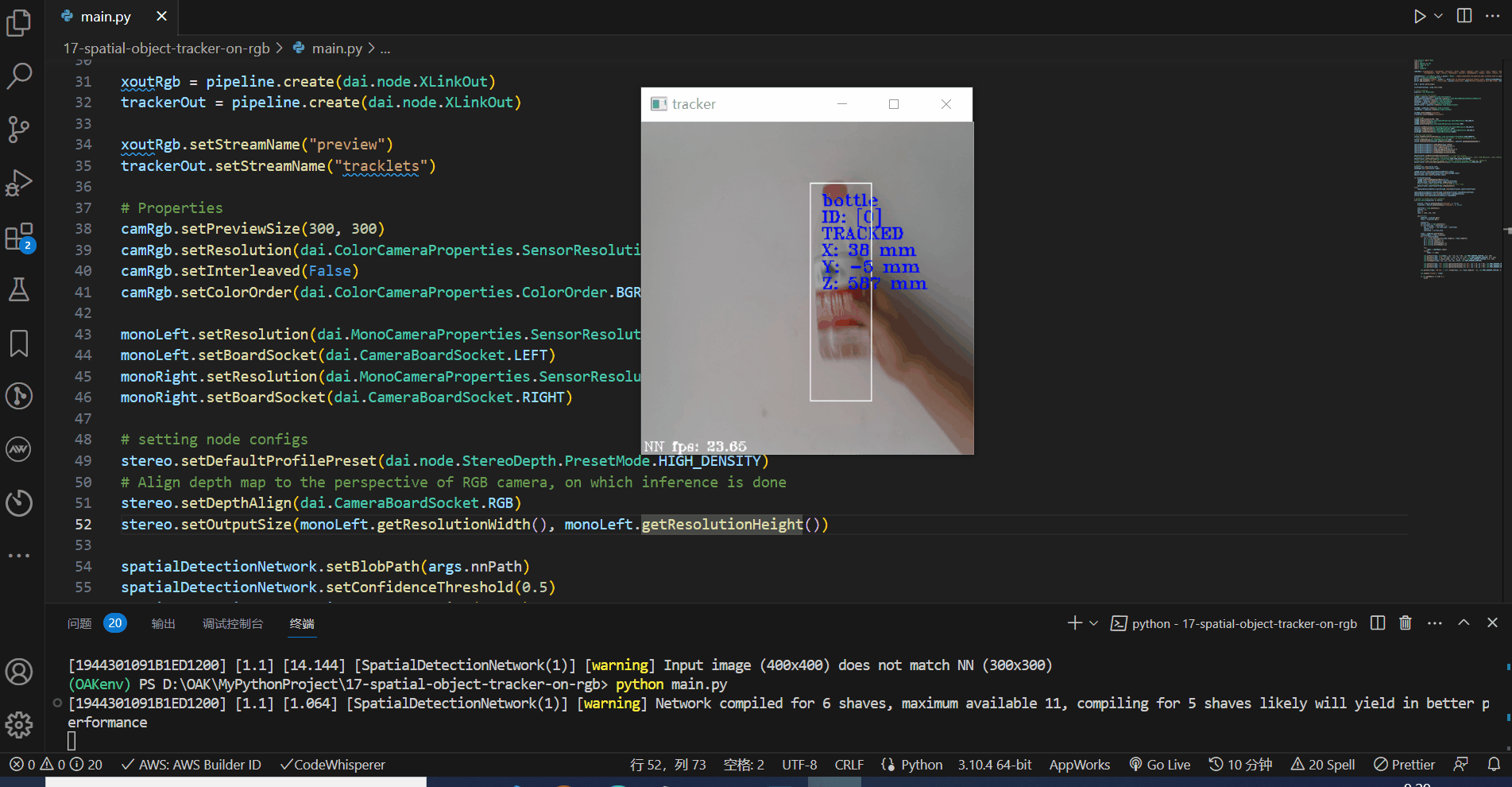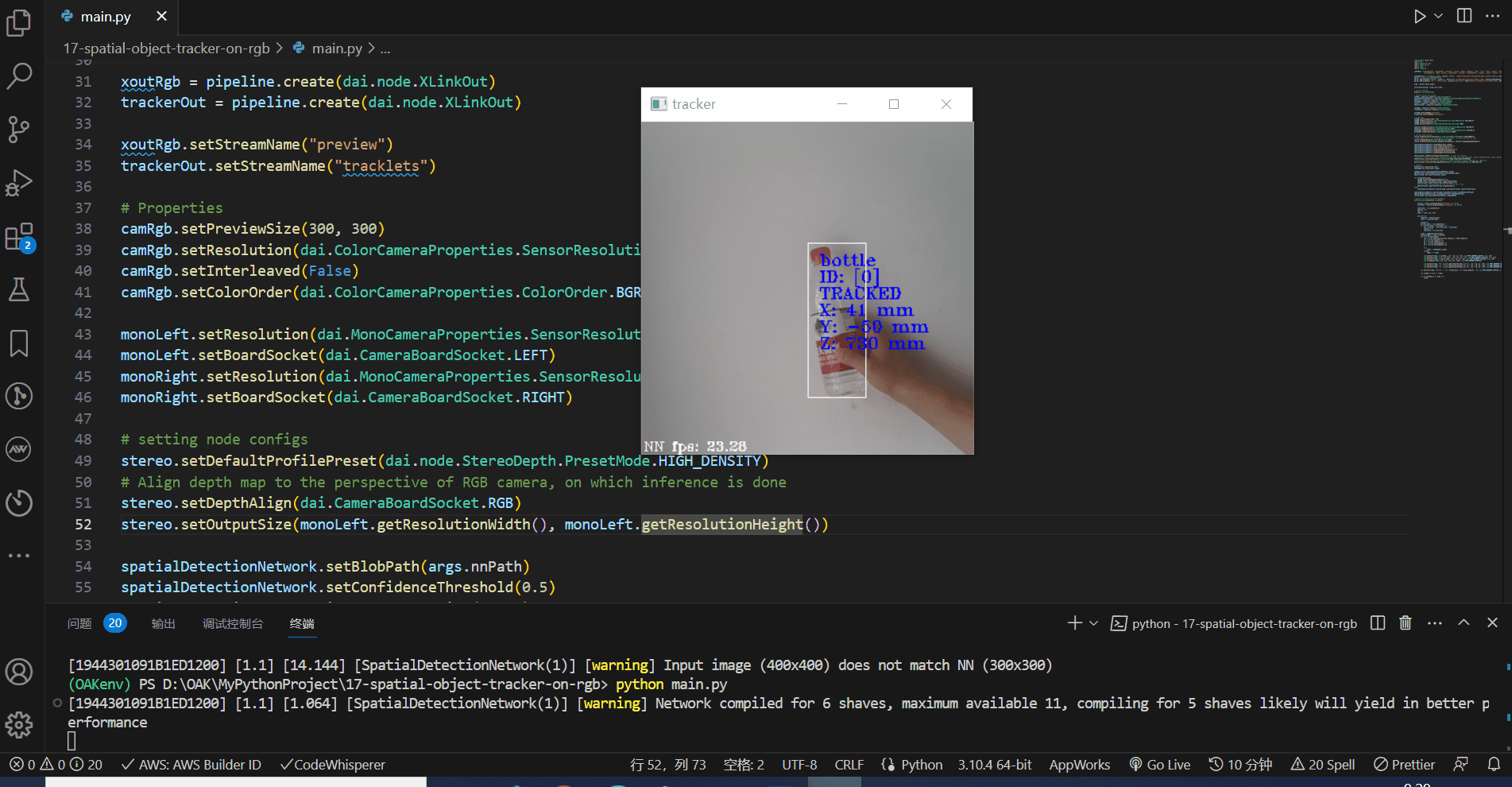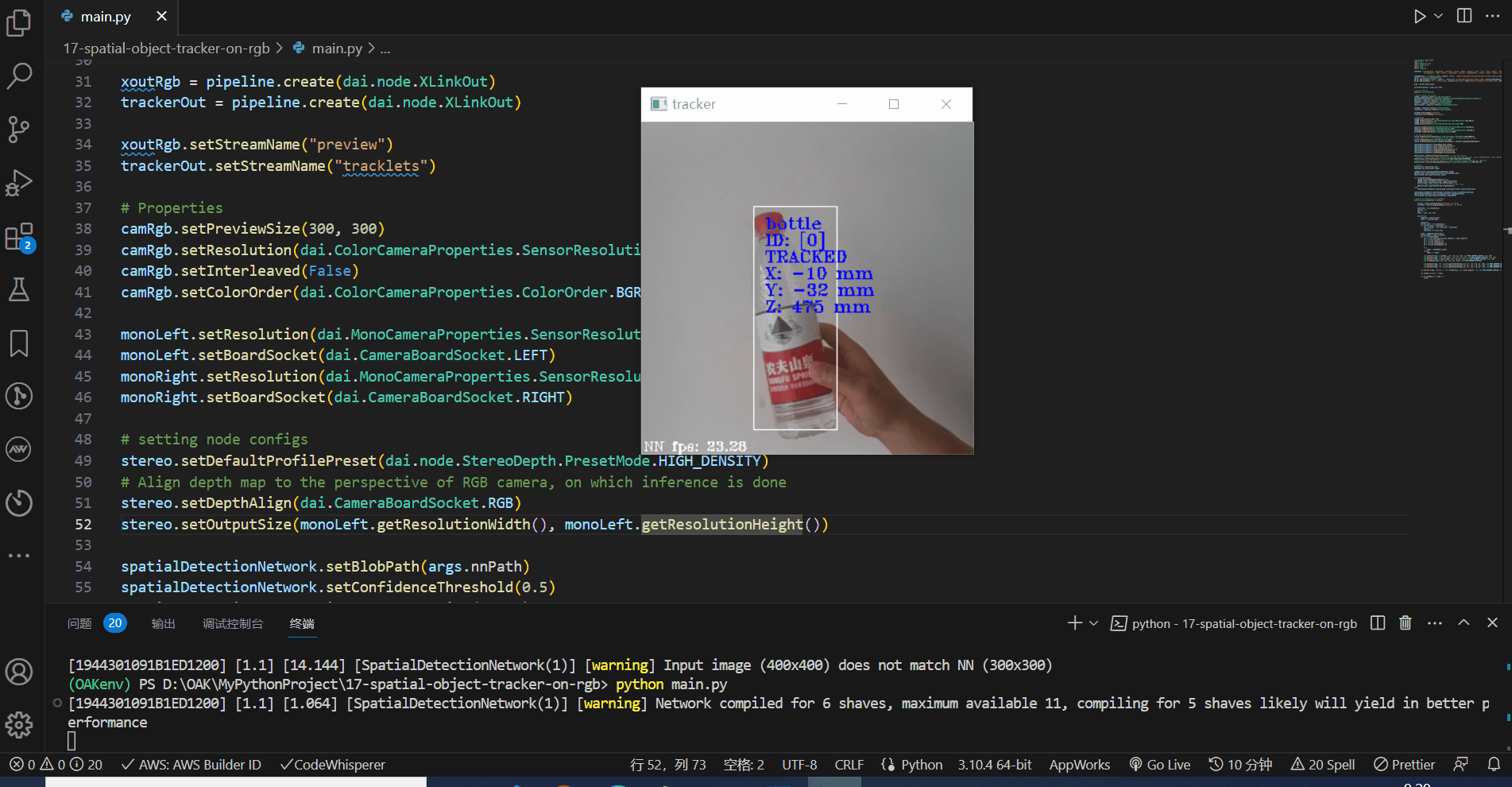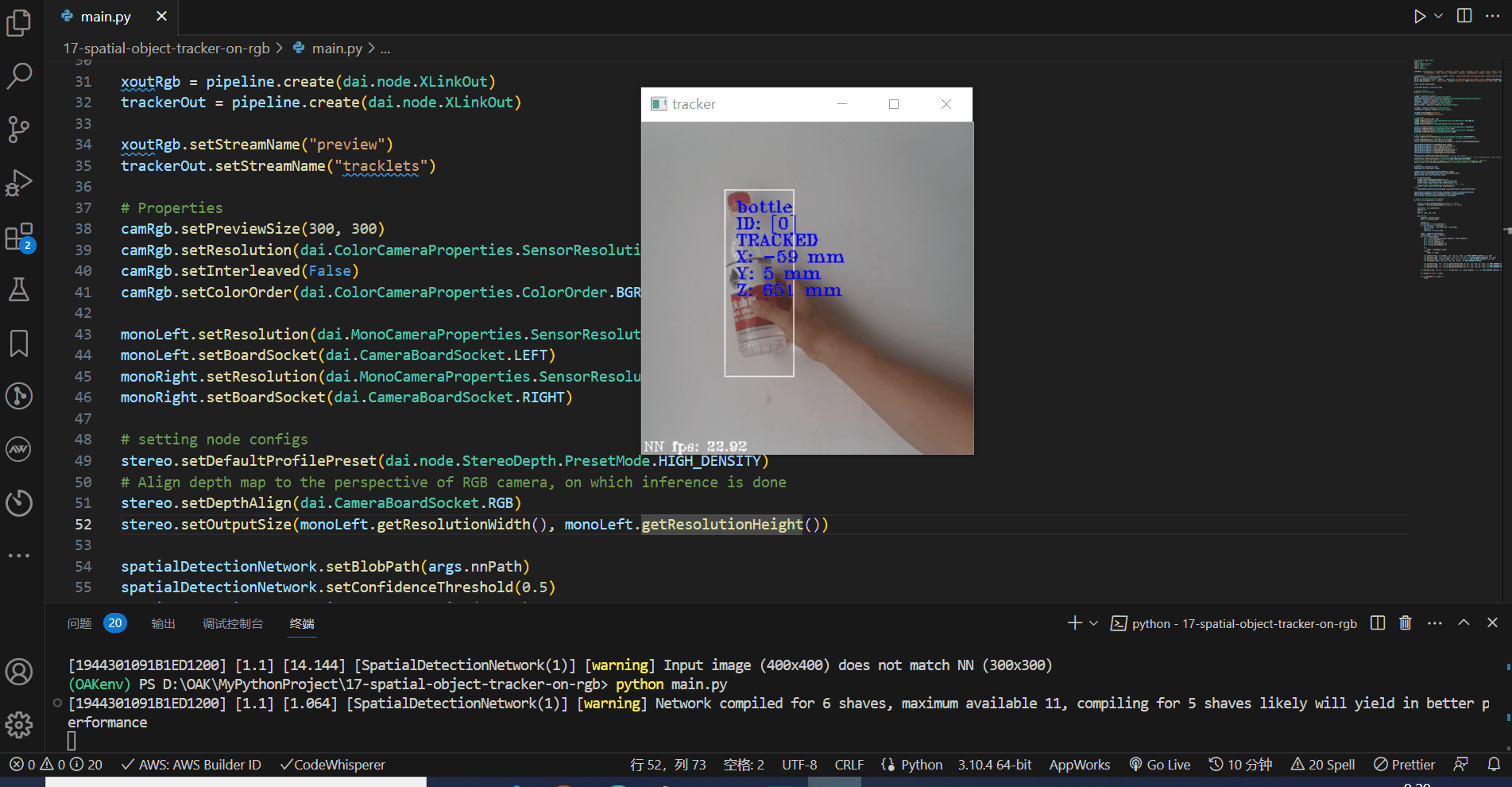
前面我们实现了在RGB相机上进行物体的对象跟踪,能够实时跟踪我们想要追踪的物探,但是,如果我们要想知道这个物体的三维空间坐标,该如何实现呢?要想实现这个功能,我们需要用到DepthAI API提供的MobileNetSpatialDetectionNetwork节点和ObjectTracker节点,现在我们来实现它。
这里我们依然用到了mobilenet-ssd_openvino_2021.4_6shave.blob模型文件,将其下载到本地models文件夹
目录
Setup 1: 创建文件
- 创建新建17-spatial-object-tracker-on-rgb文件夹
- 用vscode打开该文件夹
- 新建一个main.py 文件
Setup 2: 安装依赖
安装依赖前需要先创建和激活虚拟环境,我这里已经创建了虚拟环境OAKenv,在终端中输入cd…退回到OAKenv的根目录,输入 OAKenv\Scripts\activate激活虚拟环境
安装pip依赖项:
pip install numpy opencv-python depthai blobconverter --user
Setup 3: 导入需要的包
在main.py中导入项目需要的包
from pathlib import Path
import cv2
import depthai as dai
import numpy as np
import time
import argparse
pathlib用于处理文件路径,sys用于系统相关的操作,cv2是OpenCV库用于图像处理,depthai是depthai库用于深度计算和AI推理。time用于处理时间,argparse用于处理命令行参数。
time库:用于处理和操作时间相关的功能和操作。提供了许多用于测量时间、获取当前时间、等待或延迟执行的函数。可用于计时、性能测试、调度任务等场景。例如,time.time()可以获取当前的时间戳,time.sleep()可以使程序休眠指定时间。
argparse库:用于解析命令行参数以及生成用户友好的命令行界面。
- 允许定义程序所需的命令行参数,并自动解析和验证这些参数。
- 可以处理位置参数、可选参数、布尔标志等多种参数类型。
- 使用
argparse可以实现灵活的命令行接口,使得程序可以方便地从命令行中获得输入。 - 例如,可以使用
argparse.ArgumentParser创建一个解析器对象,定义参数后调用parse_args()方法解析命令行参数。
Setup 4:定义和加载模型相关的路径和标签
labelMap = ["background", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow","diningtable", "dog", "horse", "motorbike", "person", pottedplant", "sheep", "sofa", "train", "tvmonitor"]
nnPathDefault = str((Path(__file__).parent / Path('../models/mobilenet-ssd_openvino_2021.4_6shave.blob')).resolve().absolute())
