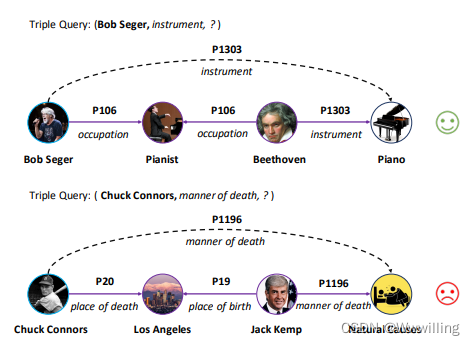
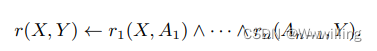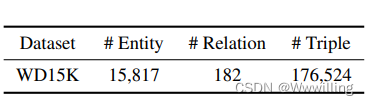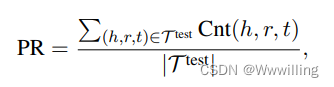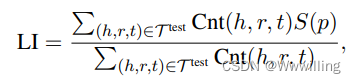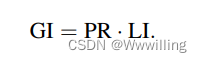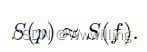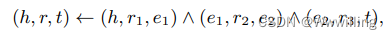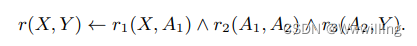大多数现有的多跳推理模型都认为输出路径是合理的,并且非常重视链路预测的性能。例如,MultiHop (Lin et al, 2018) 使用强化学习来训练智能体搜索知识图谱。智能体找到的路径被认为是对预测结果的合理解释。但是手动标注之后,我们发现超过60%的路径是不合理的。如图 1 的下部所示,给定一个三元组查询(Chuck Connors, manner of death, ?),多跳推理模型通过推理路径(紫色实线箭头)找到正确的尾部实体 Natural Causes 。尽管该模型正确地完成了缺失的三元组,但这种推理路径是有问题的,因为死亡方式与一个人的出生或死亡城市无关。可解释性失败的原因主要是因为许多人在洛杉矶出生和死亡的同一个地方,自然原因是占主导地位的死亡方式。因此,路径仅在统计上与查询三元组相关,无法提供可解释性。在实验中,我们发现这种不合理的路径在多跳推理模型中无处不在,这表明迫切需要进行可解释性评估。
在本文中,我们提出了一个统一的框架来自动评估多跳推理模型的可解释性。与以往的工作主要依靠案例研究(Wan et al, 2020)来展示模型的可解释性不同,我们旨在通过计算模型生成的所有路径的可解释性分数来进行定量评估。具体来说,我们定义了三个指标:路径召回、局部可解释性和评估的全局可解释性(详见第 4.2 节)。然而,给每条路径一个可解释性分数是很耗时的,因为多跳推理可以给出的可能路径的数量非常大。为了解决这个问题,我们提出了一种近似策略,通过忽略仅剩下关系的实体,将推理路径抽象为有限的规则(详见等式 6 和 7)。通过这种方式获得的规则总数远小于路径数,我们将规则的可解释性分数分配给其对应的路径。
我们探索了两种方法给每个规则一个可解释性分数,即手动注释和规则挖掘方法自动生成。前者是本文的重点。具体来说,我们邀请注释者手动注释所有可能规则的可预测性分数,以建立手动注释基准(A-benchmark)。这个标记过程也面临一个挑战,即,可解释性是高度主观的并且难以标注。不同的注释者可能会给出不同的解释。为了减少变化,我们为注释者提供了许多可解释的选项,而不是要求他们给出直接分数。此外,对于每个样本,我们要求十个注释者进行注释,并以他们的平均分数作为最终结果。除了 A-benchmark,我们还提供了基于规则挖掘方法的基准(R-benchmark)(Meilicke et al, 2019)。这些基准使用挖掘规则的置信度作为规则的可解释性分数。这种方法不如手动标注准确,但可以自动推广到大多数 KG。
在实验中,我们验证了我们的基准 BIMR 的有效性。具体来说,我们使用采样注释方法获得每个模型的可解释性,并将其与我们的 A 基准生成的结果进行比较。实验结果表明,它们之间的差距很小,这表明近似策略对结果的影响很小。此外,我们在基准测试中运行了九个具有代表性的基线。实验结果表明,现有多跳推理模型的可解释性不太令人满意,距离我们的 A-benchmark 给出的上限还很远。具体来说,即使是最好的多跳推理模型,其可解释性仍然比上限低 51.7%。这提醒我们,在多跳推理的研究中,我们不仅要关心性能,还要关心可解释性。此外,我们发现基于规则的最佳推理方法 AnyBURL (Meilicke et al, 2019) 在性能和可解释性方面明显优于现有的多跳推理模型,这为我们指明了未来可能的研究方向,即如何更好地将规则合并到多跳推理中。
相关工作
多跳推理
