帧拼接在有些场景下非常有用,比如将一个较大的帧输入到尺寸较小的神经网络中时。可以将较大的帧拆分成多个较小的帧,并将这些较小的帧输入到神经网络中。
这里我们使用 2 个 ImageManip 将原始预览帧拆分为两个帧。
这里写目录标题
涉及到的节点内容
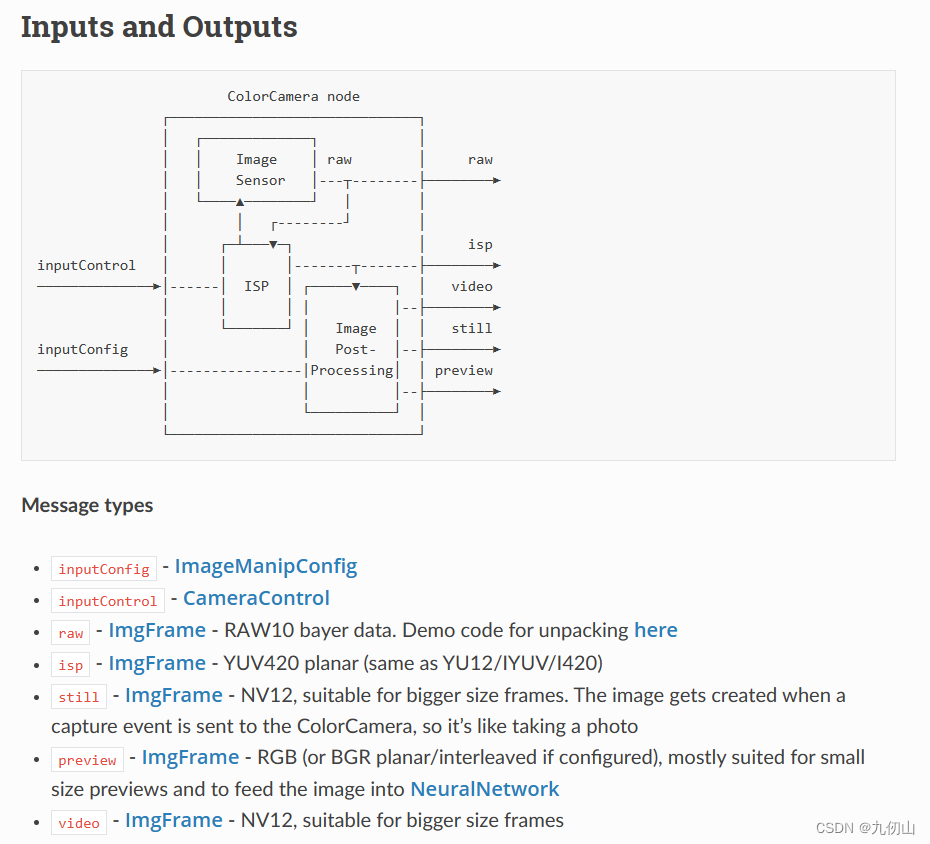
ColorCamera节点
ColorCamera 节点是图像帧的来源。其输入输出如下图所示:
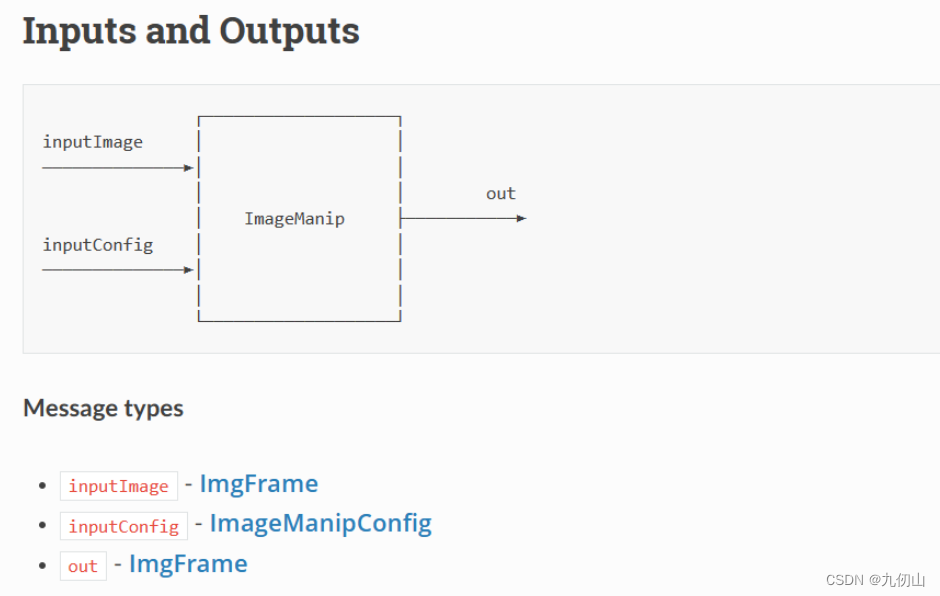
ImageManip 节点
ImageManip 节点可用于裁剪、旋转矩形区域或执行各种图像变换:旋转、镜像、翻转、透视变换。其输入输出如下图所示:
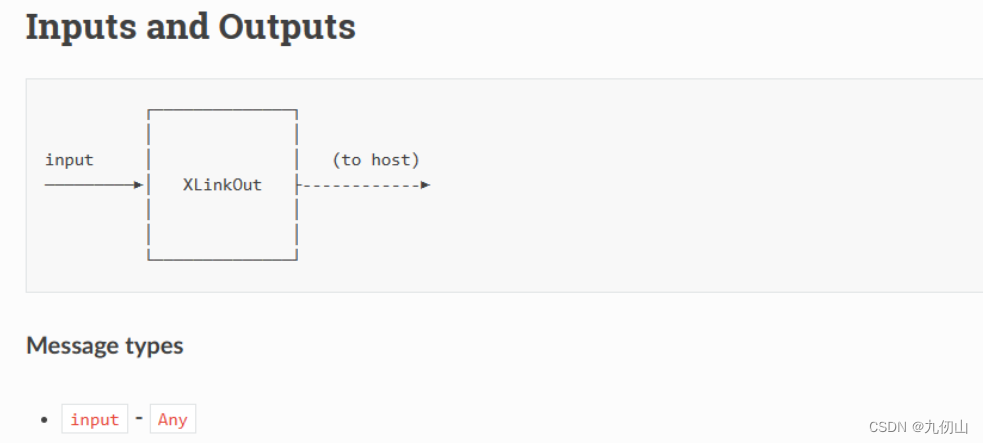
XLinkOut节点
XLinkOut节点用于通过XLink将数据从设备发送到主机。其输入输出如下图所示:
实现步骤
Setup 1: 创建文件
- 创建新建10-imageManip-tiling文件夹
- 用vscode打开该文件夹
- 新建一个main.py 文件
Setup 2: 安装依赖
安装依赖前需要先创建和激活虚拟环境,我这里已经创建了虚拟环境OAKenv,在终端中输入cd…退回到OAKenv的根目录,输入 OAKenv\Scripts\activate激活虚拟环境
安装pip依赖项:
pip install numpy opencv-python depthai blobconverter --user
Setup 3: 导入需要的包
在main.py中导入项目需要的包
import cv2
import depthai as dai
Setup 4: 创建pipeline
pipeline = dai.Pipeline()
Setup 5: 创建节点
创建相机节点
camRgb = pipeline.createColorCamera()
camRgb.setPreviewSize(1000, 500)
camRgb.setInterleaved(False)
maxFrameSize = camRgb.getPreviewHeight() * camRgb.getPreviewWidth() * 3
-
创建一个ColorCamera(camRgb),并设置其预览尺寸为1000x500像素。设置摄像头的数据格式为非交错格式(非交错表示像素数据是按照RGB或BGR的顺序连续存放的,而不是交错存储)。
-
maxFrameSize = camRgb.getPreviewHeight() * camRgb.getPreviewWidth() * 3
计算最大帧尺寸。通过将camRgb摄像头节点的预览高度乘以预览宽度,再乘以3(代表每个像素有3个通道:红、绿、蓝),来计算最大帧尺寸。最终的结果将存储在变量maxFrameSize中。
创建ImageManip节点并建立连接