parser = argparse.ArgumentParser()
parser.add_argument('nnPath', nargs='?', help="Path to mobilenet detection network blob", default=nnPathDefault)
parser.add_argument('-ff', '--full_frame', action="store_true", help="Perform tracking on full RGB frame", default=False)
args = parser.parse_args()
fullFrameTracking = args.full_frame
这段代码使用argparse库解析命令行参数,并根据解析的结果设置对应的变量值。
-
定义
labelMap为一个字符串列表,包含了针对图像分类任务的类别标签。每个元素代表一个类别,按照索引与模型预测结果相对应。 -
定义
nnPathDefault字符串,指定了模型文件的路径,默认为mobilenet-ssd_openvino_2021.4_6shave.blob文件的路径。 -
parser = argparse.ArgumentParser()创建一个参数解析器对象。 -
parser.add_argument('nnPath', nargs='?', help="Path to mobilenet detection network blob", default=nnPathDefault)定义一个位置参数nnPath,该参数用于指定模型文件的路径,默认值为nnPathDefault。 -
parser.add_argument('-ff', '--full_frame', action="store_true", help="Perform tracking on full RGB frame", default=False)用于开启全帧追踪。该参数可以通过命令行中的-ff或--full_frame标志进行设置,默认值为False。 -
args = parser.parse_args()执行解析命令行参数的操作,并将解析结果保存在args对象中。 -
fullFrameTracking = args.full_frame根据解析的结果获取可选参数full_frame的值,并将其赋值给fullFrameTracking变量。
Setup 5: 创建pipeline
pipeline = dai.Pipeline()
Setup 6: 创建节点
camRgb = pipeline.create(dai.node.ColorCamera)
spatialDetectionNetwork = pipeline.create(dai.node.MobileNetSpatialDetectionNetwork)
monoLeft = pipeline.create(dai.node.MonoCamera)
monoRight = pipeline.create(dai.node.MonoCamera)
stereo = pipeline.create(dai.node.StereoDepth)
objectTracker = pipeline.create(dai.node.ObjectTracker)
xoutRgb = pipeline.create(dai.node.XLinkOut)
trackerOut = pipeline.create(dai.node.XLinkOut)
xoutRgb.setStreamName("preview")
trackerOut.setStreamName("tracklets")
