会议:2020 icassp
作者:Kaizhi Qian
单位:University of Illinois at Urbana-Champaign
abstract
AutoVC的方法可以完成集内many-to-many的语音转换,并且可以实现zero-shot VC,但是对基频的控制作用很弱,生成的目标语音基频经常会有不明显的波动。本文是对AutoVC结构的改进,实现同时解耦说话人,内容和F0,进一步改善语音质量和自然度。
1. introduction
- AutoVC的假设是F0不属于spk_emb,也不属于content info。但是实验发现,两个部分中都残存一些基频信息,会导致合成语音时候的基频偏移,尤其是跨性别转换的时候,F0会突然从一个性别跳到另一个性别。
- 分析原因是:(1)F0需要很多数据才能建模,但是speaker encoder的训练是基于有限量的数据,因此目标说话人的speaker embedding中编码的韵律信息有限,decoder无法根据此生成自然的F0。(2)因此speaker encoder的韵律信息不完整,为了优化self-recontruction,bn中会携带一些prosody的信息给到decoder,从而导致infer的时候,基频在source和target之间跳跃。
- PS:认为作者分析的第一点不太对,本文conversion时候的prosody应该走势就是和source一致,因此不加显性指示的话,会来自source;此外,target spk_emb被压缩到一维表示,本身就损失了时间上的变换信息,更不太可能对基频包络的走势进行补充。
- 解决方法:显性的把sourceF0添加到decoder中,用于self-reconstruction的过程。
2. Method
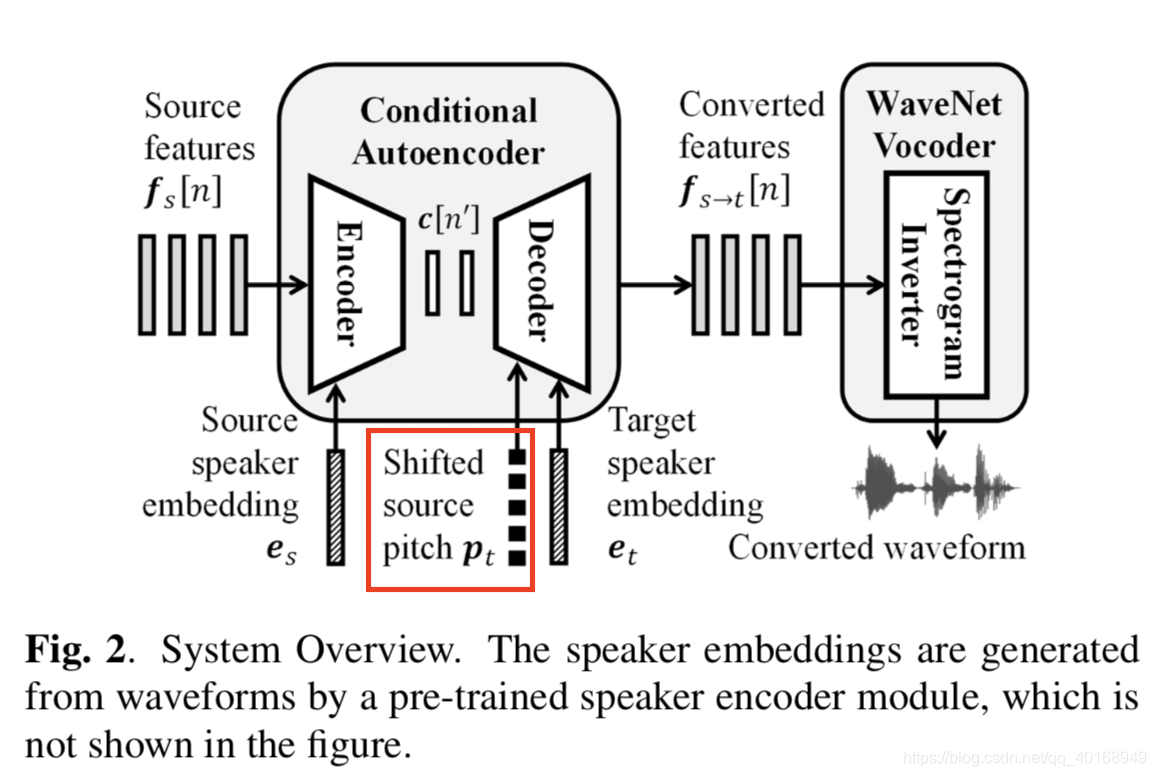
加入sourceF0,处理方式:
