单位:合肥中科大&科大讯飞
时间:2019.1
期刊:TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING
基于平行数据的实验
abstract:
Sequence-to- sequence ConvErsion NeTwork (SCENT)—voice conversion的声学模型
training stage—用attention机制将source和target speaker的future sequence精确对齐以估计SCENT model
converse stage—用统一的声学模型将source utterance的特征和持续时间同步的转换
声学特征—mel scale谱,包含了声学激励和声道描述
用ASR model从source speech中提取的bottleneck feature作为辅助输入 (是什么特征??)
WaveNet vocoder—以SCENT输出的梅尔谱作为输入,重建wav, 结果分析:
- 与传统方法对比,duration conversion(周期/基频倒数)更好;
- 以GMM和DNN声学模型的结果为baseline,本方法的主观客观性能都更优秀,也比我们2018年voice conversion比赛的结果(top rank)好
1.introduction
用 统计声学模型(statistical acoustic models ,如HMM)作特征匹配是比较流行的方法
**传统方法:(parallel data)**流程
- training stage: 1⃣️从source和target speaker中提取特征,2⃣️用算法(比如DTW)强制frame to frame对齐,3⃣️然后用paired source-target frames的声学特征训练conversion 网络(声学模型)。这个声学模型可以是JD-GMM或者DNN,都是通用函数近似器。
- conversion stage:将训好的模型用于source to target的转换
- construct: 声学模型得到的mel送入vocoder,重建wav波形
局限性
- 关注的是谱特征的转换,并且只在对数域对F0做一个简单的线性变换;
- 转换句子的时长和source一模一样,因为声学模型是一帧一帧构建的;然而人类说话是一个高度动态的过程,frame-by-frame的假设限制了映射模型的建模能力。
本文提出的方法—sequence to sequence
网络架构:带有attention的VAE
encoder将输入feature转成decoder可以处理的hidden representation
decoder的每一个时间步中,attention module都通过attention probability挑选encoder的输出,并将其转换成a context vector。
然后,decoder通过context vectors 一帧一帧的预测输出的声学特征,
还有post-filtering network,用于增强转换声学特征的精度
vocoder: speaker-dependent的WaveNet用于恢复波形
[ ] 用mel scale spectrogram作为声学特征,不依赖语音产生的source-fileter假设,因此F0和谱特征可以在一个模型中共同完成转换。
[ ] 用ASR得到的bottleneck feature作为source谱的附加,可以改善转换语音的发音正确性。
[ ] attention module是source-target序列之间的软对齐,结果是生成的target sequence的时长可能是和source不一样的。
主要是one-to-one的voice conversion,也可以扩展到many-to-one。
2⃣️related work
A --Relationship with sequence-to-sequence learning for text- to-speech
本文受启发于将seq2seq应用于TTS,然而voice conversion和TTS在一些方面是不同的。
- voice conversion的输入是帧级别的声学,而不是phone-level or character-level的语言特征,(语言特征是离散的,而声学特征是连续的)声学特征不仅包含语言信息,还包含说话者特征,这在voice conversion过程中也应该被处理。
- 输入输出的对齐也是不一样的:TTS的speech generation的对齐是一个解压缩的过程,文本和声学特征是一对多的映射。voice conversion的映射可以是one-to-many,也可以是many-to-one,取决于speaker pairs的特征,也取决于 声学序列的动态特点。
- voice conversion可用的训练数据要比 TTS少很多。
B. Relationship with voice cloning
our method:用一个单独的ASR模型提取语言相关的特征,模型的输入是source speech,然后按照one pair生成target speech。
这个想法由voice cloning 发展而来,有可能从one-to-one推广到many-to-many conversion。voice cloning 是text-to-speech,利用一些speech sample生成unseen speaker speech。
C. Sequence-to-sequence learning for voice conversion
【31】第一次使用带有attention的seq2seq的转换,但是他不能使用自己的预测产生实值输出;
【32】基于CNN的seq2seq的voice conversion,但是没有attention,还是帧级别的对齐;
【33】使用seq2seq模型匹配文本后验概率,提出基于RNN的encoder-decoder网络,将source seq后验概率的每一个phone转成target,在转换阶段,target speech的音素持续时间是非常关键的。
我们和【31】的方法很像,句子级的seq2seq,带有attention网络,输入mel 谱。可以不依赖DTW完成input和output的句子匹配。在转换过程中,目标音素的持续时间自动决定,每个解码时间步预测完成的概率。
D.Voice conversion using WaveNet
本文用WaveNet作为声码器重建target speech,mel谱作为输入,以speaker-dependent的方式训练。
3⃣️PROPOSED METHOD

A. Overall architecture
如图1所示,两个阶段,SCENT用于声学特征预测,将输入的特征序列转成target的mel谱特征,最后用WaveNet vocoder进行语音波形恢复。
B. Feature extraction
mel spec:用STFT+ mel fbank 生成
**bottleneck feature:**用基于RNN的ASR模型在单独的识别数据集训练好,每一帧的bottleneck feature就是ASR最后一个隐层在做softmax之前的激活后的数值。因此bottleneck feature包含语言特征,有利于voice conversion。而且它仍然是声学特征,不必要做文本转换。
source speech每一帧的mel和bottleneck feature拼接起来作为SCENT的输入。
C. Structure of SCENT

依次介绍各个部分
## ## 1)Encoder
pyramid (金字塔形)bidirectional LSTM,在较高的层处理较低时间分辨率的序列???较低层多个时间步的输出拼接作为后续时间步的输入(可以实现降采样)
常规的BLSTM
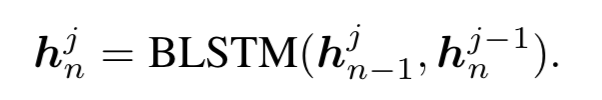
本文pBLSTM
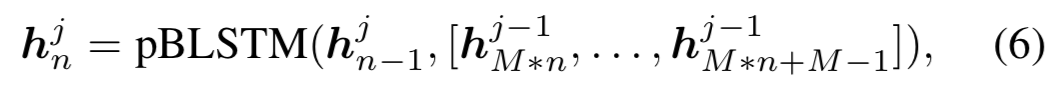
M是降采样因子
希望encoder提取到 high-level并且语言相关的特征。
- 因为一个phone会对应数十个frame,因此将采样是合理的。
- 低采样率的hidden representation可以使attention更快的收敛,并且加快计算速度,因为低采样率会产生更少的attention编码需求
location code告诉模型现在在处理哪一部分的信息。直接加在encoder最后一层的输出,作为hidden representation 的一部分。
2) Decoder with attention mechanism:(很重要,重看一遍)
生成过程(decoder)是单向的,自回归RNN,从hidden representation预测声学特征。每个时间步预测出不重叠的r帧,将整个解码过程分成r步,进一步减少了train和inference的时间。图2画的是r=1的情况。
本文实现中,采用混合注意力机制,在计算attention probability的时候,将之前decoder step的对齐考虑在内。
为了提取location information,做卷积
3) Post-filtering network:
为了利用双向的上下文信息,引入PostNet是双向的,改进生成结果。PostNet的输出也是整个网络的输出。PostNet和decoder的帧采样率是一样的,因此输出帧数目一致。