本文来自于网易云课堂
为什么要进行实例探究
上一讲我们介绍了卷积神经网络的基本组件,事实上过去几年,计算机视觉研究中的大量研究都集中在如何把这些基本构建组合起来形成有效的卷积神经网络。找感觉的最好方法之一就是去看一些案例,就像很多人通过看别人的代码来学习编程一样,通过研究别人构建有效组件的案例是个不错的办法。实际上在视觉网络中表现良好的网络架构往往也适合于其他任务。也就是说,如果别人已经训练或者计算出擅长识别猫,狗,人的神经网络架构,而你的任务与此相关,那你完全可以借鉴别人的架构。学完这几节课你应该可以读一些计算机视觉方面的论文了,而我希望这也是你学习本课程的收货。—Andrew Ng
下面会介绍一些经典网络和残差网络ResNet和Inception等,就算你不是研究计算机视觉方面的,但是相信你也会从ResNet和Inception网络这样的实例中,找到一些不错的想法,这里面很多思路都是多学科融合的产物。总之,即便你不打算构建计算机视觉相关的应用程序,试着从中发现一些有趣的思路对你的工作也会有所帮助。
经典网络
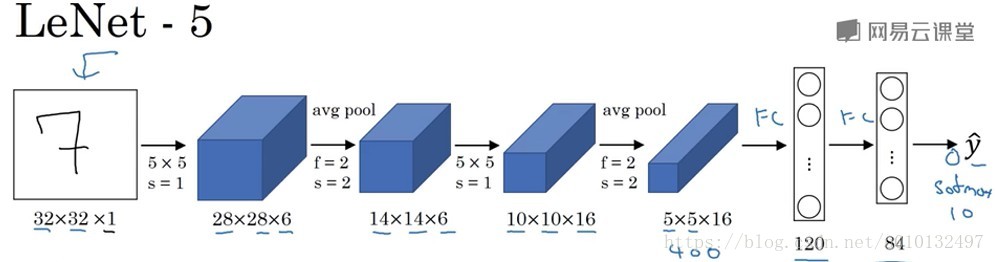
LeNet-5
假设你有一张32*32*1的图片,LeNet-5网络可以识别其中的手写字体,然后过滤然后池化-在当时的年代人们更喜欢使用平均池化…。相比与现在的版本,这个神经网络相对较小一些,只有约6万个参数,而现在我们经常看到含有1000万或者1亿个参数的神经网络。但是不管怎么样,随着神经网络深度的增加,图像的宽度和高度都在减小而信道数在增加。
