Hadoop 概念
1.Hadoop是什么?
广义:Hadoop生态圈的代名词
狭义:Apache 软件基金会下用Java 语言开发的一个开源分布式计算平台
2.Hadoop发展历史
来源:2005年,Hadoop作为Lucene子项目Nutch的一部分正式被引入Apache基金会,随后又从Nutch中剥离,成为一套完整独立的软件,起名为Hadoop。
Lucene 是 Doug Cutting 使用 Java 编写开源软件,Lucene 其实是一个搜索引擎。
2003-2004 年,Google 公布了部分 GFS(Google File System) 和 MapReduce 思想的细节,其实就是三篇论文 。
Doug Cutting 等人用 2 年的业余时间实现了 DFS(Distributed File System) 和 MapReduce 机制。
需求:基于早期搜索业务对海量数据的存储和计算的遇到的瓶颈
创作源泉:谷歌提出的大数据论文
3.Hadoop的版本发展
学习阶段:重点掌握Apache的基础版本
生产领域一般使用商业版或者社区(CDH版本)
4. Hadoop的优势(4高)
高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5. Hadoop的组成部分
-- HDFS (hadoop的组成部分-负责海量数据的存储)
-- NameNode(nn):管理真实数据的元数据的(hdfs集群中的老大)
-- DataNode(dn):主要负责对真实数据块存储(hdfs集群中的小弟)
-- SecondaryNameNode(2nn):主要为NameNode进行一些数据备份,
一般恢复数据的时候才会用到它,它也不能保证完全数据恢复。
-- YARN (hadoop的组成部分,主要负责资源调度)
-- ResourceManager(rm):统筹管理每一台机器上的资源,并且负责接收处理客户端
作业请求。
-- NodeManager(nm):负责单独每一台机器的资源管理,实时保证和大哥
(ResourceManager)通信。
-- ApplicationMaster:针对每个请求job的抽象封装
-- Container:将来运行在YARN上的每一个任务都会给其分配资源,
Container就是当前任务所需资源的抽象封装
-- MapReduce(hadoop的组成部分,主要负责数据的计算分析)
-- Map阶段:就是把需要计算的数据按照需求分成多个MapTask任务来执行
-- Reduce阶段: 把Map阶段处理完的结果拷贝过来根据需求进行汇总计算
Hadoop环境搭建
模板机环境准备
1)准备一台模板虚拟机 hadoop100
注:本文Linux系统环境全部以CentOS-7.5-x86-1804为例说明
模板虚拟机:内存4G,硬盘50G
安装必要环境,为安装hadoop做准备
[root@hadoop100 ~]# yum install -y epel-release
[root@hadoop100 ~]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
epel 这个是很常用软件源,比如 python3, zabbix 都需要用到 epel
2)关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld
3)创建用户,并修改用户的密码
[root@hadoop100 ~]# useradd yls
[root@hadoop100 ~]# passwd yls
4)配置用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
yls ALL=(ALL) NOPASSWD:ALL
5)在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为atguigu用户
[root@hadoop100 ~]# chown yls:yls /opt/module
[root@hadoop100 ~]# chown yls:yls /opt/software
(3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 yls yls 4096 5月 28 17:18 module
drwxr-xr-x. 2 yls yls 4096 5月 28 17:18 software
6)卸载虚拟机自带的open JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
查询并卸载
7)重启虚拟机
[root@hadoop100 ~]# reboot
虚拟机克隆
1)利用模板机hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
2)修改克隆机IP,以下以hadoop102举例说明
(1)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
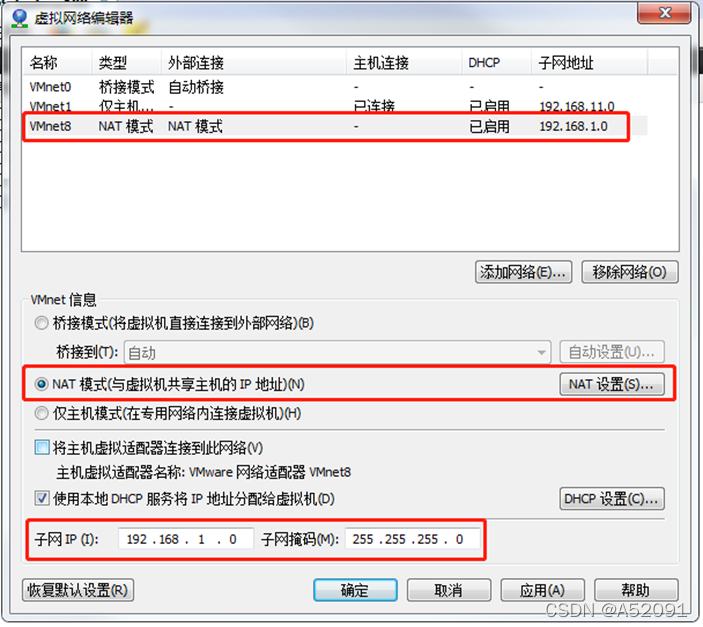

(2)查看Windows系统适配器VMware Network Adapter VMnet8的IP地址

(3)修改克隆虚拟机的静态IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME=“ens33”
IPADDR=192.168.1.102 //静态ip地址 根据自己的修改
PREFIX=24
GATEWAY=192.168.1.2 /网关
DNS1=192.168.1.2
保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址
3)修改克隆机主机名,以下以hadoop102举例说明
(1)修改主机名称,两种方法二选一
[root@hadoop100 ~]# hostnamectl --static set-hostname hadoop102
或者修改/etc/hostname文件
[root@hadoop100 ~]# vim /etc/hostname
hadoop102
(2)配置linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
4)重启克隆机hadoop102
[root@hadoop100 ~]# reboot
5)修改windows的主机映射文件(hosts文件)
(1)如果操作系统是window7,可以直接修改
(a)进入C:\Windows\System32\drivers\etc路径
(b)打开hosts文件并添加如下内容,然后保存
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
(2)如果操作系统是window10,先拷贝出来,修改保存以后,再覆盖即可
(a)进入C:\Windows\System32\drivers\etc路径
