作者:张华 发表于:2022-06-07
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
什么是masakari
masakari是OpenStack VM HA项目, 支持3种故障恢复:
- VM process down, 虚拟机进程挂了, 则通过虚拟机的API关闭和启动虚拟. process_all_instances=True时检测所有VM, 若为False时结合VM’s metadata是否为HA_enabled, 并根据VM状态来决定如何处理,如若是stop状态的(masakari\engine\drivers\taskflow\instance_failure.py#StopInstanceTask)那就执行StartInstanceTask, 然后定期执行ConfirmInstanceActiveTask(可通过masakari/setup.cfg自定义恢复方式)
- provisioning process down, 虚拟化进程挂了, 则通过Nova-computeAPI设置Nova-compute服务为down状态. 检测到libvirt, nova-compute, sshd, masakari-instancemonitor, masakari-hostmonitor等进程(process_list.yaml中定义)异常后disable该计算节点并让新创建的VM不会被调度到此节点(masakari\engine\drivers\taskflow\process_failure.py#DisableComputeNodeTask).然后定期运行ConfirmComputeNodeDisabledTask(配置在masakari/setup.cfg中),也有个重要配置叫process_failure_recovery_tasks nova-compute host failure,
- Nova-compute进程挂了, 则疏散计算节点上的虚拟机。(masakari\engine\drivers\taskflow\host_failure.py,)
Masakari的架构如下:
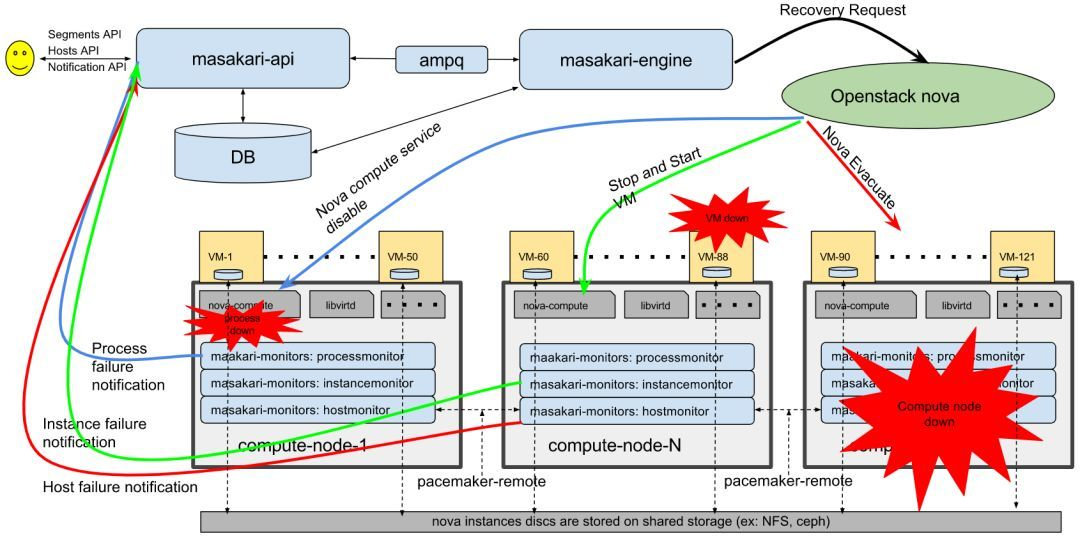
Masakari由controller服务与monitor服务组成,controller服务运行在控制节点,monitor服务则运行在计算节点。
- masakari-api: 运行在控制节,提供服务api。通过RPC它将发送到的处理API请求交由masakari-engine处理。
- masakari-engine: 运行在控制节点,通过以异步方式执行恢复工作流来处理收到的masakari-api发送的通知。
- masakari-instancemonitor : 运行在计算节点,属于masakari-monitor,检测虚拟机进程是否挂掉了
- masakari-processmonitor : 运行在计算节点,属于masakari-monitor,检测Nova-compute是否挂了
- masakari-hostmonitor : 运行在计算节点,属于masakari-monitor,检测计算节点是否挂了
- masakari-introspectiveinstancemonitor:运行在计算节点,属于masakari-monitor,当虚拟机安装了qemu-ga,可用于检测以及启动回复故障进程或服务
- pacemaker-remote:运行在计算节点,解决corosync/pacemaker的16个节点的限制。有些节点可能没有安装corosync, pacemaker-remote让没有安装corosync的节点也能像管理corosync一样来管理
Masakari依赖于pacemaker,Masakari host-monitor定期检查由pacemaker报告的节点状态,并且如果发生故障,则向masakari api发送通知。Pacemaker应该运行stonith资源来关闭节点,然后masakari将在计算节点上运行的guest虚拟机移动到另一个可用的物理节点。Pacemaker是OpenStack官方推荐的资源管理工具,群集基础架构利用Coresync提供的信息和成员管理功能来检测和恢复云端资源级别的故障,达到集群高可用性。Corosync在云端环境中提供集群通讯,主要负责为控制节点提供传递心跳信息的作用。
注:STONITH(Shoot-The-Other-Node-In-The-Head)是用来保护数据的,例如检测到计算节点死掉了, 可能只是管理网络不可达, 业务网络如存储网络可能仍然有数据访问.这个时候,masakari-monitor通过masakari-api将些计算节点上的虚机迁移到其他计算节点上了, 但此时旧计算节点上的虚机还在访问相同的共享存储从而造成数据毁坏. 解决方案便是在packemaker/corosync集群中启用stonith, 当群集检测到某个节点已失联时,它会运行一个stonith插件来关闭计算节点。Masakari推荐使用IPMI的方式去关闭计算节点(基于IPMI的stonith)。这样避免了后端同样的存储资源双写的问题。
测试环境快速搭建
#./generate-bundle.sh --name masakari --series focal --release ussuri --num-compute 3 --ovn --masakari --charmstore --use-stable-charms --run
