原文标题:New Directions in Automated Traffic Analysis
原文作者:Jordan Holland; Paul Schmitt; Nick Feamster; Prateek Mittal
发表会议:CCS 2021
原文链接:https://dl.acm.org/doi/abs/10.1145/3460120.3484758
中文标题:自动化流量分析的新方向
1 Motivation
为了让目前在网络流量分析领域的:特征选择和表示、模型选择和参数调整工作自动化,作者提出了nPrintML(nPrint与AutoML的结合)。在nPrint中,作者提出了一种原始流量数据的表征方式,原始pcap文件经过nPrint处理后,可以直接作为后面机器学习模型的输入。同时结合AutoML技术,使得数据预处理–>模型选择–>超参数调整形成一条龙自动服务。
2 论文主要工作
- 提出了nPrint,一个可以对原始流量数据进行处理,从而形成一个标准化的数据表示格式,可以直接用作后续机器学习模型的输入
- 结合了AutoML,自动化了模型选择和超参数调整的工作
- 在多个任务上测试了nPrintML系统,证明节省了大量人工精力的同时达到了良好的性能
3 模型实现
nPrintML模型的整体结构如下图所示:
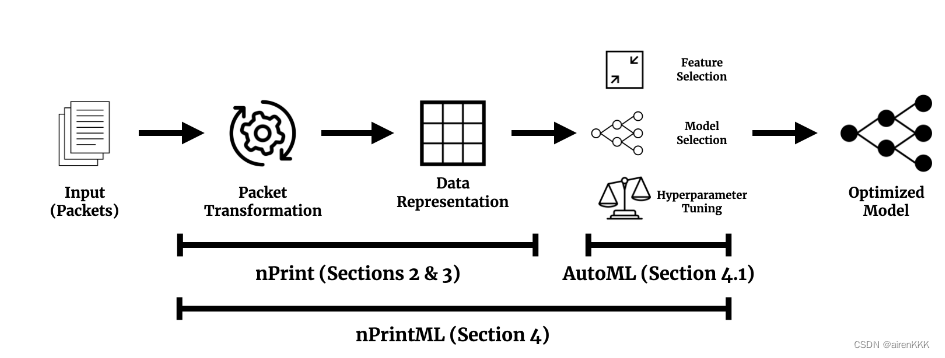
3.1 数据预处理
在本节中,作者介绍了为什么要提出nPrint这种表征格式的原因,以及具体的格式的形式。作者讨论了三种对网络流量的表征方式,即:基于语义的表示、二进制表示以及混合表示。首先给出三种表示方式的对比,如下图所示。
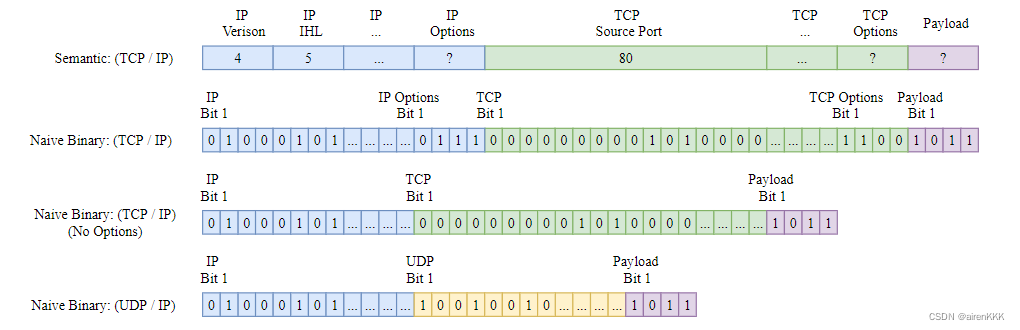
接下来分别讨论这三种方式的具体信息:
- 基于语义的表示。网络流量的经典视图将数据包视为更高级别标头的集合,例如 IP、TCP 和 UDP。每个标头都有语义字段,例如 IP TTL、TCP 端口号和 UDP 长度字段。网络流量的标准语义表示将所有这些语义字段收集在一个表示中。
- 朴素二进制表示。我们可以使用原始位图表示来保持排序并减轻对手动特征工程的依赖。这种选择导致了一致的、预标准化的表示,类似于每个数据包的“图像”。
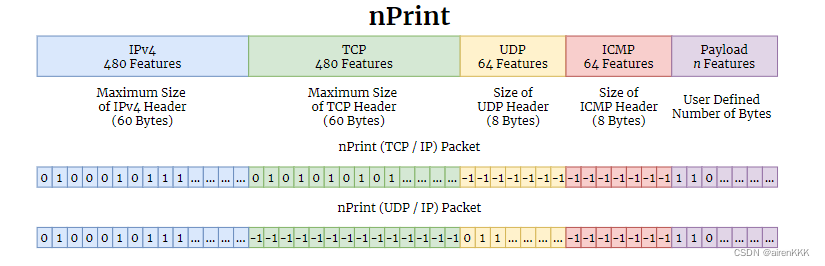
- 混合表示。也即nPrint。nPrint 是语义和二进制数据包表示的混合,将数据包表示为原始二进制数据模型,但以识别数据包本身具有特定语义结构的方式对齐二进制数据。通过使用内部填充,nPrint 减轻了未对齐的二进制表示可能发生的不对齐,同时仍然保留了选项的顺序。一言以蔽之,nPrint就是在二进制表示的基础之上,将原始流量中未出现的协议部分填充为-1,这样既保证了原始数据的完整性,又使得经过处理之后的数据具有统一的长度。
作者表示之所以使用nPrint来作为原始流量的表征,是由于基于语义的表示方法丢失了特定字段,例如 TCP 选项。二进制 nPrint 缺乏对齐,而不对齐的特征会导致后续学习器性能降低。
作者用C++实现了nPrint,并通过实验证明nPrint内存占用小,处理速度快。同时,作者也将nPrint项目进行了开源,项目主页:nPrint
3.2 结合AutoML技术
以下引用作者对结合AutoML技术的原话:
我们使用 AutoGluon-Tabular 对我们评估的所有八个问题执行特征选择、模型搜索和超参数优化。我们选择 AutoGluon,因为它已被证明在相同数据的情况下优于许多其他公共 AutoML 工具,并且它是开源的,尽管 nPrint 的良好结构格式使其适用于任何 AutoML 库。虽然许多 AutoML 工具搜索一组模型和相应的超参数,但 AutoGluon 通过集成多个表现良好的单个模型来实现更高的性能。 