{
"actions": [
{
"add": {
"index": "movie_index",
"alias": "movie_index_aliases",
"filter": {
"term": {
"actorList.id": "3"
}
}
}
}
]
}
--查看查询结果
GET movie_index_aliases/_search
应用3:为某个别名进行无缝连接
在运行的集群中可以无缝的从一个索引切换到另一个索引。
POST _aliases
{
"actions": [
{
"remove": {
"index": "movie_chn",
"alias": "movie_1001"
}},
{
"add": {
"index": "movie_index",
"alias": "movie_1001"
}
}
]
}
①查看别名列表
GET _cat/aliases?v

②删除某个索引的别名
POST _aliases
{
"actions": [
{
"remove": {
"index": "movie_index",
"alias": "movie_index_aliases_idg2"
}
}
]
}
4.10 索引模板 _template
Index Template索引模板,创建索引的模具,可以定义一系列规则来构建符合特定业务需求的索引的mappings(表结构)和settings(分片数和副本数)。
①创建模板
- “index_patterns:[“movie_test*”] 表示:凡是往movie_test开头的索引写入数据时,如果索引不存在,那么es会根据此模板自动创建索引。
- “settings”: { “number_of_shards”: 1} 表示:索引的分片数
- “aliases” : { “{index}-query”: {},“movie_test-query”:{}} 表示:设置两个别名为"{index}-query"和"movie_test-query"
- mappings:表结构类型
PUT _template/template_movie2020
{
"index_patterns": ["movie_test*"],
"settings": {
"number_of_shards": 1
},
"aliases" : {
"{index}-query": {},
"movie_test-query":{}
},
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "keyword"
},
"movie_name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
-- 测试添加数据
POST movie_test_2020/_doc
{
"id":"333",
"name":"zhang3"
}
-- 因为设置了两个别名,可以查询这两个别名
GET movie_test_2020-query/_search
GET movie_test-query/_search
-- 也可以直接查这个索引
GET movie_test_2020/_search
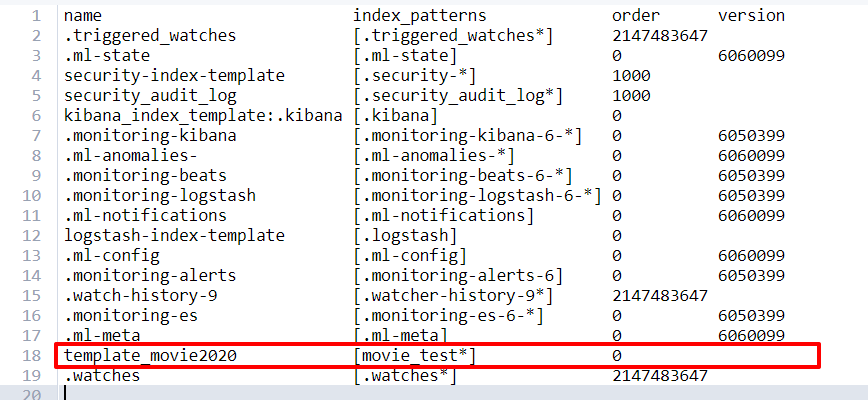
②查看所有的模板清单
GET _cat/templates?v
③查看某个模板详情
GET _template/template_movie2020
GET _template/template_movie*
5 shard划分
elasticsearch中的索引一般都是以天为单位建立的,每个索引的shard要合理控制
5.1 shard太多的危害
每个分片都有Lucene索引,这些索引都会消耗cpu和内存。同样的数据,分片越多,额外消耗的cpu和内存就越多。
shard的目的是为了负载均衡让每个节点的硬件充分发挥,但是如果分片太多,在单个节点上的多个shard同时接受请求,并对本节点的资源形成了竞争,实际上反而造成了内耗。
6 IDEA中操作ElasticSearch
客户端:
- TransportClient,ES的原生客户端,不能执行DSL语句必须使用Java的API方法。(7.0排除)
- jset,可以使用DSL语句拼成字符串,直接传给服务器,然后返回json字符串再解析。
6.1 导入pom依赖
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.6.0</version>
</dependency>
6.2 获取jset客户端对象
//定义获取客户端的工厂
private var factory:JestClientFactory = null
//获取操作es的java客户端工具类jestClient
def getJestClient = {
if (factory == null){
factory = new JestClientFactory
val httpClientConfig = new HttpClientConfig.Builder("http://hadoop102:9200")
.multiThreaded(true) //是否开启多线程处理
.maxTotalConnection(20) //最多连接数
.connTimeout(10000) //连接超时时间
.readTimeout(1000) //读取超时时间
.build()
factory.setHttpClientConfig(httpClientConfig)
}
factory.getObject
}
6.3 向es插入数据
①方式1:
-
步骤1:获取客户端连接
-
步骤2:通过客户端对象执行execute(action: Action)
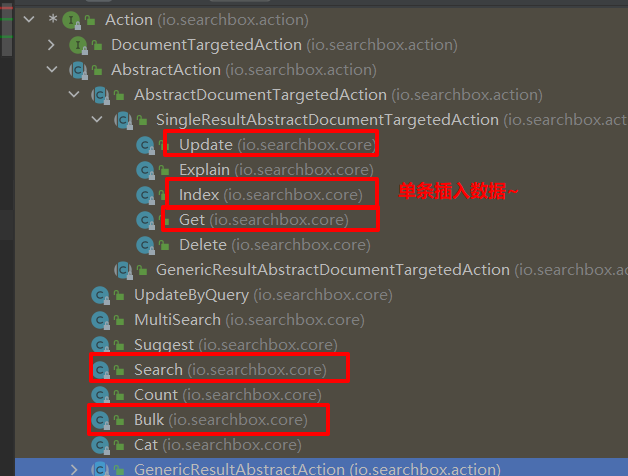
-
步骤3:根据业务逻辑,创建action
Action是一个接口
- 这里使用了构造器设计模式:在Index里面有Builder的内部类。
//向es中的index索引中插入数据
def putIndex() = {
//获取客户端连接
val jestClient = getJestClient
val source : String =
"""
|{
| "id":1001,
| "name":"天龙八部",
| "doubanScore":8.9,
| "actorList":[
| {"id":1, "name":"张三"},
| {"id":2, "name":"李四"}
| ]
|}
|""".stripMargin
//创建插入操作对象
val index = new Index.Builder(source)
.index("movie_chn_1")
.`type`("movie")
.id("1")
.build()
//执行插入操作
jestClient.execute(index)
//关闭连接
jestClient.close()
}
②方式2:封装样例类
根据方式1:写出来document之后,再封装样例类,插入数据。
生产环境规范是方式2.