多跳推理模型可以在执行三重完成时提供可解释的路径。大多数现有的多跳推理模型都是基于强化学习(RL)框架。其中,DeepPath (Xiong et al, 2017) 是第一个正式提出和解决使用 RL 进行多跳推理任务的工作,它启发了很多后来的工作,例如 DIVA (Chen et al, 2018) 和 AttnPath (王等人,2019)。 MINERVA (Das et al, 2018) 是一种具有广泛影响的端到端模型,可解决多跳推理任务。在该模型的基础上,M-Walk (Shen et al, 2018) 和 MultiHop (Lin et al, 2018) 分别通过离策略学习和奖励塑造来解决奖励稀疏问题。此外,还有一些其他模型,例如 DIVINE (Li and Cheng, 2019)、R2D2 (Hildebrandt et al, 2020)、RLH (Wan et al, 2020) 和 RuleGuider (Lei et al, 2020)分别从模仿学习、辩论动力学、分层强化学习和规则引导四个方向进行-hop推理。 CPL (Fu et al, 2019) 和 DacKGR (Lv et al, 2020) 通过向 KG 添加额外的三元组来增强模型的效果。
基于规则的推理
与多跳推理类似,基于规则的推理也可以执行可解释的三元组,只是它们给出了相应的规则而不是特定的路径。 基于规则的推理可以分为两类,即基于神经的模型和规则挖掘模型。 其中,基于神经的模型(Yang et al, 2017; Rocktäschel and Riedel, 2017; Sadeghian et al,2019; Minervini et al, 2020)在执行三重补全的同时给出相应的规则,而规则挖掘模型(Galárraga et al, 2020) al, 2015; Om ran et al, 2018; Ho et al, 2018; Meilicke et al, 2019)首先挖掘规则,然后使用它们完成。
**知识图(KG)**定义为有向图 K G = { E , R , T } KG = \{E, R, T \} KG={
E,R,T},其中 E E E 是实体集, R R R 是关系集, T = { ( h , r , t ) } ⊆ E × R × E T = \{(h, r, t)\} ⊆ E × R × E T={(h,r,t)}⊆E×R×E 是三元组的集合。
多跳推理旨在通过可解释的链接预测来完成 KG。 形式上,给定一个三元组查询 ( h , r , ? ) (h, r, ?) (h,r,?),它不仅需要预测正确的尾部实体 t t t,还需要给出一条路径 ( h , r , t ) ← ( h , r 1 , e 1 ) ∧ ( e 1 , r 2 , e 2 ) ∧ ⋅ ⋅ ⋅ ∧ ( e n − 1 , r n , t ) (h, r, t) ← (h, r_1, e_1)∧(e_1, r_2, e_2) ∧ · · · ∧ (e_{n-1}, r_n, t) (h,r,t)←(h,r1,e1)∧(e1,r2,e2)∧⋅⋅⋅∧(en−1,rn,t) 作为解释。
基于规则的推理可以被认为是广义的多跳推理,也可以在我们的基准上进行评估。 给定一个三元组查询 ( h , r , ? ) (h, r, ?) (h,r,?),它需要预测尾部实体 t t t 并给出一些有信心的 Horn 规则作为解释,其中规则 f f f 的形式如下:
其中大写字母表示变量, r ( . . . ) r(...) r(...) 是规则的头部, r 1 ( . . . ) r_1(...) r1(...) 的合取,···, r n ( . . . ) r_n(...) rn(...) 是规则的主体, r ( h , r ) r(h , r) r(h,r) 等价于三元组 ( h , r , t ) (h, r, t) (h,r,t)。 为了得到与多跳推理任务相同的路径,我们按照置信度降序对这些规则进行排序,并在 KG 上进行匹配。
我们基于 Wikidata (Vrandeciˇ c and Krötzsch´, 2014) 以及广泛使用的 FB15K-237 (Toutanova et al, 2015) 策划了一个可解释的数据集 WD15K。 我们的目标是利用 Wikidata 中的阅读友好关系,同时保持 FB15K-237 中的实体不变。 我们依靠 Wikidata 中每个实体的 Freebase ID 属性来连接两个来源,我们的数据集 WD15K 的最终统计数据列在表 1 中。我们对其进行洗牌并使用 90%/5%/5% 作为我们的训练/验证/ 测试集。 由于篇幅限制,我们将数据集构建的详细步骤放在补充材料中(附录 A)。
表 1:WD15K 的统计数据。 三列分别表示实体、关系和三元组的数量。
