版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/gang950502/article/details/73351187
hdfs 测试环境搭建
- 新建4个虚拟机
操作系统选用 CentOS-7-x86_64-Everything-1503-01.iso/(win10 64位/vm12)
安装中选择基本服务器类型安装。在创建普通用户时赋予管理员权限,方便测试。
同步系统时间,要求所有机器时差小于30秒。
由于在VM上安装,时间自动统一。
由于后期有大量测试任务,需要配置四台机器间的静态IP访问,VM网络模式选择NET方式。
Linux系统中的配置可参考Linux静态IP配置
配置完后在四台机器上/etc/hosts 中添加以下四个地址解析,并重启网卡.127.0.0.1 vm51 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 vm51 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.40.50 vm50 192.168.40.52 vm52 192.168.40.53 vm53 ##注意其中 针对自身地址解析放在127和::1中,否则在配置ssh免密码登录时会失败(centos 7)由于节点需要执行本地的一个start-dfs.sh的脚本,因此需要配置节点对自身的ssh免密码登录。需要在每个节点执行以下命令。(注意:每个节点都需要执行一次)
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys ssh vm50(节点自身名称)如果还不行就要执行这条命令
chmod 600 ~/.ssh/authorized_keys
原因参考 SSH本机免登陆密码同理需要配置vm50对从节点vm51,vm52,vm53 的免密码登录
#在vm51上执行下边的命令,发送公钥到子节点 scp id_dsa_node1.pub ggg@vm51:/home/ggg/.ssh scp id_dsa_node1.pub ggg@vm52:/home/ggg/.ssh scp id_dsa_node1.pub ggg@vm53:/home/ggg/.ssh#在vm51,vm52,vm53 上分别执行,追加子节点对主节点的证书认证 cat ~/.ssh/id_dsa_node1.pub >> ~/.ssh/authorized_keys rm ~/.ssh/id_dsa_node1.pub上传并解压hadoop压缩文件至四台服务器,并解压。版本遵循版本选择中的标准,本次选用2.5.1 X64位。
上传后在根目录建一个新文件夹用来专门安装hadoopsudo mkdir /hadoop sudo chown ggg:ggg /hadoop cd /hadoop && tar -zxvf hadoop-2.5.1_x64.tar.gz- 配置hadoop中JAVA路径(JAVA版本:版本选择)
注意此处即使系统jdk版本符合要求也要重新下载一个jdk,系统自带jdk目录结构不符合hadoop调用方法,
但新jdk解压后不必替换环境变量,可直接修改hadoop的读取路径即可。
shell
# 查看该文件25行是一个修改JAVA路径的选项,可修改此处。
[ggg@localhost hadoop]$ awk "NR==25" /hadoop/hadoop-2.5.1/etc/hadoop/hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
/hadoop/jdk1.7.0_07
修改namenode 节点IP,端口,临时数据文件
- 该文件是 /hadoop/hadoop-2.5.1/etc/hadoop/core-site.xml
- 增加一个临时数据存放目录 /hadoop/tmpdata
编辑该文件下边位置
