1.简介
Knuth-Morris-Pratt 算法,简称 \text{KMP}KMP 算法,由 \text{Donald Knuth}Donald Knuth、\text{James H. Morris}James H. Morris 和 \text{Vaughan Pratt}Vaughan Pratt 三人于 19771977 年联合发表。其经常被用于求解字符串匹配算法。
对于暴力匹配算法,让模式字符串 needle 与待匹配主串 haystack 的所有长度为 mm 的子串均匹配一次。如此造成的开销是巨大的,其时间复杂度为O(m*n),空间复杂度为O(1)。
当模式串和待匹配串发生失配时,在暴力匹配算法中,其下一步是完全回退模式串再重新匹配。这样做的好处是简单易于理解,但是却也完全放弃了已匹配的字符中的可用信息。
KMP算法的核心在于next数组,next中保存了当前位置匹配失配后,其下一步应该回退多少步,有效的利用了已有的信息。其时间复杂度为O(n+m),空间复杂度为O(m)。
2.代码
即使看起来不太好理解求next的原理,但是其代码却十分的简洁,就几行代码。
int GetNext(char ch[], int length, int next[]){
next[1] = 0;
int i = 1, j = 0;
while(i <= length){
if(j==0 || ch[i] == ch[j]){
next[++i] = ++j;
}else{
j = next[j];
}
}
}2.1原理
2.2.1前缀后缀
对于失配时回退多少的问题,就要理解前缀和后缀的概念。假如当前匹配到箭头所指的位置,发现A和B并不相等,那么暴力法需要将箭头重新移动到模式串首(黄色串)A。

而实际上我们发现箭头前面的字符串串头和串尾(两个白色框)是相同的,因此实际上我们将箭头移动至相同的字符串串头的白色框就可以继续匹配下去,这两个框就叫做前缀和后缀。

在该视频中有对该算法的详细讲解「天勤公开课」KMP算法易懂版_哔哩哔哩_bilibili
2.2.2求next的代码解释
next数组就是记录当前最长公共子串(即最长前缀)的长度加一的大小。
next[1]=0;首先是模式串的第一个字符,由于其前面没有字符,前缀为0,但是我们习惯上将第一位的前缀记为-1,在加上一之后得到next[1]=0。后续的前缀为0, 当作0 + 1, 也就是说0 只出现在串首。
int i = 1, j = 0;i 指向当前位置的模式串失配的前一个位置。j 指的是上一个位置的最长前缀 + 1。
if(j==0 || ch[i] == ch[j]){
next[++i] = ++j;
}else{
j = next[j];
}该代码是求next数组的核心,其判断条件 j == 0 即模式串上一个位置的前缀为-1(串首),ch[i] == ch[j] 即模式串当前位置与模式串上一位置的前缀后一位匹配,如图:
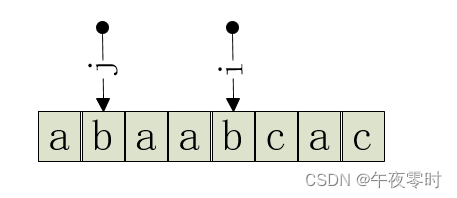
此时,i 指向当前位置的模式串失配的前一个位置,即 c 发生失配,i 指向b。j 指的是上一个位置的最长前缀 + 1,即abaa的前缀为1,j 指向2。因此 c 对应位置字串abaab的前缀就应该是前一个的基础上加一。
故next[++i] == ++j。
上述为当前位置的字符匹配上的情况,那么如果当前位置未匹配上会发生什么呢。此时b和a失配。
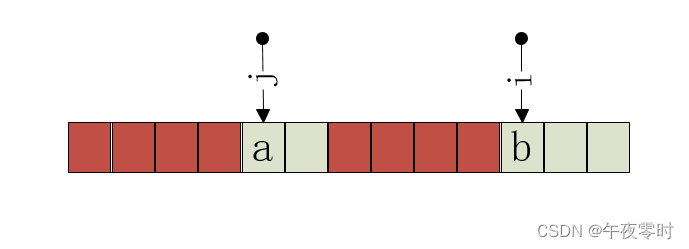
但是j中保存着 前四个字符组成的前缀长度。假设为长度为1。

由红色前缀后缀相同,蓝色前缀后缀相同,推论出红色的后缀部分也应该有蓝色的结构,即

因此当字符失配时,令j = next[j],就得到一个更小的前缀(蓝色),然后比较ch[j] == ch[i],实际上是再比较
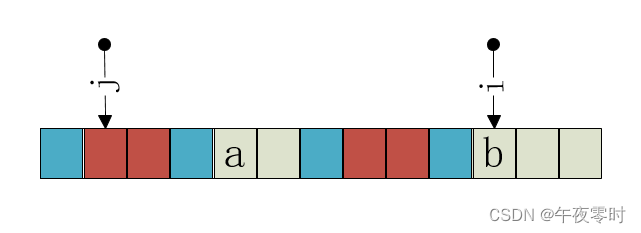
如果i 和 j 匹配上了next[++i] = ++j; 如果未匹配上继续向前寻找更小的前缀,直到找到串首即 j == 0。
关于next数组求解的视频KMP算法之求next数组代码讲解_哔哩哔哩_bilibili
2.2总结
简而言之,求next数组分两种情况:
当前 i 指向的字符和前一位置的前缀的后一个字符匹配成功,当前位置的最大前缀等于上一位置最大前缀 + 1,i 和 j 分别向后移一位。
当前 i 指向的字符和前一位置的前缀的后一个字符匹配不成功,向前寻找到一个更小的前缀,由于前后缀相同,所以更小的前缀保存在next[j]中。