来源:Thoughtworks洞见
作者:张思楚
最近几年 “软件研发效能” 成了业界的热词 ,频繁出现在各个行业大会,被各大厂、传统行业数字化部门、追求高效能的团队不断的提及并迭代,比如阿里的效能改进211愿景,腾讯的智研平台,百度工程能力白皮书。
那么为什么软件研发效能会成为热词,有哪些合适的软件研发效能指标呢? 本文想尝试回答这两个问题,并尝试构建一个根据团队上下文的软件研发效能推荐指标图表,同时介绍一些实际度量指标的案例。
一、为什么软件研发效能会成为热词?
咱们先看看现有的问题,与传统制造业相比,软件研发行业还很年轻,并没有达到传统行业的大规模流水线的生产方式,这解释了为什么没有一种统一的,被广泛认可的方法来衡量开发人员或研发小组的效能。
研发效能的度量很大程度上取决于公司的类型、规模、文化、与之合作的项目类型以及其它诸多因素。甚至某些小而精,依靠聪明才智和资深经验的创业团队,不用度量研发效能,团队依然非常高效。
很显然,10年前使用代码行数(Lines of code)来度量研发效能的方式已经不适用现代敏捷过程对软件研发的理解了。以前关注代码产出,而不是业务成果,以前关注个人绩效,而不是团队效能。
例如: 随着公司和开发人员向着价值驱动和基于团队开发方向的转变,代码行数不再具有任何意义。100行代码是否比20行好?行数是否告诉你取得了良好的进展,还是只是一个没有上下文的抽象指标?软件企业都在寻求其它有效的指标来度量研发效能。
同时,如今的软件行业已经不再是“以大吃小”的时代了,而是转变成了“以快吃慢”的时代。对于很多大型软件企业、传统行业的数字化部门。原本“大”是优势,现在却陷入了“大船难掉头”的尴尬。如何破局?研发效能具体来讲就是从需求转化成软件或者服务的能力。改善研发效能从某种方面也在试图解决“大船难掉头”的尴尬。
研发效能试图在解决度量和让研发变快的问题,那为什么会成为热词? 为什么最近几年各大厂、传统行业数字化部门、追求高效能的团队,都纷纷开始在研发效能领域发力,我认为这背后的原因有以下四点:
-
从外部技术视角来看:研发效能的土壤和环境已经就绪,类似高速移动网络的普及为智能手机和App培育了土壤和环境。4G移动网络的普及,让人们可以方便、快速的接入互联网,为智能手机和App铺好了路。现代软件研发的各个环节已经全面数字化,为研发效能的数据收集和度量做好了准备。比如: 电子看板管理任务状态,可数字化团队协作情况。Git等工具管理代码提交,可数字化开发过程。持续部署流水线管理发布过程,可数字化发布情况。DevOps云上编排、监控,可数字化产品运行状态。
-
从组织内部视角来看:很多公司都有“谷仓” (The Silo Effect),伴随着市场竞争的日趋激烈,“谷仓” 效应越发突出,局部优化但是无法全局优化,破局“大船难掉头”的尴尬势在必行。开发到测试的衔接完成了优化,但是当用户需求被设计好以后需要很长时间才能传递到开发,当产品上线后,线上问题需要很久才能从运维传递给开发并修复,影响了全局效率。基于协作流程的优化,打破流程中的“谷仓”,去除不必要的等待,让价值流动快起来,也是研发效能试图解决的问题。
-
从公司业务视角来看:组织发展规模化,技术驱动商业差异化,然而IT交付工厂化,难以应对市场的快速变化。传统企业对于IT投资,追求ROI最大化以及交付过程的透明化,从而缓解市场带来的压力,提升差异化竞争力。研发效能度量的核心是提供数据支撑这个目标的达成,基于数据持续改进。
-
从外部资源视角来看:以前业务的快速发展靠烧钱、人海战术换取更快的市场占有率,从而达到赢家通吃。那时候关心的是软件产品功能产出,研发效率可以用人、用钱填上。但是随着时间的推移,还有这么多从业人员可填吗?即便有了这么多人还能砸这么多钱吗?每年从事软件研发的毕业生有限,然而行业对人才的需求从没削减过,当抽干一线城市的人才,各个大厂已经开始热衷去二、三线城市的大学招人了。同时,随着产品利润的下降,需要更多的获客,回馈客户,需要开始节流了,节流就是研发效能的提升,同样的资源,同样的时间来获得更多的成果。
二、有哪些合适的软件研发效能度量指标呢?