(1)提取source logF0,计算mean/std,norm到0-1之间; P n o r m P_{norm} Pnorm= (logF0-mean)/std/4
(2)用256个数字将0-1之间的logF0量化,使用one-hot encode;
(3)加一维uv编码,一共257维信息;
希望decoder根据spk_emb自己学到normF0的denorm信息
- Bottleneck Tuning and augmentation
content encoder的输出降到16维;
数据增广的方式:(1)时间维度的放缩;(2)能量变化;(3)整体长度裁剪,以适用不同的语音长度。
3. EXPERIMENTS
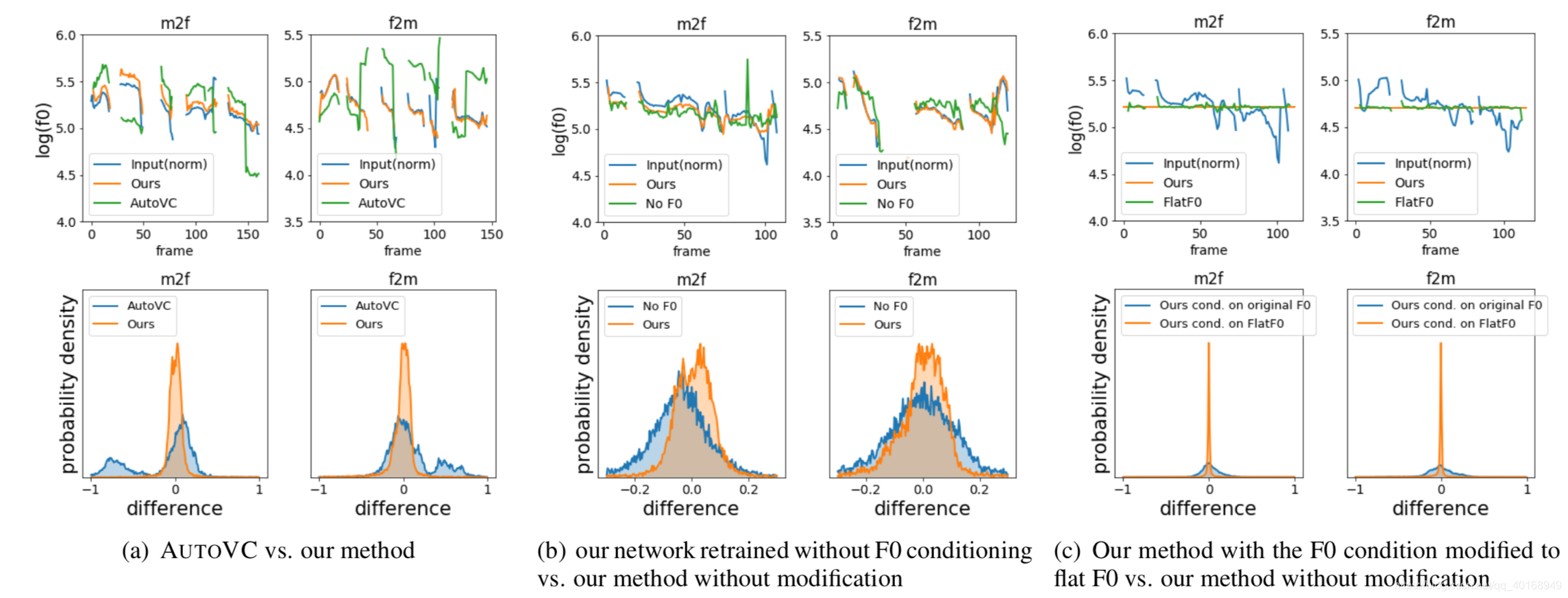
Fig. 4. Comparison of F0 contours of generated speech based on the two methods. In each sub-figure, the upper two plots display example F0 contour overlaid on the input F0 normalized to the target speaker’s F0 range. The lower two plots show the error distribution between the F0 of the converted speech and the normalized input F0. In both upper and lower plots, the left one corresponds to male-to-female cases and the right one corresponds to female-to-male cases. The caption of each sub-figure shows the two methods being compared.