扫描二维码关注公众号,回复: 3173670 查看本文章
<configuration> </configuration>增加如下信息
<property> <name>fs.defaultFS</name> <value>hdfs://vm50:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/hadoop/tmpdata</value> </property>
- 修改从节点连接信息
- 该文件是/hadoop/hadoop-2.5.1/etc/hadoop/hdfs-site.xml
- 编辑该文件下边位置
<configuration>
</configuration>
- 增加以下信息
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm51:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>vm51:50091</value>
</property>
- 增加datanode节点信息
vi /hadoop/hadoop-2.5.1/etc/hadoop/slaves
#增加如下信息
vm51
vm52
vm53
- 增加从节点信息
echo "vm51" > /hadoop/hadoop-2.5.1/etc/hadoop/masters
- 主节点到此配置完成,下边开始配置从节点
# 复制主节点到从节点
$ mv /hadoop/hadoop-2.5.1/share/doc /hadoop
$ scp -r /hadoop/hadoop-2.5.1 ggg@vm51:/hadoop
$ scp -r /hadoop/hadoop-2.5.1 ggg@vm52:/hadoop
$ scp -r /hadoop/hadoop-2.5.1 ggg@vm53:/hadoop
# 在四台机器上执行下边三条命令
$ su root -c 'echo "export HADOOP_HOME=/hadoop/hadoop-2.5.1" >> /etc/profile'
$ su root -c 'echo "export PATH=\$PATH:/hadoop/hadoop-2.5.1/bin:/hadoop/hadoop-2.5.1/sbin" >> /etc/profile'
$ source /etc/profile
测试
```
#主节点执行
$ hdfs namenode -format
/hadoop/hadoop-2.5.1/bin/hdfs: /hadoop/jdk1.7.0_07/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: 没有那个文件或目录
/hadoop/hadoop-2.5.1/bin/hdfs:行262: /hadoop/jdk1.7.0_07/bin/java: 成功
服务器1sudo yum install glibc.i686(4台机器都要配置,否则会在下一步失败)
```
执行结果:
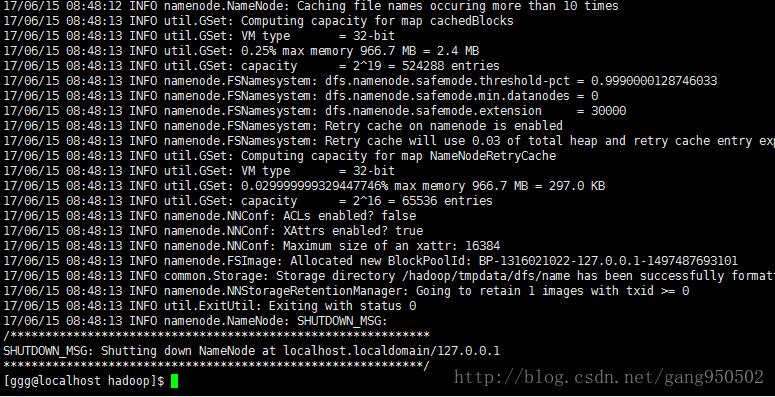
```
[ggg@localhost current]$ cd /hadoop/tmpdata/dfs/name/current
[ggg@localhost current]$ ls
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
#出现了一个警告
[ggg@localhost current]$ start-dfs.sh
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
# 测试警告依然没有消失
```
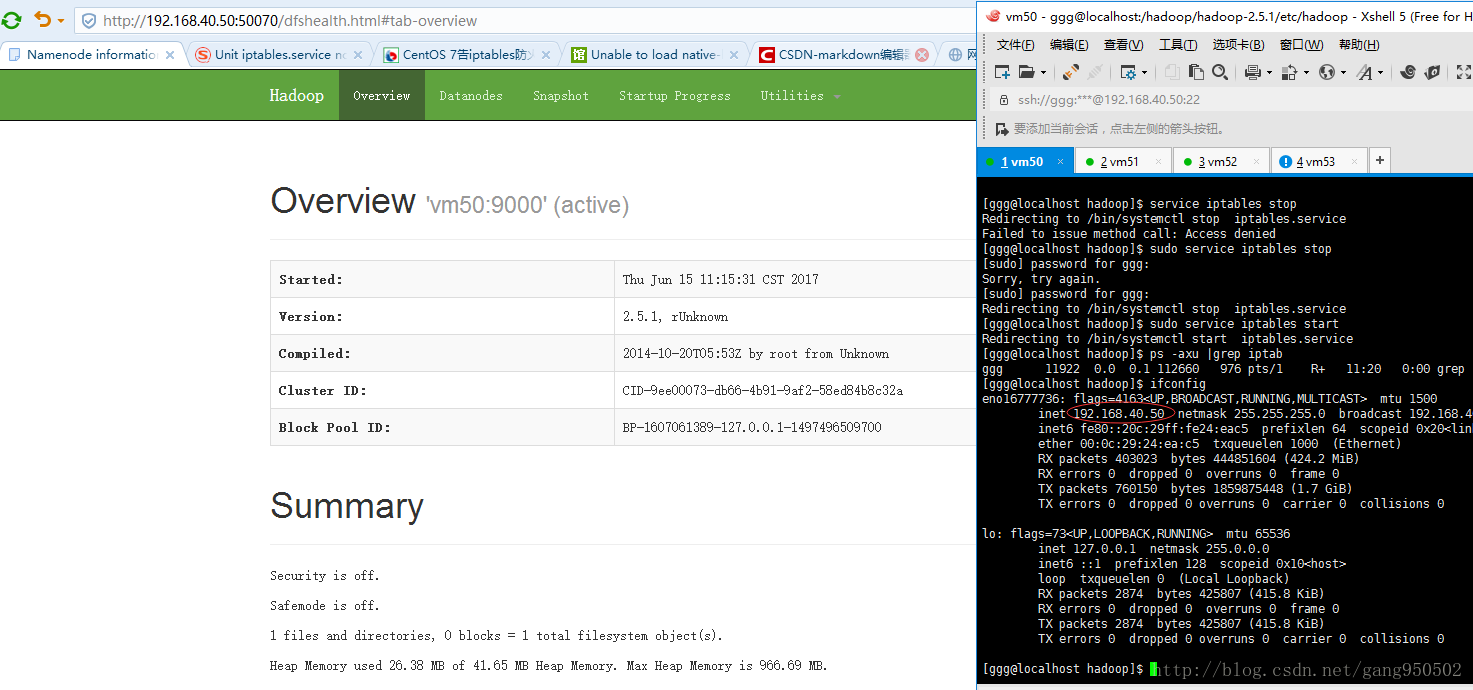
放开主节点对外防火墙,然后则可在主机上访问主节点50070端口查看主节点信息。