分别创建ColorCamera节点、MobileNetSpatialDetectionNetwork节点、两个MonoCamera节点,StereoDepth节点,ObjectTracker节点和两个XLinkOut节点,并设置两个XLinkOut节点的节点名称
Setup 7: 设置属性
设置相机属性
camRgb.setPreviewSize(300, 300)
camRgb.setResolution(dai.ColorCameraProperties.SensorResolution.THE_1080_P)
camRgb.setInterleaved(False)
camRgb.setColorOrder(dai.ColorCameraProperties.ColorOrder.BGR)
monoLeft.setResolution(dai.MonoCameraProperties.SensorResolution.THE_400_P)
monoLeft.setBoardSocket(dai.CameraBoardSocket.LEFT)
monoRight.setResolution(dai.MonoCameraProperties.SensorResolution.THE_400_P)
monoRight.setBoardSocket(dai.CameraBoardSocket.RIGHT)
使用dai.ColorCamera对象的方法来设置相机的预览大小、分辨率、颜色顺序和帧率等参数。
camRgb.setInterleaved(False)设置相机捕获图像时是否使用交织模式。如果设置为False,则图像数据将以分离的方式进行捕获,更容易处理和获取分离的通道数据。camRgb.setColorOrder(dai.ColorCameraProperties.ColorOrder.BGR)设置相机捕获图像的颜色顺序为BGR。这意味着相机捕获的图像中,颜色通道的排列顺序是蓝、绿、红。- 设置两个单目相机的分辨率为400x400
- 通过setBoardSocket()指定两个单目相机的板载插槽位置
设置StereoDepth节点属性
stereo.setDefaultProfilePreset(dai.node.StereoDepth.PresetMode.HIGH_DENSITY)
stereo.setDepthAlign(dai.CameraBoardSocket.RGB)
stereo.setOutputSize(monoLeft.getResolutionWidth(), monoLeft.getResolutionHeight())
-
使用
setDefaultProfilePreset()方法将StereoDepth的预设模式设置为HIGH_DENSITY。此模式将选择适合高密度深度图像生成的默认配置,以获得更精确的深度图像。 -
使用
setDepthAlign()方法将深度图对齐到RGB相机的视角上,RGB相机用于进行推理。通过对齐深度图像和RGB图像,可以在空间上将深度图像与RGB图像对齐,以便更方便地进行后续处理。 -
使用
setOutputSize()方法将深度图输出的大小设置为monoLeft相机的分辨率宽度和高度。这样设置可以确保深度图的大小与输入图像保持一致,使其易于处理和使用。
设置MobileNetSpatialDetectionNetwork节点属性
spatialDetectionNetwork.setBlobPath(args.nnPath)
spatialDetectionNetwork.setConfidenceThreshold(0.5)