AutoGluon-Tabular 允许我们针对每个问题训练、优化和测试 50 多个模型,这些模型源自 6 个不同的基本模型类,它们是基于树的方法、深度神经网络和基于邻居的分类的变体。我们检查的每个问题的最高性能模型是基本模型类的集合。 AutoGluon 有一个预设参数,用于确定训练速度和模型大小与训练模型的整体预测质量。我们将预设参数设置为 high_quality_fast_inference_only_refit,从而生成具有高预测精度和快速推理的模型。有一个“最佳质量”的质量预设,可以创建预测精度略高的模型,但代价是推理速度慢 10 倍至 200 倍,磁盘使用率高 10 倍至 200 倍。我们做出这个决定是因为我们相信推理时间是考虑网络流量分析时的一个重要指标。我们注意到 AutoML 工具的预设参数并不代表对单个模型的训练,而是针对给定任务对一组模型的优化。我们对模型训练时间没有设置限制,允许 AutoGluon 找到最佳模型,并将每个数据集分成 75% 的训练数据集和 25% 的测试数据集。最后,我们将评估指标设置为 f1_macro,它表示一个 F1 分数,该分数是通过计算多类分类问题中每个类的 F1 分数并计算它们的未加权平均值来计算的。这一决定导致 AutoGluon 5 调整超参数和集成权重,以优化验证数据的 F1 宏分数。
nPrintML即可以用于在线数据,也可以用于离线数据,该模型的具体方法和命令见nPrint项目主页。作者用热力图显示了在模型对具体字段的关注程度,也从侧面反映了某些字段在特定的分类任务中的重要性,非常直观。

4 实验评估
本文在8个任务上测试了nPrintML的性能以及其与人工工作的比较,如下图:
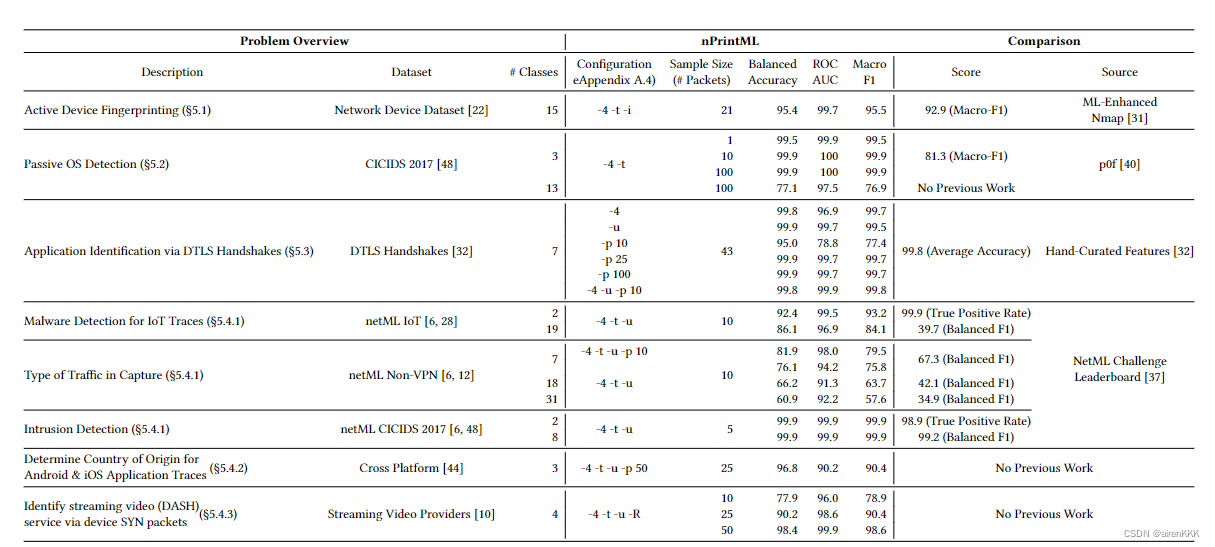
4.1 主动设备指纹识别
在本环节,作者主要和nmap的识别结果做了对比,如下图所示:
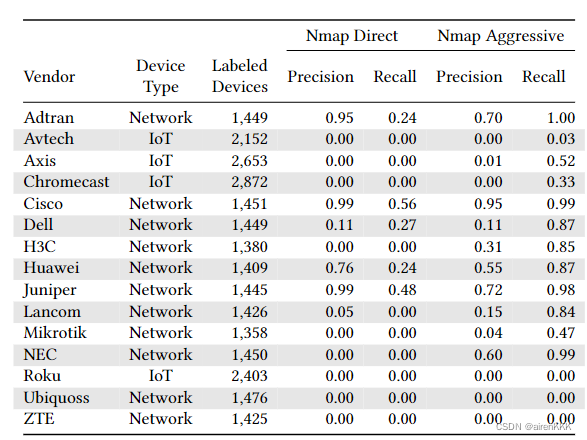
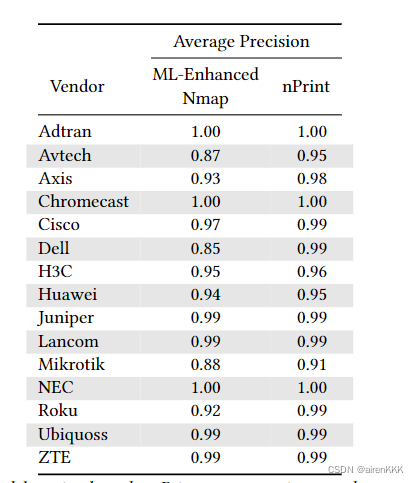
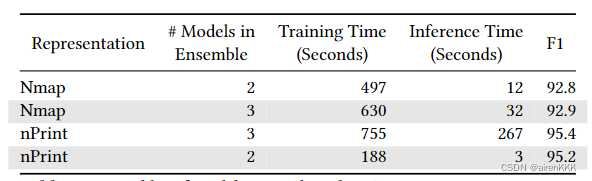
同时,实验表明,nPrint在时间上也具有优势:
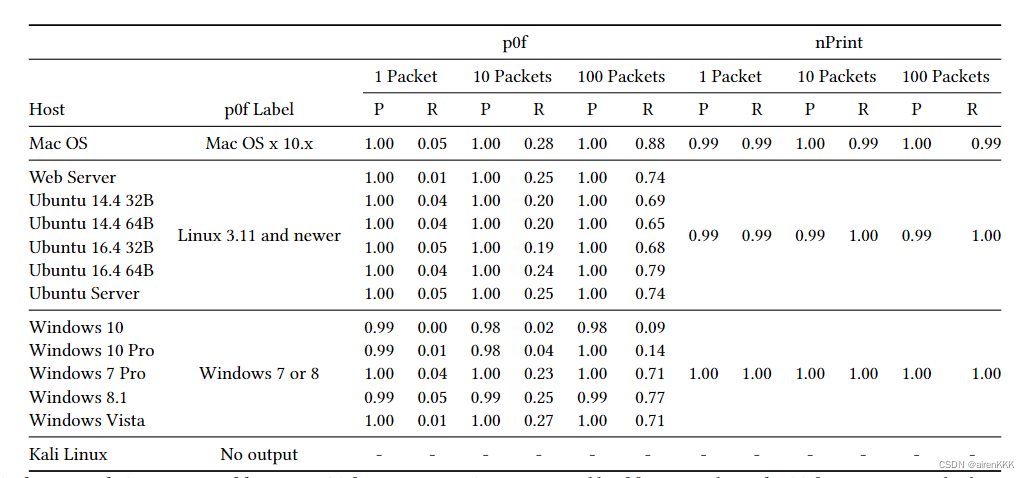
4.2 被动系统指纹识别
在本节中,作者主要和 p0f 做对比,实验结果如下图所示:
4.3 DTLS应用识别
在本节中,作者测试了 nPrintML 通过 DTLS 握手识别一组应用程序的能力。
分别用Chrome和Firefox浏览器收集的数据:
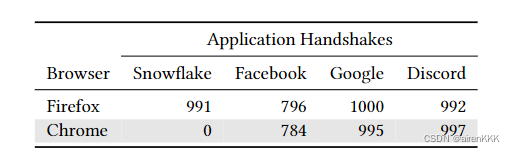
实验结果表明在 nPrint 表示上训练的加权集成分类器实现了完美的 ROC AUC 分数、99.8% 的准确率和 99.8% 的 F1 分数。
nPrintML 几乎可以完美地识别生成每次握手的(浏览器、应用程序)对。虽然在先前的工作中,手动设计的特征在更简单的问题版本上实现了相同的精度,但 nPrintML 完全避免了模型选择和特征工程,在更困难的问题实例上匹配手动特征和模型的性能 。
还有一些其他的实验任务,感兴趣的同学可以参考原文。
5 总结
本文为自动流量分析创建了一个新方向,提出了 nPrint,这是一种统一的数据包表示,它将原始网络数据包作为输入并将它们转换为适合表示学习和模型训练的格式,这种标准格式可以轻松地将网络流量分析与最先进的自动化机器学习 (AutoML) 管道集成。 nPrintML 是 nPrint 与 AutoML 的集成,可自动学习相应任务的最佳模型、参数设置和特征表示。 nPrint 已经证明,许多网络流量分类任务都可以自动化。作者还开源了项目的代码,同时也放出了实验用的所有数据集。