上面基本回答了研发效能为什么会成为热词,那什么才是软件研发效能中合适的指标呢? 要度量哪些指标和数据呢?根据不同的场景和目标人群需要给出相应的度量指标。正如《关键对话》中建议的,需要根据信息接收者的兴趣点来构建沟通策略和沟通内容。
从研发效能DevOps角度 《Accelerate》 这本书给出了4个指标和评价标准。研发效能是一个比较大的话题,如何根据不同的关注点,给出不同的指标呢?Roy Osherove 的 “Lies, Damned Lies, and Metrics”也给出了很好的归类。根据我们在项目中的实际使用和经验总结,这里把当前常用的度量指标归类如下:
2.1 规划进度:评估进度,获取背景信息和上下文,知道任务何时完成,预测问题(未来),对问题复盘与回顾(过去)。
-
燃尽图 (每个迭代/每个发布) (Burn down chart sprint/release)
-
速率图 (Velocity chart)
-
标准差 (Standard deviation)
-
吞吐量(Throughput)
-
累积流程图 (Cumulative flow diagram)
-
控制图 (Control chart)
-
看板 在制品限制图 (Kanban WIP board)
2.2 快速反馈:持续集成,持续部署。
-
构建与部署速度 (Build & Deploy speed)
-
测试速度 (Test speed)
-
代码签审时长 (PR approval Time)
-
单元测试通过速率 (Unit tests passed)
-
集成测试通过速率 (Integration tests passed)
2.3 团队转型:使用特定指标来衡量不同工作方式的方法,可以影响行为,帮助改变人们的行为方式。也可以向管理层说明某些事情不合理,需要改变,或者说明需要更多的时间和预算。
-
结对编程的时长 (Pairing Time)
-
手工测试的时长 (Time spent manual testing)
-
代码签审时长 (PR approval Time)
-
修复失败构建的耗时 (Fix red build time)
-
修复Bug的耗时 (Cost of fixing bug in Dev/Prod)
-
测试覆盖率 (Coverage test count)
-
功效分配比率 (Effort allocation, New work / Unplanned work or rework / Other work)
2.4 辅助决策:可进行实验并不断寻找新的度量指标,帮助做决策。
-
前置时长 (Lead time)
-
发布出去的Bug数 (Escaped bugs 线上逃逸Bug数)
-
功效分配比率 (Effort allocation, New work / Unplanned work or rework / Other work)
-
交付的价值 (Valued delivered)
2.5 工程能力:4 key metrics 度量并找出团队工程实践的弱点。
-
变更前置时长 (Lead Time for Changes)
-