manip1 = pipeline.createImageManip()
manip1.initialConfig.setCropRect(0, 0, 0.5, 1)
manip1.setMaxOutputFrameSize(maxFrameSize)
camRgb.preview.link(manip1.inputImage)
-
创建了一个图像处理节点(manip1)。
-
通过调用initialConfig.setCropRect()方法,设置图像处理节点的裁剪区域。这里的参数(0, 0, 0.5, 1)代表裁剪区域的位置和大小。(0, 0)代表裁剪区域的左上角坐标,0.5代表裁剪区域的宽度占原始图像宽度的比例(这里为原始图像宽度的一半),1代表裁剪区域的高度占原始图像高度的比例(这里为原始图像高度的全部)。
-
调用manip1.setMaxOutputFrameSize()方法,设置图像处理节点的最大输出帧尺寸为之前计算得到的maxFrameSize。
-
通过调用camRgb.preview.link(manip1.inputImage)方法,将摄像头节点的预览输出连接到图像处理节点的输入。这样,图像处理节点将接收到来自摄像头的预览图像,并进行预定义的裁剪和调整尺寸操作。
manip2 = pipeline.createImageManip()
manip2.initialConfig.setCropRect(0.5, 0, 1, 1)
manip2.setMaxOutputFrameSize(maxFrameSize)
camRgb.preview.link(manip2.inputImage)
创建了另一个图像处理节点(manip2)。
-
通过调用manip2.initialConfig.setCropRect()方法,设置图像处理节点的裁剪区域。这里的参数(0.5, 0, 1, 1)代表裁剪区域的位置和大小。(0.5, 0)代表裁剪区域的左上角坐标,1代表裁剪区域的宽度占原始图像宽度的比例(这里为原始图像宽度的一半之后的部分),1代表裁剪区域的高度占原始图像高度的比例(这里为原始图像高度的全部)。
-
调用manip2.setMaxOutputFrameSize()方法,设置图像处理节点的最大输出帧尺寸为之前计算得到的maxFrameSize。
-
通过调用camRgb.preview.link(manip2.inputImage)方法,将摄像头节点的预览输出连接到第二个图像处理节点的输入。这样,第二个图像处理节点将接收到来自摄像头的预览图像,并进行预定义的裁剪和调整尺寸操作。
创建XLinkOut并建立连接
xout1 = pipeline.create(dai.node.XLinkOut)
xout1.setStreamName('out1')
manip1.out.link(xout1.input)
创建XLinkOut节点,命名为xout1,并设置它的输出流名称为’out1’。然后,将manip1节点的输出链接到xout1节点的输入。这样,manip1节点处理后的图像数据将通过xout1节点输出。