AlexNet
这个论文名字叫《Image Net Classification with Deep Convolutional Neural Networks》
这个网络的名字是以论文的第一作者Alex Krithevsky来命名的。AlexNet首先用227*227*3的图片作为输入。实际上这种网络与LeNet-5有很多相似之处,不过AlexNet要大的多,它包含大约6000万个参数。它可以采用相似的含有大量隐藏单元或数据的基本构造模块使得AlexNet表现出色。它比LeNet-5表现好的另一个原因是它采用了Relu激活函数

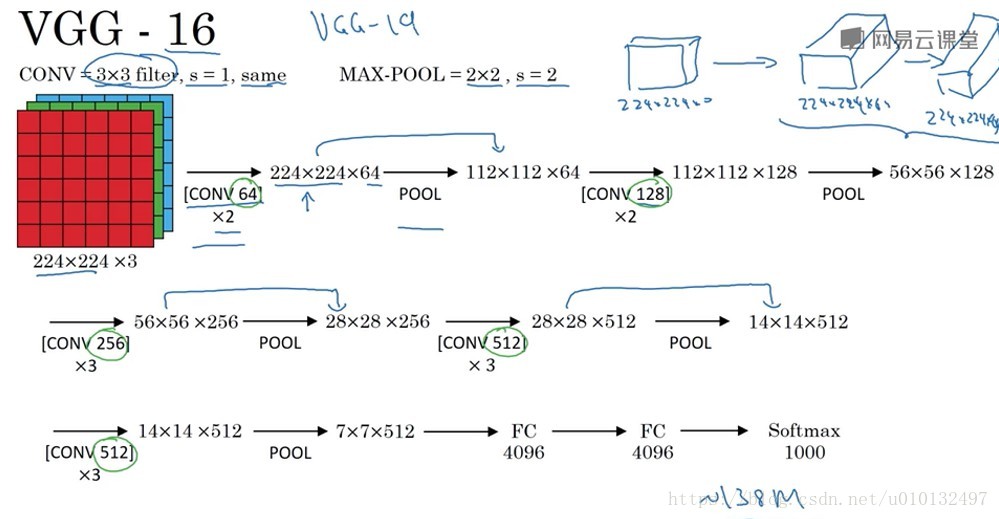
VGG-16
这是一种没有那么多参数,只需要专注于构建卷积层的简单网络。不过这种网络非常深,参数大约有1.38亿。但是其结构不复杂,这一点非常吸引人,而且非常规整。
学完这些经典的网络之后,我们开始学习更先进的网络。
ResNet(残差网络)
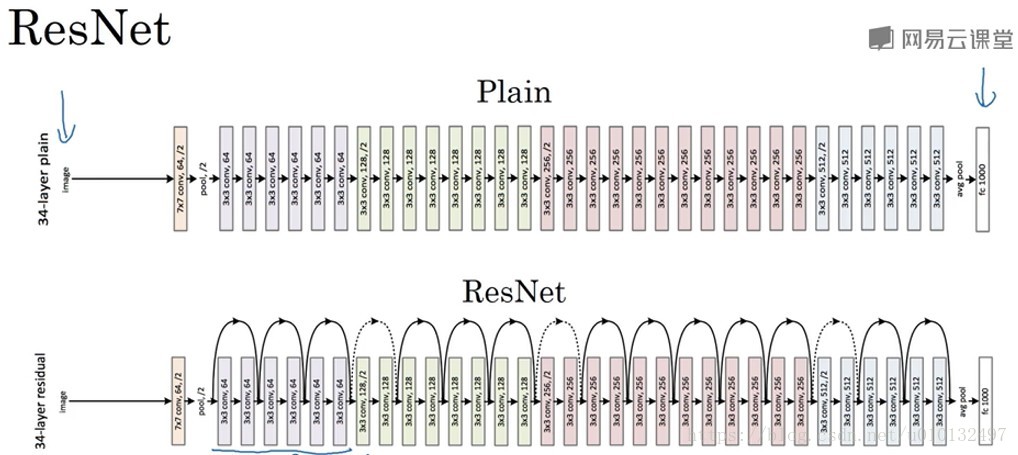
非常非常深的网络是很难训练的,因为存在梯度消失和梯度爆炸问题,这节课我们学校跳远连接(skip connection),它可从某一网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的最深层。我们可以利用skip connection来构建非常非常深的ResNet,最深可达到100层。
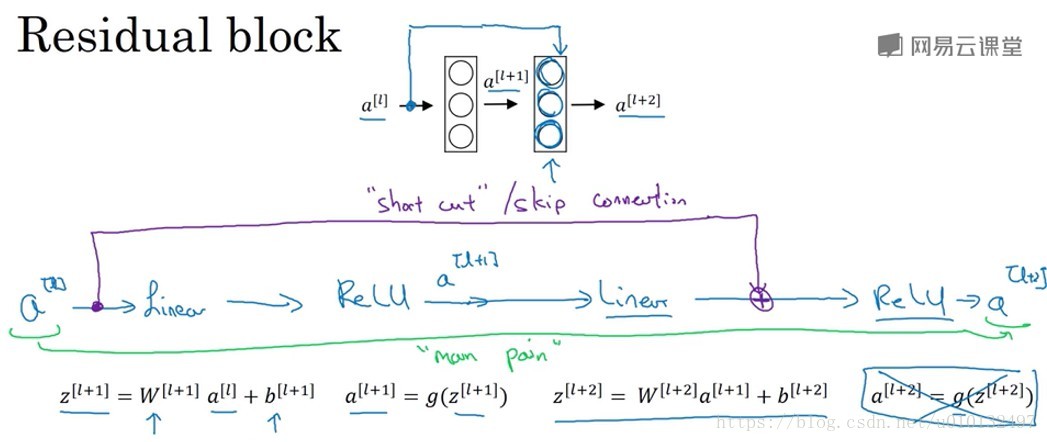