部署频率 (Deployment Frequency)
-
变更失败率 (Change Fail Rate)
-
服务恢复耗时(Time to restore service)
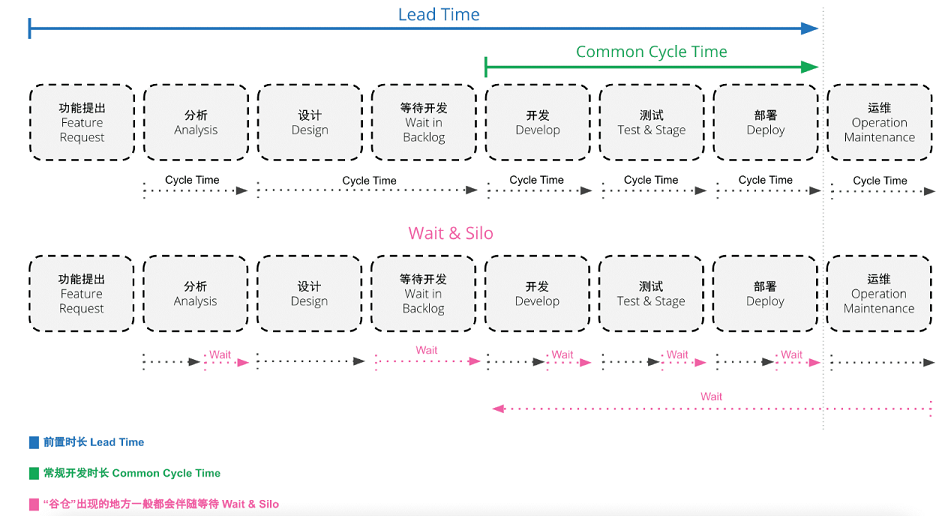
当您在为团队寻找研发效能指标时,其实并没有一个恒定不变的模板,需要分析多个因素,选择最适合您的指标,并与团队一起不断的使用它们,不断的根据价值交付为导向来修改和迭代。您自己团队的度量指标很可能与其他公司或团队的指标完全不同,这是完全正常的事情。因为正如前面提到的,研发效能的度量很大程度上取决于公司的类型、规模、文化、与之合作的项目类型以及其它因素。
三、我在一线开发过程中对效能的三个观察和观点
观点一:莫让度量变目标。
经济学家查尔斯·古德哈特在1975提出了古德哈特定律 : When a measure becomes a target, it ceases to be a good measure. “当一个度量本身成为目标时,它就不再是一个好的度量”。根据我们在项目中的观察和经验,古德哈特定律不光适用于经济学领域,一样适用于软件研发领域。
此定律在现实中的故事: 在法国殖民时期的越南,鼠患成灾,所以当地政府想出办法: 鼓励民众一起动手灭鼠并奖励灭鼠的民众,民众只需要上交死老鼠的尾巴就可以获得奖励。不久之后,越南的街头就出现了没有尾巴的老鼠,人们为了持续盈利,并没有杀死老鼠,而只是切下它的尾巴,等待它去生新老鼠给自己赚钱。
在正常情况下,「被切下的老鼠尾巴的数量」与「死去老鼠的数量」正相关,是一个好的指标。可是,一旦政府把「被切下的老鼠尾巴的数量」变成大家的优化目标,就会产生未曾预料到的结果。简单来说,这种度量变成了目标,驱动并产生了“上有政策,下有对策。”
在软件研发领域里,当你度量团队产出的代码行数并设置目标时,比如: 800行/人天,聪明的程序员,就会被驱动去优化「代码行数」并让它达到目标。比如: 多加点中间变量,多加点注释,多抽点方法和测试,目标不就达成了吗?(曾见过方法实现只有两行代码,注释20多行,而且在工程里经常看到类似的注释和方法。) 这种目标度量会给业务带来价值吗?
再比如你度量并设置团队每个迭代需要完成Story的点数或者个数的时候,比如: 20点/迭代,团队就会被驱动优化「Story点数」并让它达到目标。比如: BA和Dev在开迭代计划会议的时候多估算一点,多拆一些卡,目标不就达成了吗?(曾听到有团队的卡墙上有一张三个点的Team Building卡。Create DB这种操作原来估1个点,现在估3个点。为了不影响Cycle time的统计, 由于第三方依赖阻塞的卡,阻塞不好推动,也不想持续识别并推动了,移回Backlog。) 这种目标度量会给业务带来价值吗?它是否可以落实到具体的管理或技术实践中?
让度量指标和数据收集尽量真实,需要关注的是趋势和阻塞。在上面的案例里,统计每个迭代完成的卡,需要观察其趋势,一般情况下,每个迭代完成的卡,会在一个合理的区间内波动。(好比:用听诊器测量每分钟的心跳,非运动状态在60~100bpm次/分钟都属于正常。) 观察趋势并识别阻塞和阻塞的原因,加以针对性的治理,从而加速卡的流动,是度量的意义。而不是简单的和其他团队比较,粗狂的设定一个目标,驱使团队产生未曾预料的结果。
