本文介绍使用tsfresh自动化提取时序特征的过程。不足之处,还望批评指正。
tsfresh是一个自动化提取时序特征的库。
● tsfresh Github:https://github.com/blue-yonder/tsfresh
● tsfresh 文档:https://tsfresh.readthedocs.io
图1:时序简易特征示意图
以KDD2022风电时序数据集为例,分享下tsfresh使用体验,风电训练集的时间长度是245天,每隔10分钟有采样样本,然后有134个风机,所以一共有134*245*144=4272520,约427w条数据。基础特征有10个左右。预测目标是有功功率Patv。
使用tsfresh的使用步骤如下:
前期训练阶段:
1. 数据准备:准备符合tsfresh输入格式的数据集;
2. 样本抽样:以步长s为间隔滑窗抽样;
3. 特征生成:对采样样本生成特征,并收集它们;
4. 特征选择:收集多个特征下的衍生特征,进行特征选择;
后期部署阶段:
1. 数据准备:准备符合tsfresh输入格式的数据集;
2. 特征选择:对滑窗样本生成特征,并收集它们;
一、前期训练阶段
喂入特征生成和特征选择前,数据要有x和y,其中x要有id、time和feature列。id是指时序id,time是时间顺序标识值,feature是特征列。y则要有1列是预测目标值,然后索引值是对应的时序id。图2所示的只是一个样本用例,你可以把x看作在时刻t下的滑窗时序数据,把y看作在时刻t下要预测的label。
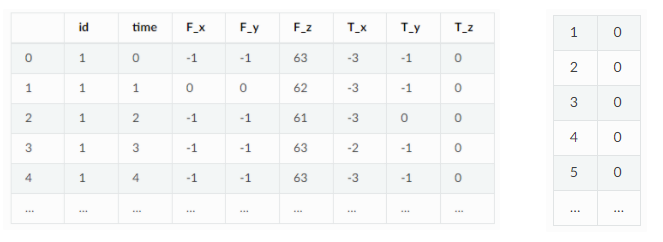
图2:用例x和y
注意,tsfresh不允许空值,所以待生成衍生特征的feature列要提前保证无空值。以风电数据为例,我们要基于Day和Tmstamp获取整型的time列。
data = pd.read_csv("./KDD2022/wtbdata_245days.csv")
data = data.fillna(0) # 填补空值
# 基于Day和Tmstamp获取整型的time列。
data = data.sort_values(['TurbID','Day','Tmstamp'], ascending=True)
day_num = len(data['Day'].unique())
turb_num = len(data['TurbID'].unique())
time_col = [j for i in range(turb_num) for j in range(int(len(data)/turb_num))]
data['time'] = time_col上面提到的只是个用例,实际上,我们会对数据做滑窗,所以样本用例x会非常多。特别是这里的风电数据,tsfresh也考虑到这点,所以提供了roll_time_series()。
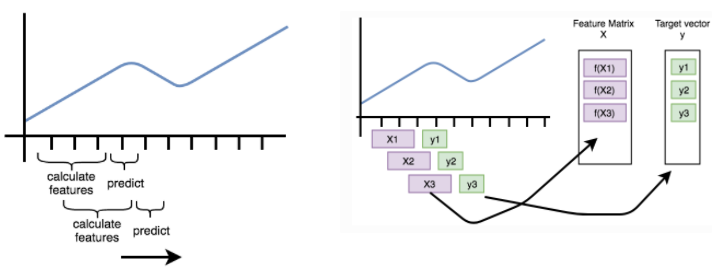
图3:滑动组织特征和标签
它的内部机制是针对每个id做滑窗,然后所有滑窗到的用例用新的id作为标识(新id的格式是(旧id,第几个time下滑窗数据)),新id和time作为联合key来区分不同的用例数据。虽然调用简单且速度较快,但若原始数据过长,一次性把所有滑窗数据都展开合并,会占用很多的内存。如果要使用,建议按需调整参数:max_timeshift,控制最大的窗口大小,不然它会随着滑窗步进,生成的用例长度会不断增加,内存占用也随着滑窗线性增加。感兴趣可以访问:https://tsfresh.readthedocs.io/en/latest/text/forecasting.html。
所以这里我自定义滑动步长和窗口长度,均匀采样用例x和y,然后依次喂入用例x进extract_features()获取特征后,收集所有用例的特征和标签后,再喂入select_features()选择出相关的特征。这样的好处在于节省空间,但速度会略微慢些。
# 准备训练集
trn_data = data[['TurbID','time','Patv','target']]
trn_data.drop(index = trn_data[trn_data['target'].isnull()].index, axis=0, inplace=True)
trn_data = trn_data.reset_index(drop=True)
time_list = trn_data['time'].unique()
min_time = 144*3 # 最小的采样起点
sample_freq = 5 # 采样间隔 大概25%的数据
sample_idxs = [i for i in np.arange(1,len(time_list), sample_freq) if i >= min_time]
sample_times = time_list[sample_idxs]
print('Total Sample Number: ', len(sample_times))
settings = EfficientFCParameters()
trn_data_x, trn_data_y = [], []