评估框架
我们提出了一个通用框架,用于定量评估多跳推理模型的可解释性。 形式上,测试集中的每个三元组 ( h , r , t ) (h, r, t) (h,r,t) 都被转换为一个三元组查询 ( h , r , ? ) (h, r, ?) (h,r,?)。 该模型需要预测 t t t 和可能的推理路径。 因此,我们计算模型的可解释性分数,该分数基于三个指标定义:路径召回 (PR)、局部可解释性 (LI) 和全局可解释性 (GI)。
其中 C n t ( h , r , t ) Cnt(h, r, t) Cnt(h,r,t) 是一个指示函数,表示模型是否能找到从 h h h 到 t t t 的路径。 如果至少可以找到一条路径,则函数值为 1,否则为 0。PR 是必要的,因为对于大多数模型,并非每个三元组都可以找到从头实体到尾实体的路径。 对于基于 RL 的多跳推理模型(例如 MINERVA),光束大小beam size是对 PR 有直接影响的关键超参数。 光束尺寸越大,模型可以找到的路径就越多。 然而,在现实中,它不能设置为无限。 也就是说,每个三元组查询的路径数 ( h , r ,?) (h,r,?) (h,r,?)都有一个上限。 另一方面,可能没有从 h h h 到 t t t 的路径,或者我们可能无法为每个规则匹配 KG 上的真实路径。 这导致 C n t ( h , r , t ) = 0 Cnt(h, r, t) = 0 Cnt(h,r,t)=0。
**局部可解释性(LI)**用于评估模型找到的路径的合理性。 它被定义为
其中 p p p 是模型找到的从 h h h 到 t t t 的最佳路径(得分最高的路径), S ( p ) S(p) S(p) 是该路径的可解释性得分,将在下一节介绍。
Global Interpretability (GI) 评估模型的整体可解释性,因为 LI 只能表达模型找到的路径的合理程度,而没有考虑可以找到多少条路径。 我们将 G I GI GI 定义如下:
我们总结并比较了 LI 和 GI。 具体来说,LI 可以反映所有可以找到的路径的可解释性,而 GI 则评估模型的整体可解释性。
近似可解释性分数
基于 WD15K 和上述评估框架,我们可以构建基准来定量评估可解释性。 然而,由于路径数量巨大,评估框架中的 S ( p ) S(p) S(p) 难以获得。 因此,在具体构建之前,需要做一些准备工作,即路径收集和逼近策略。
路径集合。 这一步旨在收集从 h h h 到 t t t 的所有可能路径,以便我们的评估框架可以涵盖多跳推理模型的各种输出。 具体来说,我们首先为训练集中的每个三元组 ( h , r , t ) (h, r, t) (h,r,t) 添加反向三元组 ( t , r − 1 , h ) (t, r^{−1}, h) (t,r−1,h)。 然后,对于 WD15K 中的每个测试三元组 ( h , r , t ) (h, r, t) (h,r,t),我们使用广度优先搜索 (BFS) 在长度为 3 内的训练集上搜索从 h h h 到 t t t 的所有路径,即路径中最多存在三个关系,广泛用于多跳推理模型(例如,MultiHop)。 因为跳数过多会大大增加搜索空间,降低可解释性。 经过去重后,我们得到了最终的路径集 P P P,其中包含大约 1600 万条路径,它涵盖了多跳推理模型可能发现的所有路径。
近似优化。 我们提出了一种近似策略,以避免在大量路径 P P P(即 1600 万条)上使用不切实际的符号或计算。 根据观察,我们发现路径的可解释性主要来自规则而不是特定实体。 因此,我们将每条路径 p ∈ P p ∈ P p∈P 抽象为其对应的规则 f f f,并使用规则可解释性得分 S ( f ) S(f) S(f) 作为路径可解释性得分 S§,即
形式上,对于路径 p p p
我们将其转换为以下规则 f f f
经过这样的转换,我们将 P P P 转换为一组规则 F F F。由于规则是实体独立的,所以 F F F 的大小减少到 96,019,我们只需要给每个规则 f ∈ F f ∈ F f∈F 一个可解释的分数 S ( f ) S(f) S(f) 来构建基准。
接下来,我们将介绍两种获取规则可解释性分数的方法。
使用手动注释进行基准测试
我们用可解释性分数手动标记 F F F 中的每个规则,以形成手动注释基准(A-benchmark)。 本次benchmark的具体构建过程可以分为剪枝优化和手工标注两步。 我们将分别详细介绍这两个部分。