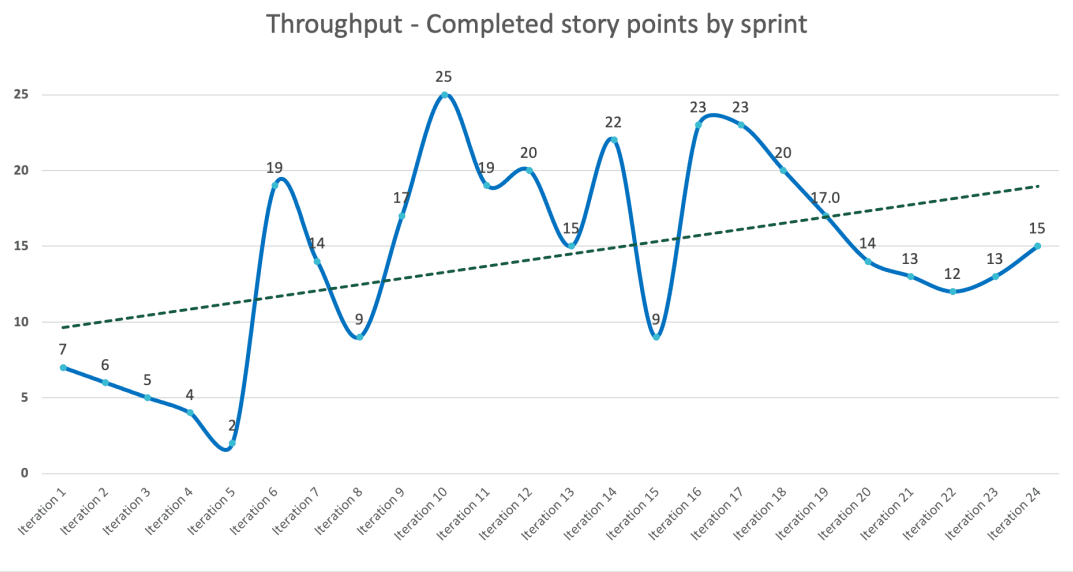
(某团队24个迭代所完成故事点统计图)
上图是一个项目24个迭代,每个迭代完成故事卡点数的统计图。由于团队所工作的业务领域没有变化,团队在此业务领域越来越熟练,所以总体交付趋势逐渐是上升的,交付速率逐步在一个合理区间内波动。观察并分析交付点数波动较大的迭代,分析并采取行动:
-
迭代7到迭代8,单个故事卡过大,拆卡质量不高,沟通复杂性增加,单卡开发时长增加,速率下降。行动:开发人员与业务分析师紧密沟通,在工作开始时将其拆解成更独立,更小的故事卡。
-
迭代14到迭代15,由于开发过程中所依赖的第三方API出现问题,无法按时对接,有累计超过10个点的卡延迟交付,不能贡献给本迭代,但会在下个迭代第三方API完工后完成,并体现在下个迭代。行动:及时的沟通和追踪依赖系统的情况并进行开发任务的调整,防止阻塞与等待的发生。
观察和观点二:无法拆解的度量指标,可能不是一个好的度量指标。
可拆解的指标和结果才是一个好的指标。变更前置时长 (Lead time for change) 或者需求交付时长,是一个很好的指标,能帮助并促进价值流的交付。但是你只是捕获需求提出的时间点和需求上线的时间点,并计算这两个点之间的耗时以此进行度量和阻塞识别,这是非常困难的,因为跨度太大,包括的因素太多,你很难看清楚到底发生了什么,到底在哪个阶段什么因素导致了阻塞。
杜邦分析法就是问题拆解的经典应用,拆解某个不容易看清楚的大问题到若干个子问题,通过分析若干子问题从而解决原来的大问题。比如分析并优化股本回报率这个一下看不清楚的大问题,拆解: 股本回报率(ROE)= 利润率 × 资产周转率 × 权益乘数 = (净收入 / 营业收入) × (营业收入 / 资产) × (资产/ 股东权益)从而将无法直接分析和优化的股本回报率,变得更容易分析和优化,同时再次钻取这些子问题,直到找出一个个更加显而易见的指标。
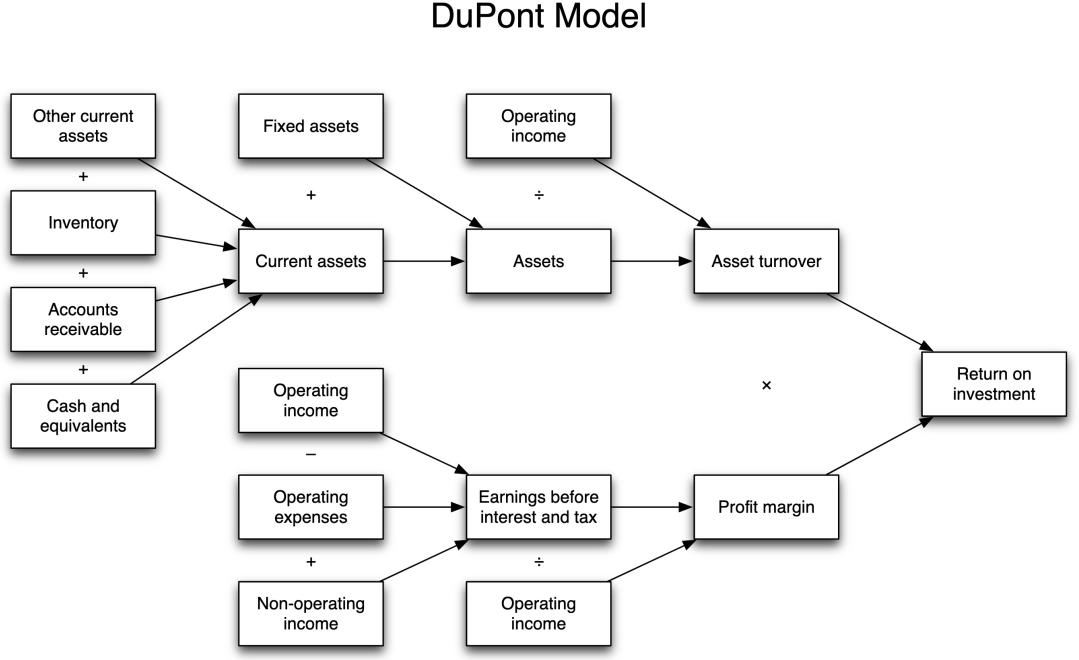
(杜邦分析模型)

(杜邦分析图)
那么为什么可以借鉴杜邦分析法来拆解研发效能?因为研发效能也是一个不容易看清楚的大问题,需要拆解到若干个子问题,通过分析若干子问题从而解决原来的大问题,同时它是一个可分阶段度量拆解的指标,并且每阶段都可以再次细分、拆解。
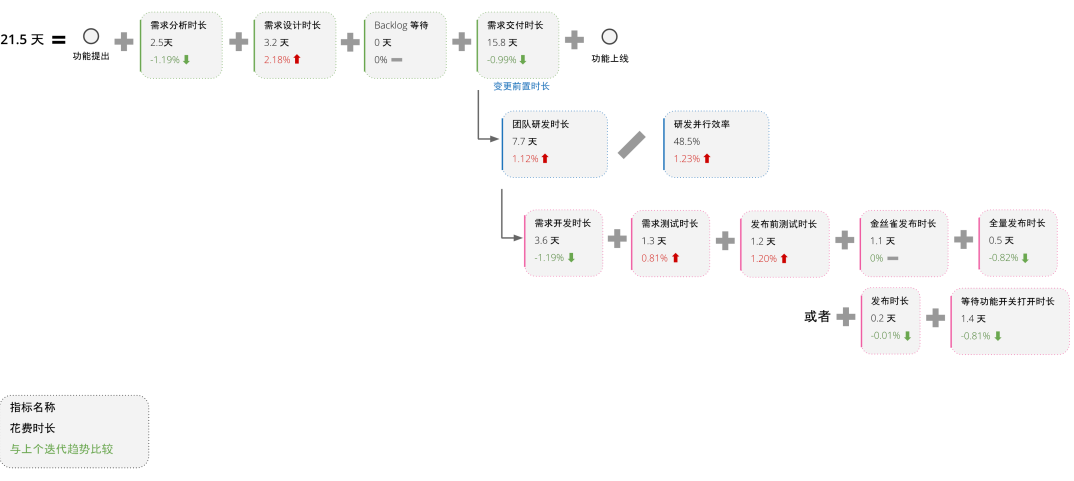
如上图,一个需求交付时长的拆解,通过不断的拆解找到更细化、具体的指标,找到优化点。
-
需求从提出到上线总花费时长为:21.5天 (工作日)=需求分析时长(2.5天)+需求设计时长(3.2天)+Backlog等待(0天)+需求交付时长(15.8天);
-
需求交付时长(15.8天)=团队研发时长(7.7天)/研发并行效率(48.5%),如果只有一个团队,并行效率为100%;
-
团队研发时长(7.7天)=需求开发时长(3.6天)+需求测试时长(1.3天)+发布前测试时长(1.2天)+金丝雀发布时长(1.1天)+全量发布时长(0.5天)。