for i, end_t in enumerate(sample_times):
print(f'Progress:{i+1}/{len(sample_idxs)}')
# 获取抽样片段
sample_data = trn_data[(trn_data['time']>end_t-min_time) & (trn_data['time']<end_t)]
# 针对给定片段准备x和y
cur_time = max(sample_data.time)
sample_data_x = sample_data[['TurbID','time','Patv']]
sample_data_y = sample_data[sample_data['time']==cur_time][['TurbID','target']].set_index('TurbID')['target']
# 抽取特征
extracted_features = extract_features(sample_data_x, column_id="TurbID", column_sort="time", disable_progressbar=True, default_fc_parameters=settings, n_jobs=10)
extracted_features.to_csv(f'/home/notebook/data/group/intention_rec/TimeSeries/KDD2022/extract_feats/i{i}_end_t{end_t}_extracted_features.csv')
sample_data_y.to_csv(f'/home/notebook/data/group/intention_rec/TimeSeries/KDD2022/extract_feats/i{i}_end_t{end_t}_sample_data_y.csv')
# 收集多个片段下的衍生特征和y
trn_data_x.append(extracted_features)
trn_data_y.append(sample_data_y)
# 合并多个片段下的衍生特征和y
trn_data_x = pd.concat(trn_data_x, axis=0).reset_index(drop=True)
trn_data_y = pd.concat(trn_data_y, axis=0).reset_index(drop=True)
# 选择特征,获取优质特征集
impute(trn_data_x)
trn_x_selected = select_features(trn_data_x, trn_data_y, n_jobs=5)
kind_to_fc_parameters=tsfresh.feature_extraction.settings.from_columns(trn_x_selected) # 抽取选择后的特征配置
print('Selected Features Number: ', len(trn_x_selected.columns))extract_features()内的default_fc_parameters可以配置不同的特征生成策略:
参考文档:https://tsfresh.readthedocs.io/en/latest/text/feature_extraction_settings.html
● ComprehensiveFCParameters:包括所有没有参数的特征和所有有参数的特征,每个特征都有不同的参数组合。如果您根本不提交default_fc_parameters ,这是extract_features的默认值;
● MinimalFCParameters:仅包含少数功能,可用于快速测试。这里的特征“最小”;
● EfficientFCParameters:与ComprehensiveFCParameters中的大部分功能相同,但没有“high_comp_cost”。如果运行时主要考虑性能,则可以使用此功能。
当然你也能自选特征和参数,以下例子说明只有temperature和pressure两个特征会分别生成均值和最大最小值特征:
kind_to_fc_parameters = {
"temperature": {"mean": None},
"pressure": {"maximum": None, "minimum": None}
}然后赋值给kind_to_fc_parameters参数上,这样的话,会覆盖default_fc_parameters的配置,不然的话,特征配置会默认使用default_fc_parameters。
使用下来,我用EfficientFCParameters能在风电Patv特征上获取到700多个特征,特征选择后剩下500多个特征。在n_jobs=5下,内存占用是40个G左右,耗时近7个小时(共接近7k个用例,还仅仅是20%左右的数据,如果是全量数据,更耗时)。