ResNet是由残差块组成的,它通过跳远改变了信息的传递主路径。ResNet的发明者是何凯明,张翔宇,任少卿以及孙剑。他们发现用残差块能训练更深的网络。所以构建一个ResNet网络就是将很多这样的残差块堆积在一起形成一个残差网络。
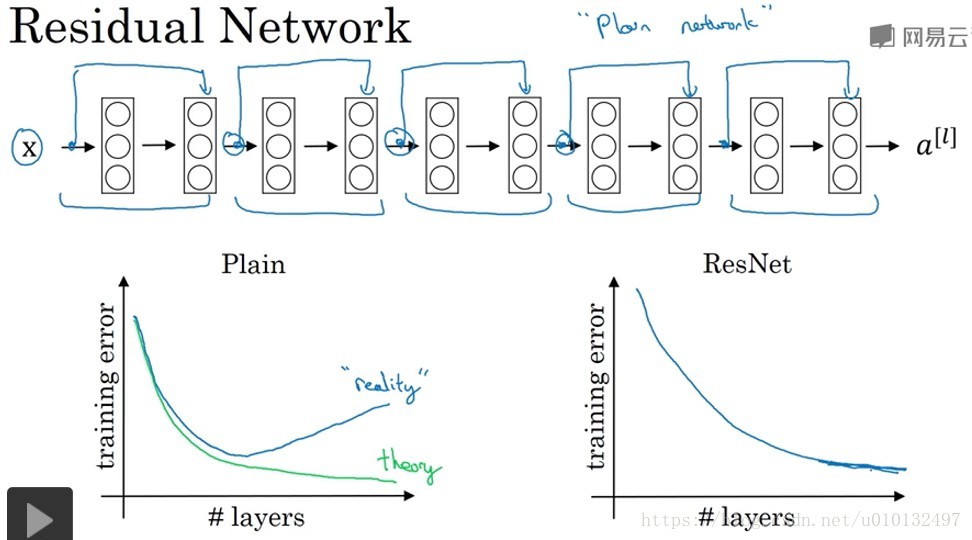
理论上,随着神经网络深度的加深,误差应该越来越小,但实际上普通的神经网络会出现先下降后上升的趋势,而采用残差神经网络则可以达到很深层。这种方式很好的解决了梯度消失和梯度爆炸的问题,又可以保持很好的性能。
残差网络为什么有效
我们给出一个例子可以解释。上节课我们了解到神经网络越深,它在训练集上训练网络的效率会有所减弱,这也是有时候我们不愿意加深网络的原因,但不完全是这样,至少对于Resnet来说。
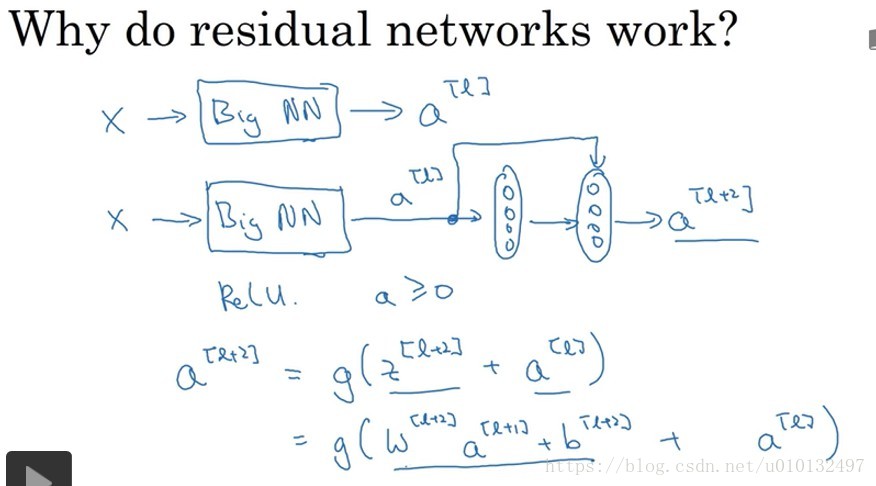
对于上图,如果使用L2正则化和权重衰减,它会压缩
的值,如果对b这样用,也会达到同样的效果,实际上对b不怎么用。所以这里的
是关键项,如果
是0,为方便起见,假设b也是0,那么最后g(
)=
,因为我们使用的Relu激活函数。结果表明残差块学习这个恒等式函数残差块并不难,跳远连接使得我们很容易得出
=
,这意味着即使神经网络增加了2层,它的效率也不逊色简单的神经网络,尽管它多了2层也只是把
赋值给了