在上个迭代找类似大小的需求,同样拆解各个工序指标的时长、占比,从趋势角度观察各个指标是上升了还是下降了。如果上升了,比如需求设计时长(3.2天)比上迭代类似大小需求的占比上升了2.18%,原因是什么,是否需要注意并改进什么? 由于这次的一个需求点没有分析透彻,导致了设计多次反馈修改,耗时加长。
行动:对于需求分析的产出增加更明确的检查列表,保证需求在送入设计之前已经被分析透彻了。所以当一个度量指标是一个可拆解的指标,它才可能是一个可落地到管理实践、技术实践的好指标。
观察和观点三:可持续扩展的度量,才可能驱动价值流的增效。
研发效能的度量经常从一个比较全局的指标开始,因为比较全局的指标,能更直观的体现交付价值,比如:上文的需求交付时长,但是不容易直观的看到问题,需要不断拆解,以此找到明确的问题点,把改进行动落地到管理实践、技术实践。与此同时指标也可以从局部开始,通过不断的扩展,驱动价值流增效。例如:起始的度量指标是《Accelerate》中的 Lead time, 度量从代码提交到部署到生产环境的时长。
原文第二章 Measuring Performance:
“The elevation of lead time as a metric is a key element of Lean theory. Lead time is the time it takes to go from a customer making a request to the request being satisfied. However, in the context of product development, where we aim to satisfy multiple customers in ways they may not anticipate, there are two parts to lead time: the time it takes to design and validate a product or feature, and the time to deliver the feature to customers. In the design part of the lead time, it’s often unclear when to start the clock, and often there is high variability. For this reason, Reinertsen calls this part of the lead time the “fuzzy front end” (Reinertsen 2009). However, the delivery part of the lead time—the time it takes for work to be implemented, tested, and delivered—is easier to measure and has a lower variability.”