spatialDetectionNetwork.input.setBlocking(False)
spatialDetectionNetwork.setBoundingBoxScaleFactor(0.5)
spatialDetectionNetwork.setDepthLowerThreshold(100)
spatialDetectionNetwork.setDepthUpperThreshold(5000)
使用setBlobPath()方法设置空间检测网络的模型文件路径。
使用setConfidenceThreshold()方法设置置信度阈值为0.5。这个阈值决定了只有置信度高于0.5的检测结果才会被保留。
使用input.setBlocking(False)方法将输入设置为非阻塞模式。即,当输入数据不可用时,代码将不会等待,而是直接继续执行下一条语句。
使用setBoundingBoxScaleFactor()方法设置边界框的缩放因子为0.5。这个因子决定了生成的边界框相对于输入图像的大小。
使用setDepthLowerThreshold()和setDepthUpperThreshold()方法设置深度的下限和上限阈值。这些阈值用于限制检测结果的深度范围,只保留落在指定范围内的物体。
设置物体跟踪对象属性
objectTracker.setDetectionLabelsToTrack([5])
objectTracker.setTrackerType(dai.TrackerType.ZERO_TERM_COLOR_HISTOGRAM)
objectTracker.setTrackerIdAssignmentPolicy(dai.TrackerIdAssignmentPolicy.SMALLEST_ID)
-
objectTracker.setDetectionLabelsToTrack([5])将要跟踪的目标类别设置为只有瓶子(类别标签为5)。这意味着只有检测到瓶子目标时,才会进行跟踪。 -
objectTracker.setTrackerType(dai.TrackerType.ZERO_TERM_COLOR_HISTOGRAM)设置跟踪器的类型为“零阶跟踪器”(ZERO_TERM_COLOR_HISTOGRAM)。这种类型的跟踪器使用颜色直方图来描述目标,并根据颜色信息进行跟踪。 -
objectTracker.setTrackerIdAssignmentPolicy(dai.TrackerIdAssignmentPolicy.SMALLEST_ID)设置当新目标开始跟踪时,选择最小的ID作为跟踪器的ID。这意味着在跟踪过程中,较早被检测到的目标将具有较小的ID值。
Setup 8: 建立链接
monoLeft.out.link(stereo.left)
monoRight.out.link(stereo.right)
camRgb.preview.link(spatialDetectionNetwork.input)
objectTracker.passthroughTrackerFrame.link(xoutRgb.input)
objectTracker.out.link(trackerOut.input)
if fullFrameTracking:
camRgb.setPreviewKeepAspectRatio(False)
camRgb.video.link(objectTracker.inputTrackerFrame)
objectTracker.inputTrackerFrame.setBlocking(False)
# do not block the pipeline if it's too slow on full frame
objectTracker.inputTrackerFrame.setQueueSize(2)
