ConcurrentHashMap
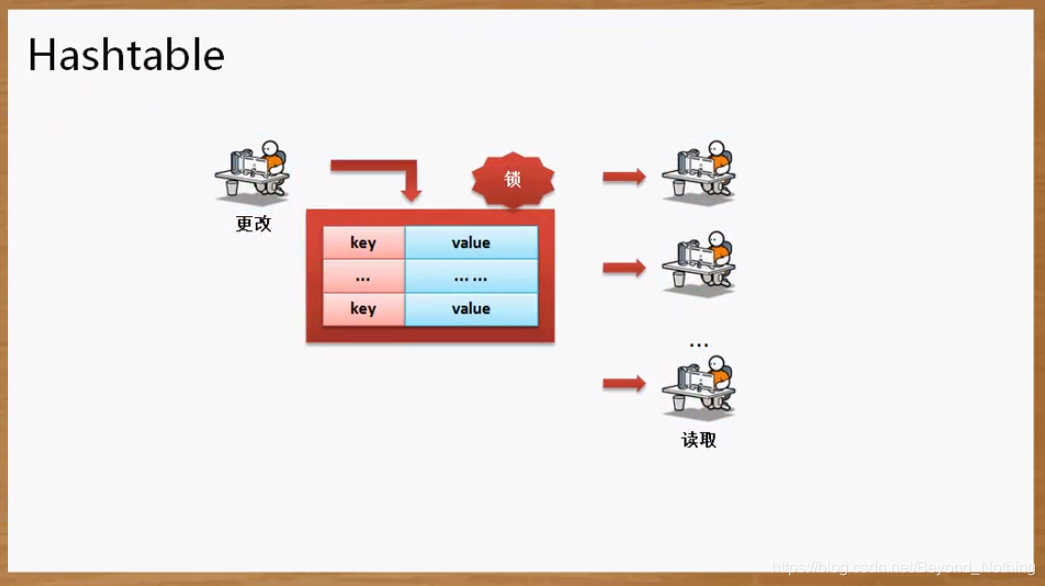
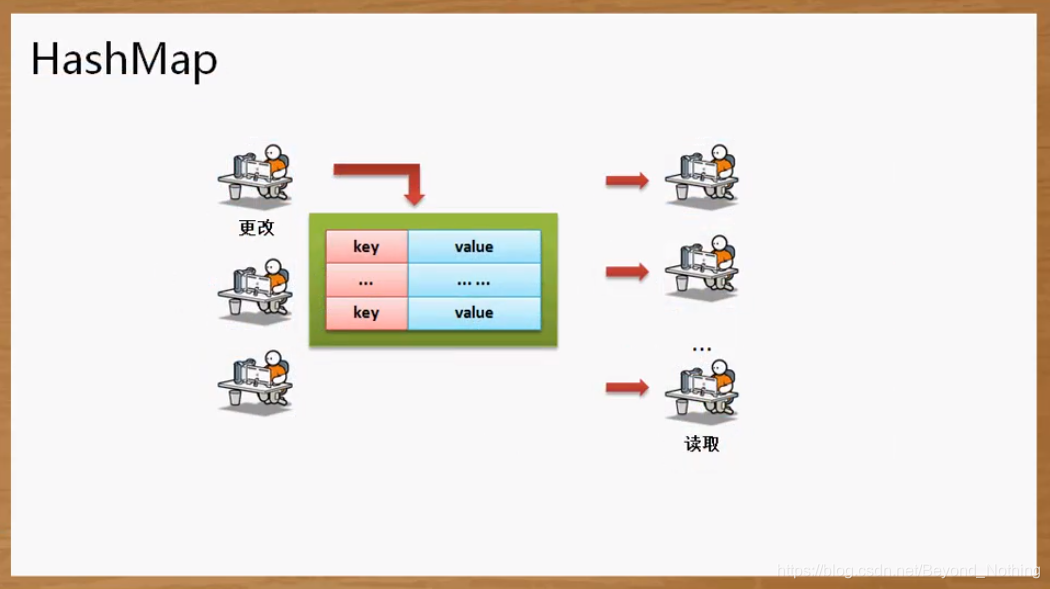
ConcurrentHashMap 的特点 = Hashtable 的线程安全性 + HashMap 的高性能
在使用 ConcurrentHashMap 处理的时候既可以保证多个线程更新数据的同步, 又可以保证很高效的查询速度.
首先来观察 ConcurrentHashMap 的子类定义:
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V> implements ConcurrentMap<K,V>, Serializable
范例: 使用 ConcurrentHashMap
package com.beyond.nothing;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
public class test {
public static void main(String[] args) {
Map<Integer,String> map = new ConcurrentHashMap<>();
map.put(1, "Hello");
map.put(1, "World"); // key 重复
map.put(2, "World2");
System.out.println(map);
System.out.println(map.get(1)); // 根据 key 取得数据
Set<Integer> set = map.keySet(); // 取得所有的Key信息
Iterator<Integer> iter = set.iterator();
while (iter.hasNext()){
Integer key = iter.next();
System.out.println(key +"= "+map.get(key));
}
}
}
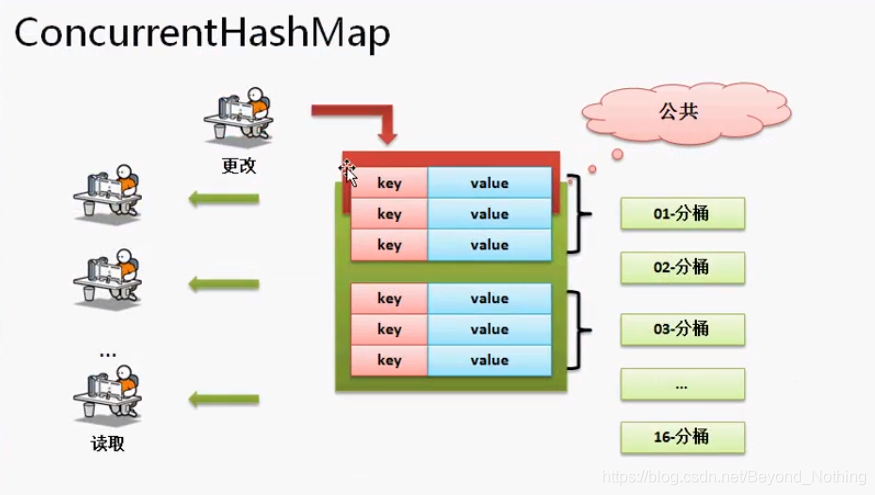
于是现在就需要分析一下 ConcurrentHashMap 的工作原理:
如果说现在采用一定的算法, 将保存的大量数据平均分在不同的桶(数据区域), 这样在进行数据查找的时候就可以避免掉种全部的数据扫描.
采用分桶之后每一个数据中必须有一个明确的分桶的标记, 很明显使用 hashCode().