作者:tianxiaohai
单位: 新加坡国立&南洋理工
abstract:
在vc任务中,vocoder是用于feature-2-speech的合成,但是vocoder会造成语音质量的损失,本文提出一个vocoder-free的想法,通过wavenet直接匹配ppgs和waveform samples,做non-parallel的任务,而不需要中间的数据,因而可以避免feature conversion和vocoder带来的损失。ppg是说话者独立的。
1.introduction
本文受【28】【29】的启发,首先编码说话者独立的语音信号,例如ppgs;训练阶段:将ppgs和时域的语音信号做映射;转换阶段:从给定的speech中提取ppgs,然后通过wavenet恢复成speech。ps.conversion model是在同一个speaker的ppgs和语音信号上训练的。
本文的新意:
(1)不需要参数化的声码器,因此可以避免特征提取和通过声码器语音重建的误差;
(2)跳过声码器转换需要的中间特征,进一步简化用wavenet vocoder的转换技术
2.voice conversion with wavenet vocoder
本章主要讲用wavenet vocoder做转换的优缺点
2.1 wavenet vocoder
wavenet vocoder是一个传统的wavenet,将声学特征重建回时域信号,
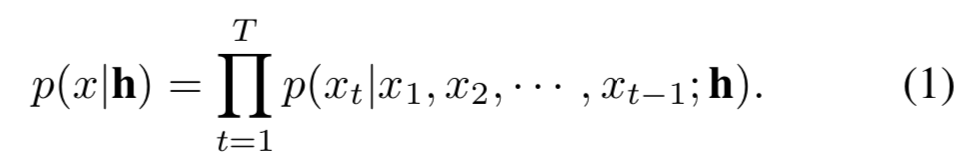
用空洞卷积和门控单元建模长时依赖,深度残差网络加速收敛(30层)。
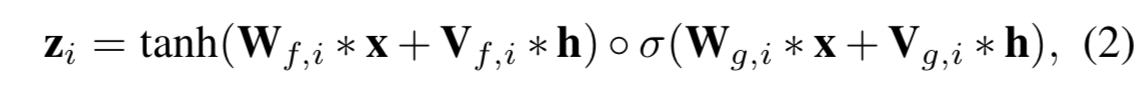
2.2 the limitation
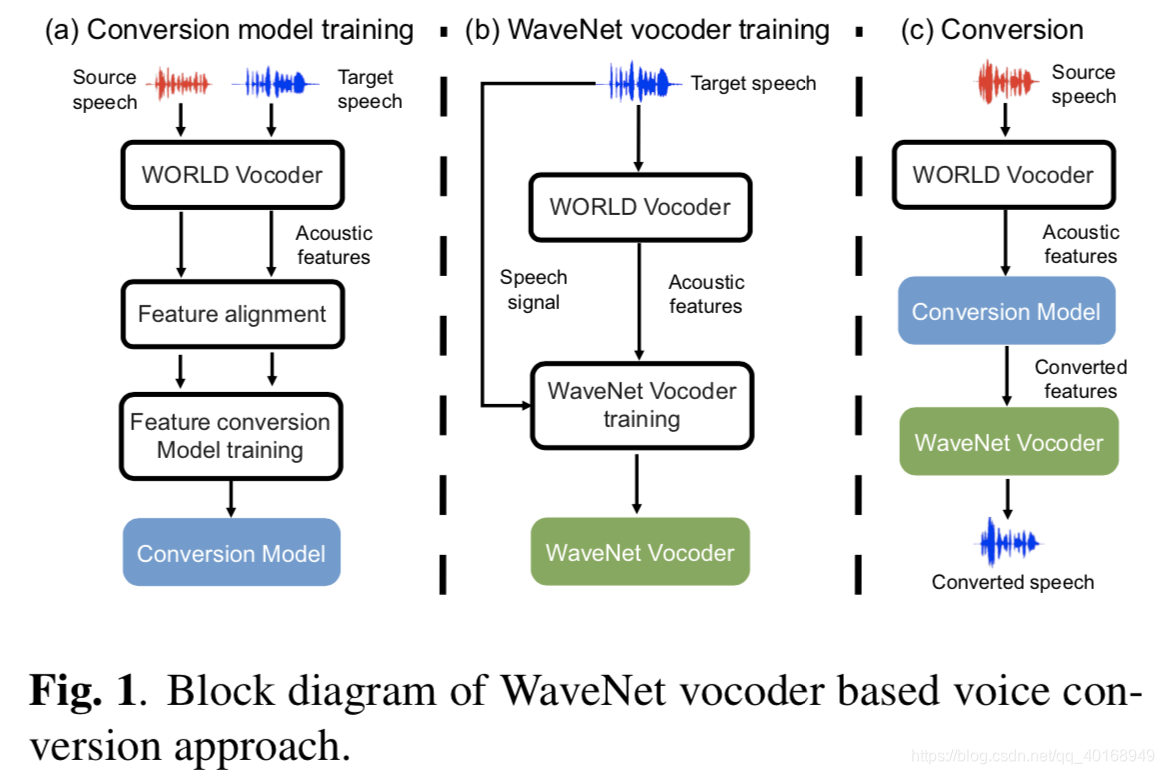
【23】用GMM架构+wavenet vocoder做语音转换,取得一个较好的结果。实现的过程如图1,训练阶段(a)(b),两个网络,conversion网络输入source 和target对齐的声学特征;wavenet vocoder输入target的声学特征作为local condition feature用于合成语音。