else:
spatialDetectionNetwork.passthrough.link(objectTracker.inputTrackerFrame)
spatialDetectionNetwork.passthrough.link(objectTracker.inputDetectionFrame)
spatialDetectionNetwork.out.link(objectTracker.inputDetections)
stereo.depth.link(spatialDetectionNetwork.inputDepth)
连接不同的节点以建立数据流。
-
使用
monoLeft.out.link(stereo.left)和monoRight.out.link(stereo.right)方法将左摄像头(monoLeft)的输出链接到立体相机(stereo)的左摄像头输入,将右摄像头(monoRight)的输出链接到立体相机的右摄像头输入。这样可以将左右摄像头的图像传递给立体相机进行深度感知。 -
使用
camRgb.preview.link(spatialDetectionNetwork.input)方法将RGB相机(camRgb)的预览输出链接到空间检测网络(spatialDetectionNetwork)的输入。这样可以将RGB图像传递给空间检测网络进行物体检测。 -
使用
objectTracker.passthroughTrackerFrame.link(xoutRgb.input)和objectTracker.out.link(trackerOut.input)将物体追踪器(objectTracker)的追踪器帧输出链接到xoutRgb模块的输入,将物体追踪器的输出链接到trackerOut模块的输入。这样可以将物体追踪器的追踪结果和输出传递给后续的处理模块。 -
根据
fullFrameTracking变量的值来确定是否进行全帧追踪。如果是全帧追踪,则使用camRgb.setPreviewKeepAspectRatio(False)方法设置RGB相机的预览输出不保持纵横比,然后使用camRgb.video.link(objectTracker.inputTrackerFrame)方法将RGB相机的视频输出链接到物体追踪器的追踪帧输入。设置objectTracker.inputTrackerFrame为非阻塞模式,并设置队列大小为2。这样可以在全帧追踪时,不阻塞管道,处理速度较慢时可以有一个缓冲区。否则,如果不是全帧追踪,则使用spatialDetectionNetwork.passthrough.link(objectTracker.inputTrackerFrame)方法将空间检测网络的直通输出链接到物体追踪器的追踪帧输入。这样可以将空间检测网络的检测结果直接传递给物体追踪器进行后续追踪。 -
使用
spatialDetectionNetwork.passthrough.link(objectTracker.inputDetectionFrame)方法将空间检测网络的直通输出链接到物体追踪器的检测帧输入,将空间检测网络的检测结果传递给物体追踪器。 -
使用
stereo.depth.link(spatialDetectionNetwork.inputDepth)方法将立体相机的深度输出链接到空间检测网络的深度输入,将深度信息传递给空间检测网络进行深度与物体检测结果的关联。
Setup 9: 连接设备并启动管道
with dai.Device(pipeline) as device:
Setup 10: 创建与DepthAI设备通信的输出队列
preview = device.getOutputQueue("preview", 4, False)
tracklets = device.getOutputQueue("tracklets", 4, False)
startTime = time.monotonic()
counter = 0
fps = 0
color = (255, 255, 255)
创建输出队列,以便从设备获取处理后的结果。
-
device.getOutputQueue("preview", 4, False)创建一个名为 “preview” 的输出队列。这个队列最多可以存储4个元素,且不是自动清空。通常,“preview” 输出队列用于获取相机的预览图像数据。 -
device.getOutputQueue("tracklets", 4, False)创建一个名为 “tracklets” 的输出队列。这个队列最多可以存储4个元素,且不是自动清空。通常,“tracklets” 输出队列用于获取目标跟踪的结果,如目标的位置、边界框等信息。 -
startTime = time.monotonic()用于获取当前的绝对时间,作为计时器的起始时间。time.monotonic()函数返回的是一个不受系统时间调整影响的单调递增的值。
Setup 11: 主循环
while True:
从输出队列中获取图像帧数据和目标跟踪结果
imgFrame = preview.get()
track = tracklets.get()
-
imgFrame = preview.get()用于从名为 “preview” 的输出队列中获取图像帧数据。preview.get()函数会从队列中获取最新的元素并将其返回给imgFrame变量。 -
track = tracklets.get()用于从名为 “tracklets” 的输出队列中获取目标跟踪结果。tracklets.get()函数会从队列中获取最新的元素并将其返回给track变量。
计算帧率FPS(frames per second)
counter+=1
current_time = time.monotonic()
if (current_time - startTime) > 1 :
fps = counter / (current_time - startTime)
counter = 0
startTime = current_time
-
counter += 1用于增加计数器的值,表示接收到了一帧新的图像数据。 -
current_time = time.monotonic()用于获取当前的绝对时间。 -
通过
(current_time - startTime) > 1条件判断,在过去的一秒钟内是否已经计算过帧率。如果是,则执行以下操作:
fps = counter / (current_time - startTime)计算帧率,即每秒接收到的图像帧数。counter = 0将计数器重置为0,准备重新计数下一秒的图像帧数。startTime = current_time更新起始时间为当前时间,重新开始计时。
获取OpenCV格式的图像帧数据以及目标跟踪的数据
frame = imgFrame.getCvFrame()
trackletsData = track.tracklets
-
frame = imgFrame.getCvFrame()从imgFrame对象中获取OpenCV格式的图像帧数据getCvFrame()函数是一个用于从imgFrame对象中提取图像帧数据的方法。 -
