作者:Yuki
单位:东京大学&日本NTT(电报电话)公司
会议:2018 icassp
ps.本文中latent variable都是说话人无关的语言特征
abstract
本文提出一个新的基于VAE的non-parallel 的VC,原有的VAE是给定语句(speaker representation),因为VAE潜在变量的原因,转换语音的phonetic content会因为over regularization而消失。本文提出一个新的VAE,不仅依赖于speaker representation, 而且需要音素级的PPGs。因为训练过程中的给了音素内容(phonetic content),因此希望VC模型学到说话者相关的特征(latent features)。基于这个特点,我们做成一个many-to-many的VC。
我们研究两种不包含在语料库中的方法以估计说话者的表达(1)调整传统说话者编码(2)使用d-vector作为说话者特征表示;
实验结果表明(1)PPGs成功地改善说话者和target的相似度和自然度;(2)说话者编码(speaker code)和d-vector都可以用于非平行的many-to-many VC。
1.introduction
DNN网络被用于voice conversion,并且取得了比传统GMM更好的效果。但是大部分是完成平行数据集的VC任务,虽然可以做到很好的帧与帧的对齐映射,但是很难应用到实际生活中。
VAE被应用于非平行数据的语音转换,encoder从输入数据中提取说话者独立的latent feature, decoder在给定target speech的情况下将latent feature重建语音。因此,我们可以假设latent feature代表了说话者独立的音素特征,VC修改说话者特征之后送入decoder网络。但是语音转换的效果并没有基于平行数据的DNN好,一个主要的原因是VAE中潜在变量的过度规范化(the over regularization of latent feature),导致潜在变量的分布过于简单。可以验证这个观点的就是GMM中latent feature更复杂的先验分布(more complex prior distribution)。但是在VAE中直接修改这一点并不简单,因为phonetic content的内容变化比较大,很难确定 GMM中聚类的数目。
从很多不明的说话者中提取speaker-independent的潜在特征,可以根据这一特性将模型扩展到many-to-many的任务中。用ASR(automatic speaker recognintion)模型的输出PPGs表征说话者无关的内容变量,从预训练的ASV(automatic speaker verification)中获得d-vector,用于表征不同的说话者的身份特征。
2.conventional VAE based on non-parallel VC
2.1. Non-parallel VC using VAEs conditioned by speaker codes【6】
图1是三种模型。图中黑线是特征推断的过程;红线是预测speech参数的过程。

(a)使用1-of-S的one-hot编码方式表示S个人中的一个人,
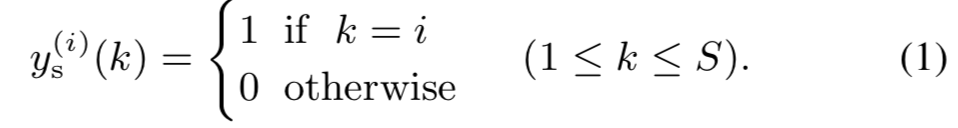
假设z和ys是独立的,p(z)是隐藏变量的先验,目的是估计模型的参数值,使得speaker representation给定的情况下最大化边际似然。其中P(Z)是latent variable的一个先验概率。
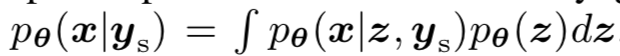
因为神经网络很难处理积分的问题,我们引入两个网络
(1)说话者独立的编码网络q(Z|X),近似latent variable的后验概率P(Z|X);
(2)说话者相关的编码网络,近似speech参数的后验概率P(X| Z, Y)
网络的目标函数是最大化对数似然的变分下界
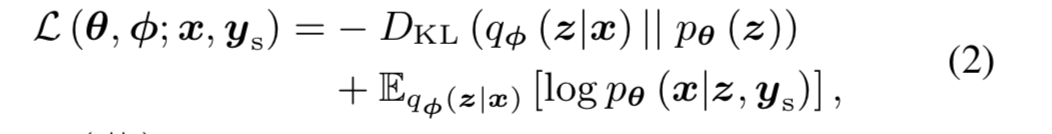
网络训练好之后,将target speaker(训练时候见过的)的编码送到decoder网络中(不送source apeech??),就可以完成转换。
2.2 problems
我们假设latent speaker是和说话者无关的音素级特征,但是在非平行数据的基于VAE的VC任务中,训练过程中语音信息通常会消失,这是因为公式(2)中KL项太强的先验影响,这就是latent variable的over-regularization,使得得到的latent variable被过度简化,难以表示音素结构的本身特征。而且,尽管VAE有可能从许多不固定的说话者中提取出说话者无关的laten variable ,目前他们只能把source的说话者特征转换到训练数据集中的target speaker上。
3.proposed VAE-based non-parallel VC
改进了现有的VAE结构,提升的转换的语音质量,并且实现了基于非平行数据的many-to-many的语音转换。
3.1 Non-parallel VC using VAEs conditioned by PPGs and speaker codes
zp是通过ASR生成的PPGs, 然后分别送入encoder和decoder的网络,ys–one hot code,对应图1(b)。

本阶段训练的损失函数为
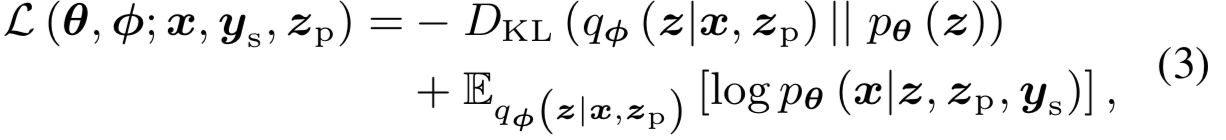
3.2 Effective speaker representations for many-to-many VC
当target speaker没有包含在VAE训练的语料库中时,我们必须用一个小的数据集估计speaker representation。其中用到两种方法–
3.2.1 Adapting speaker codes using back propagation algorithm
最早在【12】中提出,首先对估计的speaker codes设计初始值,然后计算目标语音和合成的目标语音之间的均方差;最后用反传算法对估计的speaker code进行梯度更新,多次迭代得到new speaker的speaker code。
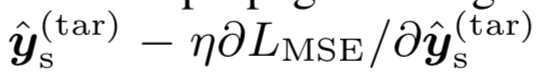
3.2.2 Using d-vectors for speaker representations
从ASV模型中获得d-vector【11】,是一个表征说话人身份的潜在特征。将传统离散的speaker code替换为连续的d-vector。
再次将损失函数 更新为
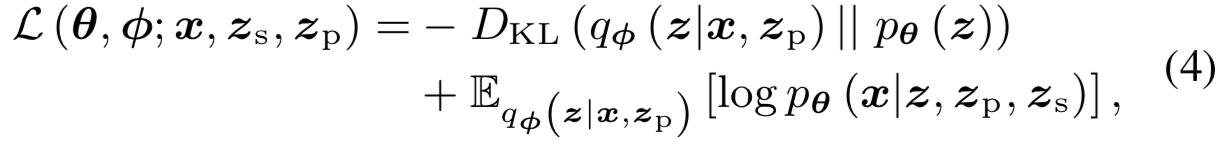
在训练VAE的阶段,d-vector按照speaker code的方式一帧帧送入decoder;
在conversion阶段,一个新的speaker被估计成语音区域的d-vector平均值。参考图1(c)。

4.experimental evaluation
4.1 experimental set
用Japanese 260 speaker训练ASR和ASV,Janpanese 3 speaker(2male,1female)训练VAE,425句平行语音,400句用于训练,25句用于验证,为了制造非平行数据,将400句分成两部分,source来源于一部分,target来源于另一部分。
22.05KHz,STRAIGHT vocoder。
4.2 experimental result
PPGs对语音的相似度和自然度 有贡献;
speaker code和d-vector都可以完成many-to-many的VC任务,其中d-vector更优秀一些。下一步工作会探讨d-vector维度的影响。
(遗留问题:VAE的网络结构是怎么样的??loss函数的数学表达式具体如何??)