case class Movie(
id: Long,
name: String,
doubanScore: Double,
actorList:java.util.List[java.util.Map[String, Any]]
)
//方法2:使用样例类(用来封装document中的属性) 向Index中插入数据
def putIndex2 = {
//获取客户端连接
val jestClient = getJestClient
val actorList = new util.ArrayList[util.Map[String, Any]]()
val actor1 = new util.HashMap[String, Any]()
actor1.put("id", 111)
actor1.put("name", "张三丰")
val actor2 = new util.HashMap[String, Any]()
actor2.put("id", 222)
actor2.put("name", "张无忌")
actorList.add(actor1)
actorList.add(actor2)
//
val movie = Movie(
666,
"一部好看的电影",
10.0,
actorList
)
val index = new Index.Builder(movie)
.index("movie_chn_1")
.`type`("movie")
.id("2")
.build()
//执行插入操作
jestClient.execute(index)
//关闭资源
jestClient.close()
}
6.4 从es查询一条数据
def getIndexById() = {
//获取连接
val jestClient = getJestClient
//创建Get查询操作对象
val get = new Get.Builder("movie_chn_1", "2").build()
//执行查询操作
val documentResult: DocumentResult = jestClient.execute(get)
println(documentResult.getJsonString)
//关闭连接
jestClient.close()
}

6.5 从es查询多条数据
方式1
//根据条件,从es索引中查询出符合条件的所有文档
def getIndexByCondition() = {
//获取连接
val jestClient = getJestClient
val query: String =
"""
|{
| "query":{
| "bool":{
| "filter":[ {"term": { "actorList.id": "1" }},
| {"term": { "actorList.id": "3" }}
| ],
| "must":{"match":{"name":"red"}}
| }
| }
|}
|""".stripMargin
val search = new Search.Builder(query)
.addIndex("movie_index")
.build()
//执行查询操作
val searchResult: SearchResult = jestClient.execute(search)
//对查询结果进行处理
val resList: util.List[SearchResult#Hit[util.Map[String, Any], Void]] = searchResult.getHits(classOf[util
.Map[String, Any]])
//将java集合转换成Scala集合
import scala.collection.JavaConverters._
val list: List[util.Map[String, Any]] = resList.asScala.map(_.source).toList
println(list.mkString("\n"))
//关闭连接
jestClient.close()
}
方式2:利用SearchSourceBuilder
//方式2:根据条件,从es索引中查询出符合条件的所有文档:利用SearchSourceBuilder
def getIndexByCondition2() = {
//获取jest客户端对象
val jestClient = getJestClient
//创建SearchSourceBuilder对象
val searchSourceBuilder = new SearchSourceBuilder()
//创建QueryBuilder对象
val boolQueryBuilder = new BoolQueryBuilder()
boolQueryBuilder.must(new MatchQueryBuilder("name", "red"))
boolQueryBuilder.filter(new TermQueryBuilder("actorList.name.keyword", "zhang han yu"))
searchSourceBuilder.query(boolQueryBuilder)
searchSourceBuilder.from(0)
searchSourceBuilder.size(20)
searchSourceBuilder.sort("doubanScore", SortOrder.DESC)
searchSourceBuilder.highlighter(new HighlightBuilder().field("name"))
val query : String = searchSourceBuilder.toString()
// println(query)
//创建查询对象
val search = new Search.Builder(query).build()
//执行查询操作:对结果处理
val searchResult = jestClient.execute(search)
val resList: util.List[SearchResult#Hit[util.Map[String, Any], Void]] = searchResult.getHits(classOf[util
.Map[String, Any]])
//将java集合转化为scala集合进行操作
import scala.collection.JavaConverters._
val list = resList.asScala.map(_.source).toList
println(list.mkString("\n"))
//关闭客户端连接
jestClient.close()
}