trackletsData = track.tracklets获取目标跟踪数据。track是一个对象或类,其中包含目标跟踪的相关方法和数据。这里通过track.tracklets访问了目标跟踪数据,可能是获取目标物体的位置、速度等信息。根据实际情况,trackletsData可能包含一个列表或其他数据结构,存储跟踪目标的相关数据。
在图像帧上绘制目标跟踪的结果
for t in trackletsData:
roi = t.roi.denormalize(frame.shape[1], frame.shape[0])
x1 = int(roi.topLeft().x)
y1 = int(roi.topLeft().y)
x2 = int(roi.bottomRight().x)
y2 = int(roi.bottomRight().y)
try:
label = labelMap[t.label]
except:
label = t.label
cv2.putText(frame, str(label), (x1 + 10, y1 + 20), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
cv2.putText(frame, f"ID: {[t.id]}", (x1 + 10, y1 + 35), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
cv2.putText(frame, t.status.name, (x1 + 10, y1 + 50), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
cv2.rectangle(frame, (x1, y1), (x2, y2), color, cv2.FONT_HERSHEY_SIMPLEX)
cv2.putText(frame, f"X: {int(t.spatialCoordinates.x)} mm", (x1 + 10, y1 + 65), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
cv2.putText(frame, f"Y: {int(t.spatialCoordinates.y)} mm", (x1 + 10, y1 + 80), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
cv2.putText(frame, f"Z: {int(t.spatialCoordinates.z)} mm", (x1 + 10, y1 + 95), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
-
通过
for t in trackletsData循环遍历目标跟踪数据列表中的每一个跟踪目标。 -
通过
t.roi.denormalize(frame.shape[1], frame.shape[0])将目标的相对坐标转换为绝对坐标,并赋值给roi。roi是一个矩形区域对象,表示目标在图像中的位置。 -
通过
roi对象获取目标矩形的四个角的坐标值,并分别赋值给x1、y1、x2、y2变量。这些坐标用于确定目标矩形框的位置和大小。 -
通过
labelMap[t.label]尝试从labelMap字典中获取目标的标签值,并将其赋值给label变量。如果在labelMap中没有找到对应的标签,就将t.label的值直接赋给label。 -
使用
cv2.putText()在图像帧上绘制目标的标签、ID和状态信息。cv2.putText()函数用于在图像上绘制文本,可以指定文本内容、位置、字体、字体大小、颜色等参数。 -
使用