原文说明了完整的 lead time 是从客户提出需求到功能上线、需求被满足的时间,但是由于需求分析、设计的起始时间不确定性大,难以统计,所以从确定性大的交付阶段开始统计,同时《Accelerate》这本书也是主打DevOps工程实践,更关注此方面的度量和指标。可以从这个指标开始,但是不应就此停留在这一阶段,这一阶段的耗时少了,说明团队的工程实践强,有完善的CI/CD,但不一定快速的响应了客户的需求。所以需要持续扩展度量,驱动价值流增效。
实际案例:团队度量了 lead time for change: 10分钟左右就从代码提交部署到生产环境了,但是观察发现一个功能的好几个代码提交等了几天才被部署,后来发现这些代码提交后进入了 pull request review,需要被客户团队review,但是客户团队并没有及时的 review 且合并 master 主分支,没有触发 pipeline,所以等了几天。团队可以自行 review 和 merge 的 pull request 都被很快的 review 合并了。此时团队扩展 lead time for change 的度量,起始时间从合并到主分支这个时间点,左移到 pull request 里的第一个提交,通过度量找到了和客户团队合作 pull request review 过程中可以优化的点,加速 pull request 的过程。
后来 lead time for change 的起始时间又被进一步左移,移动到了Story卡被移进 开发 列的时间,当Story被移进 开发 列就代表此功能的 lead time for change 开始计时了,从而了解开发过程中是否有和BA、QA沟通中的阻塞,有可优化的点。如果开发的功能被 feature toggle 所保护,在代码提交并部署上线后,feature toggle 没有被打开,也可以将 lead time 的结束时间右移,计算为feature toggle打开的时间点,可以分析是否业务决策的时间过长影响了功能上线。
以上的三个观察和观点:
-
莫让度量变目标。让度量指标和数据收集尽量真实,需要关注的是趋势和阻塞。
-
无法拆解的度量指标,可能不是一个好的度量指标。
-
可持续扩展的度量,才可能驱动价值流的增效。
希望能在您使用研发效能的指标与度量过程中带来帮助,通过设定的指标和对应的度量,找到软件研发过程中的阻塞,从而制定对应的行动,有效的落地到管理实践和技术实践。
四、三种项目类型及其推荐指标
软件研发效能的度量指标和工具链越来越丰富,主打数字化转型的企业在内部也开始建设自己的效能中台了,作为一线研发人员,面对这些眼花缭乱的指标、工具和平台,不经要问:我需要把这些东西都实践了吗?什么是我最需要做的,什么是我现阶段的优先级?
在前文中咱们提到,研发效能的度量很大程度上取决于公司的类型、规模、文化、与之合作的项目类型等因素。一个团队的度量指标很可能与其他公司或团队的完全不同,这是完全正常的事情。那么有没有一个稍微简单的方式能帮我们快速识别一些更适合现阶段的度量指标呢?