#ERROR cannot deploy bundle: cannot resolve charm or bundle "pacemaker-remote": retry resolving with preferred channel:
latest/stable
#delete pacemaker-remote from common/charm_lists to use latest/stable channel instead of ussuri/edge for ch:pacemaker-remote
./generate-bundle.sh --name masakari --series focal --num-compute 3 --ovn --masakari --use-stable-charms --run
./tools/vault-unseal-and-authorise.sh
sudo snap install openstackclients
#sudo snap refresh openstackclients --channel=edge
openstack complete |sudo tee /etc/bash_completion.d/openstack
source /etc/bash_completion.d/openstack
openstack segment --help
source novarc
./configure
openstack compute service list -c Host -c Status -c State --service nova-compute
openstack server show focal-1 -c OS-EXT-SRV-ATTR:host
openstack network list
openstack agent list
Masakari CLI
https://docs.openstack.org/charm-guide/latest/admin/instance-ha.html
1, 虚机evacuation恢复
openstack segment createsegment1 auto COMPUTE
- reserved_host:segment中专门配置一台机器用于reserve目的,当有机器DOWN时它将被标为on_maintenance状态,并且它上面的VMs将迁移到reserve机器(同时去掉reserve标签, 可通过命令恢复:openstack segment host update --reserved= )
- auto:segment中没有专门配置reserve机器,当有机器DOWN时它被标为on_maintenance状态,并且它上面的VMs将迁移到其他机器
- auto_priority:首先它会尝试’自动’恢复方法,如果它失败了,那么它会尝试使用’reserved_host’恢复方法。
- rh_priority:它与’auto_priority’恢复方法完全相反。
openstack segment host create compute205 COMPUTE SSH S1
openstack segment host delete
juju run --unit nova-compute/2 sudo ip link set br-ens3 down
有问题的主机再加回去时:
openstack compute service set --enable nova-compute
openstack segment host update --on_maintenance=False
2, 虚机重启
openstack server set --property HA_Enabled=True focal-1
juju run --unit nova-compute/2 ‘pgrep -f guest=instance-00000001’
juju run --unit nova-compute/2 ‘sudo pkill -f -9 guest=instance-00000001’
juju run --unit nova-compute/2 ‘pgrep -f guest=instance-00000001’
openstack server show focal-1 -c OS-EXT-SRV-ATTR:host -c OS-EXT-SRV-ATTR:instance_name
3, 主机恢复(如关闭主机网卡)
openstack server show VM-1-c OS-EXT-SRV-ATTR:host -f value
fence_ipmilan -P -A password-a 10.0.5.18 -p password -l admin -u 15206 -o status
Reference
[1] Openstack Masakari task流程源码分析 - https://cloud.tencent.com/developer/article/1583296
[2] OpenStack高可用组件Masakari架构、原理及实战 - https://www.pcserver.cn/h-nd-28.html
[3] https://docs.openstack.org/masakari/latest/
[4] https://docs.openstack.org/charm-guide/latest/admin/instance-ha.html