cv2.rectangle()在图像帧上绘制目标矩形框,以及使用定义的color绘制框的颜色。 -
使用
cv2.putText(frame, f"X: {int(t.spatialCoordinates.x)} mm", (x1 + 10, y1 + 65), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)方法,在视频帧(frame)上添加X轴的空间坐标信息。这个信息显示在边界框左上角的位置,具体的位置由(x1+10, y1+65)指定。文本使用的字体是cv2.FONT_HERSHEY_TRIPLEX,大小为0.5,颜色为白色(255)。t.spatialCoordinates.x是一个变量,表示物体在空间中的X坐标,使用int()函数将其转换为整数,单位为毫米。 -
使用类似的方式,使用
cv2.putText(frame, f"Y: {int(t.spatialCoordinates.y)} mm", (x1 + 10, y1 + 80), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)方法,在视频帧上添加Y轴的空间坐标信息,位置为(x1+10, y1+80),字体为cv2.FONT_HERSHEY_TRIPLEX,大小为0.5,颜色为白色。t.spatialCoordinates.y表示物体在空间中的Y坐标。 -
使用
cv2.putText(frame, f"Z: {int(t.spatialCoordinates.z)} mm", (x1 + 10, y1 + 95), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)方法,在视频帧上添加Z轴的空间坐标信息,位置为(x1+10, y1+95),字体为cv2.FONT_HERSHEY_TRIPLEX,大小为0.5,颜色为白色。t.spatialCoordinates.z表示物体在空间中的Z坐标。
在窗口中显示图像帧,并在帧上绘制神经网络的帧率信息
cv2.putText(frame, "NN fps: {:.2f}".format(fps), (2, frame.shape[0] - 4), cv2.FONT_HERSHEY_TRIPLEX, 0.4, color)
cv2.imshow("tracker", frame)
if cv2.waitKey(1) == ord('q'):
break
-
使用
cv2.putText(frame, "NN fps: {:.2f}".format(fps), (2, frame.shape[0] - 4), cv2.FONT_HERSHEY_TRIPLEX, 0.4, color)方法在视频帧上添加了一个表示神经网络每秒处理帧数的文本信息。"NN fps: {:.2f}".format(fps)是一个格式化字符串,用来将fps变量的值插入到字符串中。(2, frame.shape[0] - 4)指定了文本的位置,位于视频帧的左下角。cv2.FONT_HERSHEY_TRIPLEX表示使用的字体类型,0.4表示字体的大小,color表示文本的颜色。 -
使用
cv2.imshow("tracker", frame)方法显示名为"tracker"的窗口,并在窗口中显示当前的视频帧。 -
使用
cv2.waitKey(1) == ord('q')来检查用户是否按下了键盘上的"q"键。如果按下了"q"键,就会跳出循环,退出程序。
Setup 12:运行程序
在终端中输入如下指令运行程序
python main.py
看下效果,测量的准确度还是可以的,稍微有些误差,后期可以进行优化