,所以加两次网络并不会影响表现。当然,我们的目标不仅仅是保持它的效率还要增加它的效率。想象一下,如果这些隐层单元学到一些有用信息,那么它可能比学习恒等函数效果更好。而对于那些简单网络,随着深度的加深,就算是选择学习恒等函数都很困难。Andrew Ng认为残差网络表现好的原因是这些残差块学习恒等函数很容易,你能确定效率不受影响很多时候甚至会提高效率。关于残差网络另一个值得探讨的细节就是假设
与
具有相同的维度,所以ResNet使用了很多”same”卷积,所以实现了跳远连接。如果不同的话,需要增加一个参数自学习的Ws。
网络中的网络以及1×1卷积
在架构内容设计方面,其中一个比较有帮助的想法是使用1×1卷积,那么1×1卷积有什么用呢?不就是乘以1个数吗?这听上去很好笑,但事实并不是如此。
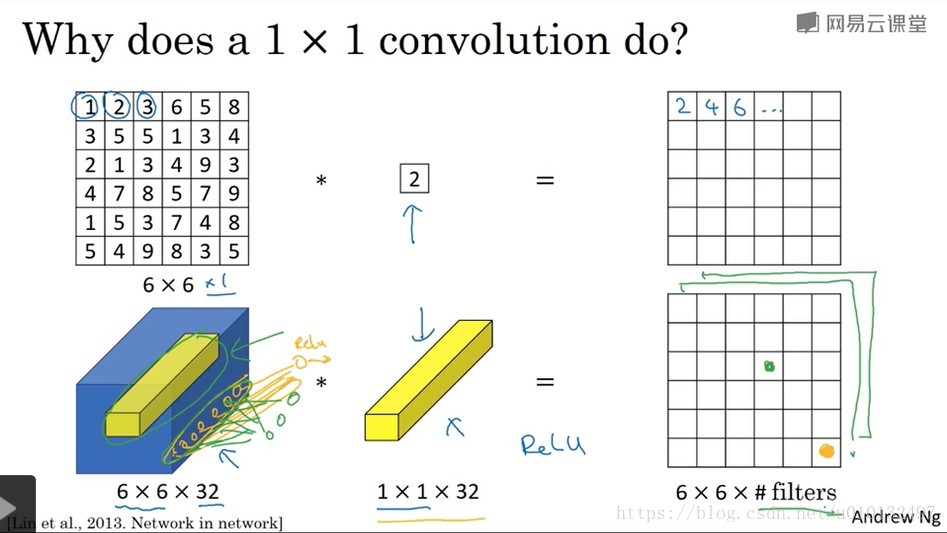
使用1×1卷积对于1个通道的输入来说效果并不好,但是如果对于多通道来说效果就比较好了。具体来说,它实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素智能乘积,然后运用relu非线性函数。一般来说,如果过滤器不止一个,而是多个,就好像有多个输入单元。这种方法称为1×1卷积有时也被称为网络中的网络。在林敏,陈强和杨学成的论文中有详细描述,虽然论文中的详细内容并没有得到广泛的应用,但是1×1这种理念却很有影响力。注:还可以参考这篇文章
使用1×1卷积可以起到降维的作用。例如,假设有一个28*28*192的输入,你可以使用池化层来压缩它的高度和宽度,但如果信道数很大,该如何把它压缩为28*28*32的层呢?你可以使用32个1*1*192的过滤器,所以这就是压缩通道数的方法。