4.1 三种项目类型
在软件研发过程中,一般会经过三个阶段或者说接手三种类型的项目:绿地项目、棕地(黄地)项目、红地项目,(下文使用: 绿地、黄地、红地与之对应并简化代表),好像一个软件系统的生命周期。通过识别项目类型来找到此类型合适的度量指标,这可能是一个快速高效的方案。
-
绿地:“In software development, a greenfield project could be one of developing a system for a totally new environment, without concern for integrating with other systems, especially not legacy systems. Such projects are deemed higher risk, as they are often for new infrastructure, new customers, and even new owners.” 一个全新的项目可能是为一个全新的环境开发一个系统,而不用关心与其他系统的集成,尤其是与遗留系统的集成。
-
黄地:“Brownfield development is a term commonly used in the information technology industry to describe problem spaces needing the development and deployment of new software systems in the immediate presence of existing(legacy) software applications/systems. This implies that any new software architecture must take into account and coexist with live software already in situ. In contemporary civil engineering, Brownfield land means places where new buildings may need to be designed and erected considering the other structures and services already in place.” 在现有(遗留)软件程序/系统之下开发和部署新的软件系统。这意味着任何新的软件架构都必须考虑并与已运行的软件系统共存。
-
红地:软件系统进入维护期,并且不再开发新功能,只修复终端用户所发现的Bug,维护一段时间后,可能从此进入消亡期,不久后会被新系统所取代。
绿地与黄地的快速识别因素:是否考虑遗留系统的集成、共存。黄地与红地的快速识别因素:所维护的系统是否只修复Bug,不考虑增加新功能,或已经有计划会被取代。当快速区分项目的类型后,那么就可以根据项目的类型来设置度量指标。
4.2 三种项目类型的推荐指标
-
绿地推荐指标
相比其它类型,绿地项目研发团队是最可能接近项目终端用户,最可能开展端到端度量的,同时此类型的项目没有“历史包袱”,可以正常的进行架构设计,技术栈选择,在正常开销下完成部署流水线、线上监控告警、回滚、灾备等必要的线上保障措施。可选择 辅助决策、工程能力 这两类指标为首要指标,关注端到端的价值流,同时保证项目初期就将良好的工程实践落地。可选择 规划进度、快速反馈 为次要指标,辅助端到端价值流度量的达成。
首要指标和次要指标之间一般会相互影响,相互印证,次要指标的改善会带来首要指标的改善(比如:快速反馈-代码签审时长的改善,会带来辅助决策-前置时长的改善。)如果提升首要指标不好下手,可从次要指标开始。此时的 fuzzy front end 可定义为:终端用户向团队提出了某个需求的那一刻,可将用户需求被明确记录的那一刻认定为 lead time 的开始。
-
黄地推荐指标