但由于500多个特征,还是太多了,tsfresh提供selection.select_features()是调用calculate_relevance_table(),计算特征矩阵X中包含的特征相对于目标向量y的相关性表(主要由p值决定,越低意味着越重要)。所以,为了进一步减少生成特征的量,我基于p值获取前排的特征作为最终要衍生的特征集:
relevance_table = calculate_relevance_table(trn_data_x, trn_data_y, n_jobs=5)
# 选了前59个top p值小的特征
select_feats = relevance_table[relevance_table.relevant].sort_values('p_value', ascending=True).iloc[:59]['feature'].values
kind_to_fc_parameters=tsfresh.feature_extraction.settings.from_columns(trn_x_selected[select_feats]) # 抽取选择后的特征配置
np.save('../kind_to_fc_parameters_top59.npy', kind_to_fc_parameters)其中relevance_table的样子如下:

挑选后top59个特征配置如下:
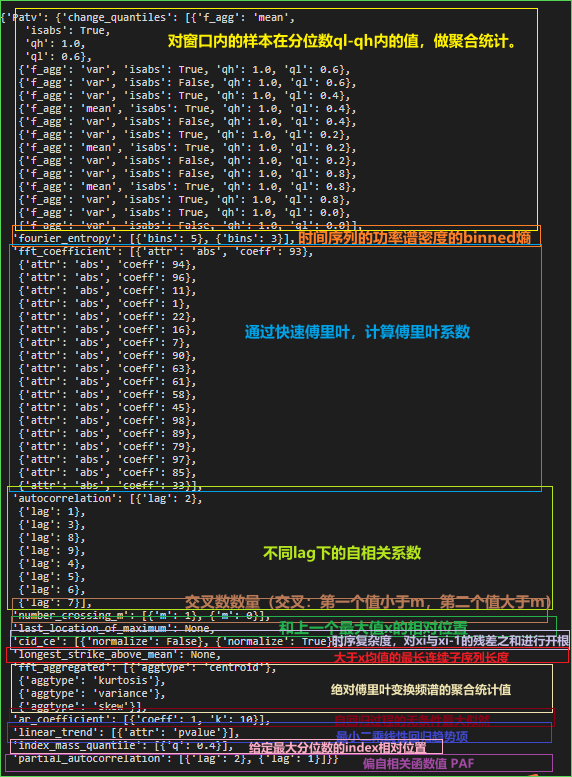
有兴趣了解内部有哪些特征的朋友,可以访问:https://tsfresh.readthedocs.io/en/latest/text/list_of_features.html。
二、后期部署阶段
部署时,就把之前保存好的特征配置传入kind_to_fc_parameters就行。需要注意,由于现在特征生成的范围缩小了,所以即使单步滑窗,也只需要7-8小时就能完成全量数据集的时序特征生成工作。
data = pd.read_csv("./KDD2022/wtbdata_245days.csv")
data = data.fillna(0) # 填补空值
# 增加time一列
data = data.sort_values(['TurbID','Day','Tmstamp'], ascending=True)
day_num = len(data['Day'].unique())
turb_num = len(data['TurbID'].unique())
time_col = [j for i in range(turb_num) for j in range(int(len(data)/turb_num))]
data['time'] = time_col
# 获取预准备好的特征生成配置
saved_kind_to_fc_parameters = np.load('./kind_to_fc_parameters_top59.npy', allow_pickle='TRUE').item()
# 针对单片段生成特征
time_list = data['time'].unique()
min_time = 144*3 # 最小的采样起点
sample_freq = 1 # 采样间隔
sample_idxs = [i for i in np.arange(0,len(time_list), sample_freq) if i >= min_time-1]
sample_times = time_list[sample_idxs]
print('Total Sample Number: ', len(sample_times))
# settings = EfficientFCParameters()
trn_data_x, trn_data_y = [], []
for end_t in tqdm(sample_times):
# 获取抽样片段
sample_data = data[(data['time']>end_t-min_time) & (data['time']<=end_t)]
# 针对给定片段准备x和y
cur_time = max(sample_data.time)
sample_data_x = sample_data[['TurbID','time','Patv']]
# 抽取特征
extracted_features = extract_features(sample_data_x, column_id="TurbID", column_sort="time", disable_progressbar=False, kind_to_fc_parameters=saved_kind_to_fc_parameters, n_jobs=5)
extracted_features = extracted_features.reset_index().rename(columns={'index':'TurbID'})
extracted_features['time'] = cur_time
# 收集多个片段下的衍生特征和y
trn_data_x.append(extracted_features)推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书