xout2 = pipeline.create(dai.node.XLinkOut)
xout2.setStreamName('out2')
manip2.out.link(xout2.input)
创建第二个XLinkOut节点,命名为xout2,并设置它的输出流名称为’out2’。然后,将manip2节点的输出链接到xout2节点的输入。这样,manip2节点处理后的图像数据将通过xout2节点输出。
Setup 6: 连接设备并启动管道
with dai.Device(pipeline) as device:
Setup 7: 创建与DepthAI设备通信的输入队列和输出队列
q1 = device.getOutputQueue(name="out1", maxSize=4, blocking=False)
q2 = device.getOutputQueue(name="out2", maxSize=4, blocking=False)
创建两个输出队列q1和q2。
第一个输出队列q1通过设备的getOutputQueue方法创建,传入参数name="out1"表示要获取名称为"out1"的输出流。同时指定了队列的最大大小为4,blocking=False表示在队列满时不会阻塞添加新的元素。
第二个输出队列q2也是通过设备的getOutputQueue方法创建,传入参数name="out2"表示要获取名称为"out2"的输出流。同样地,指定了队列的最大大小为4,blocking=False表示在队列满时不会阻塞添加新的元素。
Setup 8: 主循环
while True:
从输出队列q1和q2中获取帧数据并显示在窗口中
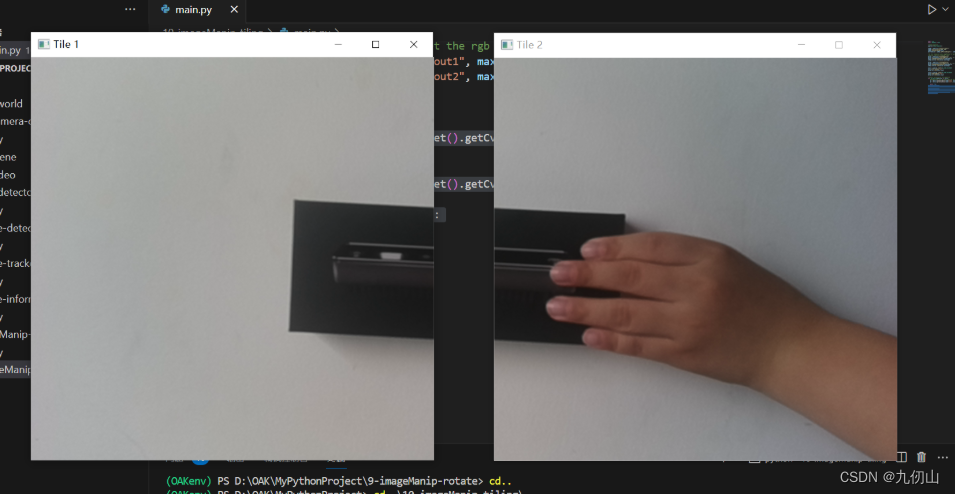
if q1.has():
cv2.imshow("Tile 1", q1.get().getCvFrame())
if q2.has():
cv2.imshow("Tile 2", q2.get().getCvFrame())
if cv2.waitKey(1) == ord('q'):
break
使用q1.has()和q2.has()检查输出队列q1和q2是否有可用的帧数据。
如果输出队列q1有可用的帧数据,就使用q1.get().getCvFrame()获取最新的帧,并使用OpenCV的cv2.imshow()方法在名为"Tile 1"的窗口中显示。
如果输出队列q2有可用的帧数据,就使用q2.get().getCvFrame()获取最新的帧,并使用OpenCV的cv2.imshow()方法在名为"Tile 2"的窗口中显示。
使用cv2.waitKey(1)等待用户按下键盘上的键。如果检测到按键为字符’q’,则退出循环,结束程序。
Setup 9:运行程序
在终端中输入如下指令运行程序
python main.py
运行后的效果如下: