单位:新加坡国立
作者:Haizhou Li
abstract
现在的vc基本都是基于谱做的变换,但是和说话者相关的韵律特征,比如基频、能量包络,我们认为如果能量更好的理解基频,就能更好的实现更好的vc效果。说话者依赖的特征是说话者的特性,说话者独立的特征是语言表达的特性,在vc任务中,前者是需要转换的,后者是需要保留的。我们提出用wavelet在不同的时间尺度分析这两个特征。
(谱参数与音色有关,基频与清晰度、韵律有关)
1. introduction
vc就是把一个说话者讲的话转成像是另外一个人说的。说话者特征体现在(1)反映在句子结构和词汇上的语言特征;(2)超音节因素,或者韵律特征,反映在stress,声调,音节、单词或者短语的连读;(3)与短时特征有关的分段因子,例如短时谱和共振峰。当说话内容固定时,超音节特征和segmental feature就和说话者个体有关系了。
对韵律的建模非常有难度,韵律是supra-segmental level,而谱是短时帧.prosody由F0和能量组成,但是他们变化很大。它包括可以表达情绪的对比(生气或高兴),lexical stress,或者对话中的语音事件(陈述或疑问),我们称这些为说话者独立的特征;它也包括个人的、方言和其他背景特征等和说话者相关的特征。
韵律本质上也是分等级的,会被短时和长时依赖性影响。F0是韵律一个关键的特征,因此之前转换也都主要关注F0的转换。提出用Continuous wavelet transform(CWT)通过数据分析分解成F0和能量包络,因此转换网络可以从source和target中携带说话者独立的韵律特征。而将source中说话者相关的韵律特征转成target。
2. Prosody Modelling in Voice Conversion
韵律携带着各种各样的语言的、副语言的以及非语言的信息,比如说话者特性、意图、情绪,它实际上是超音节的特征,因为不能从语音片段中获得。它被词、短语、句子等不同级别的长时依赖性影响,同时也被片段的不同影响,比如无声的片段没有F0,高的元音比低的元音的F0高。
由STRAIGHT vocoder提取到的低维F0,数据复杂度远小于谱参数,用高斯归一化变换(线性变换)可以简单的对F0做转换,但这不足以表示所有时间步不同的变换。但是CWT可以分解为F0和能量包络,对于信号f0的CWT变换就可以写成

pusai是10个离散的范围,因此f0可以表示为,t0=5ms
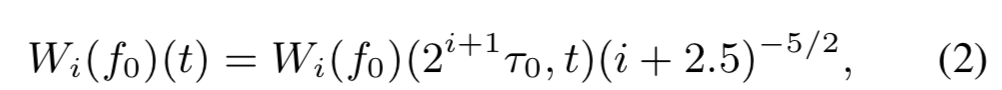
10个区间的划分参考了语言结构,从micro-prosody到句子级,重建的过程可以表示为
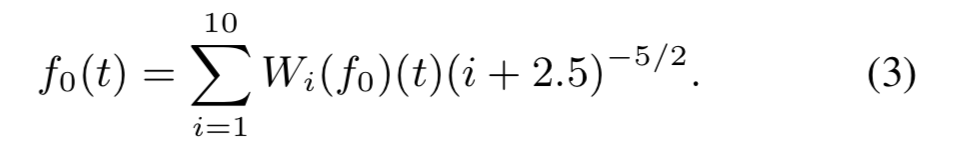
因为CWT对韵律特征的不连续很敏感,因此需要进行预处理
(1)对F0和能量包络的线性变换转成对数变换;
(2)用3点均值滤波器对F0和能量包络进行平滑处理;
(3)线性的插入无声片段
(4)对处理后的F0和能量进行归一化处理
主要是想通过CWT(连续小波变换)分解找到和说话人相关以及无关的特征。
3. Analysis of Prosody Features for Voice Conversion
PCC和RMSE
PCC是皮尔逊相关系数,表明2个参数之间的线性相关
首先做一个对齐,然后对10-scale分别求PCC和RMSE。


发现scale 4-8有低的相关度和高的RMSE值,这表明它携带的是说话者相关的信息。
我们把发现归纳为:scales1-3(低的时间尺度)代表短时韵律特征,scales9-10代表长时韵律特征。短时的韵律特征在片段内表示,因此speaker之间差别不大,长时韵律特征表示句子级韵律,比如表示、问题、要求,也是说话者独立的;scales4-8是超音节信息,比如节奏、腔调等,和说话者有关。因此转换网络carry低和高的信息,转换中间的信息。
个人感想:提供了一个合理的思路,有一些变换提取的思路是可以参考借鉴的。