WORLD vocoder是一个高质量的实时语音合成系统。
因为run-time时(测试),converted feature和训练时原始的target feature不一样,导致合成语音中的噪声和不规则脉冲片段。
3. wavenet approach for voice conversion
本文提出用ppgs特征作为输入,ppgs是asr系统提取得到的与说话者无关的特征。
提取到ppgs: LD*N,D和N分别是特征维度和帧数,为了保证韵律不变,也提取到f0和vuv(voice/unvoice flag feature)特征。因此,local conditioning input表示为h=[L, F0, Fvuv]T
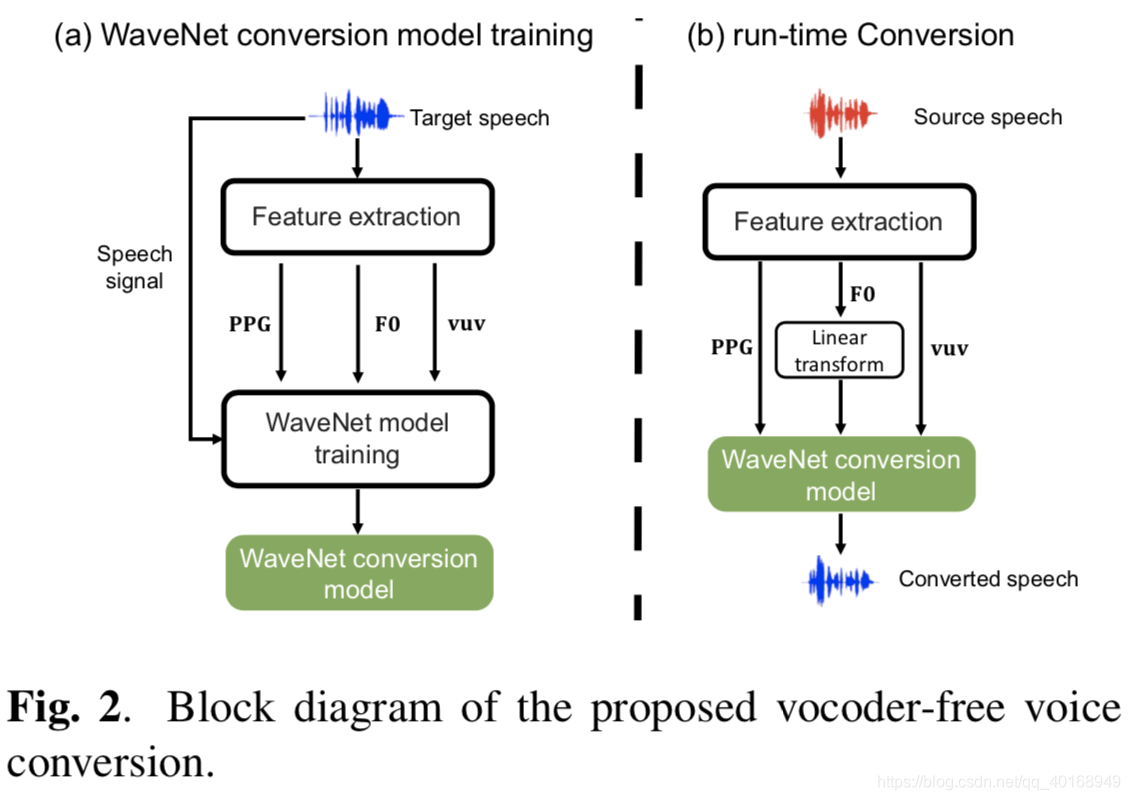 对提取到的f0做线性变换后输入网络,x是source,y是target,均值方差变换。
对提取到的f0做线性变换后输入网络,x是source,y是target,均值方差变换。
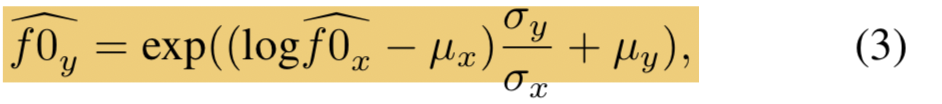
4. experimental setup
用cmu-arctic数据集做F2F,M2M,M2F和F2M的变换。500句用于训练,20句用于测试。
WORLD vocoder用于提取513维谱特征,F0和1维的非周期系数,帧移5ms。从谱中用SPTK计算40维的MCC,用WSJ训练提取42维的PPG,详细设置见【29】。
wavenet-PPG: 输入42维的PPG
wavenet-vc:输入42维的PPG,F0, vuv flag ,一共44维特征。
5. evaluations
客观测量用RMSE,值越小,说明生成的效果越好。
主观测量:AB,从两个生成的语句中选择一个更好的,自然度的测量;XAB,X是target的,A、B是生成的,对比决定哪一个和X更加相似,相似度的测量。(测试语句内容相同)
结果表明,wavenet-vc的性能在各方面都优于wavenet-PPG
wavenet-vc客观性能接近baseline,主观性能优于baseline。