(b)拷贝hosts文件到桌面
(c)打开桌面hosts文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
(d)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
安装JDK Hadoop
1)卸载现有JDK
[yls@hadoop102 ~]$ rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
2)下载JDK,将JDK导入到opt目录下面的software文件夹下面
下载Hadoop,将JDK导入到opt目录下面的software文件夹下面
3)在Linux系统下的opt目录中查看软件包是否导入成功
[yls@hadoop102 ~]$ ls /opt/software/
看到如下结果:
hadoop-3.1.3.tar.gz jdk-8u212-linux-x64.tar.gz
6)解压JDK到/opt/module目录下
[yls@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
解压Hadoop安装文件到/opt/module下面
[yls@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
8)测试JDK是否安装成功
[yls@hadoop102 ~]$ java -version
如果能看到以下结果,则代表Java安装成功。
java version “1.8.0_212”
将Hadoop添加到环境变量
获取Hadoop安装路径
[yls@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh
在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
export PATH= P A T H : PATH: PATH:HADOOP_HOME/sbin
保存后退出
:wq
让修改后的文件生效
[yls@hadoop102 hadoop-3.1.3]$ source /etc/profile
测试是否安装成功
[yls@hadoop102 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.3
Hadoop目录结构
1)查看Hadoop目录结构
[yls@hadoop102 hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x. 2 yls yls 4096 5月 22 2019 bin
drwxr-xr-x. 3 yls yls 4096 5月 22 2019 etc
drwxr-xr-x. 2 yls yls 4096 5月 22 2019 include
drwxr-xr-x. 3 yls yls 4096 5月 22 2019 lib
drwxr-xr-x. 2 yls yls 4096 5月 22 2019 libexec
-rw-r–r–. 1 yls yls 15429 5月 22 2019 LICENSE.txt
-rw-r–r–. 1 yls yls 101 5月 22 2019 NOTICE.txt
-rw-r–r–. 1 yls yls 1366 5月 22 2019 README.txt
drwxr-xr-x. 2 yls yls4 096 5月 22 2019 sbin
drwxr-xr-x. 4 yls yls 4096 5月 22 2019 share
2)重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
完全分布式配制及启动
编写集群分发脚本xsync
1)scp(secure copy)安全拷贝
(1)scp定义:
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
(3)案例实操
前提:在 hadoop102 hadoop103 hadoop104 都已经创建好的 /opt/module /opt/software 两个目录, 并且已经把这两个目录修改为yls:yls sudo chown yls:yls -R /opt/module
(a)在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上。
[yls@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 yls@hadoop103:/opt/module
(b)在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上。
[yls@hadoop103 ~]$ scp -r yls@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
(c)在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上。
[yls@hadoop103 opt]$ scp -r yls@hadoop102:/opt/module/* yls@hadoop104:/opt/module
rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
基本语法如下:
$ rsync -r source destination
-r表示递归,即包含子目录。注意,-r是必须的,否则 rsync 运行不会成功。source目录表示源目录,destination表示目标目录。
如果有多个文件或目录需要同步,可以写成下面这样。
$ rsync -r source1 source2 destination
上面命令中,source1、source2都会被同步到destination目录
-a参数可以替代-r,除了可以递归同步以外,还可以同步元信息(比如修改时间、权限等)。由于 rsync 默认使用文件大小和修改时间决定文件是否需要更新,所以-a比-r更有用。下面的用法才是常见的写法。
$ rsync -a source destination
rsync 除了支持本地两个目录之间的同步,也支持远程同步。它可以将本地内容,同步到远程服务器。
$ rsync -av source/ username@remote_host:destination
-v参数则是将结果输出到终端,这样就可以看到哪些内容会被同步。
案例实操
把hadoop102机器上的/opt/software目录同步到hadoop103服务器的/opt/software目录下
[yls@hadoop102 opt]$ rsync -av /opt/software/* yls@hadoop103:/opt/software
xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/
(b)期望脚本:
xsync要同步的文件名称
(c)说明:在/home/yls/bin这个目录下存放的脚本,yls用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/home/yls/bin目录下创建xsync文件
[yls@hadoop102 opt]$ cd /home/yls
[yls@hadoop102 ~]$ mkdir bin
[yls@hadoop102 ~]$ cd bin
[yls@hadoop102 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
(b)修改脚本 xsync 具有执行权限
[yls@hadoop102 bin]$ chmod +x xsync
(c)将脚本复制到/bin中,以便全局调用
[yls@hadoop102 bin]$ sudo cp xsync /bin/
(d)测试脚本
[yls@hadoop102 ~]$ xsync /home/yls/bin
[yls@hadoop102 bin]$ sudo xsync /bin/xsync
SSH免密登录配置
SSH 会生成一对密钥,分别是公钥和私钥,公钥和私钥是可以互相进行解密,但是不能自己给自己解密
.ssh文件夹下(~/.ssh)的文件功能解释
| name | 功能 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key)(已知的主机列表) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥(公钥的认证列表) |
# 安装 SSH 服务
yum install -y openssh-server openssh-clients
生成公私钥:ssh-keygen -t rsa
将本机的公钥发送到目标机器的认证列表 (authorized_keys) 中
以下操作每个节点都来一遍
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
注意:
还需要在hadoop103上采用yls账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop104上采用yls账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
集群规划
| - | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
常用端口号说明
| Daemon | App | Hadoop2 | Hadoop3 |
|---|---|---|---|
| NameNode Port | Hadoop HDFS NameNode | 8020 / 9000 | 9820 |
| ` | Hadoop HDFS NameNode HTTP UI | 50070 | 9870 |
| Secondary NameNode Port | Secondary NameNode | 50091 | 9869 |
| - | Secondary NameNode HTTP UI | 50090 | 9868 |
| DataNode Port | Hadoop HDFS DataNode IPC | 50020 | 9867 |
| - | Hadoop HDFS DataNode | 50010 | 9866 |
| - | Hadoop HDFS DataNode HTTP UI | 50075 | 9864 |
集群配置
配置core-site.xml
[yls@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[yls@hadoop102 hadoop]$ vim core-site.xml
内容为
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
</configuration>
配置hdfs-site.xml
配置hdfs-site.xml
[yls@hadoop102 hadoop]$ vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
配置yarn-site.xml
[yls@hadoop102 hadoop]$ vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
MapReduce配置文件
配置mapred-site.xml
[yls@hadoop102 hadoop]$ vim mapred-site.xml
内容如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在集群上分发配置好的Hadoop配置文件
[yls@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
去103和104上查看文件分发情况
[yls@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[yls@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
群起集群
配置workers
[yls@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[yls@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
集群的启动方式有两种,一种是单个服务启动,另外一种是利用 Hadoop 官方给我们提供的脚本分模块启动
如果集群是第一次启动,需要格式化 NameNode,NameNode 终身只格式化一次!!!
当 Hadoop 集群启动失败,或者需要重新格式化,必须先清除以下数据:
将每个虚拟机的 /opt/module/hadoop-3.1.3/logs、 /opt/module/hadoop-3.1.3/data、 /opt/module/hadoop-3.1.3/pid 删除
这种操作每个节点都需要
格式化 NameNode
hadoop namenode -format
启动
单服务的启动和停止
# 竖线表示多选 1
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
# yarn 相关的服务
yarn-daemon.sh start|stop resourcemanager|nodemanager
模块化的脚本启动和停止
# 此脚本必须在 namenode 运行的机器上执行
start-dfs.sh
stop-dfs.sh
# 此脚本必须在 resourcemanager 运行的机器上执行
start-yarn.sh
stop-yarn.sh
Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息