项目已上线一段时间,有不少终端用户,并且要在原有系统上进行设计和开发,团队需要背负一定的“历史包袱”,架构和工程实践可能已经开始腐化。可选择规划进度、工程能力这两类指标为首要指标,关注交付任务的进度、架构和工程能力的改善,当工程能力提升后,会带来交付的加速。可选择辅助决策为次要指标,拓展功能交付所产生价值的度量,促进端到端的价值流度量。前文提到的:可持续扩展的度量,才可能驱动价值流的增效,是一个有效技法。此时的 fuzzy front end 可定义为:在业务交给开发的那一刻,故事卡得到了明确定义。
根据以往经验,接手此类项目一般会有很多协调和沟通工作,“谷仓” (The Silo Effect) 严重,一开始就想从需求源头度量比较困难,从交付延展至价值度量是一个更合适的方式。同时此类型的项目还伴随着自上而下的变革诉求(尤其发生在畅销的、长生命周期的产品项目上),此时可加入 团队转型、快速反馈 这两类指标为首要指标,协助完成变革诉求。
-
红地推荐指标
软件系统上线多年,稳定服务于终端用户,不再开发新功能,只修复Bug,可能不久后会被新系统所取代。产品团队很可能不想再投入更多的资源改善系统,只要能把重要的Bug修复,每个季度发布一次就行。可选择 规划进度 为首要指标,保证有良好的 Bug 修复吞吐量。如果产品团队希望增加部署频率,加快响应终端用户的Bug诉求,可选择 快速反馈 为次要指标,帮助加速发布周期从而快速响应终端用户的Bug诉求。此时的 fuzzy front end 可定义为:终端用户将 Bug 清晰地报告给客服人员的那一刻。
指标的选择和团队的上下文强相关,需根据团队具体的上下文来选择推荐的指标集,并裁剪指标集中的具体指标。
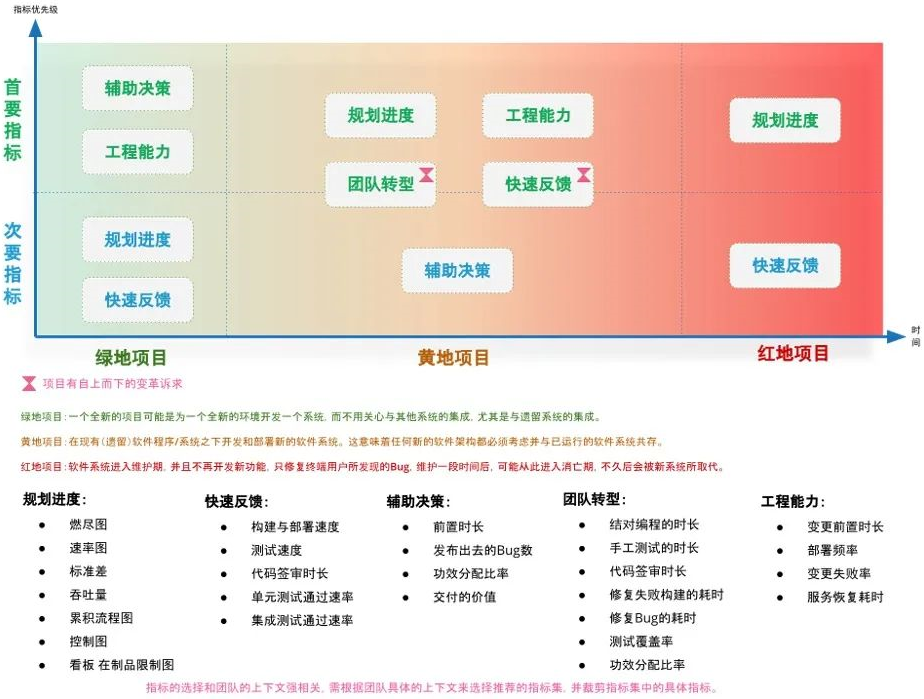
(基于项目类型的效能指标推荐图)
五、度量债与治理
伴随度量的开展和深入,项目同时也经历了一段时间的发展(由绿转黄,或由黄转红),你可能会得到一个宝贵的顿悟时刻度量债,绿地不开始度量,项目发展到了黄地或者红地的时候想度量了,就需要实现原来的度量(债务),拖延的时间越久相比一开始就度量所付出的代价就越高(利息)。
这两个特点非常类似现实中的债务,和常常提到的技术债也很相似。比如:系统想分析和统计一个请求在各个阶段所花费的时长从而进行优化,在最初的设计和实现时,不想花成本,牺牲未来的度量需求,满足当下的快速上线,没有为请求做一个TraceID,或者Tag、Bag,这样的属性,让其可以跟随请求经过各个系统,做好序列化和反序列化,那么当你想度量请求耗时的时候,很可能只能在请求端记录一个发出时间和返回时间,中间各个系统的处理时长基本无法获取和分析。
当你想加这个信息的时候,会发现牵连的系统太多了(网关, 反向代理, 服务 A、B、C、..., 消息队列, 数据库,等),工作量太大,甚至有些系统你可能还不知道。度量也类似:当项目还是绿地阶段,干系人较少,需求评审和设计流程短,此时牺牲度量需求,只管功能上线,没有统计终端用户的需求创建时间、需求评审和设计时间,只统计了故事卡被交给开发的那一刻,随着项目发展 (尤其是盈利项目,战略项目,需求和规模快速扩大的项目),干系人增多,需求评审和设计流程加长,此时再想统计终端用户的需求创建时间、需求评审和设计时间,可能你已无法知道故事卡在传给开发之前都经历了那些流程和阶段,所以此时再想度量,就会比绿地时所花费的代价大得多。
如何治理度量债?由于和技术债的相似性,可以借鉴技术债的治理方法,尽量只留下:谨慎故意的、谨慎无心的度量债。借鉴 Martin Fowler 的 Tech debt quadrant。

当你向团队提议说:“咱们来度量一下研发效能吧,看看有没有什么可以改善的?” 可能会得到下面的回答:
-
“我们没时间进行度量,就这样吧!”,此时团队是鲁莽并且故意的,团队知道这样做是会欠债,然而并不清楚欠了债的具体后果,这种情况可以增加流程、负责人来作为提醒。
-
“我们知道要度量,但是等这次发布之后就开始吧。”,此时团队是谨慎并且故意的,团队知道这样做是会欠债,而且也知道欠了债的具体后果,这种情况基本无法避免。
-
“什么是度量?怎么度量?”,此时团队是鲁莽并且无心的,团队不清楚什么是度量,不清楚如何进行度量,这种情况需要补充能力。
-
“现在我们终于知道该怎么度量了!”此时团队是谨慎并且无心的,团队知道度量这件事,但当时没有人知道如何度量,直到现在才明白如何度量。这种情况无法避免。